Azure Portal에서 변경 내용 추적을 사용하여 Azure SQL Database에서 Blob Storage로 데이터 증분 복사
적용 대상:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
데이터 통합 솔루션에서 초기 데이터로드 후 데이터 증분을 로드하는 것은 널리 사용되는 시나리오입니다. 원본 데이터 저장소의 기간 내에서 변경된 데이터는 쉽게 분할할 수 있습니다(예: LastModifyTime, CreationTime). 그러나 어떤 경우에는 마지막으로 데이터를 처리한 시점에서 델타 데이터를 식별할 수 있는 명시적인 방법이 없습니다. Azure SQL Database 및 SQL Server와 같은 데이터 저장소에서 지원하는 변경 내용 추적 기술을 사용하여 델타 데이터를 식별할 수 있습니다.
이 자습서에서는 변경 내용 추적과 함께 Azure Data Factory를 사용하여 Azure SQL Database에서 Azure Blob Storage로 증분식 델타 데이터를 로드하는 방법을 설명합니다. 변경 내용 추적에 대한 자세한 내용은 SQL Server의 변경 내용 추적을 참조하세요.
이 자습서에서 수행하는 단계는 다음과 같습니다.
- 원본 데이터 저장소를 준비합니다.
- 데이터 팩터리를 만듭니다.
- 연결된 서비스만들기.
- 원본, 싱크 및 변경 내용 추적 데이터 세트를 만듭니다.
- 전체 복사 파이프라인을 생성, 실행 및 모니터링합니다.
- 원본 테이블의 데이터를 추가 또는 업데이트합니다.
- 증분 복사 파이프라인을 생성, 실행 및 모니터링합니다.
대략적인 솔루션
이 자습서에서는 다음 작업을 수행하는 두 개의 파이프라인을 만듭니다.
참고 항목
이 자습서는 Azure SQL Database를 원본 데이터 저장소로 사용합니다. SQL Server를 사용할 수도 있습니다.
이력 데이터의 초기 로드: 원본 데이터 저장소(Azure SQL Database)에서 대상 데이터 저장소(Azure Blob Storage)로 전체 데이터를 복사하는 복사 작업으로 파이프라인을 만듭니다.
- Azure SQL Database의 원본 데이터베이스에서 변경 내용 추적 기술을 사용하도록 설정합니다.
- 변경된 데이터를 캡처하기 위한 기준으로 데이터베이스에서
SYS_CHANGE_VERSION의 초기 값을 가져옵니다. - 데이터베이스의 전체 데이터를 Azure Blob Storage로 로드합니다.

일정에 따른 델타 데이터 증분 로드: 다음 작업으로 파이프라인을 만들고 주기적으로 실행합니다.
2개의 조회 작업을 만들어 Azure SQL Database에서 이전 및 새
SYS_CHANGE_VERSION값을 가져옵니다.Azure SQL Database에서 Azure Blob Storage로 두
SYS_CHANGE_VERSION값 사이에 삽입, 업데이트 또는 삭제된 데이터(델타 데이터)를 복사하는 하나의 복사 작업을 만듭니다.sys.change_tracking_tables에서 변경된 행의 기본 키(두SYS_CHANGE_VERSION값 사이)를 원본 테이블의 데이터와 조인하여 델타 데이터를 로드한 다음 델타 데이터를 대상으로 이동합니다.하나의 저장 프로시저 작업을 만들어 다음 파이프라인 실행을 위해
SYS_CHANGE_VERSION값을 업데이트합니다.

필수 조건
- Azure 구독. 구독이 없으면 시작하기 전에 계정을 만드세요.
- Azure SQL Database. Azure SQL Database의 데이터베이스를 원본 데이터 저장소로 사용합니다. 없는 경우 Azure SQL Database에서 데이터베이스 만들기의 단계를 참조하세요.
- Azure 스토리지 계정. Blob Storage를 싱크 데이터 저장소로 사용합니다. Azure Storage 계정이 없는 경우 계정을 만드는 단계는 스토리지 계정 만들기를 참조하세요. adftutorial이라는 컨테이너를 만듭니다.
참고 항목
Azure Az PowerShell 모듈을 사용하여 Azure와 상호 작용하는 것이 좋습니다. 시작하려면 Azure PowerShell 설치를 참조하세요. Az PowerShell 모듈로 마이그레이션하는 방법에 대한 자세한 내용은 Azure PowerShell을 AzureRM에서 Azure로 마이그레이션을 참조하세요.
Azure SQL Database에 데이터 원본 테이블 만들기
SQL Server Management Studio를 열고 SQL Database에 연결합니다.
서버 탐색기에서 데이터베이스를 마우스 오른쪽 단추로 클릭한 다음 새 쿼리를 선택합니다.
데이터베이스에 대해 다음 SQL 명령을 실행하여
data_source_table이라는 테이블을 원본 데이터 저장소로 만듭니다.create table data_source_table ( PersonID int NOT NULL, Name varchar(255), Age int PRIMARY KEY (PersonID) ); INSERT INTO data_source_table (PersonID, Name, Age) VALUES (1, 'aaaa', 21), (2, 'bbbb', 24), (3, 'cccc', 20), (4, 'dddd', 26), (5, 'eeee', 22);다음 SQL 쿼리를 실행하여 데이터베이스 및 원본 테이블(
data_source_table)에서 변경 내용 추적을 사용하도록 설정합니다.참고 항목
<your database name>을data_source_table이 있는 Azure SQL Database의 데이터베이스 이름으로 바꿉니다.- 현재 예제에서 변경된 데이터는 2일간 유지됩니다. 3일(또는 그 이상)마다 변경된 데이터를 로드하는 경우 일부 변경된 데이터가 포함되지 않습니다.
CHANGE_RETENTION의 값을 더 큰 숫자로 변경하거나 변경된 데이터를 로드하는 기간이 2일 이내인지 확인해야 합니다. 자세한 내용은 데이터베이스에 대한 변경 내용 추적 사용을 참조하세요.
ALTER DATABASE <your database name> SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON) ALTER TABLE data_source_table ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)다음 쿼리를 실행하여 기본값으로
ChangeTracking_version이라는 새 테이블과 저장소를 만듭니다.create table table_store_ChangeTracking_version ( TableName varchar(255), SYS_CHANGE_VERSION BIGINT, ); DECLARE @ChangeTracking_version BIGINT SET @ChangeTracking_version = CHANGE_TRACKING_CURRENT_VERSION(); INSERT INTO table_store_ChangeTracking_version VALUES ('data_source_table', @ChangeTracking_version)참고 항목
SQL Database에 대한 변경 내용 추적을 사용하도록 설정한 후 데이터가 변경되지 않으면 변경 내용 추적 버전의 값은
0입니다.다음 쿼리를 실행하여 데이터베이스에 저장 프로시저를 만듭니다. 파이프라인이 이전 단계에서 만든 테이블에서 변경 내용 추적 버전을 업데이트하도록 저장 프로시저를 호출합니다.
CREATE PROCEDURE Update_ChangeTracking_Version @CurrentTrackingVersion BIGINT, @TableName varchar(50) AS BEGIN UPDATE table_store_ChangeTracking_version SET [SYS_CHANGE_VERSION] = @CurrentTrackingVersion WHERE [TableName] = @TableName END
데이터 팩터리 만들기
Microsoft Edge 또는 Google Chrome 웹 브라우저를 엽니다. 현재 이러한 브라우저만 Data Factory UI(사용자 인터페이스)를 지원합니다.
