자습서: Databricks Notebook을 사용하는 EDA 기술
이 자습서에서는 데이터 로드에서 데이터 시각화를 통한 인사이트 생성에 이르기까지 Azure Databricks Notebook에서 Python을 사용하여 EDA(예비 데이터 분석)를 수행하는 기본 사항을 안내합니다.
이 자습서에 사용된 Notebook은 글로벌 에너지 및 배출 데이터를 검사하고 데이터를 로드, 정리 및 탐색하는 방법을 보여 줍니다.
예제 Notebook 사용하거나 처음부터 고유한 Notebook을 만들 수 있습니다.
EDA란?
EDA(예비 데이터 분석)는 데이터 분석 및 시각화를 포함하는 데이터 과학 프로세스의 중요한 초기 단계입니다.
- 주요 특징을 파악합니다.
- 패턴 및 추세를 식별합니다.
- 변칙을 검색합니다.
- 변수 간의 관계를 이해합니다.
EDA는 데이터 세트에 대한 인사이트를 제공하여 추가 통계 분석 또는 모델링에 대한 정보에 입각한 결정을 용이하게 합니다.
Azure Databricks Notebook을 사용하면 데이터 과학자가 익숙한 도구를 사용하여 EDA를 수행할 수 있습니다. 예를 들어 이 자습서에서는 다음과 같은 몇 가지 일반적인 Python 라이브러리를 사용하여 데이터를 처리하고 그 그림으로 표시합니다.
- Numpy: 숫자 컴퓨팅을 위한 기본 라이브러리로, 배열, 행렬 및 이러한 데이터 구조에서 작동하는 다양한 수학 함수를 지원합니다.
- pandas: 구조화된 데이터를 효율적으로 처리하기 위해 DataFrames와 같은 데이터 구조를 제공하는 NumPy를 기반으로 구축된 강력한 데이터 조작 및 분석 라이브러리입니다.
- Plotly: 데이터 분석 및 프레젠테이션을 위한 고품질 대화형 시각화를 만들 수 있는 대화형 그래프 라이브러리입니다.
- Matplotlib: Python에서 정적이고 애니메이션적이며 대화형 시각화를 만들기 위한 포괄적인 라이브러리입니다.
또한 Azure Databricks는 테이블 내의 데이터 필터링 및 검색, 시각화 확대 등 Notebook 출력 내에서 데이터를 탐색하는 데 도움이 되는 기본 제공 기능을 제공합니다. Databricks Assistant를 사용하여 EDA에 대한 코드를 작성할 수도 있습니다.
시작하기 전에
이 자습서를 완료하려면 다음이 필요합니다.
- 기존 컴퓨팅 리소스를 사용하거나 새 컴퓨팅 리소스를 만들 수 있는 권한이 있어야 합니다. 컴퓨트을 참조하세요.
- [선택 사항] 이 자습서에서는 도우미를 사용하여 코드를 생성하는 방법을 설명합니다. 도우미를 사용하려면 계정 및 작업 영역에서 도우미를 사용하도록 설정해야 합니다. 자세한 내용을 확인하려면 에서 도우미를 사용하세요.
데이터 세트 다운로드 및 CSV 파일 가져오기
이 자습서에서는 글로벌 에너지 및 배출 데이터를 검사하여 EDA 기술을 보여 줍니다. 이를 수행하려면 Our World in Data의 에너지 소비 데이터 세트을 Kaggle에서 다운로드합니다. 이 자습서에서는 owid-energy-data.csv 파일을 사용합니다.
데이터 세트를 Azure Databricks 작업 영역으로 가져오려면 다음을 수행합니다.
작업 영역의 사이드바에서 작업 영역 클릭하여 작업 영역 브라우저로 이동합니다.
오른쪽 위에서 케밥 메뉴를 클릭한 다음 가져오기를 클릭합니다.
그러면 가져오기 모달이 열립니다. 여기에 나열된 대상 폴더 확인합니다. 작업 영역 브라우저에서 현재 폴더로 설정되고, 가져온 파일이 저장될 위치로 지정됩니다.
파일에서 가져오기를 선택합니다.
CSV 파일(
owid-energy-data.csv)을 창으로 끌어서 놓습니다. 또는 파일을 찾아서 선택할 수 있습니다.가져오기을 클릭합니다. 파일이 작업 영역의 대상 폴더에 표시됩니다.
나중에 파일을 전자 필기장으로 가져오려면 파일 경로가 필요합니다. 작업 영역 브라우저에서 파일을 찾습니다. 파일 경로를 클립보드에 복사하려면 파일 이름을 마우스 오른쪽 단추로 클릭한 다음 url/경로 복사 >전체 경로선택합니다.
새 전자 필기장 만들기
사용자 홈 폴더에 새 전자 필기장을 만들려면 사이드바에서 ![]() 새 클릭하고 메뉴에서 Notebook 선택합니다.
새 클릭하고 메뉴에서 Notebook 선택합니다.
노트북의 이름 옆에 있는 맨 위에서 Python을 노트북의 기본 언어로 설정합니다.
Notebook을 만들고 관리하는 방법에 대한 자세한 내용은 Notebook관리를 참조하세요.
이 문서의 각 코드 샘플을 Notebook의 새 셀에 추가합니다. 또는 제공된 예제 Notebook을 사용하여 튜토리얼을 따라 하세요.
CSV 파일 로드
새 Notebook 셀에서 CSV 파일을 로드합니다. 이렇게 하려면 numpy와 pandas을 가져오세요. 데이터 과학 및 분석을 위한 유용한 Python 라이브러리입니다.
데이터 세트에서 pandas DataFrame을 만들어 보다 쉽게 처리하고 시각화할 수 있습니다. 아래 파일 경로를 이전에 복사한 경로로 바꿉다.
import numpy as np
import pandas as pd # Data processing, CSV file I/O (e.g. pd.read_csv)
df=pd.read_csv('/Workspace/Users/demo@databricks.com/owid-energy-data.csv') # Replace the file path here with the workspace path you copied earlier
셀을 실행합니다. 출력은 각 열 및 해당 형식의 목록을 포함하여 pandas DataFrame을 반환해야 합니다.
