Python을 사용하여 파이프라인 코드 개발
DLT는 파이프라인에서 구체화된 뷰 및 스트리밍 테이블을 정의하기 위한 몇 가지 새로운 Python 코드 구문을 도입했습니다. 파이프라인 개발을 위한 Python 지원은 PySpark DataFrame 및 구조적 스트리밍 API의 기본 사항을 기반으로 합니다.
Python 및 DataFrames에 익숙하지 않은 사용자의 경우 Databricks는 SQL 인터페이스를 사용하는 것이 좋습니다. SQL 사용하여 파이프라인 코드 개발참조하세요.
DLT Python 구문에 대한 전체 참조는 DLT Python 언어 참조참조하세요.
파이프라인 개발을 위한 Python의 기본 사항
DLT 데이터 세트를 만드는 Python 코드는 DataFrames를 반환해야 합니다.
모든 DLT Python API는 dlt 모듈에서 구현됩니다. Python으로 구현된 DLT 파이프라인 코드는 Python Notebook 및 파일 맨 위에 있는 dlt 모듈을 명시적으로 가져와야 합니다.
파이프라인 구성 중에 지정된 카탈로그 및 스키마에 대한 읽기 및 쓰기 기본값입니다. 대상 카탈로그 및 스키마 설정을 참조하세요.
DLT 관련 Python 코드는 다른 유형의 Python 코드와 다른 중요한 방식으로 다릅니다. Python 파이프라인 코드는 데이터 수집 및 변환을 수행하는 함수를 직접 호출하여 DLT 데이터 세트를 만들지 않습니다. 대신 DLT는 파이프라인에 구성된 모든 소스 코드 파일의 dlt 모듈에서 데코레이터 함수를 해석하고 데이터 흐름 그래프를 작성합니다.
중요하다
파이프라인이 실행될 때 예기치 않은 동작을 방지하려면 데이터 세트를 정의하는 함수에 부작용이 있을 수 있는 코드를 포함하지 마세요. 자세한 내용은 Python 참조참조하세요.
Python을 사용하여 구체화된 뷰 또는 스트리밍 테이블 만들기
@dlt.table 데코레이터는 함수에서 반환된 결과에 따라 구체화된 뷰 또는 스트리밍 테이블을 만들도록 DLT에 지시합니다. 일괄 처리 읽기의 결과는 구체화된 뷰를 만들고 스트리밍 읽기의 결과는 스트리밍 테이블을 만듭니다.
기본적으로 구체화된 뷰 및 스트리밍 테이블 이름은 함수 이름에서 유추됩니다. 다음 코드 예제에서는 구체화된 뷰 및 스트리밍 테이블을 만들기 위한 기본 구문을 보여줍니다.
메모
두 함수는 samples 카탈로그에서 동일한 테이블을 참조하고 동일한 데코레이터 함수를 사용합니다. 이러한 예제는 구체화된 뷰와 스트리밍 테이블의 기본 구문에서 유일한 차이점이 spark.read을 사용하는 것과 spark.readStream을 사용하는 것임을 강조합니다.
모든 데이터 원본이 스트리밍 읽기를 지원하지는 않습니다. 일부 데이터 원본은 항상 스트리밍 의미 체계를 사용하여 처리해야 합니다.
import dlt
@dlt.table()
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dlt.table()
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
필요에 따라 @dlt.table 데코레이터에서 name 인수를 사용하여 테이블 이름을 지정할 수 있습니다. 다음 예제에서는 구체화된 뷰 및 스트리밍 테이블에 대해 이 패턴을 보여 줍니다.
import dlt
@dlt.table(name = "trips_mv")
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dlt.table(name = "trips_st")
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
개체 스토리지에서 데이터 로드
DLT는 Azure Databricks에서 지원하는 모든 형식의 데이터 로드를 지원합니다. 데이터 형식 옵션을 참조하세요.
메모
이 예시들에서는 작업 공간에 자동으로 연결된 /databricks-datasets의 데이터를 사용할 수 있습니다. Databricks는 볼륨 경로 또는 클라우드 URI를 사용하여 클라우드 개체 스토리지에 저장된 데이터를 참조하는 것이 좋습니다.
Unity 카탈로그 볼륨이란?.