Azure Portal의 왼쪽 메뉴에서 리소스 만들기를 선택합니다.
통합>데이터 팩터리를 선택합니다.
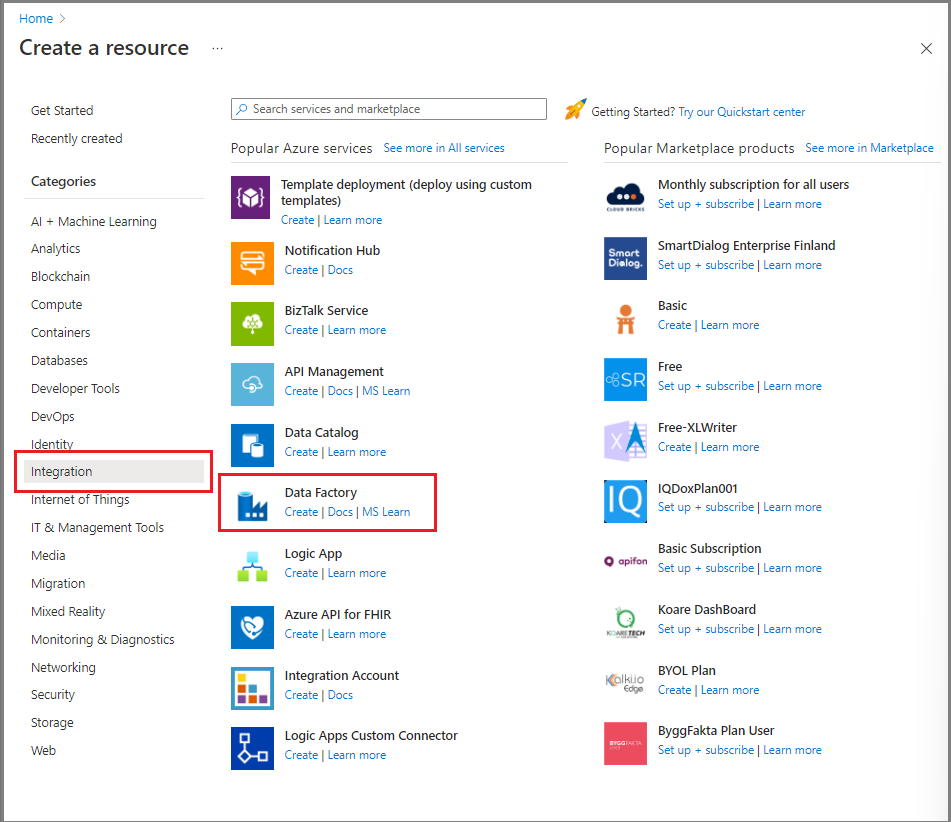
새 데이터 팩터리 페이지에서 이름에 대해 ADFTutorialDataFactory를 입력합니다.
데이터 팩터리 이름은 전역적으로 고유해야 합니다. 선택한 이름을 사용할 수 없다는 오류가 표시되면 이름을 변경(예: yournameADFTutorialDataFactory)하고 데이터 팩터리를 다시 만들어 보세요. 자세한 내용은 Azure Data Factory 명명 규칙을 참조하세요.
데이터 팩터리를 만들 Azure 구독을 선택합니다.
리소스 그룹에 대해 다음 단계 중 하나를 사용합니다.
- 기존 항목 사용을 선택한 다음 드롭다운 목록에서 기존 리소스 그룹을 선택합니다.
- 새로 만들기를 선택한 다음 리소스 그룹의 이름을 입력합니다.
리소스 그룹에 대한 자세한 내용은 리소스 그룹을 사용하여 Azure 리소스 관리를 참조하세요.
버전에서 V2를 선택합니다.
지역에서 데이터 팩터리의 지역을 선택합니다.
드롭다운 목록에는 지원되는 위치만 표시됩니다. 데이터 팩터리에서 사용하는 데이터 저장소(예: Azure Storage 및 Azure SQL Database) 및 컴퓨팅(예: Azure HDInsight)은 다른 지역에 있을 수 있습니다.
다음: Git 구성을 선택합니다. 구성 방법 4: 팩터리 만들기 중의 지침에 따라 리포지토리를 설정하거나 Git 나중에 구성 확인란을 선택합니다.
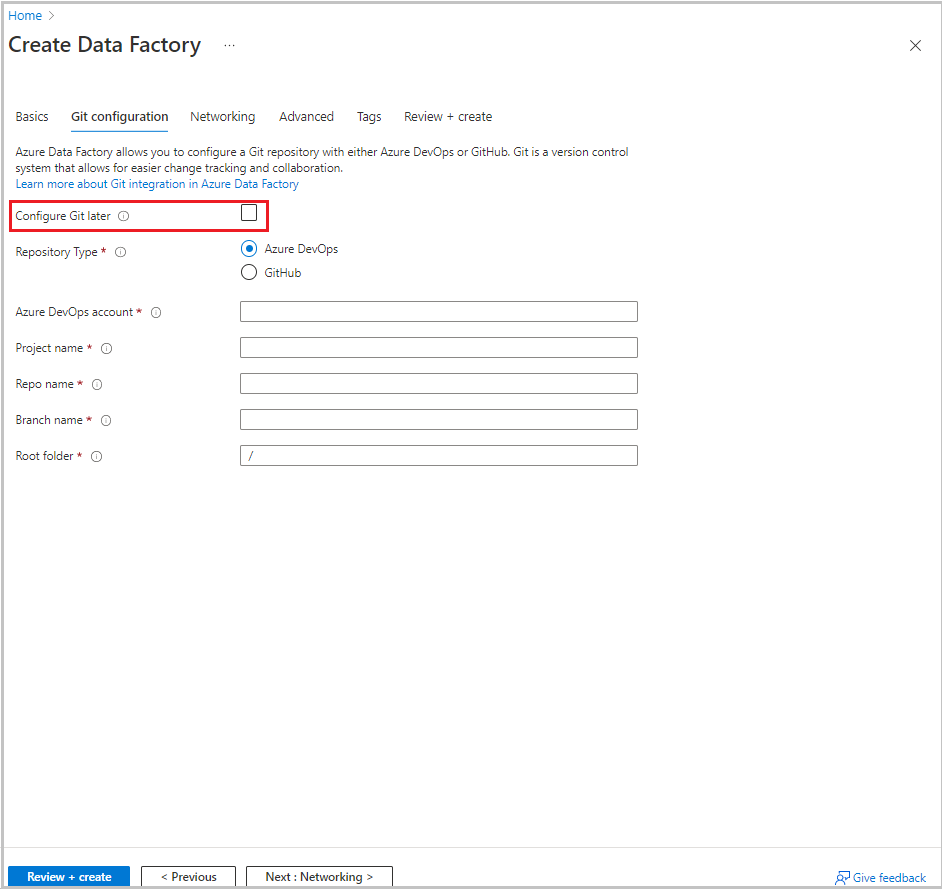
검토 + 만들기를 선택합니다.
만들기를 선택합니다.
대시보드에서 Data Factory 배포 타일에 상태가 표시됩니다.