가져온 DataFrame의 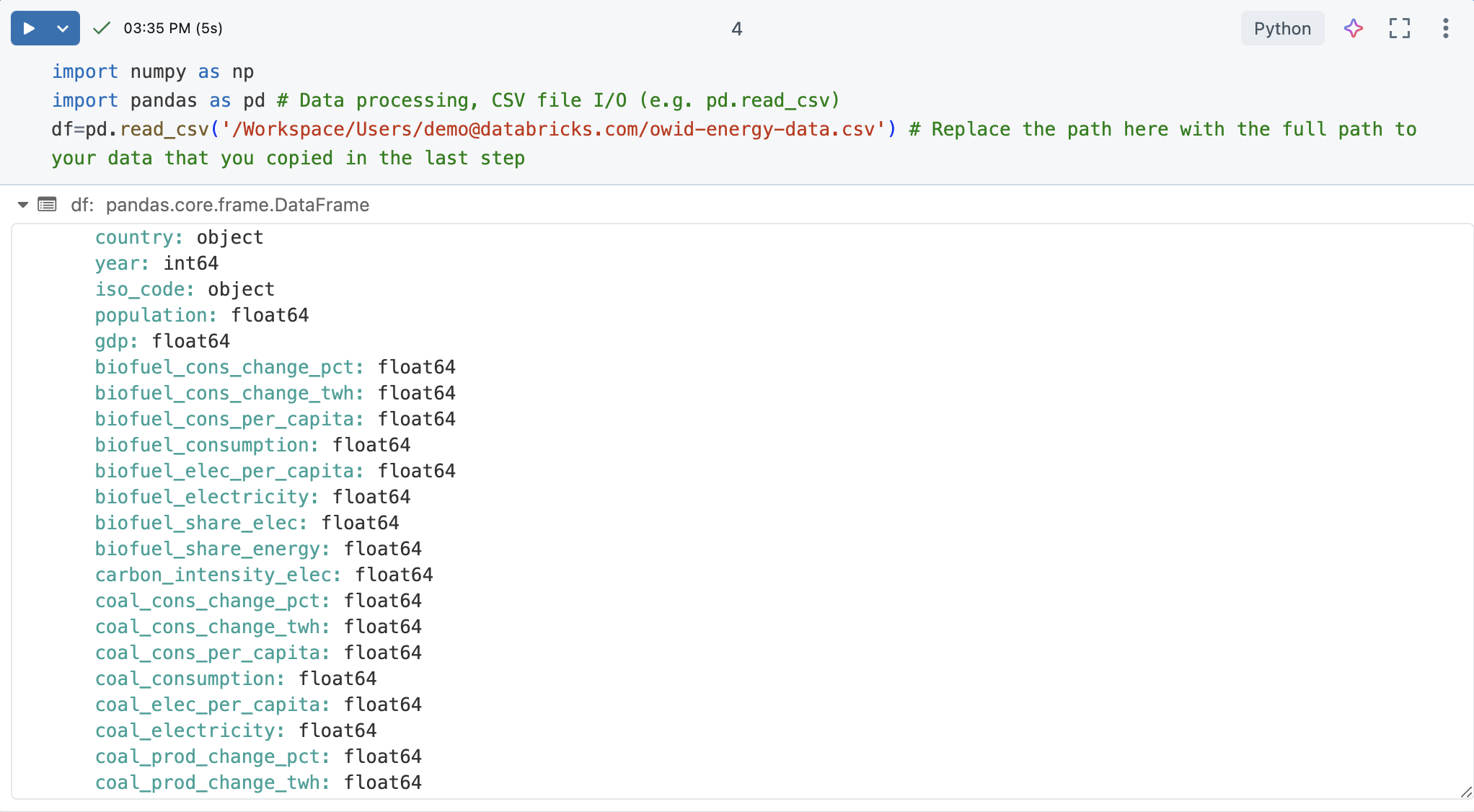
데이터 이해
데이터 세트의 기본 사항을 이해하는 것은 모든 데이터 과학 프로젝트에 매우 중요합니다. 여기에는 현재 있는 데이터의 구조, 형식 및 품질을 숙지하는 작업이 포함됩니다.
Azure Databricks Notebook에서 display(df) 명령을 사용하여 데이터 세트를 표시할 수 있습니다.
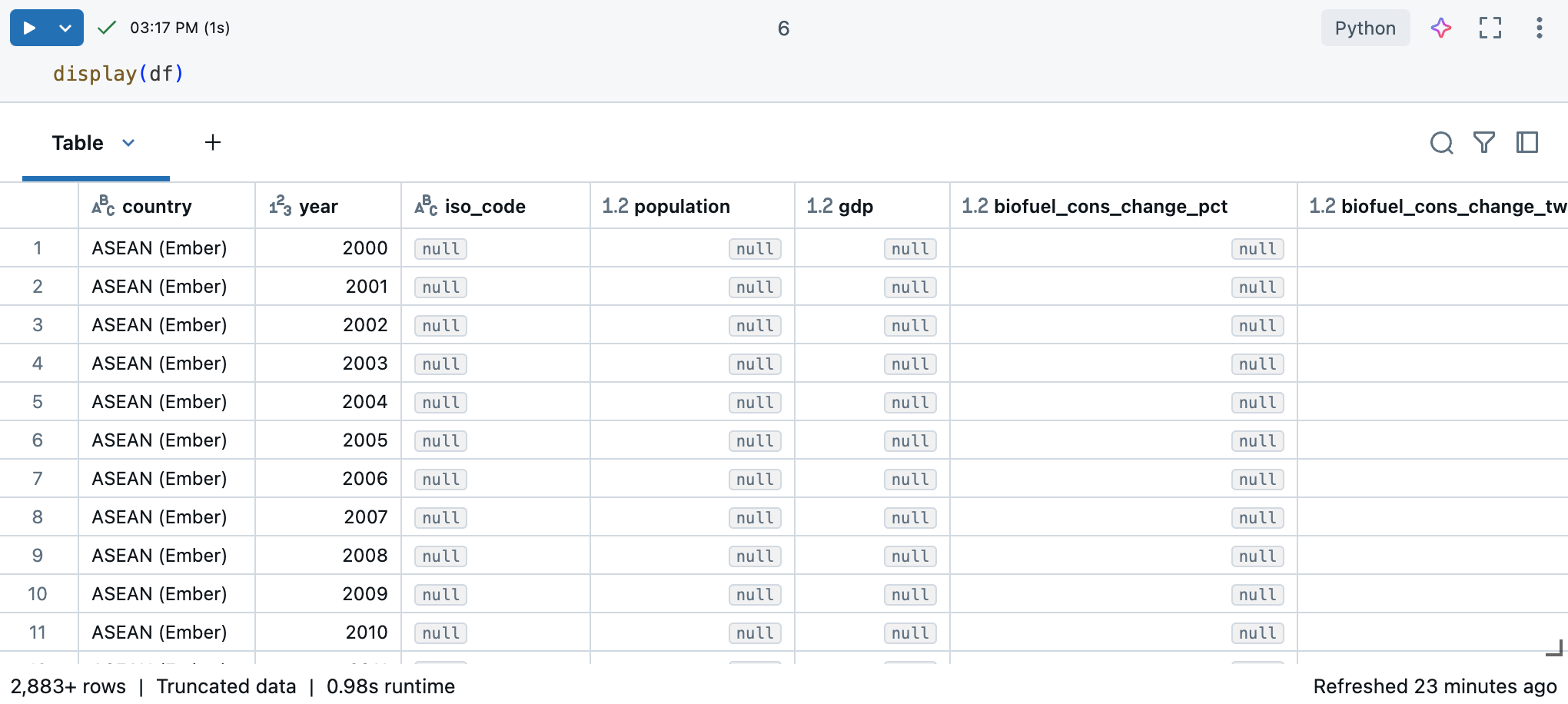
데이터 세트에 10,000개 이상의 행이 있으므로 이 명령은 잘린 데이터 세트를 반환합니다. 각 열의 왼쪽에서 열의 데이터 형식을 볼 수 있습니다. 자세한 내용은 열 서식참조하세요.
