작업 영역 모델 레지스트리(레거시)를 사용하여 모델 수명 주기 관리
중요
이 설명서에서는 작업 영역 모델 레지스트리에 대해 설명합니다. 작업 영역이 Unity 카탈로그에 사용하도록 설정된 경우 이 페이지의 절차를 사용하지 마세요. 대신 Unity 카탈로그에서 모델을 참조하세요.
Unity 카탈로그로 작업 영역 모델 레지스트리를 업그레이드하는 방법에 대한 지침은 워크플로 및 모델을 Unity 카탈로그로 마이그레이션을 참조하세요.
작업 영역의 기본 카탈로그 Unity 카탈로그(hive_metastore대신)에 있고 Databricks Runtime 13.3 LTS 이상을 사용하여 클러스터를 실행하는 경우 모델은 구성 없이 작업 영역 기본 카탈로그에서 자동으로 만들어지고 로드됩니다. 이 경우 작업 영역 모델 레지스트리를 사용하려면 워크로드 시작 시 import mlflow; mlflow.set_registry_uri("databricks")을 실행하여 명시적으로 대상을 지정해야 합니다. 2024년 1월 이전에 Unity 카탈로그의 카탈로그로 기본 카탈로그를 구성하고 2024년 1월 이전에 작업 영역 모델 레지스트리를 사용한 적은 수의 작업 영역이 이 동작에서 제외되며 기본적으로 작업 영역 모델 레지스트리를 계속 사용합니다.
이 문서에서는 머신 러닝 워크플로의 일부로 워크스페이스 모델 레지스트리를 사용하여 ML 모델의 전 과정을 관리하는 방법을 설명합니다. 작업 영역 모델 레지스트리는 Databricks에서 제공하는 호스트된 MLflow 모델 레지스트리 버전입니다.
작업 영역 모델 레지스트리는 다음을 제공합니다.
- 시간순 모델 계보(MLflow 실험 및 실행에서 지정된 시간에 모델을 생성).
- 모델 서빙.
- 모델 버전 관리
- 스테이지 전환(예: 스테이징에서 프로덕션으로 또는 보관됨)
- 레지스트리 이벤트를 기반으로 작업을 자동으로 트리거할 수 있도록 웹후크
- 모델 이벤트의 메일 알림
모델 설명을 만들고 보고 메모를 남길 수도 있습니다.
이 문서에는 작업 영역 모델 레지스트리 UI와 작업 영역 모델 레지스트리 API에 대한 지침이 포함되어 있습니다.
작업 영역 모델 레지스트리 개념에 대한 개요는 MLflow를 통해 gen AI 에이전트 및 ML 모델 수명 주기을 참조하세요.
모델 만들기 또는 등록
UI를 사용하여 모델을 만들거나 등록할 수도 있고, API를 사용하여 모델을 등록할 수도 있습니다.
UI를 사용하여 모델 생성 또는 등록
작업 영역 모델 레지스트리에서는 두 가지 프로그래밍 방식으로 모델을 등록할 수 있습니다. MLflow에 기록된 기존 모델을 등록하거나 비어 있는 새 모델을 만들고 등록한 다음 이전에 기록된 모델을 할당할 수 있습니다.
Notebook에서 기록된 기존 모델 등록
작업 영역에서 등록하려는 모델을 포함하는 MLflow 실행을 식별합니다.
Notebook의 오른쪽 사이드바에서 실험 아이콘
 을 클릭합니다.
을 클릭합니다.
실험 실행 사이드바의 실행 날짜 옆에 있는
 아이콘을 클릭합니다. MLflow 실행 페이지가 표시됩니다. 이 페이지에는 매개 변수, 메트릭, 태그 및 아티팩트 목록을 포함한 실행 세부 정보가 표시됩니다.
아이콘을 클릭합니다. MLflow 실행 페이지가 표시됩니다. 이 페이지에는 매개 변수, 메트릭, 태그 및 아티팩트 목록을 포함한 실행 세부 정보가 표시됩니다.
아티팩트 섹션에서 xxx-model이라는 디렉터리를 클릭합니다.
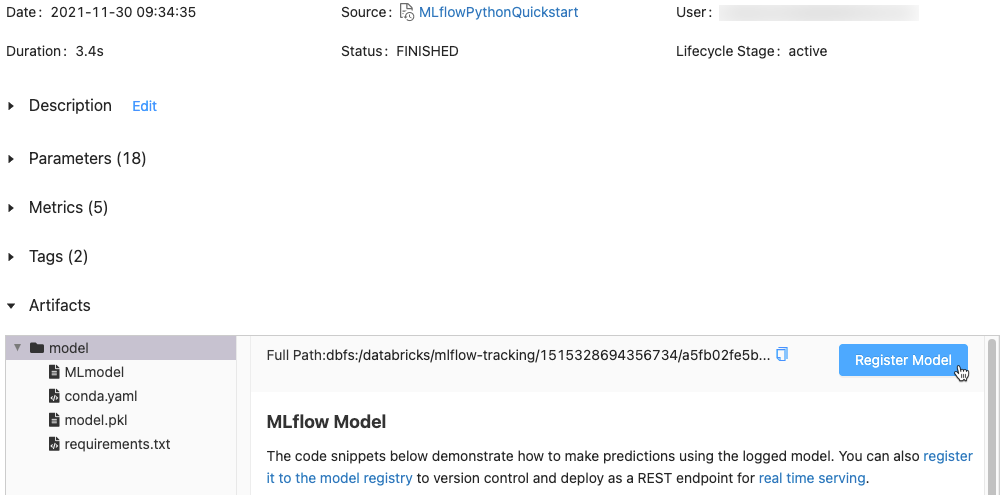
맨 오른쪽에 있는 모델 등록 단추를 클릭합니다.
대화 상자에서 모델 상자를 클릭하고 다음 중 하나를 수행합니다.
- 드롭다운 메뉴에서 새 모델 만들기 선택합니다.
모델 이름 필드가 나타납니다. 모델 이름(예:
scikit-learn-power-forecasting)을 입력합니다. - 드롭다운 메뉴에서 기존 모델을 선택합니다.
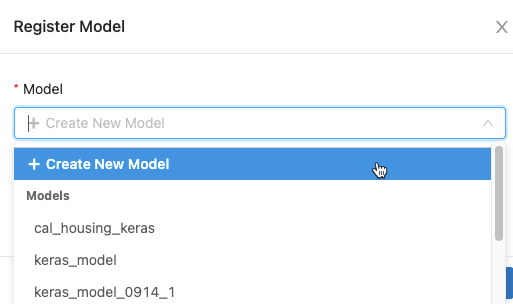
- 드롭다운 메뉴에서 새 모델 만들기 선택합니다.
