Unity Catalog 사용하여 데이터 계보 캡처 및 보기
이 문서에서는 Catalog Explorer, 데이터 계보 시스템 tables및 REST API를 사용하여 데이터 계보를 캡처하고 시각화하는 방법을 설명합니다.
Unity Catalog 사용하여 Azure Databricks에서 실행되는 쿼리에서 런타임 데이터 계보를 캡처할 수 있습니다. 계보는 모든 언어에 대해 지원되며 column 수준으로 캡처됩니다. 계보 데이터에는 쿼리와 관련된 Notebook, 작업, 대시보드가 포함됩니다. 계보는 Catalog 탐색기에서 거의 실시간으로 시각화할 수 있으며 계보 시스템 tables 및 Databricks REST API를 사용하여 프로그래밍 방식으로 검색할 수 있습니다.
계통은 Unity Catalog 메타스토어에 연결된 모든 작업 공간에서 집계됩니다. 즉, 한 작업 영역에서 캡처된 계보는 해당 메타스토어를 shares 다른 작업 영역에 표시됩니다. 특히 메타스토어에 등록된 tables 및 기타 데이터 개체는 메타스토어에 연결된 모든 작업 영역에서 해당 개체에 대해 BROWSE 이상의 권한이 있는 사용자에게 표시됩니다. 그러나 다른 작업 영역의 Notebook 및 대시보드와 같은 작업 영역 수준 개체에 대한 자세한 내용은 마스킹됩니다(제한 사항 및 계보 권한참조).
계보 데이터는 1년 동안 보존됩니다.
다음 이미지는 샘플 계보 그래프입니다. 특정 데이터 계보 기능 및 예제는 이 문서의 뒷부분에 설명되어 있습니다.
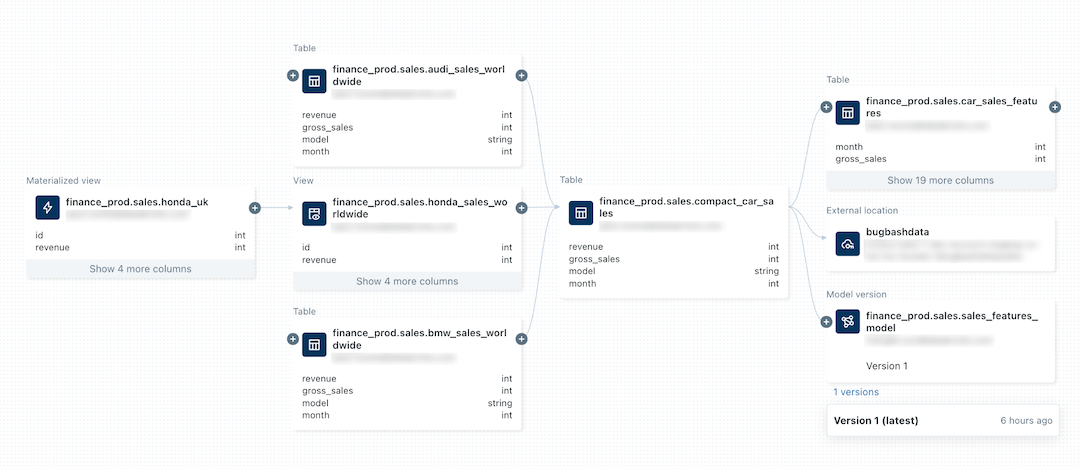
기계 학습 모델의 계보를 추적하는 방법에 대한 자세한 내용은 Unity Catalog모델의 데이터 계보 추적을 참조하세요.
요구 사항
Unity Catalog사용하여 데이터 계보를 캡처하려면 다음이 필요합니다.
작업 영역에는 Unity Catalog 활성화된있어야 합니다.
Tables은(는) Unity 메타스토어 Catalog에 등록해야 합니다.
