Azure Data Factory 및 Synapse Analytics에서 지원되는 파일 형식 및 압축 코덱(레거시)
적용 대상:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
이 문서는 Amazon S3, Azure Blob, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, HTTP 및 SFTP 커넥터에 적용됩니다.
Important
서비스에서는 새 형식 기반 데이터 세트 모델을 도입했습니다. 자세한 내용은 해당 형식 문서를 참조하세요.
- Avro 형식
- 이진 형식
- 구분된 텍스트 형식
- JSON 형식
- ORC 형식
- Parquet 형식
이 문서에 언급된 나머지 구성은 이전 버전과의 호환성을 위해 그대로 지원됩니다. 앞으로는 새 모델을 사용하는 것이 좋습니다.
텍스트 형식(레거시)
참고 항목
구분된 텍스트 형식 문서의 새 모델에 대해 알아봅니다. 파일 기반 데이터 저장소 데이터 세트에 대한 다음 구성은 이전 버전과의 호환성을 위해 그대로 지원됩니다. 앞으로는 새 모델을 사용하는 것이 좋습니다.
텍스트 파일을 읽거나 텍스트 파일에 쓰려면 데이터 세트의 format 섹션에서 type 속성을 TextFormat으로 지정합니다. format 섹션에서 다음 선택적 속성을 지정할 수도 있습니다. 구성 방법은 TextFormat 예제 섹션을 참조하세요.
| 속성 | 설명 | 허용된 값 | 필수 |
|---|---|---|---|
| columnDelimiter | 파일의 열을 구분하는 데 사용되는 문자입니다. 데이터에 없을 가능성이 높은 인쇄할 수 없는 희귀 문자를 사용하도록 고려할 수도 있습니다. 예를 들어 헤딩의 시작(SOH)을 나타내는 "\u0001"을 지정합니다. | 하나의 문자만 허용됩니다. 기본값은 쉼표(,)입니다. 유니코드 문자를 사용하려면 유니코드 문자를 참조하여 해당하는 코드를 가져옵니다. |
아니요 |
| rowDelimiter | 파일의 행을 구분하는 데 사용되는 문자입니다. | 하나의 문자만 허용됩니다. 기본값은 읽기의 경우 ["\r\n", "\r", "\n"] 중 하나이고, 쓰기의 경우 "\r\n"입니다. | 아니요 |
| escapeChar | 입력 파일의 내용에서 열 구분 기호를 이스케이프하는 데 사용되는 특수 문자입니다. 테이블에 escapeChar와 quoteChar를 둘 다 지정할 수 없습니다. |
하나의 문자만 허용됩니다. 기본값이 없습니다. 예: 열 구분 기호로 쉼표(',')를 지정했는데 텍스트에서도 "Hello, world"와 같이 쉼표 문자를 포함하려는 경우에는 이스케이프 문자로 '$'를 정의하고 원본에서 "Hello$, world" 문자열을 사용하면 됩니다. |
아니요 |
| quoteChar | 문자열 값을 인용하는 데 사용되는 문자입니다. 인용 문자 안의 열과 행 구분 기호는 문자열 값의 일부로 처리됩니다. 이 속성은 입력 및 출력 데이터 세트 모두에 적용할 수 있습니다. 테이블에 escapeChar와 quoteChar를 둘 다 지정할 수 없습니다. |
하나의 문자만 허용됩니다. 기본값이 없습니다. 예를 들어 열 구분 기호로 쉼표(‘,’)를 지정했는데 텍스트에서도 <Hello, world>와 같이 쉼표 문자를 포함하려는 경우에는 인용 문자로 "(큰따옴표)를 정의하고 원본에서 “Hello, world” 문자열을 사용하면 됩니다. |
아니요 |
| nullValue | null 값을 나타내는 데 사용되는 하나 이상의 문자입니다. | 하나 이상의 문자입니다. 기본값은 읽기의 경우 "\N" 및 "NULL"이고, 쓰기의 경우 "\N"입니다. | 아니요 |