모델 이름 필드가 나타납니다. 모델 이름(예:
등록을 클릭합니다.
-
새 모델 만들기를 선택한 경우
scikit-learn-power-forecasting이라는 모델이 등록되고 작업 영역 모델 레지스트리에서 관리하는 안전한 위치에 모델이 복사되고 모델의 새 버전이 만들어집니다. - 기존 모델을 선택한 경우 선택한 모델의 새 버전을 등록합니다.
잠시 후 모델 등록 단추가 새로 등록된 모델 버전에 대한 링크로 변경됩니다.
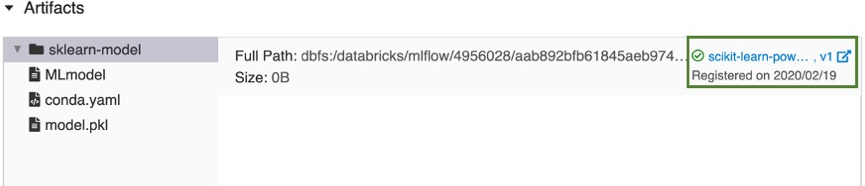 선택
선택-
새 모델 만들기를 선택한 경우
작업 영역 모델 레지스트리 UI에서 새 모델 버전을 열려면 링크를 클릭합니다. 사이드바에서
 모델을 클릭하여 작업 영역 모델 레지스트리에서 모델을 찾을 수도 있습니다.
모델을 클릭하여 작업 영역 모델 레지스트리에서 모델을 찾을 수도 있습니다.
새로 등록된 모델을 생성하고 기록된 모델을 할당하십시오.
등록된 모델 페이지의 모델 만들기 단추를 사용하여 비어 있는 새 모델을 만든 다음 로그된 모델을 할당할 수 있습니다. 다음 단계를 수행합니다.
등록된 모델 페이지에서 모델 만들기를 클릭합니다. 모델 이름을 입력하고 만들기를 클릭합니다.
Notebook에서 기존 로깅된 모델 등록의 1~3단계를 수행합니다.
모델 등록 대화 상자에서 1단계에서 만든 모델의 이름을 선택하고 등록을 클릭합니다. 이렇게 하면 사용자가 만든 이름으로 모델이 등록되고, Workspace Model Registry에서 관리하는 안전한 위치로 모델이 복사되고, 모델 버전
Version 1이 생성됩니다.잠시 후 MLflow 실행 UI가 [모델 등록] 단추를 새로 등록된 모델 버전의 링크로 바꿉니다. 이제 모델 등록 대화 상자에서 모델 드롭다운 목록을 통해 모델을 선택할 수 있으며, 이는 실험 실행 페이지에서 가능합니다. Create ModelVersion과 같은 API 명령에 이름을 지정하여 모델의 새 버전을 등록할 수도 있습니다.
API를 사용하여 모델 등록
작업 영역 모델 레지스트리에서는 세 가지 프로그래밍 방식으로 모델을 등록할 수 있습니다. 모든 메서드는 모델을 작업 영역 모델 레지스트리가 관리하는 안전한 위치에 복사합니다.
MLflow 실험 중에 모델을 기록하고 지정된 이름으로 등록하려면
mlflow.<model-flavor>.log_model(...)메서드를 사용합니다. 이름이 있는 등록 모델이 없는 경우 이 메서드는 새 모델을 등록하고, 버전 1을 만들고ModelVersionMLflow 개체를 반환합니다. 이름이 있는 등록 모델이 이미 있는 경우 이 메서드는 새 모델 버전을 만들고 버전 개체를 반환합니다.with mlflow.start_run(run_name=<run-name>) as run: ... mlflow.<model-flavor>.log_model(<model-flavor>=<model>, artifact_path="<model-path>", registered_model_name="<model-name>" )모든 실험이 완료된 후 지정된 이름으로 모델을 등록하고 레지스트리에 추가하는 데 가장 적합한 모델을 결정하려면
mlflow.register_model()메서드를 사용합니다. 이 메서드에는mlruns:URI인수에 대한 실행 ID가 필요합니다. 이름이 있는 등록 모델이 없는 경우 이 메서드는 새 모델을 등록하고, 버전 1을 만들고ModelVersionMLflow 개체를 반환합니다. 이름이 있는 등록 모델이 이미 있는 경우 이 메서드는 새 모델 버전을 만들고 버전 개체를 반환합니다.result=mlflow.register_model("runs:<model-path>", "<model-name>")지정된 이름으로 새로 등록된 모델을 만들려면 MLflow 클라이언트 API
create_registered_model()메서드를 사용합니다. 모델 이름이 있는 경우 이 메서드는MLflowException를 throw합니다.client = MlflowClient() result = client.create_registered_model("<model-name>")
Databricks Terraform 공급자 및 databricks_mlflow_model을 사용하여 모델을 등록할 수도 있습니다.
할당량 한도
모든 Databricks 작업 영역에 대해 2024년 5월부터 작업 영역 모델 레지스트리는 작업 영역당 등록된 모델 및 모델 버전의 총 수에 할당량 제한을 적용합니다. 리소스 한도를 참조하세요. 레지스트리 할당량을 초과하는 경우 Databricks는 더 이상 필요하지 않은 등록된 모델 및 모델 버전을 삭제하는 것이 좋습니다. Databricks는 또한 제한을 초과하지 않도록 모델 등록 및 보존 전략을 조정하는 것이 좋다고 권장합니다. 작업 영역 제한을 늘려야 하는 경우 Databricks 계정 팀에 문의하세요.
다음 노트북에서는 모델 레지스트리 항목을 목록화하고 삭제하는 방법을 보여 줍니다.
인벤토리 모델 레지스트리의 작업 영역 엔터티 노트북
노트북 가져오기
UI에서 모델 보기
등록된 모델 페이지
등록된 모델 페이지는 사이드바에서 ![]() 모델을 클릭하면 표시됩니다. 이 페이지에는 레지스트리의 모든 모델이 표시됩니다.
모델을 클릭하면 표시됩니다. 이 페이지에는 레지스트리의 모든 모델이 표시됩니다.
이 페이지에서 새 모델을 만들 수 있습니다.