쿼리는 Spark DataFrame(예: DataFrame을 반환하는 Spark SQL 함수) 또는 Databricks SQL 인터페이스를 사용해야 합니다. Databricks SQL 및 PySpark 쿼리의 예제는 예제를 참조하세요.
table 또는 보기의 계보를 보려면 사용자에게
BROWSE또는 뷰의 부모 catalog 대한 table 권한이 있어야 합니다. 작업 공간에서도 부모 catalog에 액세스할 수 있어야 합니다. 특정 작업 영역대한액세스를 참조하세요. Notebook, 작업 또는 대시보드에 대한 계보 정보를 보려면 작업 영역의 액세스 제어 설정에 정의된 대로 사용자에게 이러한 개체에 대한 권한이 있어야 합니다. 계보 사용 권한을 참조하세요.
Unity Catalog사용 파이프라인에 대한 계보를 보려면, 해당 파이프라인에 대해
CAN_VIEW권한이 있어야 합니다.Delta tables 간의 스트리밍 계보 추적에는 Databricks Runtime 11.3 LTS 이상이 필요합니다.
Delta Live Column 워크로드의 계보 추적은 Tables를 위해 Databricks Runtime 13.3 LTS 이상이 필요합니다.
Azure Databricks 컨트롤 플레인의 Event Hubs 엔드포인트에 연결할 수 있도록 아웃바운드 방화벽 규칙을 update 수 있습니다. 일반적으로 Azure Databricks 작업 영역이 사용자의 자체 VNet(VNet 주입이라고도 함)에 배포되는 경우에 적용됩니다. 작업 영역 영역에 대한 Event Hubs 엔드포인트를 getMetastore, 아티팩트 Blob Storage, 시스템 tables 스토리지, 로그 Blob Storage 및 Event Hubs 엔드포인트 IP 주소참조하세요. Azure Databricks용 UDR(사용자 정의 경로) 설정에 대한 자세한 내용은 Azure Databricks용 사용자 정의 경로 설정을 참조하세요.
예
참고 항목
다음 예제에서는 catalog 이름
lineage_data과 schema 이름lineagedemo을 사용합니다. 다른 catalog 및 schema을 사용하려면, 예제에서 사용된 이름을 변경하십시오.이 예제를 완료하려면
CREATE에 대한USE SCHEMA및 schema 권한이 있어야 합니다. metastore 관리자, catalog 소유자, schema 소유자 또는MANAGE에 대한 schema 권한이 있는 사용자는 이러한 권한을 grant할 수 있습니다. 예를 들어, 'data_engineers' 그룹의 모든 사용자에게 tableslineagedemo에서 schemalineage_data의 catalog을 만들 수 있는 권한을 부여하려면, 위의 권한이나 역할 중 하나를 가진 사용자가 다음 쿼리를 실행할 수 있습니다.CREATE SCHEMA lineage_data.lineagedemo; GRANT USE SCHEMA, CREATE on SCHEMA lineage_data.lineagedemo to `data_engineers`;
계보 캡처 및 탐색
계보 데이터를 캡처하려면 다음을 수행합니다.
Azure Databricks 방문 페이지로 이동하여 사이드바에서
 새을 클릭하고, 메뉴에서 selectNotebook을 선택합니다.
새을 클릭하고, 메뉴에서 selectNotebook을 선택합니다.전자 필기장의 이름을 입력하고 select SQL을 기본 언어에서 입력하십시오.
클러스터에는 Unity select에 액세스할 수 있는 클러스터 Catalog가 있습니다.
만들기를 클릭합니다.
첫 번째 Notebook 셀에 다음 쿼리를 입력합니다.
