시작: Notebook에서 CSV 데이터 가져오기 및 시각화
이 문서에서는 Azure Databricks Notebook을 사용하여 python, Scala 및 R을 사용하여 health.data.ny.gov에서 베이비 이름 데이터가 포함된 CSV 파일에서 Unity 카탈로그 볼륨으로 데이터를 가져오는 방법을 안내합니다. 열 이름을 수정하고, 데이터를 시각화하고, 테이블에 저장하는 방법도 알아봅니다.
요구 사항
이 문서의 작업을 완료하려면 다음 요구 사항을 충족해야 합니다.
- 작업 영역에 Unity 카탈로그가 활성화되어 있어야 합니다. Unity 카탈로그를 시작하는 방법에 대한 자세한 내용은 Unity 카탈로그 설정 및 관리를 참조하세요.
- 볼륨에 대한
WRITE VOLUME권한, 부모 스키마에 대한USE SCHEMA권한, 부모 카탈로그에 대한USE CATALOG권한이 있어야 합니다. - 기존 컴퓨팅 리소스를 사용하거나 새 컴퓨팅 리소스를 만들 수 있는 권한이 있어야 합니다. 시작: 계정 및 작업 영역 설정을 참조하거나 Databricks 관리자에게 문의하세요.
팁
이 문서의 완성된 Notebook은 데이터 Notebook 가져오기 및 시각화를 참조하세요.
1단계: 새 Notebook 만들기
작업 영역에서 Notebook을 생성하려면 사이드바의 ![]() 새로 만들기를 클릭한 다음 Notebook을 클릭합니다. 작업 영역에서 빈 전자 필기장이 열립니다.
새로 만들기를 클릭한 다음 Notebook을 클릭합니다. 작업 영역에서 빈 전자 필기장이 열립니다.
Notebook 만들기 및 관리에 대한 자세한 내용은 Notebook 관리를 참조하세요.
2단계: 변수 정의
이 단계에서는 이 문서에서 만든 예제 Notebook에서 사용할 변수를 정의합니다.
다음 코드를 복사하고 새로운 빈 Notebook 셀에 붙여넣습니다.
<catalog-name>,<schema-name>,<volume-name>을 Unity 카탈로그 볼륨의 카탈로그, 스키마 및 볼륨 이름으로 바꿉니다. 선택에 따라table_name값을 원하는 테이블 이름으로 바꿀 수 있습니다. 이 문서의 뒷부분에서 아기 이름 데이터를 이 표에 저장합니다.셀을 실행하고 새 빈 셀을 만들려면
Shift+Enter를 누릅니다.Python
catalog = "<catalog_name>" schema = "<schema_name>" volume = "<volume_name>" download_url = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name = "baby_names.csv" table_name = "baby_names" path_volume = "/Volumes/" + catalog + "/" + schema + "/" + volume path_table = catalog + "." + schema print(path_table) # Show the complete path print(path_volume) # Show the complete pathScala
val catalog = "<catalog_name>" val schema = "<schema_name>" val volume = "<volume_name>" val downloadUrl = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" val fileName = "baby_names.csv" val tableName = "baby_names" val pathVolume = s"/Volumes/${catalog}/${schema}/${volume}" val pathTable = s"${catalog}.${schema}" print(pathVolume) // Show the complete path print(pathTable) // Show the complete pathR
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" download_url <- "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name <- "baby_names.csv" table_name <- "baby_names" path_volume <- paste("/Volumes/", catalog, "/", schema, "/", volume, sep = "") path_table <- paste(catalog, ".", schema, sep = "") print(path_volume) # Show the complete path print(path_table) # Show the complete path
3단계: CSV 파일 가져오기
이 단계에서는 health.data.ny.gov 베이비 이름 데이터가 포함된 CSV 파일을 Unity 카탈로그 볼륨으로 가져옵니다.
다음 코드를 복사하고 새로운 빈 Notebook 셀에 붙여넣습니다. 이 코드는 Databricks dbutuils 명령을 사용하여 health.data.ny.gov의
rows.csv파일을 Unity 카탈로그 볼륨으로 복사합니다.Shift+Enter키를 눌러 셀을 실행하고 다음 셀로 이동합니다.Python
dbutils.fs.cp(f"{download_url}", f"{path_volume}" + "/" + f"{file_name}")Scala
dbutils.fs.cp(downloadUrl, s"${pathVolume}/${fileName}")R
dbutils.fs.cp(download_url, paste(path_volume, "/", file_name, sep = ""))
4단계: DataFrame에 CSV 데이터 로드
이 단계에서는 spark.read.csv 메서드를 사용하여 이전에 Unity 카탈로그 볼륨에 로드한 CSV 파일에서 df으로 명명된 DataFrame을 만듭니다.