또한 이 페이지에서 작업 영역 관리자는 작업 영역 모델 레지스트리모든 모델에 대한 사용 권한을

등록된 모델 페이지
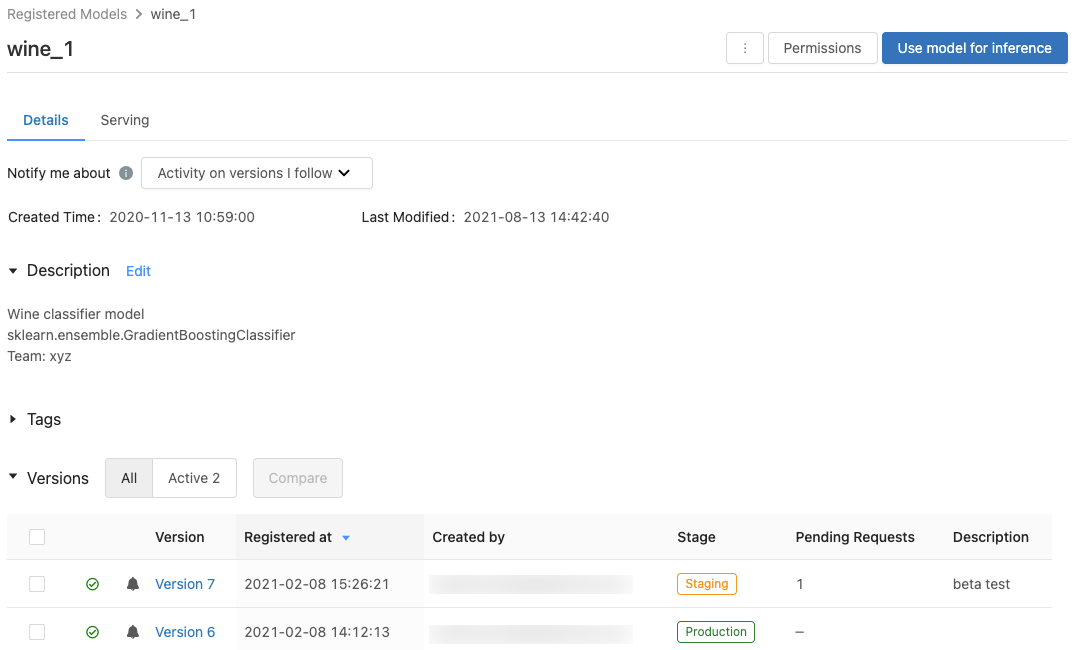
모델에 대해 등록된 모델 페이지를 표시하려면 등록된 모델 페이지에서 모델 이름을 클릭합니다. 등록된 모델 페이지에는 선택한 모델에 대한 정보와 모델의 각 버전에 대한 정보가 포함된 테이블이 표시됩니다. 이 페이지에서 다음을 수행할 수도 있습니다.
모델 버전 페이지
모델 버전 페이지를 보려면 다음 중 하나를 수행합니다.
- 등록된 모델 페이지의 최신 버전 열에서 버전 이름을 클릭합니다.
- 등록된 모델 페이지의 버전 열에서 버전 이름을 클릭합니다.
이 페이지에는 등록된 모델의 특정 버전에 대한 정보가 표시되고 원본 실행(모델을 만들기 위해 실행된 Notebook 버전) 링크도 제공합니다. 이 페이지에서 다음을 수행할 수도 있습니다.
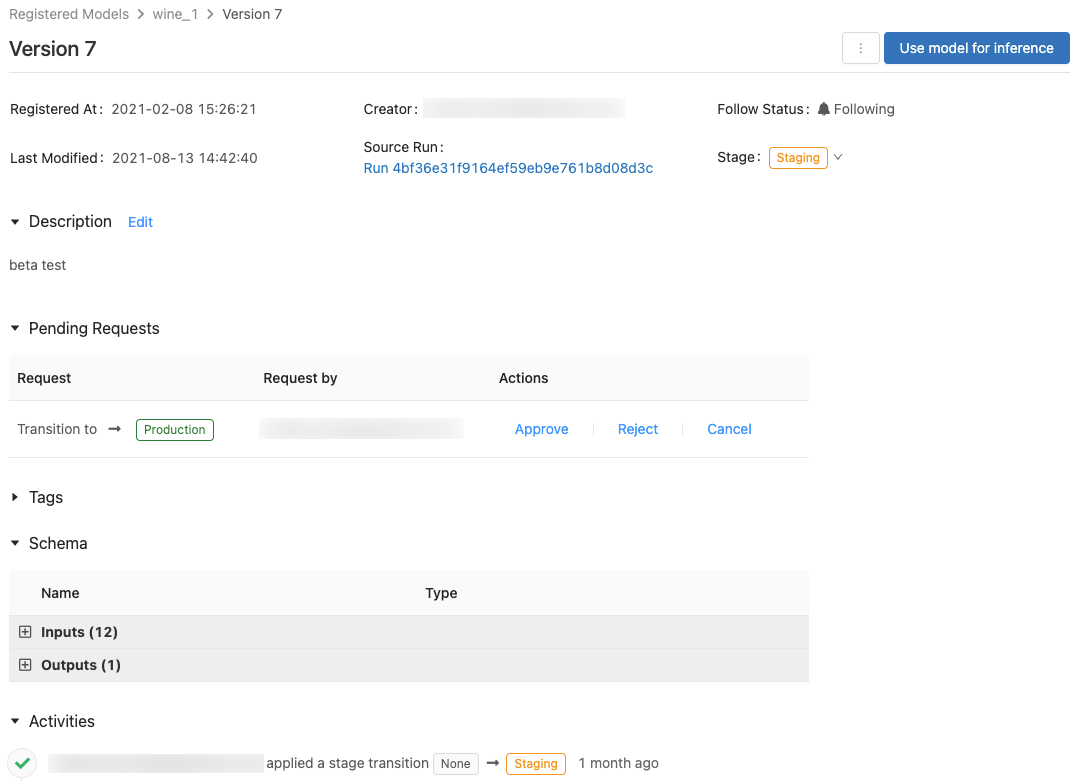
모델에 대한 액세스 제어
모델에 대한 사용 권한을 구성하려면 최소한 CAN MANAGE 권한이 있어야 합니다. 모델 권한 수준에 대한 자세한 내용은 MLflow 모델 ACL을 참조 하세요. 모델 버전은 부모 모델에서 사용 권한을 상속합니다. 모델 버전에 대한 사용 권한을 설정할 수 없습니다.