만들기가 완료되면 Data Factory 페이지가 나타납니다. 스튜디오 시작 타일을 선택하여 별도의 탭에서 Azure Data Factory UI를 엽니다.
연결된 서비스 생성
데이터 팩터리에서 연결된 서비스를 만들어 데이터 저장소를 연결하고 컴퓨팅 서비스를 데이터 팩터리에 연결합니다. 이 섹션에서는 Azure Storage 계정과 Azure SQL Database의 데이터베이스에 연결된 서비스를 만듭니다.
Azure Storage 연결된 서비스 만들기
스토리지 계정을 데이터 팩터리에 연결하려면 다음을 수행합니다.
- Data Factory UI의 관리 탭에 있는 연결에서 연결된 서비스를 선택합니다. 그런 다음 + 새로 만들기 또는 연결된 서비스 만들기 단추를 선택합니다.
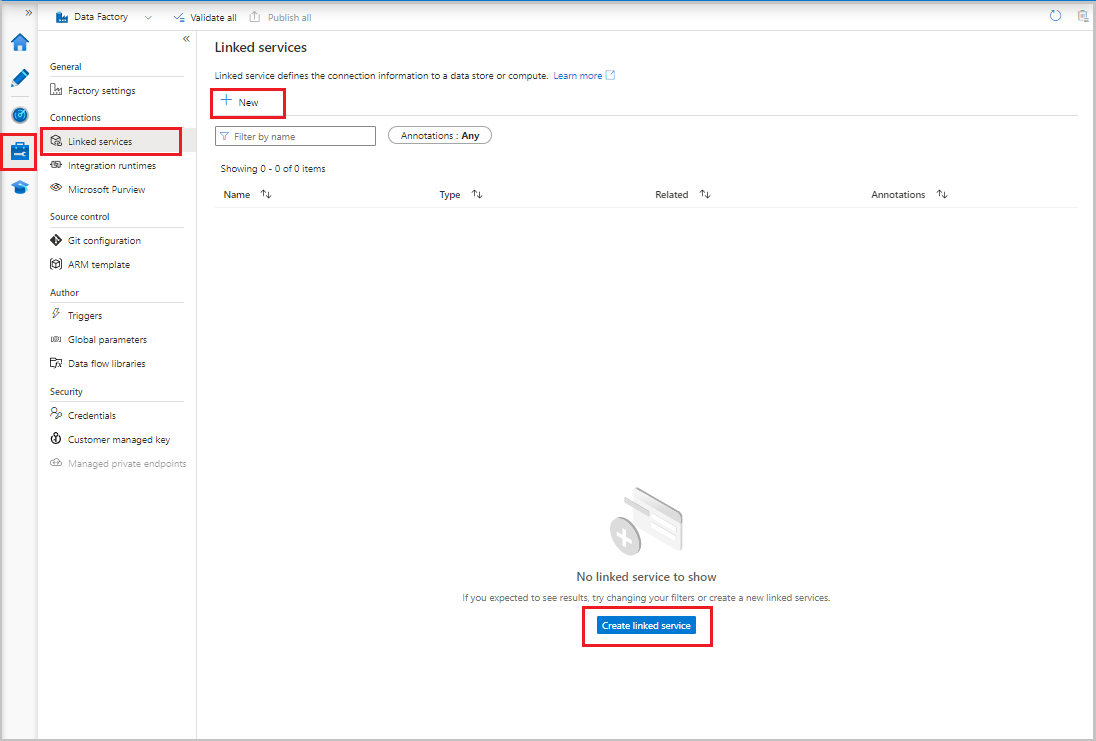
- 새 연결된 서비스 창에서 Azure Blob Storage를 선택한 다음 계속을 선택합니다.
- 다음 정보를 입력합니다.
- 이름에 대해 AzureStorageLinkedService를 입력합니다.
- 통합 런타임을 통해 연결에서 통합 런타임을 선택합니다.
- 인증 형식에서 인증 방법을 선택합니다.
- 스토리지 계정 이름에서 Azure Storage 계정을 선택합니다.
- 만들기를 실행합니다.
Azure SQL Database 연결된 서비스 만들기
데이터베이스를 데이터 팩터리에 연결하려면:
Data Factory UI의 관리 탭에 있는 연결에서 연결된 서비스를 선택합니다. 그런 다음, + 새로 만들기를 선택합니다.
새 연결된 서비스 창에서 Azure SQL Database를 선택한 다음 계속을 선택합니다.
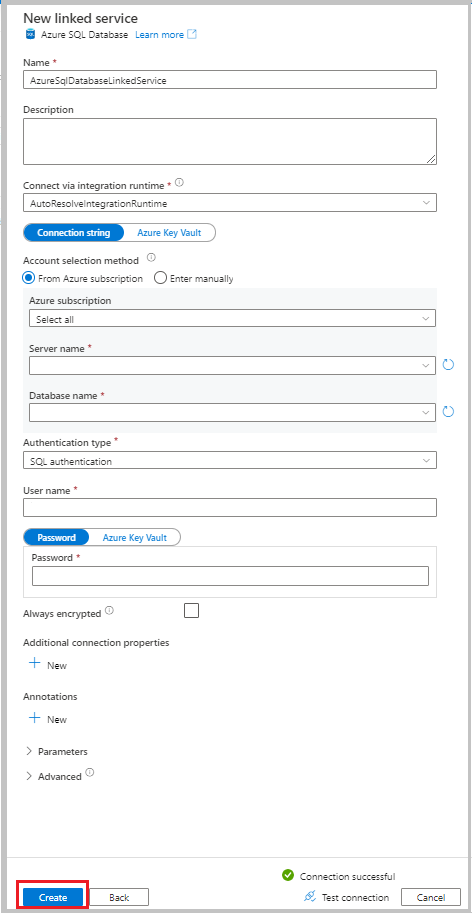
다음 정보를 입력합니다.
- 이름에 대해 AzureSqlDatabaseLinkedService를 입력합니다.
- 서버 이름에서 서버를 선택합니다.
- 데이터베이스 이름에서 데이터베이스를 선택합니다.
- 인증 형식에서 인증 방법을 선택합니다. 이 자습서에서는 데모를 위해 SQL 인증을 사용합니다.
- 사용자 이름에 사용자의 이름을 입력합니다.
- 암호에 사용자의 암호를 입력합니다. 또는 Azure Key Vault - AKV 연결된 서비스, 비밀 이름 및 비밀 버전에 대한 정보를 제공합니다.
연결 테스트를 선택하여 연결을 테스트합니다.
만들기를 선택하여 연결된 서비스를 만듭니다.
데이터 세트 생성
이 섹션에서는 SYS_CHANGE_VERSION 값을 저장할 위치와 함께 데이터 원본 및 데이터 대상을 나타내는 데이터 세트를 만듭니다.
원본 데이터를 나타내는 데이터 세트 만들기
Data Factory UI의 작성자 탭에서 더하기 기호(+)를 선택합니다. 그런 다음 데이터 세트를 선택하거나 데이터 세트 작업에 대한 줄임표를 선택합니다.
Azure SQL Database를 선택한 다음, 계속을 선택합니다.
속성 설정 창에서 다음 단계를 수행합니다.
- 이름에 SourceDataset를 입력합니다.
- 연결된 서비스에 대해 AzureSqlDatabaseLinkedService를 선택합니다.
- 테이블 이름으로 dbo.data_source_table을 선택합니다.
