에이전트에 대한 MLflow 추적
Important
이 기능은 공개 미리 보기 상태입니다.
이 문서에서는 Databricks의 MLflow 추적 및 이를 사용하여 생성 AI 애플리케이션에 가시성을 추가하는 방법을 설명합니다.
MLflow 추적이란?
MLflow 추적 gen AI 애플리케이션 실행에 대한 자세한 정보를 캡처합니다. 추적은 요청의 각 중간 단계와 연결된 입력, 출력 및 메타데이터를 기록하므로 버그 및 예기치 않은 동작의 원인을 정확히 파악할 수 있습니다. 예를 들어 모델이 거짓 정보를 제공하는 경우 거짓 정보로 이어진 각 단계를 신속하게 검사할 수 있습니다.
MLflow 추적은 Databricks 도구 및 인프라와 통합되어 Databricks Notebook 또는 MLflow 실험 UI에 추적을 저장하고 표시할 수 있습니다.
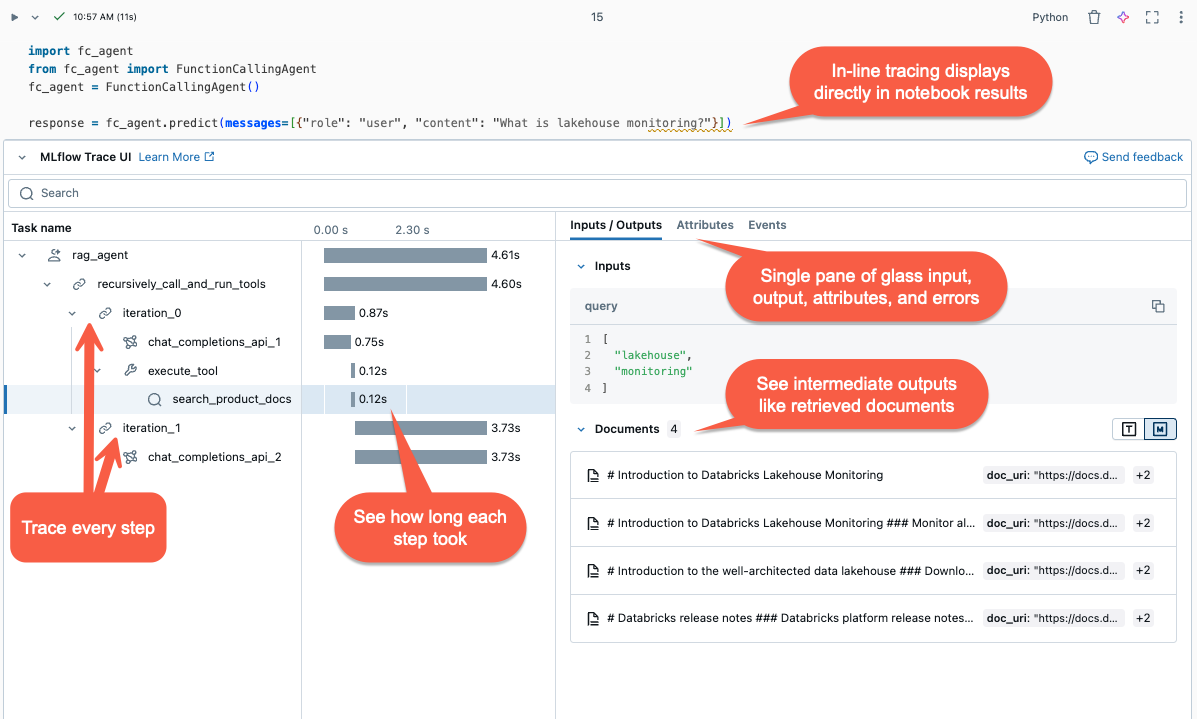 에서 캡처합니다.
에서 캡처합니다.
MLflow 추적을 사용하는 이유는 무엇인가요?
MLflow 추적은 다음과 같은 몇 가지 이점을 제공합니다.
- 대화형 추적 시각화를 검토하고 조사 도구를 사용하여 문제를 진단합니다.
- 프롬프트 템플릿 및 가드레일이 적절한 결과를 생성하는지 확인합니다.
- 다양한 프레임워크, 모델 및 청크 크기의 대기 시간을 분석합니다.
- 다양한 모델에서 토큰 사용을 측정하여 애플리케이션 비용을 예측합니다.