| encodingName | 인코딩 이름을 지정합니다. | 유효한 인코딩 이름입니다. Encoding.EncodingName 속성을 참조하세요. windows-1250 또는 shift_jis 등을 예로 들 수 있습니다. 기본값은 UTF-8입니다. | 아니요 |
| firstRowAsHeader | 첫 번째 행을 머리글로 간주할지를 지정합니다. 입력 데이터 세트의 경우 서비스는 첫 번째 행을 머리글로 읽습니다. 출력 데이터 세트의 경우 서비스는 첫 번째 행을 머리글로 씁니다. 샘플 시나리오의 경우 firstRowAsHeader 및 skipLineCount 사용 시나리오를 참조하세요. |
True False(기본값) |
아니요 |
| skipLineCount | 입력 파일에서 데이터를 읽을 때 건너뛸 비어 있지 않은 행의 수를 나타냅니다. skipLineCount와 firstRowAsHeader가 모두 지정되면 먼저 줄을 건너뛴 다음, 입력 파일에서 헤더 정보를 읽습니다. 샘플 시나리오의 경우 firstRowAsHeader 및 skipLineCount 사용 시나리오를 참조하세요. |
정수 | 아니요 |
| treatEmptyAsNull | 입력 파일에서 데이터를 읽을 때 null 또는 빈 문자열을 null 값으로 처리할지 여부를 지정합니다. | True(기본값) False |
아니요 |
TextFormat 예제
데이터 세트에 대한 다음 JSON 정의에서 선택적 속성 중 일부가 지정됩니다.
"typeProperties":
{
"folderPath": "mycontainer/myfolder",
"fileName": "myblobname",
"format":
{
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": ";",
"quoteChar": "\"",
"NullValue": "NaN",
"firstRowAsHeader": true,
"skipLineCount": 0,
"treatEmptyAsNull": true
}
},
quoteChar 대신 escapeChar을 사용하려면 quoteChar이 있는 줄을 다음 escapeChar로 바꿉니다.
"escapeChar": "$",
FirstRowAsHeader 및 skipLineCount 사용 시나리오
- 파일이 아닌 원본에서 텍스트 파일로 데이터를 복사할 때 SQL 스키마 등의 스키마 메타데이터가 포함된 머리글 줄을 추가하려고 합니다. 이 시나리오의 출력 데이터 세트에서
firstRowAsHeader를 true로 지정합니다. - 머리글 줄이 포함된 텍스트 파일에서 파일이 아닌 싱크로 데이터를 복사할 때 해당 줄을 삭제하려고 합니다. 입력 데이터 세트에서
firstRowAsHeader를 true로 지정합니다. - 텍스트 파일에서 데이터를 복사할 때 시작 부분에서 데이터도 없고 머리글 정보도 없는 몇 줄을 건너뛰려고 합니다. 건너뛸 줄 수를 나타내는
skipLineCount를 지정합니다. 파일의 나머지 부분에 헤더 줄이 있으면firstRowAsHeader도 지정할 수 있습니다.skipLineCount와firstRowAsHeader를 둘 다 지정하면 먼저 해당 줄을 먼저 건너뛴 다음 입력 파일에서 헤더 정보를 읽습니다.
JSON 형식(레거시)
참고 항목
JSON 형식 문서의 새 모델에 대해 알아봅니다. 파일 기반 데이터 저장소 데이터 세트에 대한 다음 구성은 이전 버전과의 호환성을 위해 그대로 지원됩니다. 앞으로는 새 모델을 사용하는 것이 좋습니다.
Azure Cosmos DB에서 JSON 파일을 그대로 가져오거나 내보내려면Azure Cosmos DB 간에 데이터 이동 문서에서 JSON 문서 가져오기/내보내기 섹션을 참조하세요.