- 스키마 가져오기의 경우 연결/저장에서 옵션을 선택합니다.
- 확인을 선택합니다.

싱크 데이터 저장소에 복사된 데이터를 나타내는 데이터 세트 만들기
다음 프로시저에서는 원본 데이터 저장소에서 복사된 데이터를 나타내는 데이터 세트를 만듭니다. 필수 구성 요소의 일부로 adftutorial 컨테이너를 Azure Blob Storage에 만들었습니다. 컨테이너가 없으면 만들거나 기존 컨테이너의 이름으로 설정합니다. 이 자습서에서 출력 파일 이름은 식 @CONCAT('Incremental-', pipeline().RunId, '.txt')에서 동적으로 생성됩니다.
Data Factory UI의 작성자 탭에서 +를 선택합니다. 그런 다음 데이터 세트를 선택하거나 데이터 세트 작업에 대한 줄임표를 선택합니다.
Azure Blob Storage를 선택한 다음 계속을 선택합니다.
데이터 형식의 형식을 DelimitedText로 선택한 다음 계속을 선택합니다.
속성 설정 창에서 다음 단계를 수행합니다.
- 이름에 SinkDataset를 입력합니다.
- 연결된 서비스에 대해 AzureBlobStorageLinkedService를 선택합니다.
- 파일 경로에 adftutorial/incchgtracking을 입력합니다.
- 확인을 선택합니다.
데이터 세트가 트리 뷰에 나타나면 연결 탭으로 이동하여 파일 이름 텍스트 상자를 선택합니다. 동적 콘텐츠 추가 옵션이 표시되면 선택합니다.
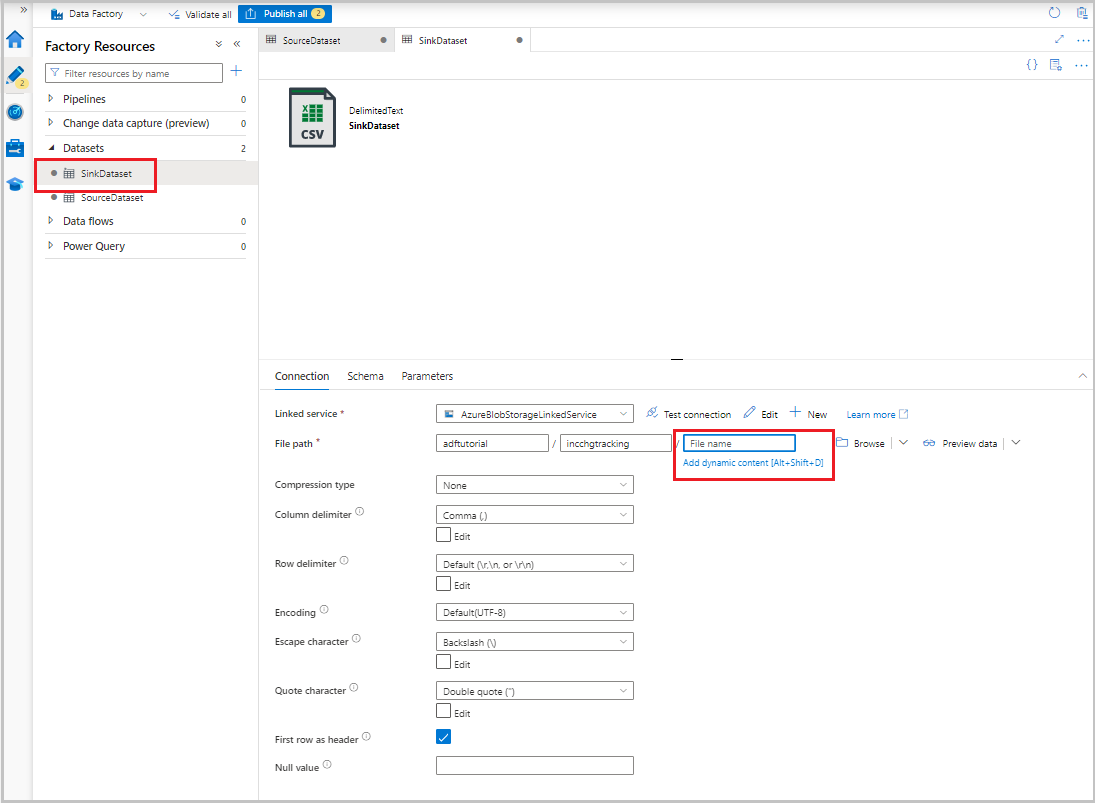
파이프라인 식 빌더 창이 나타납니다. 텍스트 상자에
@concat('Incremental-',pipeline().RunId,'.csv')를 붙여넣습니다.확인을 선택합니다.
변경 내용 추적 데이터를 나타내는 데이터 세트 만들기
다음 프로시저에서는 변경 내용 추적 버전을 저장하기 위한 데이터 세트를 만듭니다. 필수 구성 요소의 일부로 table_store_ChangeTracking_version 테이블을 만들었습니다.
- Data Factory UI의 작성자 탭에서 +을 선택한 다음 데이터 세트를 선택합니다.
- Azure SQL Database를 선택한 다음, 계속을 선택합니다.
- 속성 설정 창에서 다음 단계를 수행합니다.
- 이름에 ChangeTrackingDataset를 입력합니다.
- 연결된 서비스에 대해 AzureSqlDatabaseLinkedService를 선택합니다.
- 테이블 이름으로 dbo.table_store_ChangeTracking_version을 선택합니다.
- 스키마 가져오기의 경우 연결/저장에서 옵션을 선택합니다.
- 확인을 선택합니다.
전체 복사본에 대한 파이프라인 만들기
다음 프로시저에서는 원본 데이터 저장소(Azure SQL Database)에서 대상 데이터 저장소(Azure Blob Storage)로 전체 데이터를 복사하는 복사 작업이 포함된 파이프라인을 만듭니다.
Data Factory UI의 작성자 탭에서 +를 선택한 다음 파이프라인>파이프라인을 선택합니다.
파이프라인 구성을 위한 새 탭이 나타납니다. 파이프라인은 트리 뷰에도 나타납니다. 속성 창에서 파이프라인 이름을 FullCopyPipeline으로 변경합니다.
작업 도구 상자에서 이동 및 변환을 펼칩니다. 다음 단계 중 하나를 수행합니다.
- 복사 작업을 파이프라인 디자이너 화면으로 끌어 놓습니다.
- 작업 아래의 검색 창에서 복사 데이터 작업을 검색한 다음 이름을 FullCopyActivity로 설정합니다.
원본 탭으로 전환합니다. Source Dataset에서 SourceDataset를 선택합니다.
싱크 탭으로 전환합니다. Sink Dataset에서 SinkDataset를 선택합니다.
파이프라인 정의의 유효성을 검사하려면 도구 모음에서 유효성 검사를 선택합니다. 유효성 검사 오류가 없는지 확인합니다. 파이프라인 유효성 검사 출력을 닫습니다.
항목(연결된 서비스, 데이터 세트 및 파이프라인)을 게시하려면 모두 게시를 선택합니다. 게시됨 메시지가 표시될 때까지 기다립니다.
알림을 보려면 알림 표시 단추를 선택합니다.
전체 복사 파이프라인 실행
Data Factory UI의 파이프라인 도구 모음에서 트리거 추가를 선택한 다음 지금 트리거를 선택합니다.