사이드바에서
모델을 클릭합니다.모델 이름을 선택합니다.
사용 권한을 클릭합니다. 권한 설정 대화 상자가 열립니다.

대화 상자에서 '사용자, 그룹 또는 서비스 주체 선택' 드롭다운을 클릭하고 사용자, 그룹 또는 서비스 주체를 선택합니다.
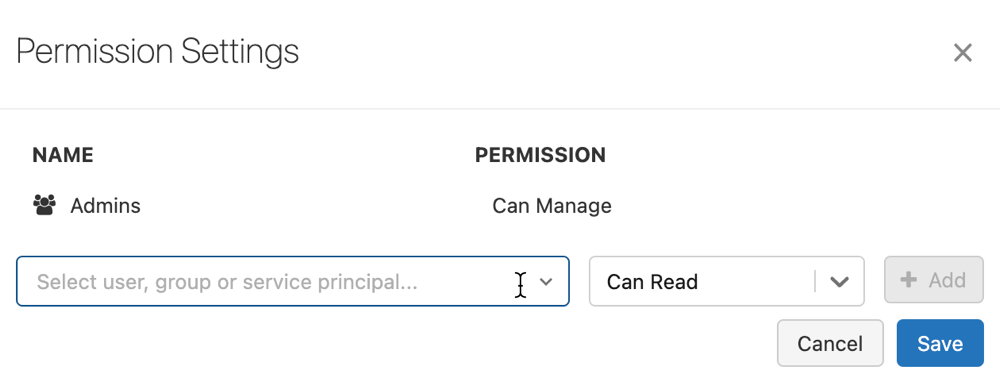
권한 드롭다운에서 사용 권한을 선택합니다.
추가를 클릭하고 저장을 클릭합니다.
레지스트리 수준 수준에서 CAN MANAGE 권한이 있는 작업 영역 관리자 및 사용자는 모델 페이지에서 사용 권한 클릭하여 작업 영역의 모든 모델에 대한 사용 권한 수준을 설정할 수 있습니다.
모델 단계 전환
모델 버전에는 없음, 스테이징, 프로덕션 또는 보관 단계 중 하나가 있습니다. 스테이징 단계는 모델 테스트와 검증을 위한 것이고, 프로덕션 단계는 테스트나 검토 프로세스를 완료하고 라이브 스코어링을 위해 애플리케이션에 배포된 모델 버전을 위한 것입니다. 보관된 모델 버전은 비활성 상태인 것으로 간주되며, 이 시점에서 삭제할 것을 고려할 수 있습니다. 모델의 다른 버전은 서로 다른 단계에 있을 수 있습니다.
적절한 사용 권한이 있는 사용자는 단계 간에 모델 버전을 전환할 수 있습니다. 모델 버전을 특정 단계로 전환할 수 있는 권한이 있는 경우 직접 전환할 수 있습니다. 권한이 없는 경우 스테이지 전환을 요청할 수 있으며 모델 버전을 전환할 수 있는 권한이 있는 사용자는 요청을 승인, 거부 또는 취소할 수 있습니다.
UI를 사용하거나 API를 사용하여 모델 스테이지를 전환할 수 있습니다.
UI를 사용하여 모델 스테이지 전환
이 지침에 따라 모델의 스테이지를 전환합니다.
사용 가능한 모델 단계 및 사용 가능한 옵션 목록을 표시하려면 모델 버전 페이지에서 스테이지 옆의 드롭다운을 클릭하고 다른 스테이지로의 전환을 요청하거나 선택합니다.
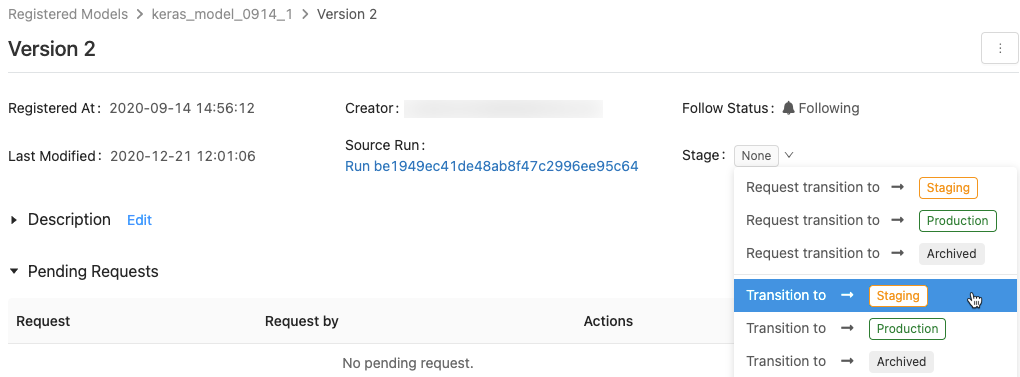
선택적 설명을 입력하고 확인을 클릭합니다.
모델 버전을 프로덕션 단계로 전환
테스트 및 유효성 검사 후에 프로덕션 단계로 전환하거나 전환을 요청할 수 있습니다.
작업 영역 모델 레지스트리는 각 스테이지에서 등록된 여러 버전의 모델을 허용합니다. 프로덕션에서 하나의 버전만 사용하려는 경우 기존 프로덕션 모델 버전을 보관으로 전환하여 현재 프로덕션에 있는 모델의 모든 버전을 보관으로 전환할 수 있습니다.
모델 버전 스테이지 전환 요청 승인 또는 거부
스테이지 전환 권한이 없는 사용자는 스테이지 전환을 요청할 수 있습니다. 요청은 모델 버전 페이지의 보류 중인 요청 섹션에 표시됩니다.

스테이지 전환 요청을 승인, 거부 또는 취소하려면 승인, 거부 또는 취소 링크를 클릭합니다.
전환 요청 작성자도 요청을 취소할 수 있습니다.
모델 버전 활동 보기
모델 버전에 요청, 승인, 보류 및 적용된 모든 전환을 보려면 작업 섹션으로 이동합니다. 이 활동 레코드는 감사 또는 검사를 위해 모델의 수명 주기 계보를 제공합니다.
API를 사용하여 모델 스테이지 전환
적절한 사용 권한이 있는 사용자는 모델 버전을 새 단계로 전환할 수 있습니다.