JSON 파일을 구문 분석하거나 데이터를 JSON 형식으로 쓰려면 format 섹션의 type 속성을 JsonFormat으로 설정합니다. format 섹션에서 다음 선택적 속성을 지정할 수도 있습니다. 구성 방법은 JsonFormat 예제 섹션을 참조하세요.
| 속성 | 설명 | 필수 |
|---|---|---|
| filePattern | 각 JSON 파일에 저장된 데이터의 패턴을 나타냅니다. 사용 가능한 값은 setOfObjects 및 arrayOfObjects이고 기본값은 setOfObjects입니다. 이러한 패턴에 대한 자세한 내용은 JSON 파일 패턴 섹션을 참조하세요. | 아니요 |
| jsonNodeReference | 동일한 패턴으로 배열 필드 내부의 개체에서 데이터를 반복하고 추출하려면 해당 배열의 JSON 경로를 지정합니다. 이 속성은 JSON 파일에서 데이터를 복사할 때만 지원됩니다. | 아니요 |
| jsonPathDefinition | 사용자 지정된 열 이름(소문자로 시작)으로 각 열 매핑에 대한 JSON 경로 식을 지정합니다. 이 속성은 JSON 파일에서 데이터를 복사할 때만 지원되며 개체 또는 배열에서 데이터를 추출할 수 있습니다. 루트 개체 아래의 필드는 root $로 시작하며, jsonNodeReference 속성으로 선택된 배열 내부의 필드는 배열 요소에서 시작합니다. 구성 방법은 JsonFormat 예제 섹션을 참조하세요. |
아니요 |
| encodingName | 인코딩 이름을 지정합니다. 유효한 인코딩 이름 목록은 Encoding.EncodingName 속성을 참조하세요. 예: windows-1250 또는 shift_jis 기본값은 UTF-8입니다. | 아니요 |
| nestingSeparator | 중첩 수준을 구분하는데 사용되는 문자입니다. 기본값은 '.'(점)입니다. | 아니요 |
참고 항목
배열의 데이터를 여러 행에 교차 적용하는 경우(JsonFormat examples의 사례 1 -> 샘플 2), jsonNodeReference 속성을 사용하여 단일 배열만 확장할 수 있습니다.
JSON 파일 패턴
복사 작업에서 다음과 같은 JSON 파일 패턴을 구문 분석할 수 있습니다.
유형 I: setOfObjects
각 파일에 단일 개체 또는 줄로 구분된/연결된 여러 개체가 포함되어 있습니다. 출력 데이터 세트에서 이 옵션을 선택하는 경우 복사 활동에서는 줄마다 개체가 하나씩 포함된(각 개체가 줄로 구분된) JSON 파일 하나를 생성합니다.
단일 개체 JSON 예제
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }줄로 구분된 JSON 예제
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}연결된 JSON 예제
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
유형 II: arrayOfObjects
각 파일에 개체 배열이 포함됩니다.
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
JsonFormat 예제
사례 1: JSON 파일에서 데이터 복사
샘플 1: 개체 및 배열에서 데이터 추출
이 샘플에서는 테이블 형식 결과에서 하나의 루트 JSON 개체를 하나의 레코드로 매핑하는 것이 예상됩니다. 다음 내용을 포함하는 JSON 파일이 있고
{
"id": "ed0e4960-d9c5-11e6-85dc-d7996816aad3",
"context": {
"device": {
"type": "PC"
},
"custom": {
"dimensions": [
{
"TargetResourceType": "Microsoft.Compute/virtualMachines"
},
{
"ResourceManagementProcessRunId": "827f8aaa-ab72-437c-ba48-d8917a7336a3"
},
{
"OccurrenceTime": "1/13/2017 11:24:37 AM"
}
]
}
}
}
개체와 배열 모두에서 데이터를 추출하여 다음과 같은 형식으로 Azure SQL 테이블에 복사하려는 경우
| ID | deviceType | targetResourceType | resourceManagementProcessRunId | occurrenceTime |
|---|---|---|---|---|
| ed0e4960-d9c5-11e6-85dc-d7996816aad3 | PC | Microsoft.Compute/virtualMachines | 827f8aaa-ab72-437c-ba48-d8917a7336a3 | 1/13/2017 11:24:37 AM |
JsonFormat 형식의 입력 데이터 세트는 다음과 같이 정의됩니다(관련 부분만 있는 부분 정의). 즉,