데이터 인사이트를 위해 pandas 사용
데이터 세트를 효과적으로 이해하려면 다음 pandas 명령을 사용합니다.
df.shape명령은 DataFrame의 차원을 반환하여 행 및 열 수에 대한 간략한 개요를 제공합니다.
df.dtypes명령은 각 열의 데이터 형식을 제공하여 처리 중인 데이터의 종류를 이해하는 데 도움이 됩니다. 결과 테이블의 각 열에 대한 데이터 형식을 볼 수도 있습니다.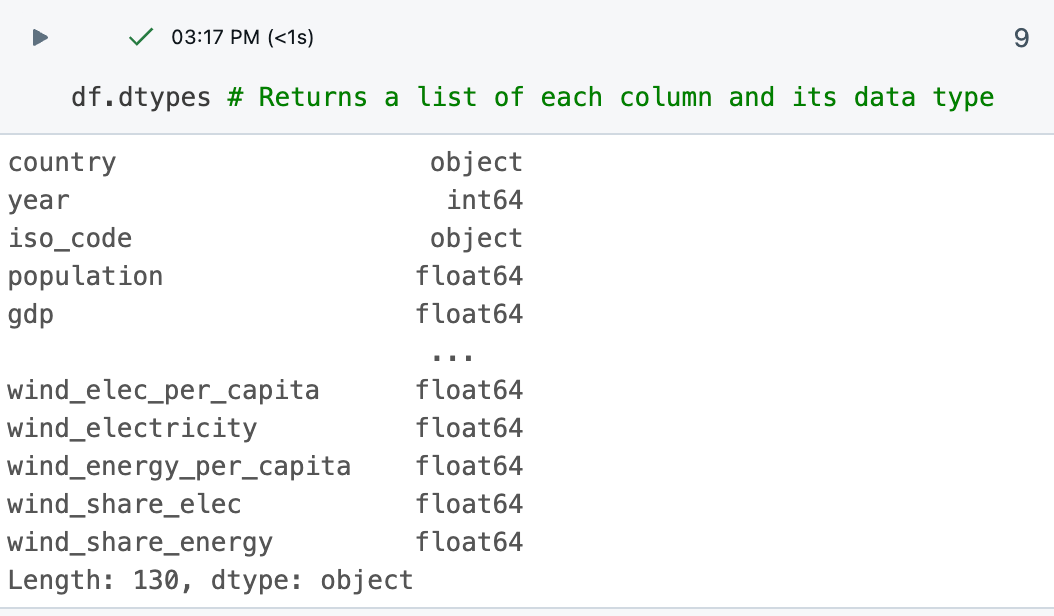
df.describe()명령은 평균, 표준 편차 및 백분위수와 같은 숫자 열에 대한 설명 통계를 생성하여 패턴을 식별하고, 변칙을 검색하고, 데이터 분포를 이해하는 데 도움이 됩니다.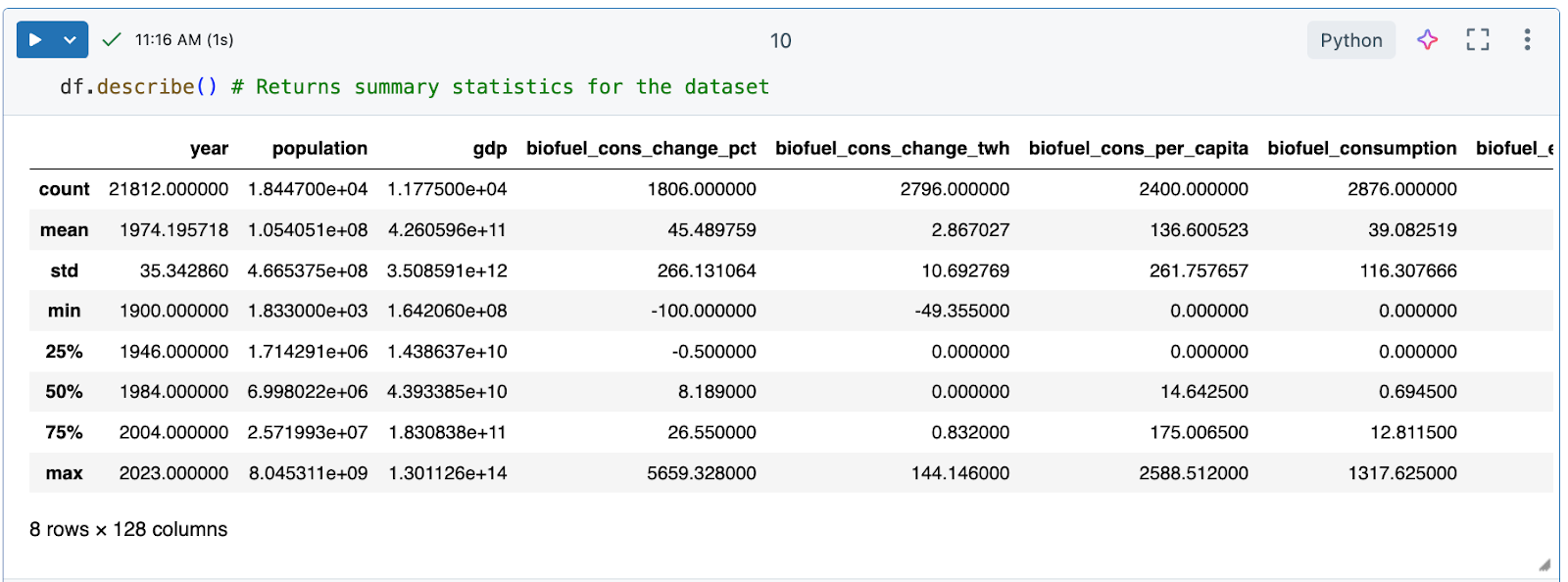
데이터 프로필 생성
Azure Databricks Notebook에는 기본 제공 데이터 프로파일링 기능이 포함됩니다. Azure Databricks 표시 함수를 사용하여 DataFrame을 볼 때 테이블 출력에서 데이터 프로필을 생성할 수 있습니다.
# Display the DataFrame, then click "+ > Data Profile" to generate a data profile
display(df)
출력의 테이블 옆에 있는 +>데이터 프로필 클릭합니다. DataFrame에서 데이터의 프로필을 생성하는 새 명령을 실행합니다.