모델 버전 단계를 새 단계로 업데이트하려면 MLflow 클라이언트 API transition_model_version_stage() 메서드를 사용합니다.
client = MlflowClient()
client.transition_model_version_stage(
name="<model-name>",
version=<model-version>,
stage="<stage>",
description="<description>"
)
<stage> 허용되는 값은 "Staging"|"staging", "Archived"|"archived", "Production"|"production", "None"|"none".
유추에 모델 사용
중요
이 기능은 공개 미리 보기 상태입니다.
모델이 워크스페이스 모델 레지스트리에 등록되면 배치 또는 스트리밍 추론에 모델을 사용하는 노트북을 자동으로 생성할 수 있습니다. 또는 모델 서비스 제공을 사용하여 모델을 실시간 제공하는 엔드포인트를 만들 수 있습니다.
등록된 모델 페이지 또는 모델 버전 페이지의 오른쪽 위 모서리에서  을 클릭합니다. 일괄 처리, 스트리밍 또는 실시간 유추를 구성할 수 있는 모델 유추 구성 대화 상자가 나타납니다.
을 클릭합니다. 일괄 처리, 스트리밍 또는 실시간 유추를 구성할 수 있는 모델 유추 구성 대화 상자가 나타납니다.
중요한
Anaconda Inc.는 anaconda.org 채널에 대한 서비스 약관을 업데이트했습니다. 새로운 서비스 약관에 따라 Anaconda의 패키지 및 배포에 의존하는 경우 상용 라이선스가 필요할 수 있습니다. 자세한 내용은 Anaconda Commercial Edition FAQ를 참조하세요. Anaconda 채널의 사용은 해당 서비스 약관에 따라 관리됩니다.
v1.18 이전에 기록된 MLflow 모델(Databricks Runtime 8.3 ML 이하)은 기본적으로 conda defaults 채널(https://repo.anaconda.com/pkgs/)을 종속성으로 로깅했습니다. 이 라이선스 변경으로 인해 Databricks는 MLflow v1.18 이상을 사용하여 기록된 모델에 대한 채널 defaults 사용을 중지했습니다. 로깅된 기본 채널은 이제 conda-forge(으)로, 관리되는 커뮤니티 https://conda-forge.org/를 가리킵니다.
모델에 대한 conda 환경에서 defaults 채널을 제외하지 않고 MLflow v1.18 이전 모델을 로깅한 경우 해당 모델은 의도하지 않았을 수 있는 defaults 채널에 대한 종속성을 가질 수 있습니다.
모델에 이 종속성이 있는지 여부를 수동으로 확인하려면 기록된 모델로 패키지된 channel 파일의 conda.yaml 값을 검사할 수 있습니다. 예를 들어 conda.yaml 채널 종속성이 있는 모델의 defaults 모양은 다음과 같습니다.
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Databricks는 Anaconda와의 관계에서 Anaconda 리포지토리를 사용하여 모델과 상호 작용하는 것이 허용되는지 여부를 확인할 수 없으므로 Databricks는 고객이 변경하도록 강요하지 않습니다. Databricks 사용을 통한 Anaconda.com 리포지토리 사용이 Anaconda의 조건에 따라 허용되는 경우 어떠한 조치도 취할 필요가 없습니다.
모델 환경에서 사용되는 채널을 변경하려는 경우 새 conda.yaml을(를) 사용하여 작업 영역 모델 레지스트리에 모델을 다시 등록할 수 있습니다.
conda_env의 log_model() 매개 변수에 채널을 지정하여 이 작업을 수행할 수 있습니다.
log_model() API에 대한 자세한 내용은 작업 중인 모델 버전에 대한 MLflow 설명서(예: scikit-learn용 log_model)를 참조하세요.
conda.yaml 파일에 대한 자세한 내용은 MLflow 설명서를 참조하세요.
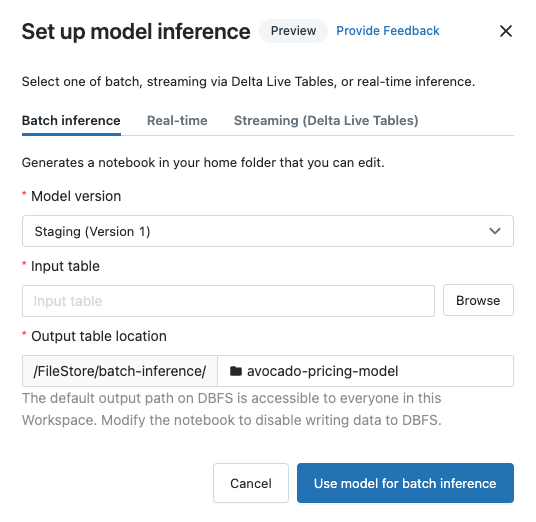
일괄 처리 추론 구성
다음 단계에 따라 배치 추론 노트북을 만들면, 노트북은 모델 이름이 있는 폴더의 Batch-Inference 폴더 아래에 있는 사용자 폴더에 저장됩니다. 필요한 경우 Notebook을 편집할 수 있습니다.
일괄 처리 유추 탭을 클릭합니다.
모델 버전 드롭다운에서 사용할 모델 버전을 선택합니다. 드롭다운의 처음 두 항목은 모델의 현재 프로덕션 및 스테이징 버전입니다(있는 경우). 이러한 옵션 중 하나를 선택하면 노트북은 실행 시점에 프로덕션 또는 스테이징 버전을 자동으로 사용합니다. 모델을 계속 개발할 때 노트북을 업데이트할 필요가 없습니다.
입력 테이블옆에 있는 찾아보기 단추를 클릭합니다. 입력 데이터 선택 대화 상자가 나타납니다. 필요한 경우 컴퓨팅 드롭다운에서 클러스터를 변경할 수 있습니다.
참고
Unity 카탈로그 사용 작업 영역의 경우 입력 데이터 선택 대화 상자를 사용하면
<catalog-name>.<database-name>.<table-name>세 가지 수준 중에서 선택할 수 있습니다.모델의 입력 데이터가 포함된 테이블을 선택하고 선택을 클릭합니다. 생성된 Notebook은 이 데이터를 자동으로 가져와서 모델로 보냅니다. 데이터가 모델에 입력되기 전에 변환이 필요한 경우 생성된 Notebook을 편집할 수 있습니다.