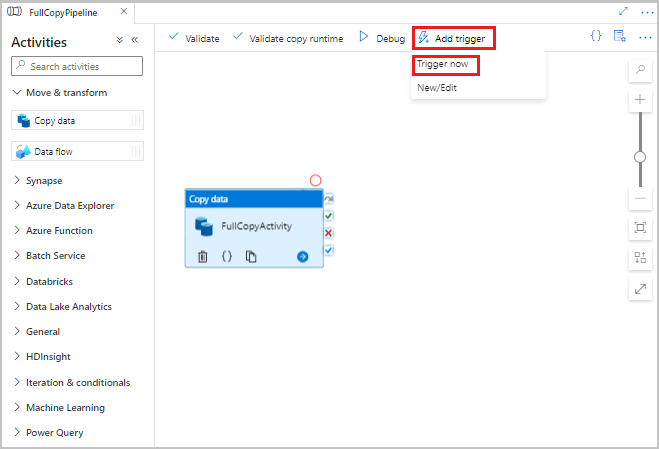
파이프라인 실행 창에서 확인을 선택합니다.

전체 복사 파이프라인 모니터링
Data Factory UI에서 모니터 탭을 선택합니다. 파이프라인 실행 및 해당 상태가 목록에 나타납니다. 목록을 새로 고침하려면 새로 고침을 선택합니다. 다시 실행 또는 사용량 옵션을 가져오려면 파이프라인 실행 위로 마우스를 가져갑니다.
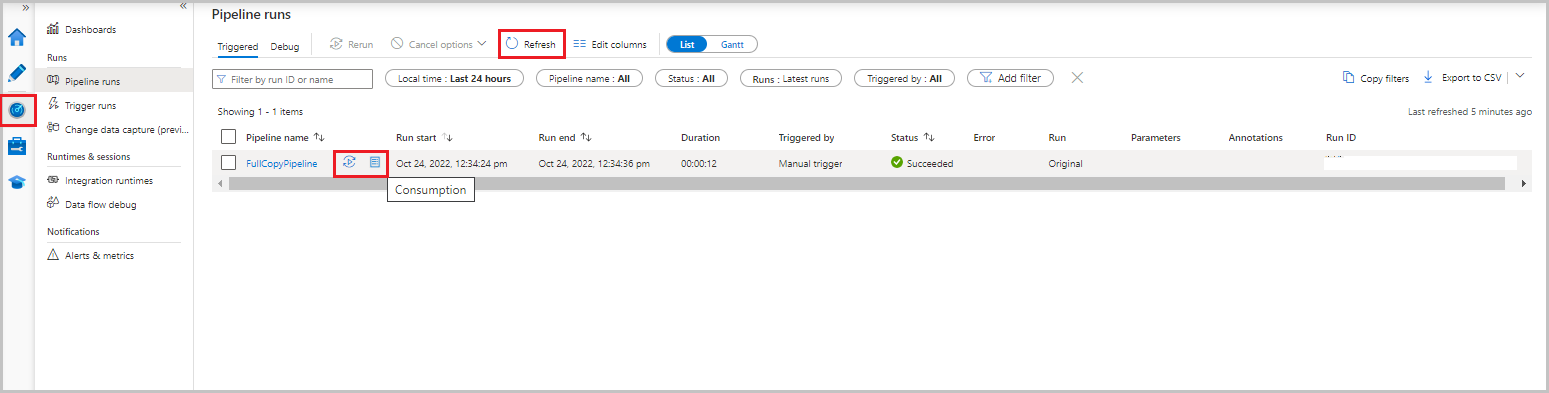
파이프라인 실행과 관련된 활동 실행을 보려면 파이프라인 이름 열에서 파이프라인 이름을 선택합니다. 파이프라인에는 하나의 작업만 있으므로 목록에는 하나의 항목만 있습니다. 파이프라인 실행 보기로 다시 전환하려면 상단에서 모든 파이프라인 실행 링크를 선택합니다.
결과 검토
adftutorial 컨테이너의 incchgtracking 폴더에는 incremental-<GUID>.csv라는 파일이 포함되어 있습니다.
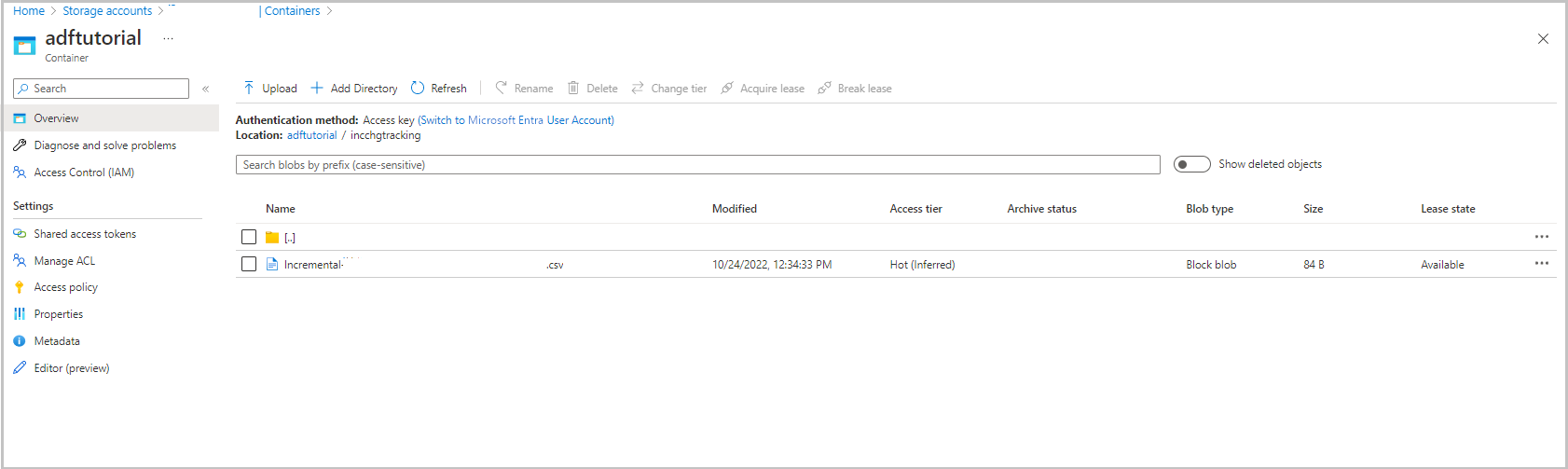
파일에는 데이터베이스의 데이터가 있어야 합니다.
PersonID,Name,Age
1,"aaaa",21
2,"bbbb",24
3,"cccc",20
4,"dddd",26
5,"eeee",22
5,eeee,PersonID,Name,Age
1,"aaaa",21
2,"bbbb",24
3,"cccc",20
4,"dddd",26
5,"eeee",22
원본 테이블에 데이터 추가
데이터베이스에 다음 쿼리를 실행하여 행을 추가하고 행을 업데이트합니다.