- 벤치마크 "골든" 데이터 세트를 설정하여 다양한 버전의 성능을 평가합니다.
- 프로덕션 모델 엔드포인트에서 추적을 저장하여 문제를 디버그하고 오프라인 검토 및 평가를 수행합니다.
에이전트에 추적 추가
MLflow 추적은 생성 AI 애플리케이션에 추적을 추가하는 세 가지 방법을 지원합니다. API 참조에 대한 자세한 내용은MLflow 문서를 참조하세요.
| API | 권장 사용 사례 | 설명 |
|---|---|---|
| MLflow 자동 로깅 | 통합 GenAI 라이브러리를 사용한 개발 | 자동 로깅은 LangChain, LlamaIndex 및 OpenAI와 같은 지원되는 오픈 소스 프레임워크에 대한 추적을 자동으로 기록합니다. |
| 유창한 API | Pyfunc를 통한 사용자 지정 에이전트 | 추적의 트리 구조를 관리할 염려 없이 추적을 추가하기 위한 하위 코드 API입니다. MLflow는 Python 스택을 사용하여 적절한 부모-자식 범위 관계를 자동으로 결정합니다. |
| MLflow 클라이언트 API | 다중 스레딩과 같은 고급 사용 사례 |
MLflowClient 고급 사용 사례에 대해 스레드로부터 안전한 세분화된 API를 제공합니다. 범위의 부모-자식 관계를 수동으로 관리해야 합니다. 이렇게 하면 특히 다중 스레드 사용 사례의 추적 수명 주기를 더 잘 제어할 수 있습니다. |
MLflow 추적 설치
MLflow 추적은 MLflow 버전 2.13.0 이상에서 사용할 수 있으며 <DBR< 15.4 LTS ML 이상에 미리 설치되어 있습니다. 필요한 경우 다음 코드를 사용하여 MLflow를 설치합니다.
%pip install mlflow>=2.13.0 -qqqU
%restart_python
또는 호환되는 MLflow 버전이 포함된 최신 버전의 databricks-agents을(를) 설치할 수 있습니다.
%pip install databricks-agents
자동 로깅을 사용하여 에이전트에 추적을 추가하십시오
GenAI 라이브러리가 LangChain 또는 OpenAI와 같은 추적을 지원하는 경우 코드에 mlflow.<library>.autolog() 추가하여 자동 로깅을 사용하도록 설정합니다. 예를 들어:
mlflow.langchain.autolog()
참고 항목
Databricks Runtime 15.4 LTS ML을 기준으로 MLflow 추적은 기본적으로 Notebooks 내에서 사용하도록 설정됩니다. 예를 들어 LangChain을 사용하여 추적을 사용하지 않도록 설정하려면 Notebook에서 mlflow.langchain.autolog(log_traces=False) 실행할 수 있습니다.
MLflow는 추적 자동 로깅을 위한 추가 라이브러리를 지원합니다. 통합 라이브러리의 전체 listMLflow 추적 설명서참조하세요.
Fluent API를 사용하여 에이전트에 추적 로그를 수동으로 추가
MLflow의 Fluent API는 코드의 실행 흐름에 따라 추적 계층을 자동으로 만듭니다.
함수 데코레이트
@mlflow.trace 데코레이터를 사용하여 데코레이팅된 함수의 범위에 대한 범위를 만듭니다.
MLflow Span 개체 추적 단계를 구성합니다. Spans는 워크플로 내에서 API 호출 또는 벡터 저장소 쿼리와 같은 개별 작업 또는 단계에 대한 정보를 캡처합니다.
범위는 함수가 호출될 때 시작되고 반환될 때 끝납니다. MLflow는 함수의 입력 및 출력과 함수에서 발생한 예외를 기록합니다.
예를 들어 다음 코드는 입력 인수 x 및 y 출력을 캡처하는 my_function이라는 범위를 만듭니다.
@mlflow.trace(name="agent", span_type="TYPE", attributes={"key": "value"})
def my_function(x, y):
return x + y
추적 컨텍스트 관리자를 사용하세요.