예측은
dbfs:/FileStore/batch-inference디렉터리의 폴더에 저장됩니다. 기본적으로 예측은 모델과 이름이 같은 폴더에 저장됩니다. 생성된 Notebook의 각 실행은 이름에 타임스탬프가 추가된 새 파일을 이 디렉터리에 씁니다. 타임스탬프를 포함하지 않고 Notebook의 후속 실행으로 파일을 덮어쓰도록 선택할 수도 있습니다. 지침은 생성된 Notebook에 제공됩니다.새 폴더 이름을 출력 테이블 위치 필드에 입력하거나 폴더 아이콘을 클릭하여 디렉터리를 찾아 다른 폴더를 선택하여 예측이 저장되는 폴더를 변경할 수 있습니다.
Unity 카탈로그의 특정 위치에 예측을 저장하려면 노트북을 편집해야 합니다. Unity Catalog에서 데이터를 사용하는 머신 러닝 모델을 학습시키고 그 결과를 Unity Catalog에 다시 쓰는 방법을 보여주는 예제 노트북은 Machine Learning 튜토리얼을 참조하세요.
DLT를 사용하여 스트리밍 유추 구성
다음 단계에 따라 스트리밍 추론 노트북을 만들면, 그 노트북은 모델 이름을 가진 폴더의 DLT-Inference 폴더 아래에 있는 사용자 폴더에 저장됩니다. 필요한 경우 Notebook을 편집할 수 있습니다.
DLT(스트리밍) 탭을 클릭합니다.
모델 버전 드롭다운에서 사용할 모델 버전을 선택합니다. 드롭다운의 처음 두 항목은 모델의 현재 프로덕션 및 스테이징 버전입니다(있는 경우). 이러한 옵션 중 하나를 선택하면 노트북은 실행 시점에 프로덕션 또는 스테이징 버전을 자동으로 사용합니다. 모델을 계속 개발할 때 노트북을 업데이트할 필요가 없습니다.
입력 테이블옆에 있는 찾아보기 단추를 클릭합니다. 입력 데이터 선택 대화 상자가 나타납니다. 필요한 경우 컴퓨팅 드롭다운에서 클러스터를 변경할 수 있습니다.
참고
Unity 카탈로그 사용 작업 영역의 경우 입력 데이터 선택 대화 상자를 사용하면
<catalog-name>.<database-name>.<table-name>세 가지 수준 중에서 선택할 수 있습니다.모델의 입력 데이터가 포함된 테이블을 선택하고 선택을 클릭합니다. 생성된 Notebook은 입력 테이블을 원본으로 사용하는 데이터 변환을 만들고, MLflow PySpark 추론 UDF을 통합하여 모델 예측을 수행합니다. 모델 적용 전 또는 후에 데이터를 추가로 변환해야 하는 경우 생성된 Notebook을 편집할 수 있습니다.
출력 DLT 이름을 제공합니다. Notebook은 지정된 이름의 라이브 테이블을 만들고 이를 사용하여 모델 예측을 저장합니다. 생성된 Notebook을 수정하여 필요에 따라 대상 데이터 세트를 사용자 지정할 수 있습니다. 예를 들어 스트리밍 라이브 테이블을 출력으로 정의하고 스키마 정보 또는 데이터 품질 제약 조건을 추가할 수 있습니다.
그런 다음 이 Notebook을 사용하여 새 DLT 파이프라인을 만들거나 기존 파이프라인에 추가 Notebook 라이브러리로 추가할 수 있습니다.
실시간 유추 구성
모델 서비스 제공은 MLflow 기계 학습 모델을 확장 가능한 REST API 엔드포인트로 노출합니다. 모델 서비스 엔드포인트를 만들려면 엔드포인트를 제공하는 사용자 지정 모델 만들기를 참조하세요.
피드백 제공
이 기능은 미리 보기로 제공되며 피드백을 받고 싶습니다. 피드백을 제공하려면 모델 유추 구성 대화 상자에서 Provide Feedback을 클릭합니다.
모델 버전 비교
작업 영역 모델 레지스트리에서 모델 버전을 비교할 수 있습니다.
- "에 등록된 모델 페이지에서, 모델 버전 왼쪽의 확인란을 클릭하여 두 개 이상의 모델 버전을 선택하십시오."
- 비교를 클릭합니다.
- 선택한 모델 버전의 매개 변수, 스키마 및 메트릭을 비교하는 테이블을 보여 주는
<N>버전 비교 화면이 나타납니다. 화면 아래쪽에서 플롯 유형(분산형, 윤곽선 또는 병렬 좌표)과 그릴 매개 변수 또는 메트릭을 선택할 수 있습니다.
알림 기본 설정 제어
지정한 등록된 모델 및 모델 버전에 대한 활동에 대해 이메일로 알리도록 작업 영역 모델 레지스트리를 구성할 수 있습니다.
등록된 모델 페이지의 알림 메뉴에는 다음 세 가지 옵션이 표시됩니다.
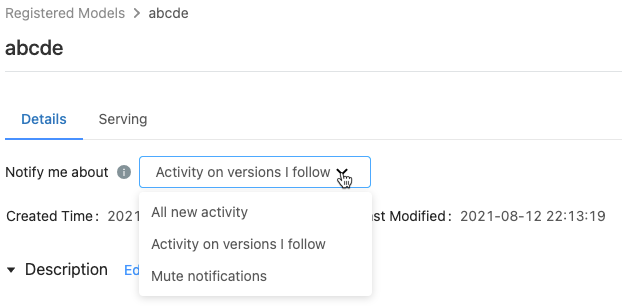
- 모든 새 활동: 이 모델의 모든 모델 버전에서 모든 활동에 대한 메일 알림 보냅니다. 등록된 모델을 만든 경우 이 설정이 기본값입니다.
- 팔로우하는 버전에 대한 작업: 팔로우하는 모델 버전에 대해서만 메일 알림 보냅니다. 이 옵션을 선택하면 팔로우하는 모든 모델 버전에 대한 알림이 표시됩니다. 특정 모델 버전에 대한 알림을 끌 수 없습니다.
- 알림 음소거: 이 등록된 모델의 활동에 대한 이메일 알림을 보내지 않습니다.
다음 이벤트는 이메일 알림을 트리거합니다.
- 새 모델 버전 만들기
- 스테이지 전환 요청
- 장면 전환
- 새 주석
다음 중 한 가지 작업을 수행하면 모델 알림이 자동으로 구독됩니다.
- 해당 모델 버전에 대한 댓글
- 모델 버전의 단계를 변경하다
- 모델 단계에 대한 전환 요청 만들기
모델 버전을 따르고 있는지 확인하려면 모델 버전 페이지에서 팔로우 상태 필드를 확인하거나, 등록된 모델 페이지의 모델 버전 테이블에서 확인하세요.