INSERT INTO data_source_table
(PersonID, Name, Age)
VALUES
(6, 'new','50');
UPDATE data_source_table
SET [Age] = '10', [name]='update' where [PersonID] = 1
델타 복사를 위한 파이프라인 만들기
다음 프로시저에서는 작업이 포함된 파이프라인을 만들고 주기적으로 실행합니다. 파이프라인을 실행할 때:
- 조회 작업은 Azure SQL Database에서 이전 및 새
SYS_CHANGE_VERSION값을 가져와 복사 작업에 전달합니다. - 복사 작업은 Azure SQL Database에서 Azure Blob Storage로 두
SYS_CHANGE_VERSION값 사이에 삽입, 업데이트 또는 삭제된 데이터를 복사합니다. - 저장 프로시저 작업은 다음 파이프라인 실행을 위해
SYS_CHANGE_VERSION값을 업데이트합니다.
Data Factory UI에서 작성자 탭으로 전환합니다. +을 선택한 다음 파이프라인>파이프라인을 선택합니다.
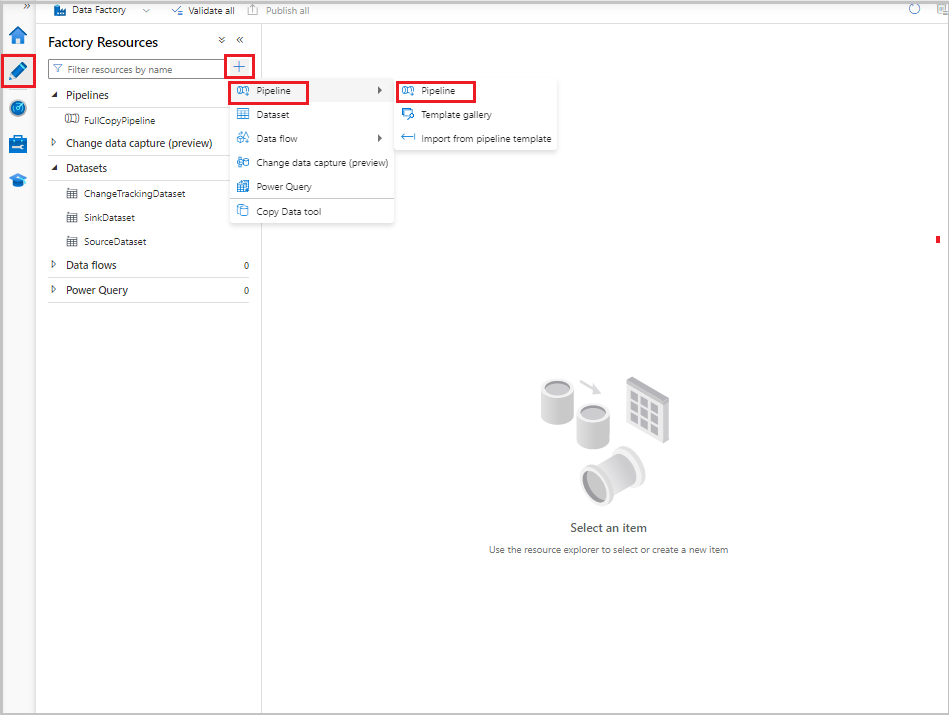
파이프라인 구성을 위한 새 탭이 나타납니다. 파이프라인은 트리 뷰에도 나타납니다. 속성 창에서 파이프라인 이름을 IncrementalCopyPipeline으로 변경합니다.
작업 도구 상자에서 일반을 확장합니다. 조회 작업을 파이프라인 디자이너 화면으로 끌어 놓거나 검색 작업 상자에서 검색합니다. 활동 이름을 LookupLastChangeTrackingVersionActivity로 설정합니다. 이 작업은
table_store_ChangeTracking_version테이블에 저장된 마지막 복사 작업에서 사용된 변경 내용 추적 버전을 가져옵니다.속성 창의 설정 탭으로 전환합니다. 원본 데이터 세트에 대해 ChangeTrackingDataset를 선택합니다.
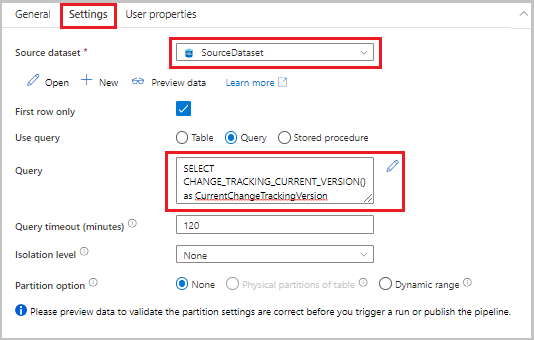
조회 작업을 작업 도구 상자에서 파이프라인 디자이너 화면으로 끌어 놓습니다. 활동 이름을 LookupCurrentChangeTrackingVersionActivity로 설정합니다. 이 활동은 현재 변경 내용 추적 버전을 가져옵니다.
속성 창에서 설정 탭으로 전환한 후 다음 단계를 수행합니다.
원본 데이터 세트에서 SourceDataset를 선택합니다.
쿼리 사용에서 쿼리를 선택합니다.
쿼리에 다음 SQL 쿼리를 입력합니다.
SELECT CHANGE_TRACKING_CURRENT_VERSION() as CurrentChangeTrackingVersion
작업 도구 상자에서 이동 및 변환을 펼칩니다. 데이터 복사 작업을 파이프라인 디자이너 화면으로 끌어 놓습니다. 활동 이름을 IncrementalCopyActivity로 설정합니다. 이 작업은 마지막 변경 내용 추적 버전과 현재 변경 내용 추적 버전 사이의 데이터를 대상 데이터 저장소에 복사합니다.
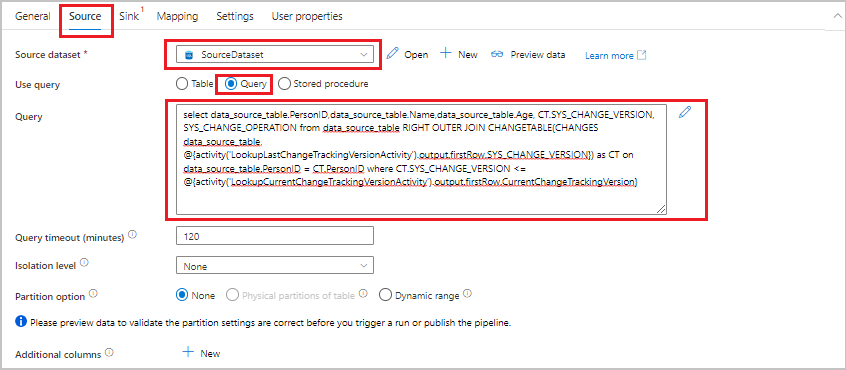
속성 창에서 원본 탭으로 전환한 후 다음 단계를 수행합니다.
원본 데이터 세트에서 SourceDataset를 선택합니다.
쿼리 사용에서 쿼리를 선택합니다.
쿼리에 다음 SQL 쿼리를 입력합니다.
SELECT data_source_table.PersonID,data_source_table.Name,data_source_table.Age, CT.SYS_CHANGE_VERSION, SYS_CHANGE_OPERATION from data_source_table RIGHT OUTER JOIN CHANGETABLE(CHANGES data_source_table, @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.SYS_CHANGE_VERSION}) AS CT ON data_source_table.PersonID = CT.PersonID where CT.SYS_CHANGE_VERSION <= @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}
싱크 탭으로 전환합니다. Sink Dataset에서 SinkDataset를 선택합니다.