CREATE TABLE IF NOT EXISTS lineage_data.lineagedemo.menu ( recipe_id INT, app string, main string, dessert string ); INSERT INTO lineage_data.lineagedemo.menu (recipe_id, app, main, dessert) VALUES (1,"Ceviche", "Tacos", "Flan"), (2,"Tomato Soup", "Souffle", "Creme Brulee"), (3,"Chips","Grilled Cheese","Cheesecake"); CREATE TABLE lineage_data.lineagedemo.dinner AS SELECT recipe_id, concat(app," + ", main," + ",dessert) AS full_menu FROM lineage_data.lineagedemo.menu쿼리를 실행하려면 셀을 클릭하고
shift+enter 누르거나실행 메뉴 클릭합니다.
Catalog 탐색기를 사용하여 이러한 쿼리에서 생성된 계보를 보려면 다음을 수행합니다.
Azure Databricks 작업 영역의 위쪽 막대에 있는 검색 상자에서
lineage_data.lineagedemo.dinnertable을 검색하고, 그것을 select하십시오.Select 탭을 하십시오. 계보 패널이 나타나고 관련 tables가 표시됩니다(이 예에서는
menutable입니다).데이터 계보의 대화형 그래프를 보려면 계보 그래프 보기를 클릭합니다. 기본적으로 한 수준이 그래프에 표시됩니다. 노드에서
 아이콘을 클릭하면, 사용 가능한 경우 더 많은 connections가 표시됩니다.
아이콘을 클릭하면, 사용 가능한 경우 더 많은 connections가 표시됩니다.계보 그래프에서 노드를 연결하는 화살표를 클릭하여 계보 연결 패널을 엽니다. 계보 연결 패널은 원본 및 대상 tables, 노트북, 작업 등을 포함하여 연결에 대한 세부 정보를 보여줍니다.
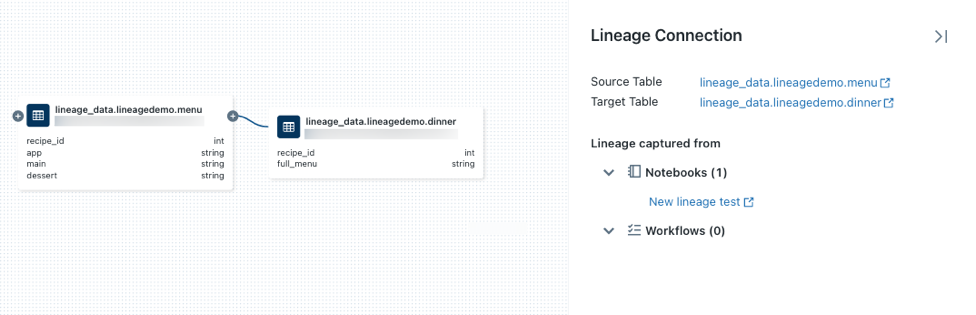
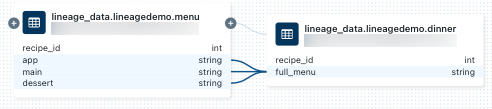
dinnertable연결된 Notebook을 표시하려면 select 패널에서 전자 필기장을 계보 그래프를 닫고 Notebook클릭합니다. 새 탭에서 Notebook을 열려면 Notebook 이름을 클릭합니다.column수준 계보를 보려면, 그래프에서 column을 클릭하여 관련 columns의 링크를 표시합니다. 예를 들어, 'full_menu' column을 클릭하면 columns가 파생된 업스트림 column이 표시됩니다.
다른 언어(예: Python)를 사용하여 계보를 보려면 다음을 수행합니다.
이전에 만든 Notebook을 열고 새 셀을 만들고 다음 Python 코드를 입력합니다.
%python from pyspark.sql.functions import rand, round df = spark.range(3).withColumn("price", round(10*rand(seed=42),2)).withColumnRenamed("id","recipe_id") df.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.price") dinner = spark.read.table("lineage_data.lineagedemo.dinner") price = spark.read.table("lineage_data.lineagedemo.price") dinner_price = dinner.join(price, on="recipe_id") dinner_price.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.dinner_price")셀을 클릭하고 shift+enter 키를 누르거나
 을 클릭하고 셀 실행을 선택하여 셀을 실행합니다.