모든 메일 알림 끄기
사용자 설정 메뉴의 작업 영역 모델 레지스트리 설정 탭에서 메일 알림 해제할 수 있습니다.
- Azure Databricks 작업 영역의 오른쪽 위 모서리에서 사용자 이름을 클릭하고 드롭다운 메뉴에서 설정 선택합니다.
- 설정 사이드바에서 알림을 선택합니다.
- 모델 레지스트리 이메일 알림을 끕니다.
계정 관리자는 관리자 설정 페이지에서 전체 조직에 대한 메일 알림 해제할 수 있습니다.
보낸 최대 전자 메일 수
작업 영역 모델 레지스트리는 활동 당 하루에 각 사용자에게 보내는 이메일 수를 제한합니다. 예를 들어 등록된 모델에 대해 만들어진 새 모델 버전에 대해 하루에 20개의 이메일을 받는 경우 작업 영역 모델 레지스트리는 일별 제한에 도달했음을 나타내는 이메일을 보내며 해당 이벤트에 대한 추가 전자 메일은 다음 날까지 전송되지 않습니다.
허용되는 전자 메일 수의 제한을 늘리려면 Azure Databricks 계정 팀에 문의하세요.
웹후크
중요한
이 기능은 공개 미리 보기 상태입니다.
Webhook를 사용하면 통합에서 작업을 자동으로 트리거할 수 있도록 작업 영역 모델 레지스트리 이벤트를 수신 대기할 수 있습니다. 웹후크를 사용하여 기계 학습 파이프라인을 자동화하고 기존 CI/CD 도구 및 워크플로와 통합할 수 있습니다. 예를 들어 새 모델 버전을 만들 때 CI 빌드를 트리거하거나 프로덕션으로의 모델 전환을 요청할 때마다 Slack을 통해 팀 구성원에게 알릴 수 있습니다.
모델 또는 모델 버전에 주석 달기
주석을 추가하여 모델이나 모델 버전에 대한 정보를 제공할 수 있습니다. 예를 들어, 문제의 개요나 사용된 방법 및 알고리즘에 대한 정보를 포함하는 것이 좋습니다.
UI를 사용하여 모델 또는 모델 버전에 주석 달기
Azure Databricks UI는 모델 및 모델 버전에 주석을 추가하는 여러 가지 방법을 제공합니다. 설명 또는 주석을 사용하여 텍스트 정보를 추가할 수 있으며 검색 가능한 키-값 태그를 추가할 수 있습니다. 설명 및 태그는 모델 및 모델 버전에 사용할 수 있으며 댓글은 모델 버전에만 사용할 수 있습니다.
- 설명은 모델에 대한 정보를 제공하기 위한 것입니다.
- 주석은 모델 버전의 활동에 대한 지속적인 논의를 유지하는 방법을 제공합니다.
- 태그를 사용하면 모델 메타데이터를 사용자 지정하여 특정 모델을 더 쉽게 찾을 수 있습니다.
모델 또는 모델 버전에 대한 설명 추가 또는 업데이트
편집 창에서 설명을 입력하거나 편집합니다.
저장을 클릭하여 변경 내용을 저장하거나 취소하여 창을 닫습니다.
모델 버전에 대한 설명을 입력한 경우 등록된 모델 페이지테이블의 설명 열에 설명이 나타납니다. 열에는 최대 32자 또는 한 줄의 텍스트가 표시되며 그 중 더 짧습니다.
모델 버전에 대한 주석을 추가합니다.
- 모델 버전 페이지를 아래로 스크롤하고 활동 옆의 아래쪽 화살표를 클릭합니다.
- 편집 창에 메모를 입력하고 메모 추가클릭합니다.
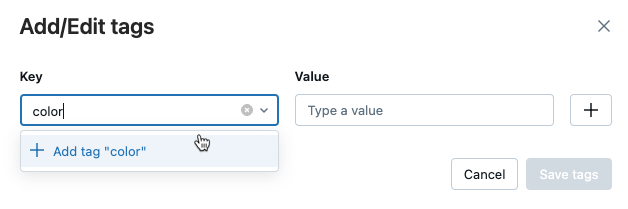
모델 또는 모델 버전에 대한 태그 추가
등록된 모델 또는 모델 버전 페이지에서 아직 열려 있지 않은 경우
 을 클릭합니다. 태그 테이블이 나타납니다.
을 클릭합니다. 태그 테이블이 나타납니다.
이름 및 값 필드를 클릭하고 태그의 키와 값을 입력합니다.
추가를 클릭합니다.
모델 또는 모델 버전의 태그 편집 또는 삭제
기존 태그를 편집하거나 삭제하려면 Actions 열의 아이콘을 사용합니다.

API를 사용하여 모델 버전에 주석 달기
모델 버전 설명을 업데이트하려면 MLflow 클라이언트 API update_model_version() 메서드를 사용합니다.
client = MlflowClient()
client.update_model_version(
name="<model-name>",
version=<model-version>,
description="<description>"
)
등록된 모델 또는 모델 버전에 대한 태그를 설정하거나 업데이트하려면 MLflow 클라이언트 API set_registered_model_tag()) 또는 set_model_version_tag() 메서드를 사용합니다.
client = MlflowClient()
client.set_registered_model_tag()(
name="<model-name>",
key="<key-value>",
tag="<tag-value>"
)
client = MlflowClient()
client.set_model_version_tag()(
name="<model-name>",
version=<model-version>,
key="<key-value>",
tag="<tag-value>"
)
모델 이름 바꾸기(API에만 해당)
등록된 모델의 이름을 바꾸려면 MLflow 클라이언트 API rename_registered_model() 메서드를 사용합니다.
client=MlflowClient()
client.rename_registered_model("<model-name>", "<new-model-name>")
참고
등록된 모델은 버전이 없거나 모든 버전이 [없음] 또는 [보관됨] 스테이지에 있는 경우에만 이름을 바꿀 수 있습니다.
모델 검색
UI 또는 API를 사용하여 작업 영역 모델 레지스트리의 모델을 검색할 수 있습니다.
참고
모델을 검색하면 ‘읽기 가능’ 권한 이상이 있는 모델만 반환됩니다.
UI를 사용하여 모델 검색
등록된 모든 모델을 표시하려면 사이드바에서 ![]() 모델을 클릭합니다.
모델을 클릭합니다.
특정 모델을 검색하려면 검색 상자에 텍스트를 입력합니다. 모델 이름 또는 이름의 일부를 입력할 수 있습니다.