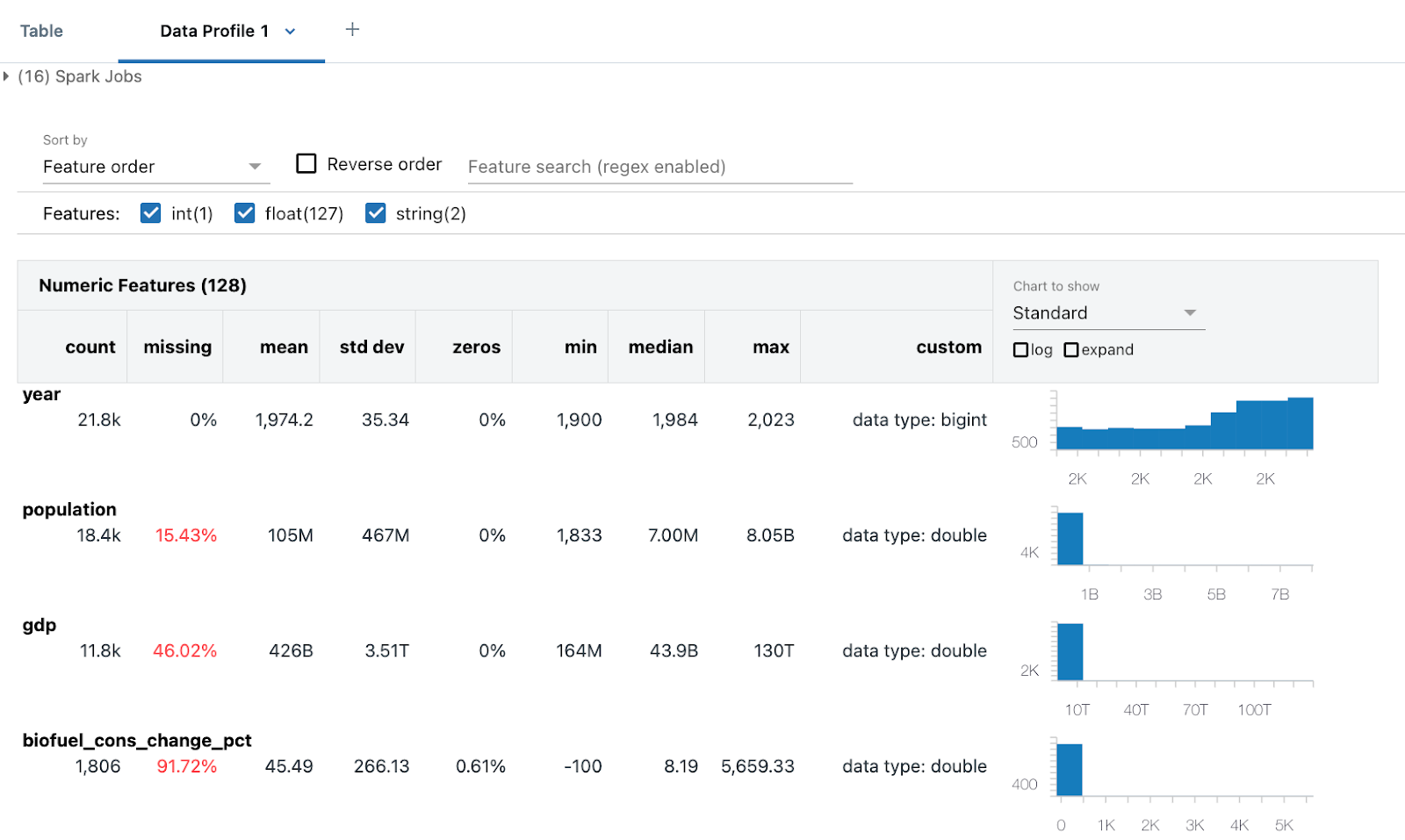
데이터 프로필에는 숫자, 문자열 및 날짜 열에 대한 요약 통계와 각 열에 대한 값 분포의 히스토그램이 포함됩니다.
데이터 정리
데이터 정리는 데이터 세트가 정확하고 일관되며 의미 있는 분석을 위해 준비되도록 하는 EDA의 중요한 단계입니다. 이 프로세스에는 다음을 포함하여 데이터를 분석할 준비가 되도록 하는 몇 가지 주요 작업이 포함됩니다.
- 중복 데이터를 식별하고 제거합니다.
- 누락된 값을 처리합니다. 여기에는 특정 값으로 대체하거나 영향을 받는 행을 제거하는 작업이 포함될 수 있습니다.
- 일관성을 보장하기 위해 문자열을
datetime로 변환하는 등의 변환 및 변형을 통해 데이터 형식을 표준화합니다. 작업하기 쉬운 형식으로 데이터를 변환할 수도 있습니다.
이 정리 단계는 데이터의 품질과 안정성을 향상시켜 보다 정확하고 통찰력 있는 분석을 가능하게 하기 때문에 필수적입니다.
팁: Databricks Assistant를 사용하여 데이터 정리 작업 지원
Databricks Assistant를 사용하여 코드를 생성할 수 있습니다. 새 코드 셀을 만들고 생성 링크를 클릭하거나 오른쪽 위에 있는 도우미 아이콘을 사용하여 도우미를 엽니다. 도우미에 대한 쿼리를 입력합니다. 도우미는 Python 또는 SQL 코드를 생성하거나 텍스트 설명을 생성할 수 있습니다. 다른 결과를 보려면 재실행을 클릭합니다.
예를 들어 도우미를 사용하여 데이터를 정리하는 데 도움이 되도록 다음 프롬프트를 시도합니다.
-
df중복 열 또는 행이 포함되어 있는지 확인합니다. 중복 항목을 인쇄합니다. 그런 다음 중복 항목을 삭제합니다. - 날짜 열의 형식은 무엇인가요?
'YYYY-MM-DD'으로 변경하세요. -
XXX열을 사용하지 않을 것입니다. 삭제합니다.
Databricks Assistant에서 코딩 도움을 받으세요.
중복 데이터 제거
데이터에 중복 행 또는 열이 있는지 확인합니다. 그렇다면 제거합니다.
팁
도우미를 사용하여 코드를 생성합니다.
프롬프트를 입력해 봅니다. "df에 중복 열 또는 행이 포함되어 있는지 확인합니다. 중복 항목을 인쇄합니다. 그런 다음 중복 항목을 삭제합니다." 도우미는 아래 샘플과 같은 코드를 생성할 수 있습니다.
# Check for duplicate rows
duplicate_rows = df.duplicated().sum()
# Check for duplicate columns
duplicate_columns = df.columns[df.columns.duplicated()].tolist()
# Print the duplicates
print("Duplicate rows count:", duplicate_rows)
print("Duplicate columns:", duplicate_columns)
# Drop duplicate rows
df = df.drop_duplicates()
# Drop duplicate columns
df = df.loc[:, ~df.columns.duplicated()]
이 경우 데이터 세트에는 중복된 데이터가 없습니다.
null 또는 누락 값 처리
NaN 또는 Null 값을 처리하는 일반적인 방법은 보다 쉬운 수학 처리를 위해 0으로 바꾸는 것입니다.
df = df.fillna(0) # Replace all NaN (Not a Number) values with 0
이렇게 하면 DataFrame의 누락된 데이터가 0으로 바뀝니다. 이는 누락된 값으로 인해 문제가 발생할 수 있는 후속 데이터 분석 또는 처리 단계에 유용할 수 있습니다.
날짜 형식 재정리
날짜는 다양한 데이터 세트의 다양한 방식으로 서식이 지정되는 경우가 많습니다. 날짜 형식, 문자열 또는 정수일 수 있습니다.
이 분석을 위해 year 열을 정수로 처리합니다. 다음 코드는 이 작업을 수행하는 한 가지 방법입니다.
# Ensure the 'year' column is converted to the correct data type (integer for year)
df['year'] = pd.to_datetime(df['year'], format='%Y', errors='coerce').dt.year
# Confirm the changes
df.year.dtype
이렇게 하면 year 열에 정수 연도 값만 포함되며 잘못된 항목이 NaT(시간이 아님)로 변환됩니다.
Databricks Notebook 출력 테이블을 사용하여 데이터 탐색
Azure Databricks는 출력 테이블을 사용하여 데이터를 탐색하는 데 도움이 되는 기본 제공 기능을 제공합니다.
새 셀에서 display(df) 사용하여 데이터 세트를 테이블로 표시합니다.
출력 테이블을 사용하여 여러 가지 방법으로 데이터를 탐색할 수 있습니다.