을 클릭하고 셀 실행을 선택하여 셀을 실행합니다.Azure Databricks 작업 영역의 위쪽 막대에 있는 검색 상자에서
lineage_data.lineagedemo.pricetable을 검색하고, 그것을 select하십시오.계보 탭으로 이동하여 계보 그래프 보기를 클릭합니다.
아이콘을 클릭하여 쿼리에서 생성된 데이터 계보를 탐색합니다.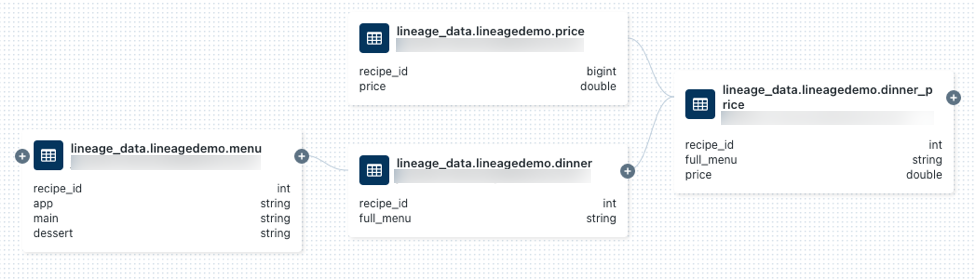
계보 그래프에서 노드를 연결하는 화살표를 클릭하여 계보 연결 패널을 엽니다. 계보 연결 패널은 원본 및 대상 tables, 노트북, 작업 등을 포함하여 연결에 대한 세부 정보를 보여줍니다.
워크플로 계보 캡처 및 보기
Unity Catalog를 읽거나 쓰는 모든 워크플로에 대해 계열도 캡처됩니다. Azure Databricks 워크플로에 대한 계보를 보려면 다음을 수행합니다.
사이드바에서
새 아이콘 새 을 클릭한 후, 메뉴에서 노트북을선택합니다. 전자 필기장의 이름을 입력하고 select SQL을 기본 언어에서 입력하십시오.
만들기를 클릭합니다.
첫 번째 Notebook 셀에 다음 쿼리를 입력합니다.
SELECT * FROM lineage_data.lineagedemo.menu위쪽 표시줄에서 일정을 클릭합니다. 일정 대화 상자에서 select수동, Unity select에 액세스할 수 있는 클러스터 Catalog, 그리고 생성을 클릭합니다.
지금 실행을 클릭합니다.
Azure Databricks 작업 영역의 위쪽 막대에 있는 검색 상자에서
lineage_data.lineagedemo.menutable을 검색하고, 그것을 select하십시오.계보 탭에서 워크플로를 클릭한 후, select 탭을 확인합니다. 작업 이름은
menu소비자로서 table 아래에 표시됩니다.
대시보드 계보 캡처 및 보기
대시보드를 만들고 해당 데이터 계보를 보려면 다음을 수행합니다.
Azure Databricks 시작 페이지로 이동한 후, 사이드바에서 Catalog을 클릭하여 Catalog 탐색기를 엽니다.
이름을 클릭하고 lineagedemo 클릭한 다음 . 위쪽 표시줄의 검색 상자를 사용하여 menutable검색할 수도 있습니다.대시보드에서 열기를 클릭합니다.
대시보드에 추가할 Selectcolumns을 선택하고 생성을 클릭합니다.
대시보드를 게시합니다.
게시된 대시보드만 데이터 계보에서 추적됩니다.
위쪽 표시줄의 검색 상자에서
lineage_data.lineagedemo.menutable을 검색하고, select을 선택하세요.계보 탭에서 대시보드를 클릭합니다. 대시보드는 대시보드 이름 아래 메뉴 table의 소비자로서 나타납니다.