두 개의 조회 작업을 하나씩 복사 작업에 연결합니다. 조회 작업에 연결된 녹색 단추를 복사 작업으로 끌어 놓습니다.
저장 프로시저 작업을 작업 도구 상자에서 파이프라인 디자이너 화면으로 끌어 놓습니다. 활동 이름을 StoredProceduretoUpdateChangeTrackingActivity로 설정합니다. 이 작업은
table_store_ChangeTracking_version테이블의 변경 내용 추적 버전을 업데이트합니다.설정 탭으로 전환한 후 다음 단계를 따릅니다.
- 연결된 서비스에 대해 AzureSqlDatabaseLinkedService를 선택합니다.
- 저장 프로시저 이름에 대해 Update_ChangeTracking_Version을 선택합니다.
- 가져오기를 선택합니다.
- 저장 프로시저 매개 변수 섹션에서 매개 변수에 대해 다음 값을 지정합니다.
이름 타입 값 CurrentTrackingVersionInt64 @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}TableName문자열 @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.TableName}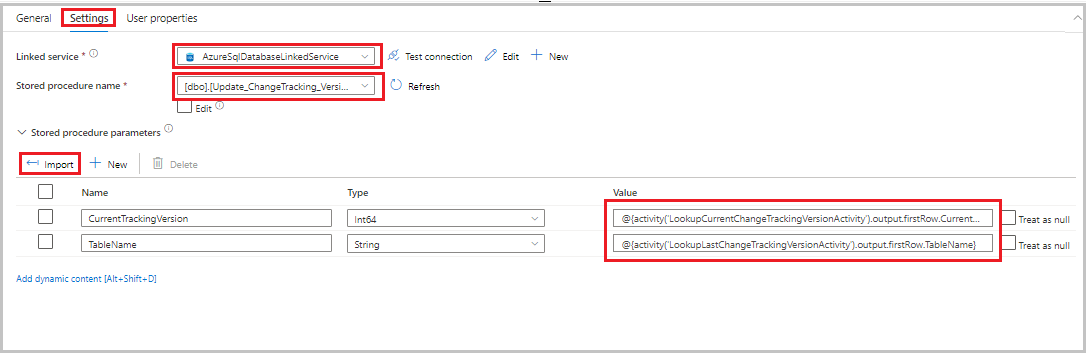
복사 작업을 저장 프로시저 작업에 연결합니다. 복사 작업에 연결된 녹색 단추를 저장 프로시저 작업으로 끌어 놓습니다.
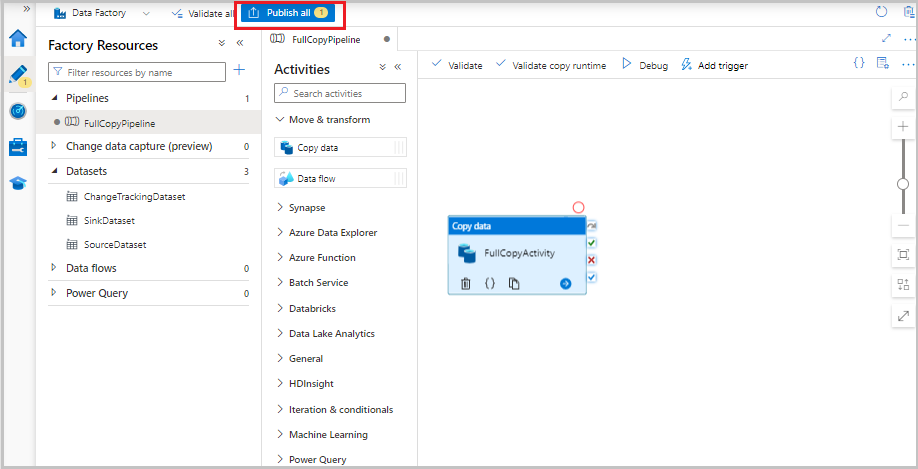
도구 모음에서 유효성 검사를 선택합니다. 유효성 검사 오류가 없는지 확인합니다. 파이프라인 유효성 검사 보고서 창을 닫습니다.
모두 게시 단추를 선택하여 엔터티(연결된 서비스, 데이터 세트 및 파이프라인)를 Data Factory 서비스에 게시합니다. 게시 성공 메시지가 나타날 때까지 기다립니다.
증분 복사 파이프라인 실행
파이프라인에 대한 도구 모음에서 트리거 추가를 선택한 다음, 지금 트리거를 선택합니다.
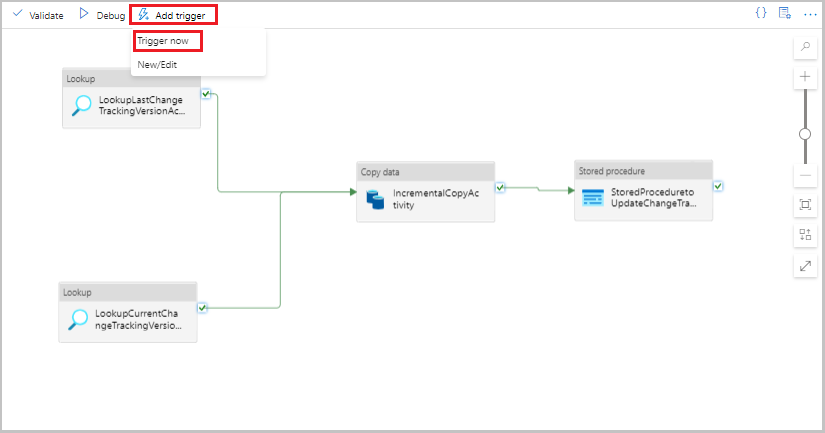
파이프라인 실행 창에서 확인을 선택합니다.
증분 복사 파이프라인 모니터링
모니터 탭을 선택합니다. 파이프라인 실행 및 해당 상태가 목록에 나타납니다. 목록을 새로 고침하려면 새로 고침을 선택합니다.
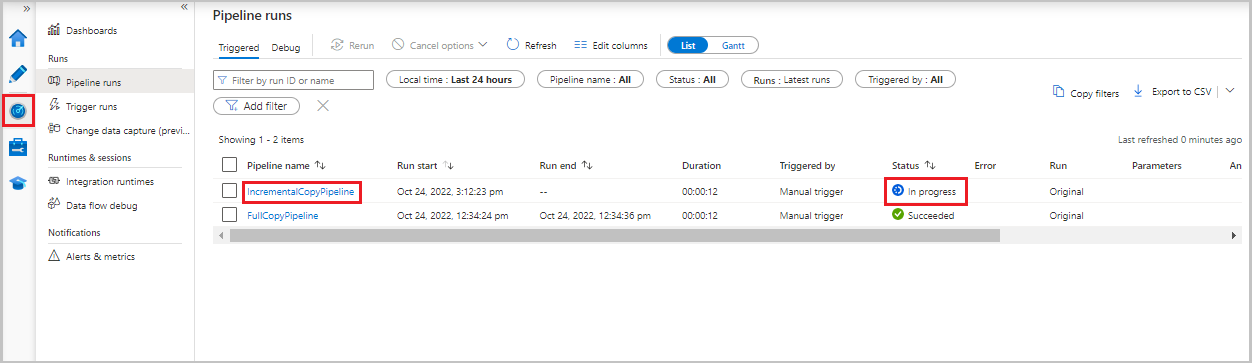
파이프라인 실행과 관련된 활동 실행을 보려면 파이프라인 이름 열에서 IncrementalCopyPipeline 링크를 선택합니다. 활동 실행이 목록에 나타납니다.