- 특정 문자열 또는 값 대한 데이터 검색
- 특정 조건에 대한 필터
- 데이터 세트 사용하여 시각화 만들기
특정 문자열 또는 값에 대한 데이터 검색
테이블의 오른쪽 위에 있는 검색 아이콘을 클릭하고 검색을 입력합니다.
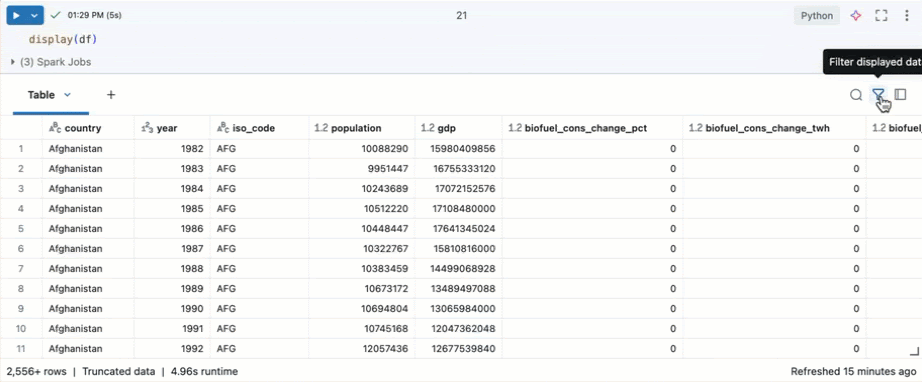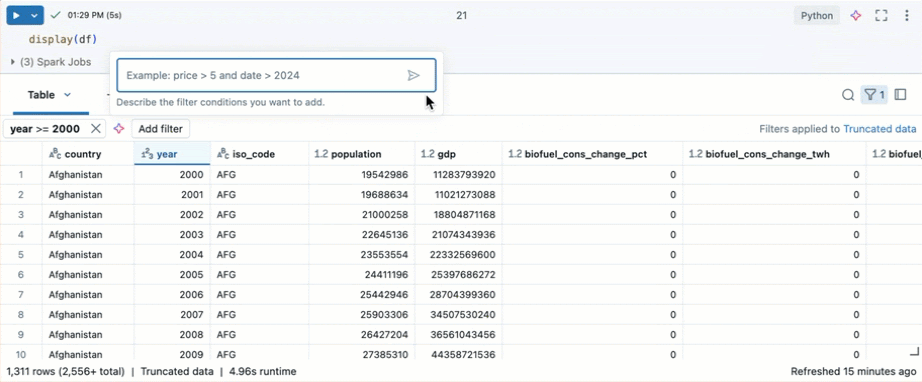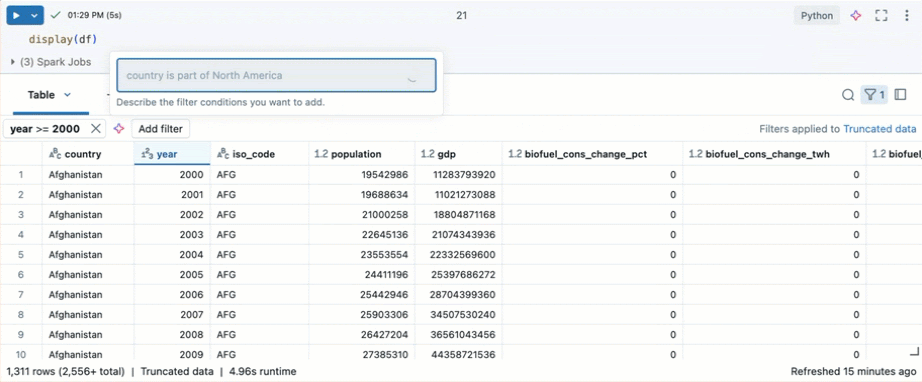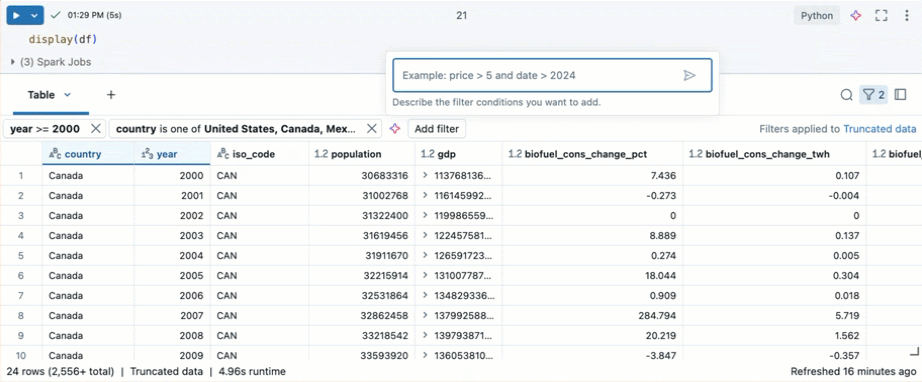
특정 조건에 대한 필터
기본 제공 테이블 필터를 사용하여 특정 조건에 대한 열을 필터링할 수 있습니다. 필터를 만드는 방법에는 여러 가지가 있습니다. 필터 결과참조하세요.
팁
Databricks Assistant를 사용하여 필터를 만듭니다. 테이블의 오른쪽 위 모서리에 있는 필터 아이콘을 클릭합니다. 필터 조건을 입력합니다. Databricks Assistant는 자동으로 필터를 생성합니다.
데이터 세트를 사용하여 시각화 만들기
출력 테이블 맨 위에서 +>시각화를 클릭하여 시각화 편집기를 엽니다.
시각화할 시각화 유형 및 열을 선택합니다. 편집기에서는 구성에 따라 차트의 미리 보기를 표시합니다. 예를 들어 아래 이미지는 여러 꺾은선형 차트를 추가하여 시간이 지남에 따라 다양한 재생 가능 에너지원의 소비량을 보는 방법을 보여 줍니다.