함수뿐만 아니라 임의의 코드 블록에 대한 범위를 만들려면 mlflow.start_span() 코드 블록을 래핑하는 컨텍스트 관리자로 사용할 수 있습니다. 범위는 컨텍스트가 입력될 때 시작되고 컨텍스트가 종료될 때 종료됩니다. 컨텍스트 관리자가 생성한 범위 개체의 setter 메서드를 사용하여 범위 입력 및 출력을 수동으로 제공해야 합니다.
with mlflow.start_span("my_span") as span:
span.set_inputs({"x": x, "y": y})
result = x + y
span.set_outputs(result)
span.set_attribute("key", "value")
외부 함수 감싸기
외부 라이브러리 함수를 추적하려면 mlflow.trace사용하여 함수를 래핑합니다.
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
traced_accuracy_score = mlflow.trace(accuracy_score)
traced_accuracy_score(y_true, y_pred)
### Fluent API example
The following example shows how to use the Fluent APIs `mlflow.trace` and `mlflow.start_span` to trace the `quickstart-agent`:
```python
import mlflow
from mlflow.deployments import get_deploy_client
class QAChain(mlflow.pyfunc.PythonModel):
def __init__(self):
self.client = get_deploy_client("databricks")
@mlflow.trace(name="quickstart-agent")
def predict(self, model_input, system_prompt, params):
messages = [
{
"role": "system",
"content": system_prompt,
},
{
"role": "user",
"content": model_input[0]["query"]
}
]
traced_predict = mlflow.trace(self.client.predict)
output = traced_predict(
endpoint=params["model_name"],
inputs={
"temperature": params["temperature"],
"max_tokens": params["max_tokens"],
"messages": messages,
},
)
with mlflow.start_span(name="_final_answer") as span:
# Initiate another span generation
span.set_inputs({"query": model_input[0]["query"]})
answer = output["choices"][0]["message"]["content"]
span.set_outputs({"generated_text": answer})
# Attributes computed at runtime can be set using the set_attributes() method.
span.set_attributes({
"model_name": params["model_name"],
"prompt_tokens": output["usage"]["prompt_tokens"],
"completion_tokens": output["usage"]["completion_tokens"],
"total_tokens": output["usage"]["total_tokens"]
})
return answer
추적을 추가한 후 함수를 실행합니다. 다음은 이전 섹션의 predict() 함수를 사용하여 예제를 계속합니다. 호출 메서드를 실행할 때 추적이 자동으로 표시됩니다, predict().
SYSTEM_PROMPT = """
You are an assistant for Databricks users. You answer Python, coding, SQL, data engineering, spark, data science, DW and platform, API, or infrastructure administration questions related to Databricks. If the question is unrelated to one of these topics, kindly decline to answer. If you don't know the answer, say that you don't know; don't try to make up an answer. Keep the answer as concise as possible. Use the following pieces of context to answer the question at the end:
"""
model = QAChain()
prediction = model.predict(
[
{"query": "What is in MLflow 5.0"},
],
SYSTEM_PROMPT,
{
# Using Databricks Foundation Model for easier testing, feel free to replace it.
"model_name": "databricks-dbrx-instruct",
"temperature": 0.1,
"max_tokens": 1000,
}
)
MLflow 클라이언트 API
MlflowClient 세분화된 스레드-안전 API를 사용하여 추적을 시작하고 종료하며, 범위와 set 범위 필드를 관리합니다. 추적 수명 주기 및 구조를 완벽하게 제어할 수 있습니다. 이러한 API는 다중 스레드 애플리케이션 및 콜백과 같은 요구 사항에 Fluent API가 충분하지 않은 경우에 유용합니다.
다음은 MLflow 클라이언트를 사용하여 전체 추적을 만드는 단계입니다.
MLflowClient 인스턴스를
client = MlflowClient()에서 만듭니다.client.start_trace()메서드를 사용하여 추적을 시작합니다. 그러면 추적 컨텍스트가 시작되고 절대 루트 범위가 시작되며 루트 범위 개체가 반환됩니다. 이 메서드는start_span()API 전에 실행해야 합니다.-
Set 속성, 입력, 출력, 그리고
client.start_trace()에 대한 추적.
참고 항목
Fluent API의
start_trace()메서드와 동일한 항목이 없습니다. Fluent API는 추적 컨텍스트를 자동으로 초기화하고 관리되는 상태에 따라 루트 범위인지 여부를 결정하기 때문입니다.-
Set 속성, 입력, 출력, 그리고
start_trace() API는 범위를 반환합니다. 요청 ID, Get, 추적의 고유한 identifier,
trace_id, 그리고span.request_id및span.span_id를 사용하여 반환된 범위의 ID입니다.client.start_span(request_id, parent_id=span_id)부터 set까지 자식 범위를 시작하여 범위의 특성, 입력 및 출력을 지정하세요.- 이 메서드는
request_id과parent_id이 추적 계층에서 올바른 위치에 해당 범위를 연결하도록 요구합니다. 다른 범위 개체를 반환합니다.