Databricks는 클라우드 개체 스토리지에 저장된 데이터에 대해 증분 수집 워크로드를 구성할 때 자동 로더 및 스트리밍 테이블을 사용하는 것이 좋습니다. 자동 로더란?.
다음 예제에서는 자동 로더를 사용하여 JSON 파일에서 스트리밍 테이블을 만듭니다.
import dlt
@dlt.table()
def ingestion_st():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
다음 예제에서는 일괄 처리 의미 체계를 사용하여 JSON 디렉터리를 읽고 구체화된 뷰를 만듭니다.
import dlt
@dlt.table()
def batch_mv():
return spark.read.format("json").load("/databricks-datasets/retail-org/sales_orders")
예상 데이터 유효성 검사
기대치를 사용하여 데이터 품질 제약 조건을 설정하고 적용할 수 있습니다. 데이터 품질 관리를 파이프라인 기대과 함께 참조하세요.
다음 코드는 @dlt.expect_or_drop 사용하여 데이터 수집 중에 null인 레코드를 삭제하는 valid_data 명명된 기대치를 정의합니다.
import dlt
@dlt.table()
@dlt.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders_valid():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
파이프라인에 정의된 머티리얼라이즈드 뷰 및 스트리밍 테이블 쿼리
다음 예제에서는 4개의 데이터 세트를 정의합니다.
- JSON 데이터를 로드하는
orders스트리밍 테이블입니다. - CSV 데이터를 로드하는
customers구체화된 뷰입니다. -
orders및customers데이터 세트의 레코드를 조인하고, 주문 타임스탬프를 날짜로 캐스팅하고,customer_id,order_number,state및order_date필드를 선택하는customer_orders명명된 구체화된 뷰입니다. - 각 상태에 대한 일일 주문 수를 집계하는
daily_orders_by_state명명된 구체화된 뷰입니다.
메모
파이프라인에서 뷰 또는 테이블을 쿼리할 때 카탈로그와 스키마를 직접 지정하거나 파이프라인에 구성된 기본값을 사용할 수 있습니다. 이 예제에서는 파이프라인에 대해 구성된 기본 카탈로그 및 스키마에서 orders, customers및 customer_orders 테이블을 작성하고 읽습니다.
레거시 게시 모드는 LIVE 스키마를 사용하여 파이프라인에 정의된 다른 구체화된 뷰 및 스트리밍 테이블을 쿼리합니다. 새 파이프라인에서 LIVE 스키마 구문은 자동으로 무시됩니다.
LIVE 스키마(레거시)를 참조하십시오.
import dlt
from pyspark.sql.functions import col
@dlt.table()
@dlt.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
@dlt.table()
def customers():
return spark.read.format("csv").option("header", True).load("/databricks-datasets/retail-org/customers")
@dlt.table()
def customer_orders():
return (spark.read.table("orders")
.join(spark.read.table("customers"), "customer_id")
.select("customer_id",
"order_number",
"state",
col("order_datetime").cast("int").cast("timestamp").cast("date").alias("order_date"),
)
)
@dlt.table()
def daily_orders_by_state():
return (spark.read.table("customer_orders")
.groupBy("state", "order_date")
.count().withColumnRenamed("count", "order_count")
)
for 루프에서 테이블 만들기
Python for 루프를 사용하여 프로그래밍 방식으로 여러 테이블을 만들 수 있습니다. 이 기능은 몇 가지 매개 변수에 따라 달라지는 많은 데이터 원본 또는 대상 데이터 세트가 있는 경우 유용할 수 있으며, 이로 인해 유지 관리할 총 코드가 줄어들고 코드 중복성이 줄어듭니다.
for 루프는 직렬 순서로 논리를 평가하지만 데이터 세트에 대한 계획이 완료되면 파이프라인은 논리를 병렬로 실행합니다.
중요하다
이 패턴을 사용하여 데이터 세트를 정의하는 경우 for 루프에 전달된 값 목록이 항상 가산적인지 확인합니다. 파이프라인에서 이전에 정의된 데이터 세트를 향후 파이프라인 실행에서 생략하면 해당 데이터 세트가 대상 스키마에서 자동으로 삭제됩니다.