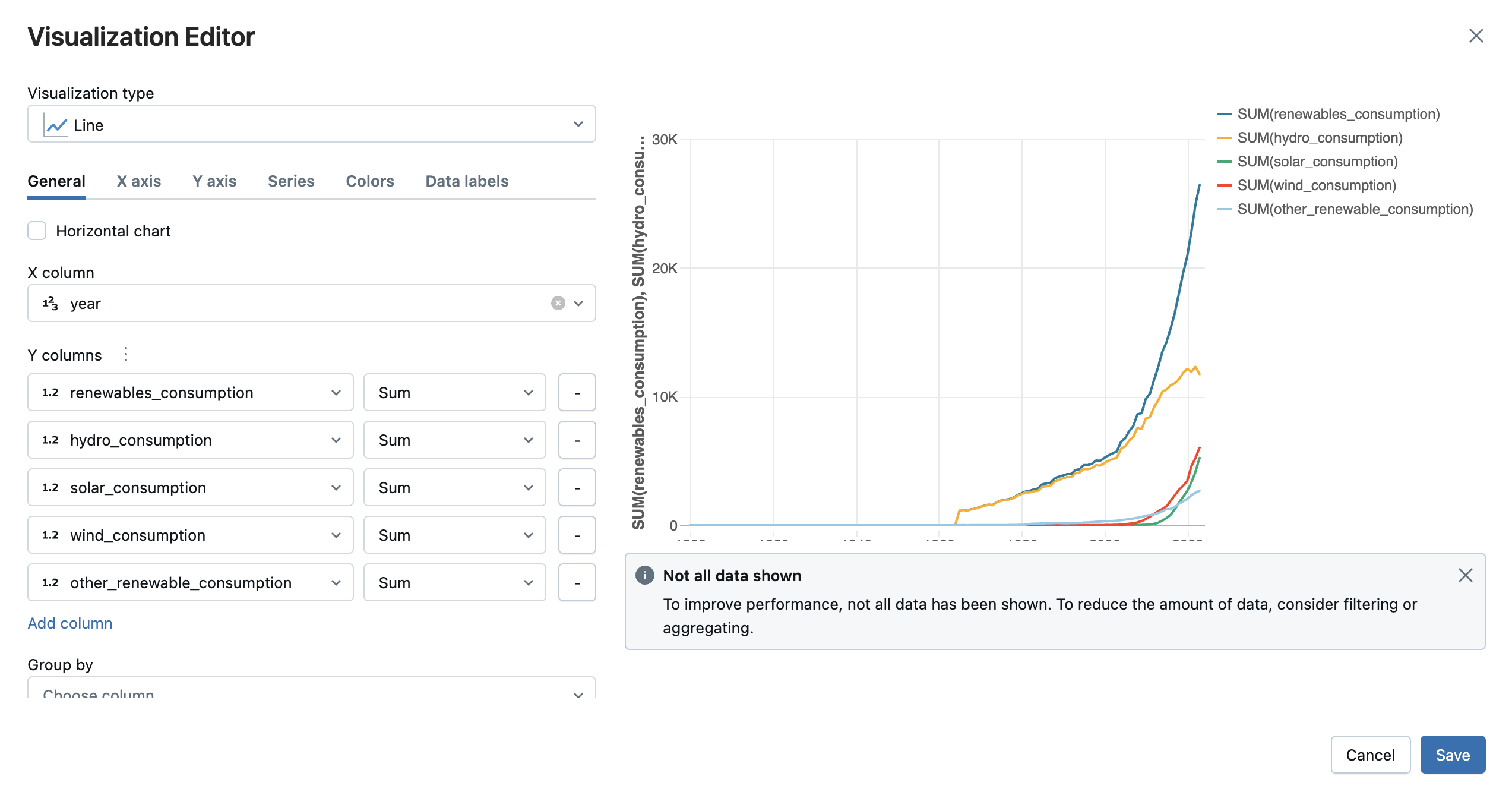
저장을 클릭하여 시각화를 셀 출력의 탭으로 추가합니다.
새 시각화만들기를 참조하세요.
Python 라이브러리를 사용하여 데이터 탐색 및 시각화
시각화를 사용하여 데이터를 탐색하는 것은 EDA의 기본 측면입니다. 시각화는 숫자 분석만으로는 즉시 표시되지 않을 수 있는 데이터 내의 패턴, 추세 및 관계를 파악하는 데 도움이 됩니다. 산점도, 가로 막대형 차트, 꺾은선형 그래프 및 히스토그램을 비롯한 일반적인 시각화 기술에는 Plotly 또는 Matplotlib와 같은 라이브러리를 사용합니다. 이러한 시각적 도구를 사용하면 데이터 과학자가 변칙을 식별하고, 데이터 분포를 이해하고, 변수 간의 상관 관계를 관찰할 수 있습니다. 예를 들어 산점도는 이상값을 강조할 수 있으며, 시계열 그래프는 추세와 계절성을 보여줄 수 있습니다.
- 고유한 국가 대한 배열 만들기
- 200-2022년 상위 10대 배출국에 대한 배출 추세를 차트로 작성
- 지역별 배출 필터링 및 차트
- 재생 에너지 비중 성장을 계산하고 그래프로 나타내기
- 산점도: 최고 배출국에서 재생 에너지가 미치는 영향
- 모델 예상 글로벌 에너지 소비
고유 국가에 대한 배열 만들기
고유한 국가에 대한 배열을 만들어 데이터 세트에 포함된 국가를 검사합니다. 배열을 만들면 country로 나열된 엔터티가 표시됩니다.
# Get the unique countries
unique_countries = df['country'].unique()
unique_countries
출력:

인사이트:
country 열에는 세계, 고소득 국가, 아시아 및 미국을 포함한 다양한 엔터티가 포함되어 있으며, 이들은 항상 직접적으로 비교할 수 있는 것은 아닙니다. 지역별로 데이터를 필터링하는 것이 더 유용할 수 있습니다.
상위 10개 방출기의 차트 배출 추세(200-2022)
2000년대에 온실가스 배출량이 가장 높은 10개국에 대한 조사에 집중하고 싶다고 가정해 보겠습니다. 보고자 하는 연도 및 배출량이 가장 많은 상위 10개국의 데이터를 필터링한 다음, 플롯을 사용하여 시간에 따른 배출량을 보여주는 꺾은선형 차트를 만들 수 있습니다.
import plotly.express as px
# Filter data to include only years from 2000 to 2022
filtered_data = df[(df['year'] >= 2000) & (df['year'] <= 2022)]
# Get the top 10 countries with the highest emissions in the filtered data
top_countries = filtered_data.groupby('country')['greenhouse_gas_emissions'].sum().nlargest(10).index
# Filter the data for those top countries
top_countries_data = filtered_data[filtered_data['country'].isin(top_countries)]
# Plot emissions trends over time for these countries
fig = px.line(top_countries_data, x='year', y='greenhouse_gas_emissions', color='country',
title="Greenhouse Gas Emissions Trends for Top 10 Countries (2000 - 2022)")
fig.show()
출력:
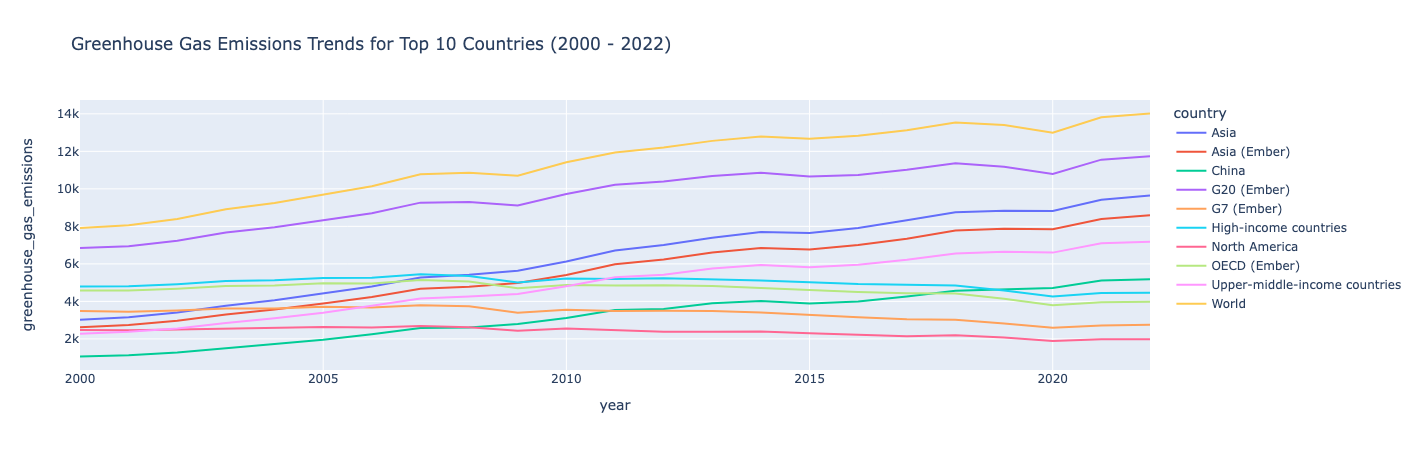
인사이트:
온실가스 배출량은 2000년부터 2022년까지 상승세를 보였으며, 그 기간 동안 배출량이 비교적 안정적이었던 몇몇 국가를 제외하면 그 기간 동안 약간의 감소가 있었습니다.