다음 코드를 복사하고 새로운 빈 Notebook 셀에 붙여넣습니다. 이 코드는 CSV 파일에서 DataFrame
df에 베이비 이름 데이터를 로드합니다.Shift+Enter키를 눌러 셀을 실행하고 다음 셀로 이동합니다.Python
df = spark.read.csv(f"{path_volume}/{file_name}", header=True, inferSchema=True, sep=",")Scala
val df = spark.read .option("header", "true") .option("inferSchema", "true") .option("delimiter", ",") .csv(s"${pathVolume}/${fileName}")R
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df <- read.df(paste(path_volume, "/", file_name, sep=""), source="csv", header = TRUE, inferSchema = TRUE, delimiter = ",")
지원되는 다양한 파일 형식에서 데이터를 로드할 수 있습니다.
5단계: Notebook에서 데이터 시각화
이 단계에서는 display() 메서드를 사용하여 Notebook의 테이블에 있는 DataFrame의 내용을 표시한 다음 Notebook의 Word 클라우드 차트에서 데이터를 시각화합니다.
다음 코드를 복사하여 빈 전자 필기장 셀에 붙여넣은 다음 셀 실행을 클릭하여 테이블에 데이터를 표시합니다.
Python
display(df)Scala
display(df)R
display(df)테이블의 데이터를 검토합니다.
테이블 탭 옆에 있는 +를 클릭한 다음 시각화를 클릭합니다.
시각화 편집기에서 시각적 개체 유형을 클릭하고 단어 클라우드가 선택되어 있는지 확인합니다.
단어 열에서
First Name이선택되어 있는지 확인합니다.빈도 제한에서
35을 클릭합니다.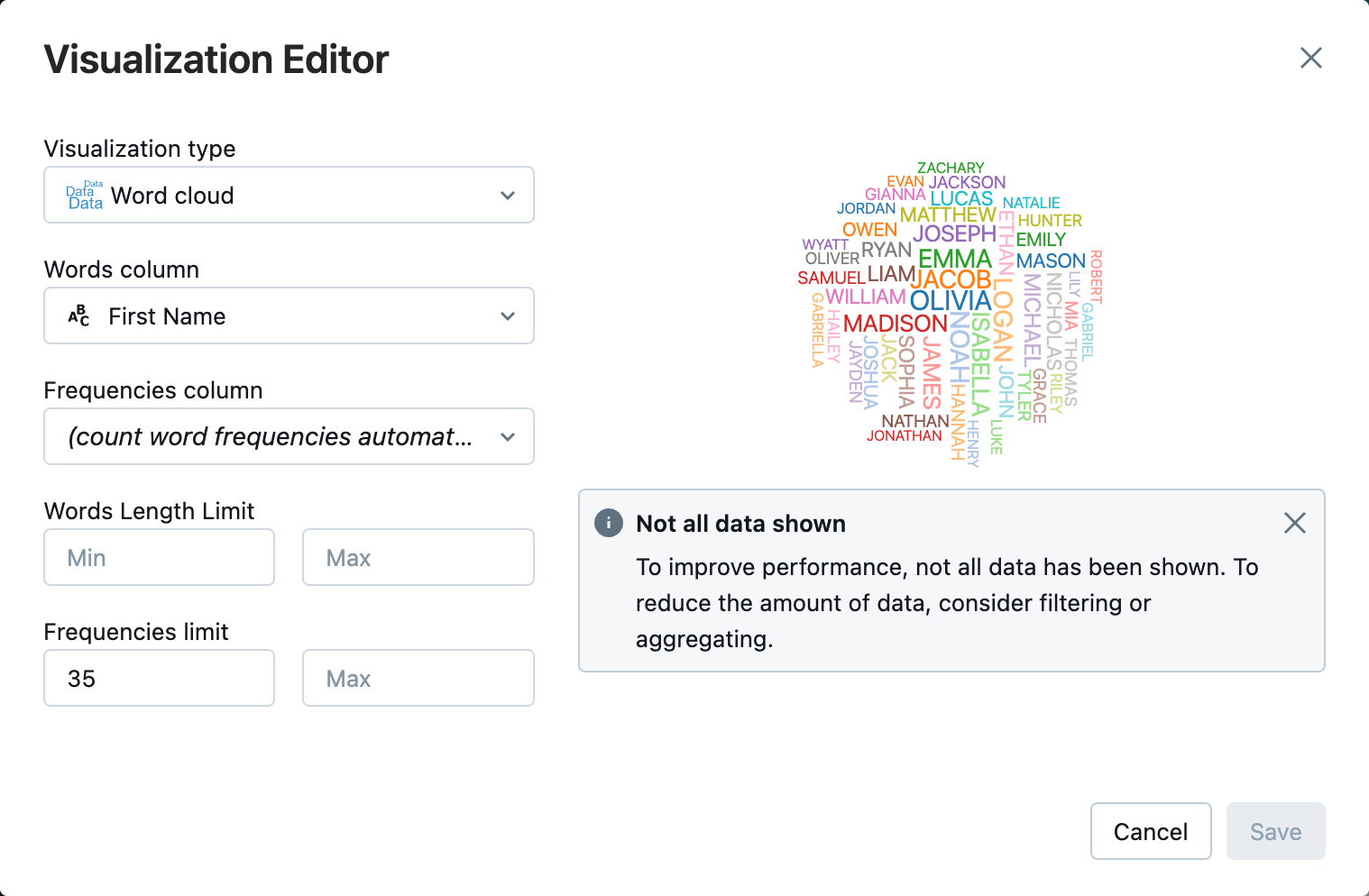
저장을 클릭합니다.
6단계: 테이블에 DataFrame 저장
Important
DataFrame을 Unity 카탈로그에 저장하려면 카탈로그 및 스키마에 대한 CREATE 테이블 권한이 있어야 합니다. Unity 카탈로그의 권한에 대한 자세한 내용은 Unity 카탈로그의 권한 및 보안 개체 및 Unity 카탈로그의 권한 관리를 참조하세요.
다음 코드를 복사한 후 빈 Notebook 셀에 붙여넣습니다. 이 코드는 열 이름의 공백을 대체합니다. 공백과 같은 특수 문자는 열 이름에 허용되지 않습니다. 이 코드는 Apache Spark