태그에서 검색할 수도 있습니다.
tags.<key>=<value> 형식으로 태그를 입력합니다. 여러 태그를 검색하려면 AND 연산자를 사용합니다.

MLflow 검색 구문을 사용하여 모델 이름과 태그를 모두 검색할 수 있습니다. 예시:

API를 사용하여 모델 검색
MLflow 클라이언트 API 메서드 search_registered_models()를 사용하여 작업 영역 모델 레지스트리에 등록된 모델을 검색할 수 있습니다.
모델에 태그이 설정되어 있는 경우, search_registered_models()를 사용하여 해당 태그로 검색할 수도 있습니다.
print(f"Find registered models with a specific tag value")
for m in client.search_registered_models(f"tags.`<key-value>`='<tag-value>'"):
pprint(dict(m), indent=4)
MLflow 클라이언트 API search_model_versions() 메서드를 사용하여 특정 모델 이름을 검색하고 해당 버전 세부 정보를 나열할 수도 있습니다.
from pprint import pprint
client=MlflowClient()
[pprint(mv) for mv in client.search_model_versions("name='<model-name>'")]
출력은 다음과 같습니다.
{ 'creation_timestamp': 1582671933246,
'current_stage': 'Production',
'description': 'A random forest model containing 100 decision trees '
'trained in scikit-learn',
'last_updated_timestamp': 1582671960712,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'ae2cc01346de45f79a44a320aab1797b',
'source': './mlruns/0/ae2cc01346de45f79a44a320aab1797b/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': None,
'version': 1 }
{ 'creation_timestamp': 1582671960628,
'current_stage': 'None',
'description': None,
'last_updated_timestamp': 1582671960628,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'd994f18d09c64c148e62a785052e6723',
'source': './mlruns/0/d994f18d09c64c148e62a785052e6723/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': None,
'version': 2 }
모델 및 모델 버전 삭제
UI 또는 API를 사용하여 모델을 삭제할 수 있습니다.
UI를 사용하여 모델 버전 또는 모델 삭제
경고
이 작업은 실행 취소할 수 없습니다. 모델 버전을 레지스트리에서 삭제하지 않고 보관된 단계로 전환할 수 있습니다. 모델을 삭제하면 작업 영역 모델 레지스트리에 저장된 모든 모델 아티팩트와 등록된 모델과 연결된 모든 메타데이터가 삭제됩니다.
참고
없음 또는 보관된 단계에서만 모델 및 모델 버전을 삭제할 수 있습니다. 등록된 모델에 스테이징 또는 프로덕션 단계의 버전이 있는 경우 모델을 삭제하기 전에 해당 버전을 없음 또는 보관된 스테이지로 전환해야 합니다.
모델 버전을 삭제하는 방법:
- 사이드바에서 모델을 클릭합니다.
- 모델 이름을 클릭합니다.
- 모델 버전을 클릭합니다.
- 화면의 오른쪽 위 모서리에 있는 kebab 메뉴
 클릭하고 드롭다운 메뉴에서 삭제를 선택합니다.
클릭하고 드롭다운 메뉴에서 삭제를 선택합니다.
모델을 삭제하려면:
- 사이드바에서 모델을 클릭합니다.
- 모델 이름을 클릭합니다.
- 화면의 오른쪽 위 모서리에 있는 kebab 메뉴 클릭하고 드롭다운 메뉴에서 삭제를 선택합니다.
API를 사용하여 모델 버전 또는 모델 삭제
경고
이 작업은 실행 취소할 수 없습니다. 모델 버전을 레지스트리에서 삭제하지 않고 보관된 단계로 전환할 수 있습니다. 모델을 삭제하면 작업 영역 모델 레지스트리에 저장된 모든 모델 아티팩트와 등록된 모델과 연결된 모든 메타데이터가 삭제됩니다.
참고
없음 또는 보관된 단계에서만 모델 및 모델 버전을 삭제할 수 있습니다. 등록된 모델에 스테이징 또는 프로덕션 단계의 버전이 있는 경우 모델을 삭제하기 전에 해당 버전을 없음 또는 보관된 스테이지로 전환해야 합니다.
모델 버전 삭제
모델 버전을 삭제하려면 MLflow 클라이언트 API delete_model_version() 메서드를 사용합니다.
# Delete versions 1,2, and 3 of the model
client = MlflowClient()
versions=[1, 2, 3]
for version in versions:
client.delete_model_version(name="<model-name>", version=version)
모델 삭제
모델을 삭제하려면 MLflow 클라이언트 API delete_registered_model() 메서드를 사용합니다.
client = MlflowClient()
client.delete_registered_model(name="<model-name>")
작업 영역에서 모델 공유
Databricks는 Unity 카탈로그 내의
그러나 작업 영역 모델 레지스트리를 사용하는 경우 일부 설정을 사용하여 여러 작업 영역에서 모델을 공유할 수도 있습니다 . 예를 들어 자체 작업 영역에서 모델을 개발하고 기록한 다음, 다른 작업 영역에서 원격 작업 영역 모델 레지스트리를 사용하여 이 모델에 액세스할 수 있습니다. 이는 여러 팀이 모델에 대한 액세스를 공유하는 경우에 유용합니다. 여러 작업 영역을 만들고 이러한 환경에서 모델을 사용하고 관리할 수 있습니다.
작업 영역 간에 MLflow 개체 복사
Azure Databricks 작업 영역 간에 MLflow 개체를 가져오거나 내보내려면 커뮤니티 기반 오픈 소스 프로젝트 MLflow Export-Import를 사용하여 작업 영역 간에 MLflow 실험, 모델 및 실행을 마이그레이션할 수 있습니다.
이러한 도구를 사용하여 다음을 수행할 수 있습니다.
- 동일하거나 다른 추적 서버의 다른 데이터 과학자와 공유하고 협업합니다. 예를 들어 다른 사용자의 실험을 작업 영역으로 복제할 수 있습니다.
- 개발 작업 영역에서 프로덕션 작업 영역으로 복사하는 것과 같이 한 작업 영역에서 다른 작업 영역으로 모델을 복사합니다.
- MLflow 실험을 복사하고 로컬 추적 서버에서 Databricks 작업 영역으로 실행합니다.
- 중요 업무용 실험 및 모델을 다른 Databricks 작업 영역에 백업합니다.
예시
이 예제에서는 작업 영역 모델 레지스트리를 사용하여 기계 학습 애플리케이션을 빌드하는 방법을 보여줍니다.