Machine Learning용 Databricks Runtime
이 문서에서는 Machine Learning용 Databricks 런타임에 대해 설명하고 이를 사용하는 클러스터를 만드는 방법에 대한 지침을 제공합니다.
Machine Learning용 Databricks 런타임이란?
Machine Learning용 Databricks Runtime(Databricks Runtime ML)은 가장 일반적인 ML 및 DL 라이브러리를 포함하여 미리 빌드된 기계 학습 및 딥 러닝 인프라를 사용하여 클러스터를 만드는 것을 자동화합니다.
Databricks Runtime ML에 포함된 라이브러리
Databricks Runtime ML에는 널리 사용되는 다양한 ML 라이브러리가 포함되어 있습니다. 라이브러리는 새로운 기능과 수정 사항을 포함하도록 각 릴리스와 함께 업데이트됩니다.
Databricks는 지원되는 라이브러리의 하위 집합을 최상위 라이브러리로 지정했습니다. 이러한 라이브러리의 경우 Databricks는 각 런타임 릴리스를 사용하여 최신 패키지 릴리스로 업데이트하는 빠른 업데이트 주기를 제공합니다(종속성 충돌 금지). Databricks는 또한 최상위 라이브러리에 대한 고급 지원, 테스트 및 포함된 최적화를 제공합니다. 최상위 계층 라이브러리는 주 릴리스에서만 추가되거나 제거됩니다.
- 최상위 계층 및 기타 제공된 라이브러리의 전체 목록은 Databricks Runtime ML에 대한
릴리스 정보를 참조하세요. - 라이브러리가 업데이트되는 빈도 및 라이브러리가 더 이상 사용되지 않는 시기에 대한 자세한 내용은 Databricks Runtime ML 유지 관리 정책참조하세요.
추가 라이브러리를 설치하여 Notebook 또는 클러스터에 대한 사용자 지정 환경을 만들 수 있습니다.
- 클러스터에서 실행되는 모든 Notebook에서 라이브러리를 사용할 수 있도록 하려면 클러스터 라이브러리를 만듭니다. 또한 init 스크립트를 사용하여 만들 때 클러스터에 라이브러리를 설치할 수 있습니다.
- 특정 Notebook 세션에 한해 사용할 수 있는 라이브러리를 설치하려면 Notebook 범위 Python 라이브러리를 사용합니다.
Databricks Runtime ML에 대한 컴퓨팅 리소스 설정
Databricks Runtime ML을 기반으로 컴퓨팅을 만드는 프로세스는 Dedicated 그룹 클러스터 공개 미리 보기 작업 영역을 사용할 수 있는지 여부에 따라 달라집니다. 미리 보기에 사용하도록 설정된 작업 영역에는 새로운 간소화된 컴퓨팅 UI있습니다.
Databricks Runtime ML을 사용하여 클러스터 만들기
클러스터를 만들 때 Databricks 런타임 버전 드롭다운 메뉴에서 Databricks Runtime ML 버전을 선택합니다. CPU 및 GPU 지원 ML 런타임을 모두 사용할 수 있습니다.
Databricks Runtime ML 선택
Notebook드롭다운 메뉴에서 클러스터를 선택할
GPU 사용 ML 런타임을 선택하는 경우 호환되는 드라이버 유형 및 작업자 유형선택하라는 메시지가 표시됩니다. 호환되지 않는 인스턴스 유형은 드롭다운 메뉴에서 회색으로 표시됩니다. GPU 지원 인스턴스 유형은 GPU 가속 레이블 아래에 나열됩니다. Azure Databricks GPU 클러스터 만들기에 대한 자세한 내용은 GPU 사용 클러스터를 참조하세요. Databricks Runtime ML에는 GPU 하드웨어 드라이버와 CUDA와 같은 NVIDIA 라이브러리가 포함되어 있습니다.
간소화된 새 컴퓨팅 UI를 사용하여 새 클러스터 만들기
작업 영역이 전용 그룹 클러스터 미리보기 기능을 사용하도록 설정된 경우에만 이 섹션의 단계를 사용하세요. .
Databricks Runtime의 기계 학습 버전을 사용하려면 Machine Learning 확인란을 선택합니다.
