유추를 위한 RAG 체인
이 문서에서는 사용자가 온라인 설정에서 RAG 애플리케이션에 요청을 제출할 때 발생하는 프로세스를 설명합니다. 데이터가 데이터 파이프라인에서 처리되면 RAG 애플리케이션에서 사용하기에 적합합니다. 유추 시간에 호출되는 계열 또는 단계 체인을 일반적으로 RAG 체인이라고 합니다.
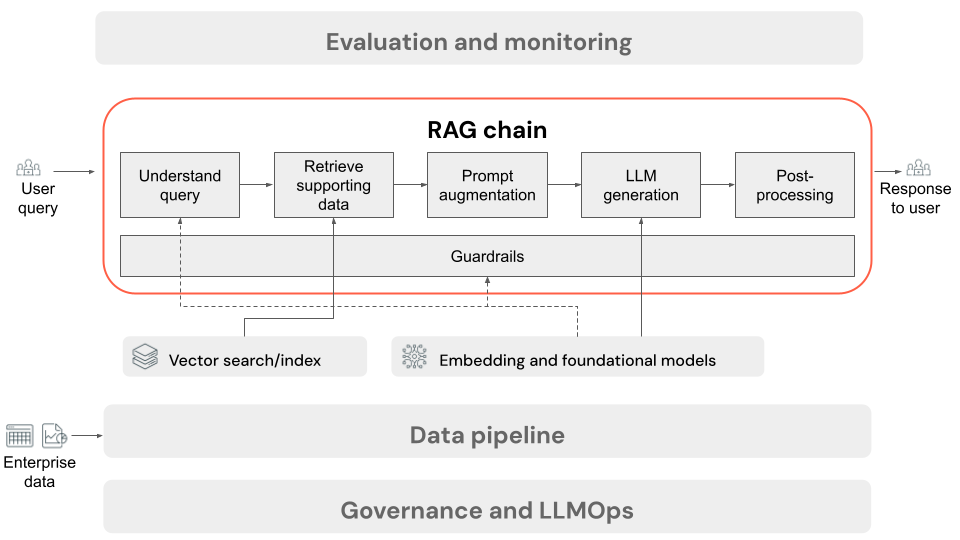
- (선택 사항) 사용자 쿼리 전처리: 경우에 따라 사용자의 쿼리가 전처리되어 벡터 데이터베이스 쿼리에 더 적합합니다. 여기에는 템플릿 내에서 쿼리의 서식을 지정하거나, 다른 모델을 사용하여 요청을 다시 작성하거나, 검색을 지원하기 위해 키워드를 추출하는 작업이 포함될 수 있습니다. 이 단계의 출력은 후속 검색 단계에서 사용되는 검색 쿼리입니다.
- 검색: 벡터 데이터베이스에서 지원 정보를 검색하기 위해 검색 쿼리는 데이터 준비 중에 문서 청크를 포함하는 데 사용된 것과 동일한 포함 모델을 사용하여 포함으로 변환됩니다. 이러한 포함을 사용하면 코사인 유사성과 같은 측정값을 사용하여 검색 쿼리와 구조화되지 않은 텍스트 청크 간의 의미 체계 유사성을 비교할 수 있습니다. 다음으로, 청크는 벡터 데이터베이스에서 검색되고 포함된 요청과 얼마나 유사한지에 따라 순위가 매겨집니다. 상위(가장 유사한) 결과가 반환됩니다.
- 프롬프트 확대: LLM으로 전송될 프롬프트는 각 구성 요소를 사용하는 방법을 모델에 지시하는 템플릿에서 검색된 컨텍스트를 사용하여 사용자의 쿼리를 보강하여 구성되며, 종종 응답 형식을 제어하는 추가 지침이 있습니다. 사용할 올바른 프롬프트 템플릿을 반복하는 프로세스를 프롬프트 엔지니어링이라고 합니다.
- LLM 생성: LLM은 사용자의 쿼리 및 검색된 지원 데이터를 입력으로 포함하는 보강된 프롬프트를 사용합니다. 그런 다음 추가 컨텍스트에 기반한 응답을 생성합니다.
- (선택 사항) 사후 처리: LLM의 응답은 추가 비즈니스 논리를 적용하거나 인용을 추가하거나 미리 정의된 규칙 또는 제약 조건에 따라 생성된 텍스트를 구체화하기 위해 추가로 처리될 수 있습니다.
RAG 애플리케이션 데이터 파이프라인과 마찬가지로 RAG 체인의 품질에 영향을 줄 수 있는 많은 결과적 엔지니어링 결정이 있습니다. 예를 들어 2단계에서 검색할 청크 수와 3단계의 사용자 쿼리와 결합하는 방법을 결정하면 모델의 품질 응답 생성 능력에 큰 영향을 줄 수 있습니다.
체인 전체에서 엔터프라이즈 정책을 준수하기 위해 다양한 가드레일을 적용할 수 있습니다. 여기에는 적절한 요청을 필터링하고, 데이터 원본에 액세스하기 전에 사용자 권한을 확인하고, 생성된 응답에 con텐트 모드ration 기술을 적용하는 작업이 포함될 수 있습니다.
다음: RAG 앱 > 평가를 위한 & 모니터링