지역별 배출량을 필터하고 차트로 표시
지역별로 데이터를 필터링하고 각 지역의 총 배출량을 계산합니다. 그런 다음, 데이터를 가로 막대형 차트로 그어 옵니다.
# Filter out regional entities
regions = ['Africa', 'Asia', 'Europe', 'North America', 'South America', 'Oceania']
# Calculate total emissions for each region
regional_emissions = df[df['country'].isin(regions)].groupby('country')['greenhouse_gas_emissions'].sum()
# Plot the comparison
fig = px.bar(regional_emissions, title="Greenhouse Gas Emissions by Region")
fig.show()
출력:
지역별 온실가스 배출량을 보여 주는 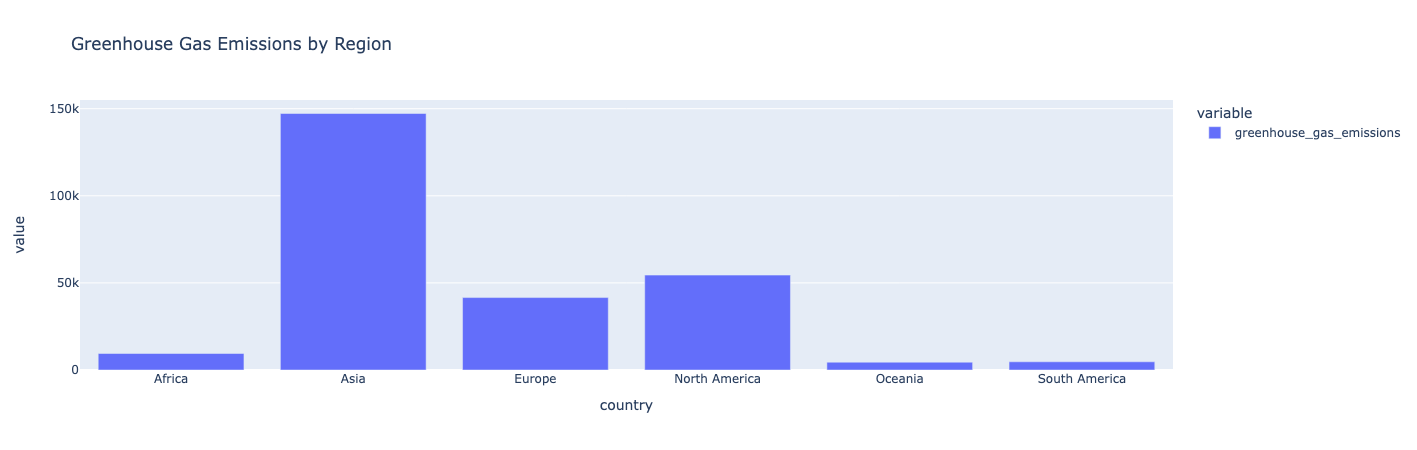
Insight:
아시아는 온실가스 배출량이 가장 높습니다. 오세아니아, 남미 및 아프리카는 가장 낮은 온실 가스 배출을 생산합니다.
재생 에너지 공유 증가율 계산 및 그래프
1차 에너지 소비량에 비해 재생 에너지 소비량의 비율로 재생 에너지 점유율을 계산하는 새로운 기능/열을 만듭니다. 그런 다음 평균 재생 에너지 점유율을 기준으로 국가 순위를 지정합니다. 상위 10개국의 경우 시간이 지남에 따라 재생 가능 에너지 점유율을 계획합니다.
# Calculate the renewable energy share and save it as a new column called "renewable_share"
df['renewable_share'] = df['renewables_consumption'] / df['primary_energy_consumption']
# Rank countries by their average renewable energy share
renewable_ranking = df.groupby('country')['renewable_share'].mean().sort_values(ascending=False)
# Filter for countries leading in renewable energy share
leading_renewable_countries = renewable_ranking.head(10).index
leading_renewable_data = df[df['country'].isin(leading_renewable_countries)]
# filtered_data = df[(df['year'] >= 2000) & (df['year'] <= 2022)]
leading_renewable_data_filter=leading_renewable_data[(leading_renewable_data['year'] >= 2000) & (leading_renewable_data['year'] <= 2022)]
# Plot renewable share over time for top renewable countries
fig = px.line(leading_renewable_data_filter, x='year', y='renewable_share', color='country',
title="Renewable Energy Share Growth Over Time for Leading Countries")
fig.show()
출력:
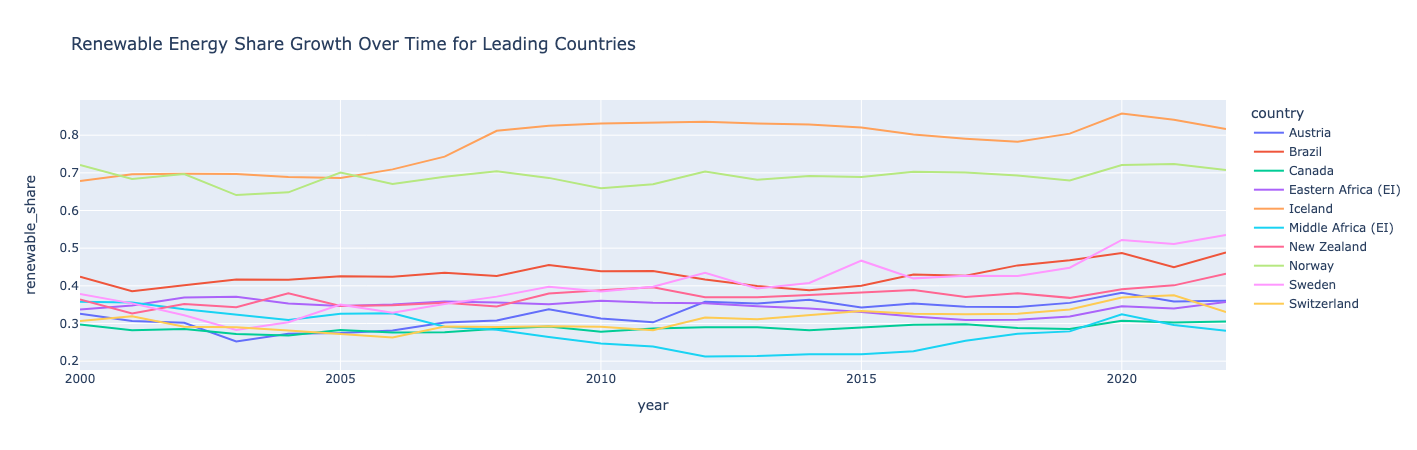
인사이트:
노르웨이와 아이슬란드는 재생 가능 에너지로 전 세계를 선도하고 있으며, 소비량의 절반 이상이 재생 가능 에너지에서 유입되고 있습니다.