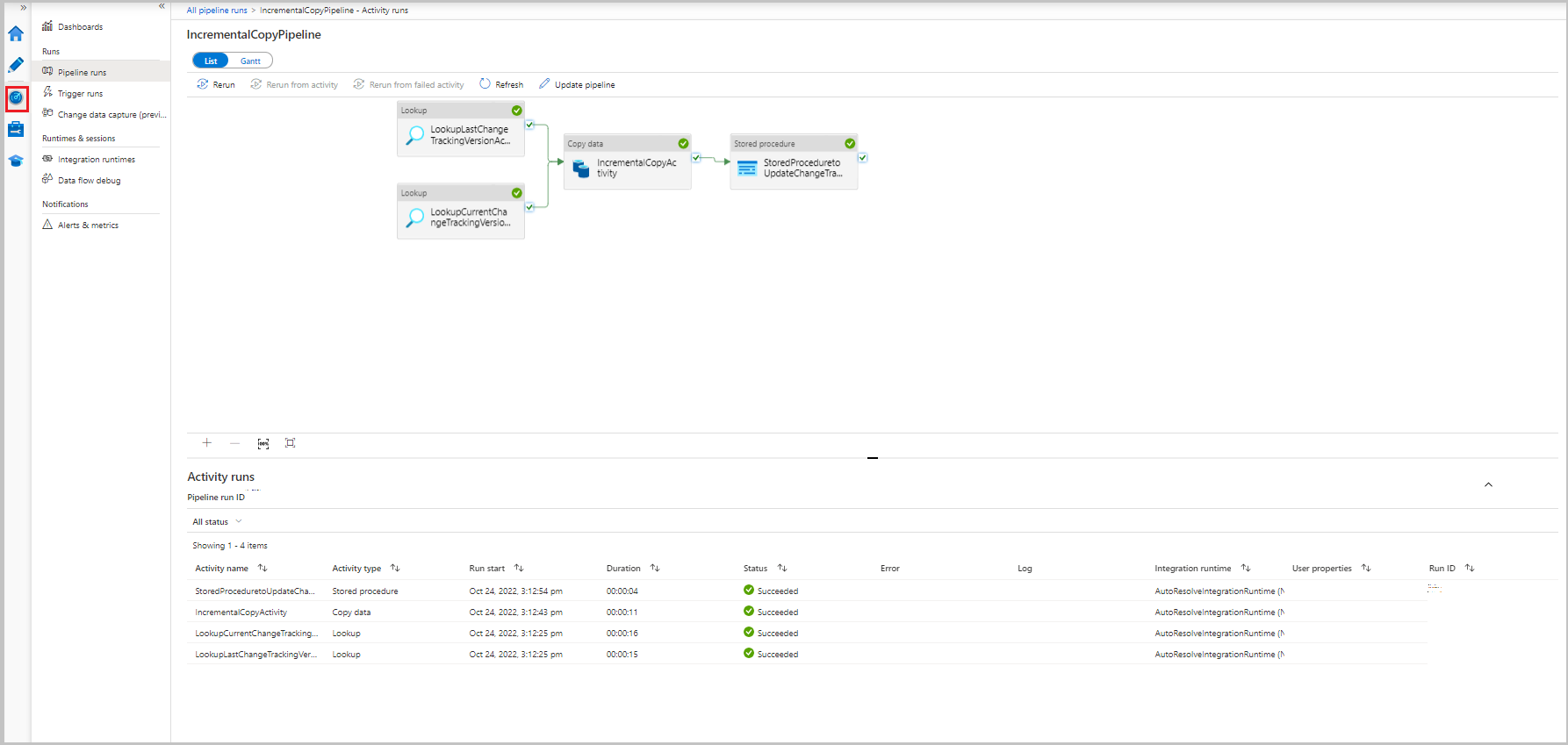
결과 검토
두 번째 파일은 adftutorial 컨테이너의 incchgtracking 폴더에 나타납니다.
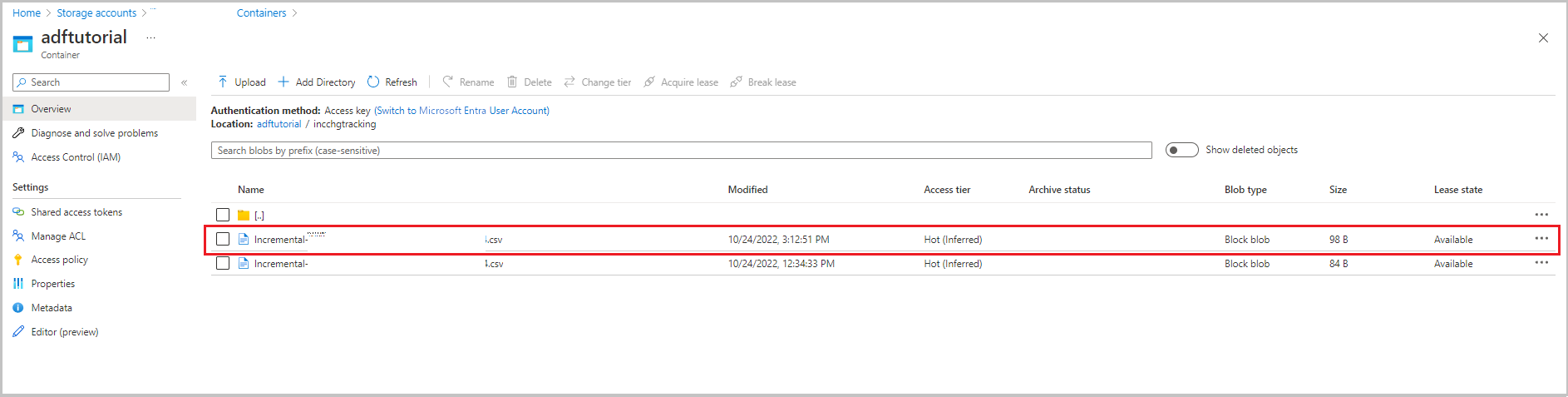
파일에는 데이터베이스의 델타 데이터만 포함되어야 합니다. U가 포함된 레코드가 데이터베이스에서 업데이트된 행이고 I가 추가된 행입니다.
PersonID,Name,Age,SYS_CHANGE_VERSION,SYS_CHANGE_OPERATION
1,update,10,2,U
6,new,50,1,I
처음 세 열은 data_source_table에서 변경된 데이터입니다. 마지막 두 열은 변경 내용 추적 시스템에 대한 테이블의 메타데이터입니다. 네 번째 열은 변경된 각 행의 SYS_CHANGE_VERSION 값입니다. 다섯 번째 열은 작업입니다. U = 업데이트, I = 삽입. 변경 내용 추적 정보에 대한 자세한 내용은 CHANGETABLE을 참조하세요.
==================================================================
PersonID Name Age SYS_CHANGE_VERSION SYS_CHANGE_OPERATION
==================================================================
1 update 10 2 U
6 new 50 1 I
관련 콘텐츠
LastModifiedDate를 기반으로 새 파일과 변경된 파일만 복사하는 방법에 대해 알아보려면 다음 자습서로 이동합니다.