계보 사용 권한
계보 그래프는 Unity 와 동일한 Catalog을 공유합니다. Unity Tables 메타스토어에 등록된 Catalog 및 기타 데이터 개체는 해당 개체에 대해 BROWSE 이상의 권한이 있는 사용자에게만 표시됩니다. 사용자에게 BROWSE대한 SELECT 또는 table 권한이 없는 경우 해당 계보를 탐색할 수 없습니다. 사용자가 적절한 개체 권한을 가진 경우, 계보 그래프는 메타스토어에 연결된 모든 워크스페이스에서 Unity Catalog 개체를 표시합니다.
예를 들어 userA에 대해 다음과 같은 명령을 실행합니다.
GRANT USE SCHEMA on lineage_data.lineagedemo to `userA@company.com`;
GRANT SELECT on lineage_data.lineagedemo.menu to `userA@company.com`;
userA
views 경우 lineage_data.lineagedemo.menutable계보 그래프를 보면 menutable가 표시될 것입니다. 그들은 다운스트림 tableslineage_data.lineagedemo.dinner같은 관련 table에 대한 정보를 보지 못할 것입니다.
dinner
table은 masked디스플레이에서 userA 노드로 표시되며, userA는 액세스 권한이 없는 tables에서 다운스트림 tables를 표시하도록 그래프를 확장할 수 없습니다.
다음 명령을 실행하여 grant에 대한 BROWSE 권한을 userB하면, 해당 사용자는 tablelineage_data의 모든 schema에 대한 계보 그래프를 볼 수 있습니다.
GRANT BROWSE on lineage_data to `userB@company.com`;
마찬가지로 계보 사용자는 Notebook, 작업 및 대시보드와 같은 작업 영역 개체를 볼 수 있는 특정 권한이 있어야 합니다. 또한 해당 개체를 만든 작업 영역에 로그인할 때만 작업 영역 개체에 대한 자세한 정보를 볼 수 있습니다. 다른 작업 영역의 작업 영역 수준 개체에 대한 자세한 정보는 계보 그래프에서 마스킹됩니다.
Unity Catalog보안 개체에 대한 액세스를 관리하는 방법에 대한 자세한 내용은 Unity Catalog권한 관리를 참조하세요. Notebook, 작업, 대시보드와 같은 작업 영역 개체에 대한 액세스를 관리하는 방법은 액세스 제어 목록을 참조하세요.
계보 데이터 삭제
Warning
다음 지침은 Unity Catalog에 저장된 모든 개체를 삭제합니다. 필요한 경우에만 다음 지침을 사용합니다. 예를 들어 규정 준수 요구 사항을 충족하기 위해 사용합니다.
계보 데이터를 삭제하려면 Unity Catalog 개체를 관리하는 메타스토어를 삭제해야 합니다. 메타스토어 삭제에 대한 자세한 내용은 메타스토어 삭제를 참조하세요. 데이터는 90일 이내에 삭제됩니다.
시스템 을 사용하여 tables계보 데이터를 쿼리합니다.
계보 시스템 tables 사용하여 계보 데이터를 프로그래밍 방식으로 쿼리할 수 있습니다. 자세한 지침은 시스템 tables를 사용하여 계정 활동을 모니터링하고, 계보 시스템 tables 참조를 참조하세요.
작업 영역이 계보 시스템 tables지원하지 않는 지역에 있는 경우 Data Lineage REST API를 사용하여 계보 데이터를 프로그래밍 방식으로 검색할 수도 있습니다.
데이터 계보 REST API를 사용하여 계보 검색
데이터 계보 API를 사용하면 table와 column 계보를 검색할 수 있습니다. 그러나 작업 영역이 계보 시스템 tables지원하는 지역에 있는 경우 REST API 대신 시스템 table 쿼리를 사용해야 합니다. 시스템 tables는 데이터 계보를 프로그래밍 방식으로 추출하는 더 나은 옵션입니다. 대부분의 지역에서는 계보 시스템 tables지원합니다.