withColumnRenamed()메서드를 사용합니다.Python
df = df.withColumnRenamed("First Name", "First_Name") df.printSchemaScala
val dfRenamedColumn = df.withColumnRenamed("First Name", "First_Name") // when modifying a DataFrame in Scala, you must assign it to a new variable dfRenamedColumn.printSchema()R
df <- withColumnRenamed(df, "First Name", "First_Name") printSchema(df)다음 코드를 복사한 후 빈 Notebook 셀에 붙여넣습니다. 이 코드는 이 문서의 시작 부분에 정의한 테이블 이름 변수를 사용하여 DataFrame의 내용을 Unity 카탈로그의 테이블에 저장합니다.
Python
df.write.mode("overwrite").saveAsTable(f"{path_table}" + "." + f"{table_name}")Scala
dfRenamedColumn.write.mode("overwrite").saveAsTable(s"${pathTable}.${tableName}")R
saveAsTable(df, paste(path_table, ".", table_name), mode = "overwrite")테이블이 저장되었는지 확인하려면 왼쪽 사이드바에서 카탈로그를 클릭하여 카탈로그 탐색기 UI를 엽니다. 카탈로그를 연 다음 스키마를 열어 테이블이 표시되는지 확인합니다.
개요 탭에서 테이블 스키마를 보려면 표를 클릭합니다.
샘플 데이터를 클릭하면 표에서 100개 행의 데이터를 볼 수 있습니다.
데이터 Notebook 가져오기 및 시각화
다음 전자 필기장 중 하나를 사용하여 이 문서의 단계를 수행합니다. <catalog-name>, <schema-name>, <volume-name>을 Unity 카탈로그 볼륨의 카탈로그, 스키마 및 볼륨 이름으로 바꿉니다. 선택에 따라 table_name 값을 원하는 테이블 이름으로 바꿀 수 있습니다.
Python
Python을 사용하여 CSV에서 데이터 가져오기
Scala
Scala를 사용하여 CSV에서 데이터 가져오기
R
R을 사용하여 CSV에서 데이터 가져오기
다음 단계
- CSV 파일에서 기존 테이블에 추가 데이터를 추가하는 방법에 대한 자세한 내용은 시작하기: 추가 데이터 수집 및 삽입을 참조하세요.
- 데이터 정리 및 향상에 대한 자세한 내용은 시작하기: 데이터 향상 및 정리를 참조하세요.