다음 예제에서는 지역별로 고객 주문을 필터링하는 5개의 테이블을 만듭니다. 여기서 지역 이름은 구체화된 대상 뷰의 이름을 설정하고 원본 데이터를 필터링하는 데 사용됩니다. 임시 뷰는 최종 구체화된 뷰를 생성하는 데 사용되는 원본 테이블의 조인을 정의하는 데 사용됩니다.
import dlt
from pyspark.sql.functions import collect_list, col
@dlt.view()
def customer_orders():
orders = spark.read.table("samples.tpch.orders")
customer = spark.read.table("samples.tpch.customer")
return (orders.join(customer, orders.o_custkey == customer.c_custkey)
.select(
col("c_custkey").alias("custkey"),
col("c_name").alias("name"),
col("c_nationkey").alias("nationkey"),
col("c_phone").alias("phone"),
col("o_orderkey").alias("orderkey"),
col("o_orderstatus").alias("orderstatus"),
col("o_totalprice").alias("totalprice"),
col("o_orderdate").alias("orderdate"))
)
@dlt.view()
def nation_region():
nation = spark.read.table("samples.tpch.nation")
region = spark.read.table("samples.tpch.region")
return (nation.join(region, nation.n_regionkey == region.r_regionkey)
.select(
col("n_name").alias("nation"),
col("r_name").alias("region"),
col("n_nationkey").alias("nationkey")
)
)
# Extract region names from region table
region_list = spark.read.table("samples.tpch.region").select(collect_list("r_name")).collect()[0][0]
# Iterate through region names to create new region-specific materialized views
for region in region_list:
@dlt.table(name=f"{region.lower().replace(' ', '_')}_customer_orders")
def regional_customer_orders(region_filter=region):
customer_orders = spark.read.table("customer_orders")
nation_region = spark.read.table("nation_region")
return (customer_orders.join(nation_region, customer_orders.nationkey == nation_region.nationkey)
.select(
col("custkey"),
col("name"),
col("phone"),
col("nation"),
col("region"),
col("orderkey"),
col("orderstatus"),
col("totalprice"),
col("orderdate")
).filter(f"region = '{region_filter}'")
)
다음은 이 파이프라인에 대한 데이터 흐름 그래프의 예입니다.
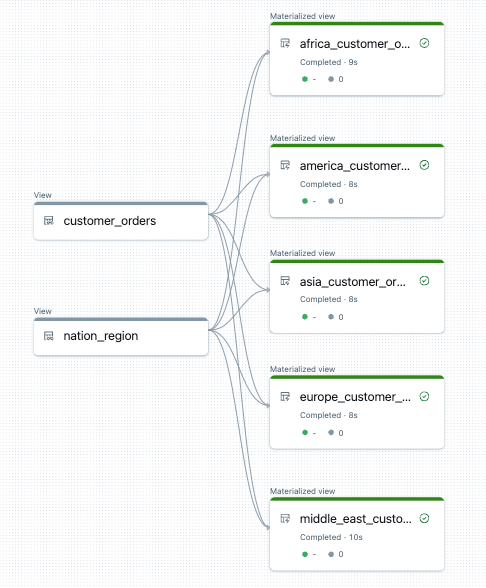
문제 해결: for 루프는 동일한 값을 가진 많은 테이블을 만듭니다.
파이프라인이 Python 코드를 평가하는 데 사용하는 지연 실행 모델을 사용하려면 @dlt.table() 데코레이팅된 함수가 호출될 때 논리가 개별 값을 직접 참조해야 합니다.
다음 예제에서는 for 루프를 사용하여 테이블을 정의하는 두 가지 올바른 방법을 보여 줍니다. 두 예제에서 tables 목록의 각 테이블 이름은 @dlt.table()데코레이팅된 함수 내에서 명시적으로 참조됩니다.
import dlt
# Create a parent function to set local variables
def create_table(table_name):
@dlt.table(name=table_name)
def t():
return spark.read.table(table_name)
tables = ["t1", "t2", "t3"]
for t_name in tables:
create_table(t_name)
# Call `@dlt.table()` within a for loop and pass values as variables
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dlt.table(name=t_name)
def create_table(table_name=t_name):
return spark.read.table(table_name)
다음 예제 참조 값을 올바르게 않습니다. 이 예제에서는 고유한 이름을 가진 테이블을 만들지만 모든 테이블은 for 루프의 마지막 값에서 데이터를 로드합니다.
import dlt
# Don't do this!
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dlt.table(name=t_name)
def create_table():
return spark.read.table(t_name)