- 이 메서드는
client.end_span(request_id, span_id)호출하여 자식 범위를 종료합니다.만들고자 하는 자식 범위에 대해 3-5단계를 반복합니다.
모든 자식 범위가 끝나면
client.end_trace(request_id)을 호출하여 추적을 종료하고 기록합니다.
from mlflow.client import MlflowClient
mlflow_client = MlflowClient()
root_span = mlflow_client.start_trace(
name="simple-rag-agent",
inputs={
"query": "Demo",
"model_name": "DBRX",
"temperature": 0,
"max_tokens": 200
}
)
request_id = root_span.request_id
# Retrieve documents that are similar to the query
similarity_search_input = dict(query_text="demo", num_results=3)
span_ss = mlflow_client.start_span(
"search",
# Specify request_id and parent_id to create the span at the right position in the trace
request_id=request_id,
parent_id=root_span.span_id,
inputs=similarity_search_input
)
retrieved = ["Test Result"]
# You must explicitly end the span
mlflow_client.end_span(request_id, span_id=span_ss.span_id, outputs=retrieved)
root_span.end_trace(request_id, outputs={"output": retrieved})
추적 검토
에이전트를 실행한 후 추적을 검토하려면 다음 옵션 중 하나를 사용합니다.
- 추적 시각화는 셀 출력에서 인라인으로 렌더링됩니다.
- 추적은 MLflow 실험에 기록됩니다. 실험 페이지의 추적 탭에서 역사적 기록의 전체 list을 검토하고 검색할 수 있습니다. 에이전트가 활성 MLflow의 Run에서 실행될 때, 추적은 Run 페이지에 나타납니다.
- search_traces() API를 사용하여 프로그래밍 방식으로 추적을 검색합니다.
프로덕션에서 MLflow 추적 사용
MLflow 추적은 Mosaic AI 모델 서비스와 통합되어 문제를 효율적으로 디버그하고, 성능을 모니터링하고, 오프라인 평가를 위한 골든 데이터 세트를 만들 수 있습니다. 서비스 엔드포인트에 대해 MLflow 트레이싱을 사용하도록 설정하면 추적이 responsecolumn아래의 추론 table 기록됩니다.
서비스 엔드포인트에 대해 MLflow 추적을 사용하도록 설정하려면 엔드포인트 구성에서 ENABLE_MLFLOW_TRACING 환경 변수를 True로 set 합니다. 사용자 지정 환경 변수를 사용하여 엔드포인트를 배포하는 방법을 알아보려면 일반 텍스트 환경 변수 추가를 참조하세요.
deploy() API를 사용하여 에이전트를 배포한 경우 추적이 유추 table에 자동으로 기록됩니다.
생성형 AI 응용 프로그램에 대한 에이전트 배포를 참조하세요.
참고 항목
table 추론에 대한 기록 작성을 비동기적으로 수행하므로 개발 중 노트북 환경에서와 같은 부담을 추가하지 않습니다. 그러나 특히 각 유추 요청의 추적 크기가 큰 경우 엔드포인트의 응답 속도에 약간의 오버헤드가 발생할 수 있습니다. Databricks는 환경 및 모델 구현에 크게 의존하므로 모델 엔드포인트에 대한 실제 대기 시간 영향에 대한 SLA(서비스 수준 계약)를 보장하지 않습니다. Databricks는 프로덕션 애플리케이션에 배포하기 전에 엔드포인트 성능을 테스트하고 추적 오버헤드에 대한 인사이트를 확보하는 것이 좋습니다.
다음 table는 다양한 추적 크기에 따른 유추 지연 시간에 미치는 영향을 대략적으로 보여줍니다.
| 요청당 추적 크기 | 대기 시간에 미치는 영향(ms) |
|---|---|
| ~10KB | ~1ms |
| ~1MB | 50~100ms |
| 10MB | 150ms~ |
제한 사항
- MLflow 추적은 Databricks Notebooks, Notebook 작업 및 모델 서비스에서 사용할 수 있습니다.
LangChain 자동 로깅은 모든 LangChain 예측 API를 지원하지 않을 수 있습니다. 지원되는 API의 전체