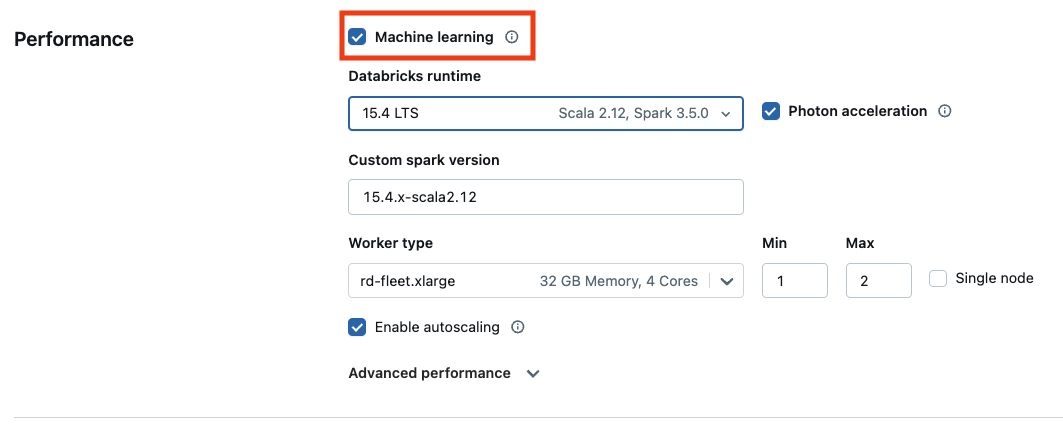
GPU 기반 컴퓨팅의 경우 GPU 사용 인스턴스 유형을 선택합니다. 지원되는 GPU 형식의 전체 목록은 지원되는 인스턴스 유형참조하세요.
Photon 및 Databricks Runtime ML
Databricks Runtime 15.2 ML 이상을 실행하는 CPU 클러스터를 만들 때 Photon을 사용하도록 선택할 수 있습니다. Photon은 Spark SQL, Spark DataFrames, 기능 엔지니어링, GraphFrames 및 xgboost4j를 사용하여 애플리케이션의 성능을 향상시킵니다. Spark RDD, Pandas UDF 및 Python과 같은 비 JVM 언어를 사용하는 애플리케이션의 성능은 향상되지 않을 것으로 예상됩니다. 따라서 XGBoost, PyTorch 및 TensorFlow와 같은 Python 패키지는 Photon에서 향상된 기능을 볼 수 없습니다.
Spark RDD API 및 Spark MLlib는 Photon과의 호환성이 제한됩니다. Spark RDD 또는 Spark MLlib를 사용하여 큰 데이터 세트를 처리할 때 Spark 메모리 문제가 발생할 수 있습니다. Spark 메모리 문제를 참조하세요.
Databricks 런타임 ML 클러스터에 대한 액세스 모드
Databricks Runtime ML을 실행하는 클러스터에서 Unity 카탈로그의 데이터에 액세스하려면 다음 중 하나를 수행해야 합니다.
- 단일 사용자 액세스 모드사용하여 클러스터를 설정합니다.
- 전용 액세스 모드사용하여 클러스터를 설정합니다. 전용 액세스 모드는 현재 공개 미리 보기로 제공됩니다. 전용 액세스 모드는 Databricks 런타임 ML에서 공유 액세스 모드의 기능을 제공합니다.
컴퓨팅 리소스에 Dedicated 액세스 권한이 있는 경우 리소스를 단일 사용자 또는 그룹에 할당할 수 있습니다. 그룹(그룹 클러스터)에 할당된 경우 사용자의 권한은 자동으로 그룹의 사용 권한 범위를 축소하여 사용자가 그룹의 다른 구성원과 리소스를 안전하게 공유할 수 있도록 합니다.
단일 사용자 액세스 모드를 사용하는 경우 다음 기능은 Databricks Runtime 15.4 LTS ML 이상에서만 사용할 수 있습니다.
- 세분화된 액세스 제어.
스트리밍 테이블 및 구체화된 뷰포함하여 Delta Live Tables 파이프라인