Important
Databricks REST API에 액세스하려면 인증해야 합니다.
table 계보 검색
이 예제에서는 dinnertable계보 데이터를 검색합니다.
요청
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/table-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "include_entity_lineage": true}'
<workspace-instance>를 바꿉니다.
다음 예제에서는 .netrc 파일을 사용합니다.
응답
{
"upstreams": [
{
"tableInfo": {
"name": "menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
],
"downstreams": [
{
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
},
{
"tableInfo": {
"name": "dinner_price",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
]
}
column 계보 검색
이 예제에서는 columndinner대한 table 데이터를 검색합니다.
요청
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/column-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "column_name": "dessert"}'
<workspace-instance>를 바꿉니다.
다음 예제에서는 .netrc 파일을 사용합니다.
응답
{
"upstream_cols": [
{
"name": "dessert",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "main",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "app",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
}
],
"downstream_cols": [
{
"name": "full_menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "dinner_price",
"table_type": "TABLE"
}
]
}
제한 사항
계보는 동일한 Unity Catalog 메타스토어에 연결된 모든 작업 공간에 대해 집계되지만, 노트북 및 대시보드와 같은 작업 공간 객체에 대한 세부 정보는 생성된 작업 공간에서만 확인 가능합니다.
계보는 1년 롤링 window계산되므로 1년 전에 수집된 계보는 표시되지 않습니다. 예를 들어 작업 또는 쿼리가 table A에서 데이터를 읽고 table B에 쓰는 경우 table A와 table B 사이의 링크는 1년 동안만 표시됩니다. 1년 window기간 내에 시간 프레임별로 계보 데이터를 필터링할 수 있습니다.
계보를 볼 때 작업 API
runs submit요청을 사용하는 작업을 사용할 수 없습니다. Table 및 column 수준 계보는runs submit요청을 사용할 때 계속 캡처되지만 실행에 대한 링크는 캡처되지 않습니다.Unity Catalog가 가능한 한 column 수준까지 계보를 캡처합니다. 그러나 wherecolumn-level 계보를 캡처할 수 없는 경우가 있습니다.
Column 계보는 원본과 대상이 모두 table 이름으로 참조되는 경우에만 지원됩니다(예:
select * from <catalog>.<schema>.<table>). 원본 또는 대상의 주소가 경로(예: Column)인 경우select * from delta."s3://<bucket>/<path>"계보를 캡처할 수 없습니다.table 또는 뷰의 이름이 변경되면, 변경된 table 또는 뷰의 이력이 캡처되지 않습니다.
schema 또는 catalog의 이름이 변경되면, 이름이 변경된 tables 또는 views아래에 있는 catalog 및 schema의 계보는 캡처되지 않습니다.
Spark SQL 데이터 세트 검사점을 사용하는 경우 계보가 캡처되지 않습니다.
Unity Catalog는 대부분의 경우 Delta Live Tables 파이프라인에서 계보를 캡처합니다. 그러나 파이프라인이 APPLY CHANGES API를 사용하거나 임시 tables경우와 같이 일부 경우에는 전체 계보 추적을 보장할 수 없습니다.
계보는 스택 함수를 캡처하지 않습니다.
전역 임시 views는 계보에 캡처되지 않습니다.
Tables은(는)
system.information_schema아래에 있으며 계보에서 포착되지 않습니다.전체 column수준의 계보는
MERGE작업에 대해 기본적으로 기록되지 않습니다.Spark 속성을
MERGEspark.databricks.dataLineage.mergeIntoV2Enabled.로 설정하여 작업에 대한true계보 캡처를 켤 수 있습니다. 이 플래그를 사용하도록 설정하면 특히 매우 광범위한 tables관련된 워크로드에서 쿼리 성능이 저하될 수 있습니다.