아이슬란드와 스웨덴은 재생 에너지 점유율에서 가장 큰 성장을 보였습니다. 모든 국가는 때때로 하락과 상승을 보았으며, 재생 에너지 점유율 성장이 반드시 선형적인 것은 아니라는 것을 보여주었습니다. 흥미롭게도, 중동은 2010년대 초반에 급락했지만 2020년에는 반등했습니다.
산점도: 주요 배출국의 재생 가능 에너지가 미치는 영향 나타내기
상위 10개 방출기의 데이터를 필터링한 다음 산점도를 사용하여 시간에 따른 재생 에너지 공유와 온실가스 배출을 확인합니다.
# Select top emitters and calculate renewable share vs. emissions
top_emitters = df.groupby('country')['greenhouse_gas_emissions'].sum().nlargest(10).index
top_emitters_data = df[df['country'].isin(top_emitters)]
# Plot renewable share vs. greenhouse gas emissions over time
fig = px.scatter(top_emitters_data, x='renewable_share', y='greenhouse_gas_emissions',
color='country', title="Impact of Renewable Energy on Emissions for Top Emitters")
fig.show()
출력:
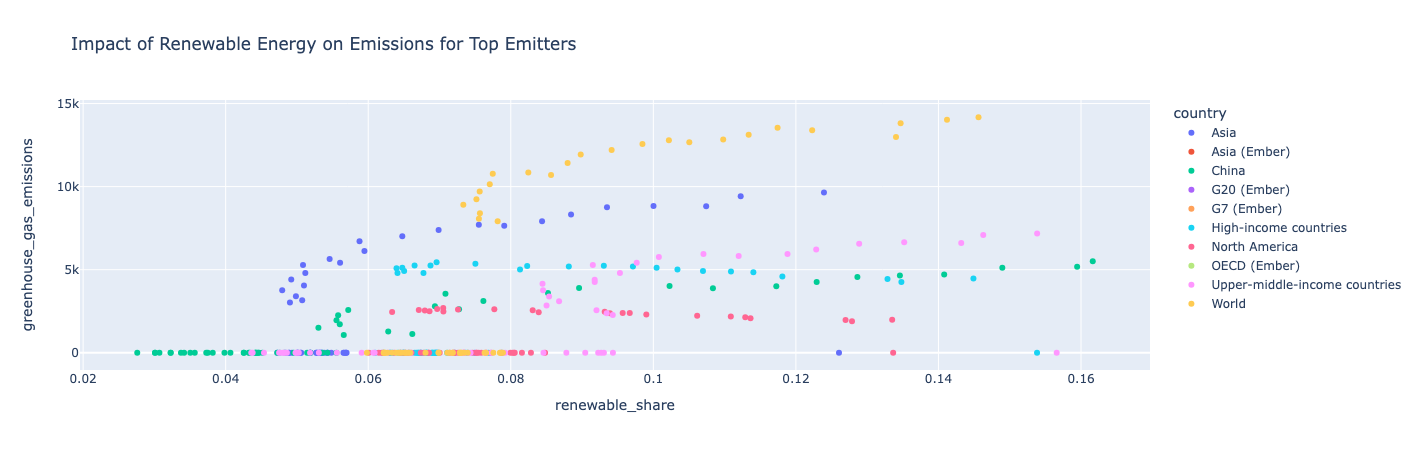
인사이트:
국가가 재생 가능 에너지를 더 많이 사용함에 따라 온실가스 배출량이 더 많기 때문에 총 에너지 소비량이 재생 가능 소비량보다 빠르게 증가합니다. 북미는 재생 가능한 점유율이 계속 증가함에 따라 온실가스 배출량이 수년에 걸쳐 상대적으로 일정하게 유지되었다는 점은 예외입니다.
모델 예상 글로벌 에너지 소비량
연간 글로벌 1차 에너지 소비량을 집계한 다음, 향후 몇 년 동안 총 글로벌 에너지 소비량을 예측하는 ARIMA(자동 회귀 통합 이동 평균) 모델을 구축합니다. Matplotlib를 사용하여 기록 및 예측 에너지 소비량을 계획합니다.
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
import matplotlib.pyplot as plt
# Aggregate global primary energy consumption by year
global_energy = df[df['country'] == 'World'].groupby('year')['primary_energy_consumption'].sum()
# Build an ARIMA model for projection
model = ARIMA(global_energy, order=(1, 1, 1))
model_fit = model.fit()
forecast = model_fit.forecast(steps=10) # Projecting for 10 years
# Plot historical and forecasted energy consumption
plt.plot(global_energy, label='Historical')
plt.plot(range(global_energy.index[-1] + 1, global_energy.index[-1] + 11), forecast, label='Forecast')
plt.xlabel("Year")
plt.ylabel("Primary Energy Consumption")
plt.title("Projected Global Energy Consumption")
plt.legend()
plt.show()
출력:
기록 및 예상 글로벌 에너지 소비를 보여 주는 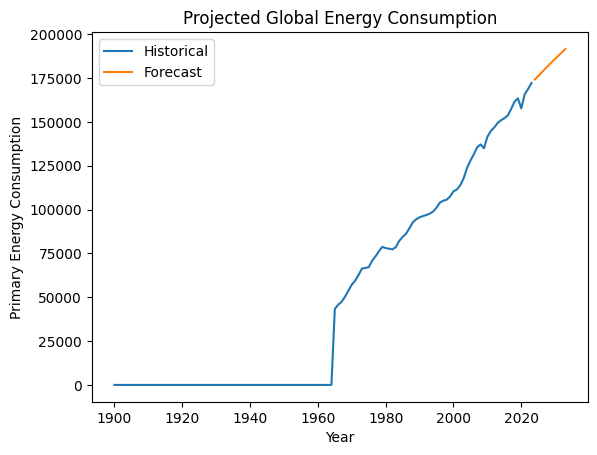
인사이트:
이 모델은 글로벌 에너지 소비가 계속 증가할 것으로 예측합니다.
노트북 예제
다음 Notebook을 사용하여 이 문서의 단계를 수행합니다. Azure Databricks 작업 영역으로 Notebook을 가져오는 방법에 대한 지침은 notebook 가져오기참조하세요.
자습서: 글로벌 에너지 데이터가 있는 EDA
노트북 가져오기
다음 단계
데이터 세트에 대한 몇 가지 초기 예비 데이터 분석을 수행했으므로 다음 단계를 수행합니다.
- 추가 EDA 시각화 예제는 예제 Notebook 부록을 참조하세요.
- 이 자습서를 진행하는 동안 오류가 발생한 경우 기본 제공 디버거를 사용하여 코드를 단계별로 실행해 보세요. 디버그 노트북을 참조하세요.
- 분석을 이해할 수 있도록 팀과 전자 필기장 공유합니다. 부여한 사용 권한에 따라 코드를 개발하여 분석을 진행하거나 추가 조사를 위한 의견과 제안을 추가할 수 있습니다.
- 분석을 완료한 후에는 관련자와 공유할 주요 시각화를 사용하여 Notebook 대시보드 또는 AI/BI 대시보드 만듭니다.