structure섹션은 테이블 형식 데이터로 변환하는 동안 사용자 지정된 열 이름과 해당 데이터 형식을 정의합니다. 이 섹션은 열 매핑을 수행할 필요가 없는 경우를 제외하고는 선택적입니다. 자세한 내용은 원본 데이터 세트 열을 대상 데이터 세트 열에 매핑을 참조하세요.jsonPathDefinition은 데이터를 추출할 위치를 나타내는 각 열의 JSON 경로를 지정합니다. 배열의 데이터를 복사하려면array[x].property를 사용하여xth개체에서 지정된 속성의 값을 추출하거나array[*].property를 사용하여 이러한 속성을 포함하는 개체의 값을 찾으면 됩니다.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "deviceType",
"type": "String"
},
{
"name": "targetResourceType",
"type": "String"
},
{
"name": "resourceManagementProcessRunId",
"type": "String"
},
{
"name": "occurrenceTime",
"type": "DateTime"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonPathDefinition": {"id": "$.id", "deviceType": "$.context.device.type", "targetResourceType": "$.context.custom.dimensions[0].TargetResourceType", "resourceManagementProcessRunId": "$.context.custom.dimensions[1].ResourceManagementProcessRunId", "occurrenceTime": " $.context.custom.dimensions[2].OccurrenceTime"}
}
}
}
샘플 2: 배열에서 동일한 패턴을 사용하여 여러 개체 배열에서 교차 적용
이 샘플에서는 테이블 형식 결과에서 하나의 루트 JSON 개체가 여러 레코드로 변환하는 것이 예상됩니다. 다음 내용을 포함하는 JSON 파일이 있고
{
"ordernumber": "01",
"orderdate": "20170122",
"orderlines": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "sanmateo": "No 1" } ]
}
배열 내부의 데이터를 평면화하고 일반적인 루트 정보로 크로스 조인하여 Azure SQL 테이블에 데이터를 다음 형식으로 복사하려는 경우
ordernumber |
orderdate |
order_pd |
order_price |
city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P2 | 13 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P3 | 231 | [{"sanmateo":"No 1"}] |
JsonFormat 형식의 입력 데이터 세트는 다음과 같이 정의됩니다(관련 부분만 있는 부분 정의). 즉,
structure섹션은 테이블 형식 데이터로 변환하는 동안 사용자 지정된 열 이름과 해당 데이터 형식을 정의합니다. 이 섹션은 열 매핑을 수행할 필요가 없는 경우를 제외하고는 선택적입니다. 자세한 내용은 원본 데이터 세트 열을 대상 데이터 세트 열에 매핑을 참조하세요.jsonNodeReference는 arrayorderlines에서 동일한 패턴을 사용하는 개체에서 데이터를 반복하고 추출하도록 지정합니다.jsonPathDefinition은 데이터를 추출할 위치를 나타내는 각 열의 JSON 경로를 지정합니다. 다음 예제에서ordernumber,orderdate및city는$.로 시작하는 JSON 경로를 사용하는 루트 개체 아래에 있는 반면order_pd및order_price는$.를 포함하지 않는 배열 요소에서 파생된 경로를 사용하여 정의됩니다.
"properties": {
"structure": [
{
"name": "ordernumber",
"type": "String"
},
{
"name": "orderdate",
"type": "String"
},
{
"name": "order_pd",
"type": "String"
},
{
"name": "order_price",
"type": "Int64"
},
{
"name": "city",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonNodeReference": "$.orderlines",
"jsonPathDefinition": {"ordernumber": "$.ordernumber", "orderdate": "$.orderdate", "order_pd": "prod", "order_price": "price", "city": " $.city"}
}
}
}
주의 사항:
structure및jsonPathDefinition이 데이터 세트에 정의되지 않은 경우 복사 작업은 첫 번째 개체에서 스키마를 검색하고 전체 개체를 평면화합니다.- JSON 입력에 배열이 있는 경우 복사 작업은 기본적으로 전체 배열 값을 문자열로 변환합니다.
jsonNodeReference및/또는jsonPathDefinition을 사용하여 데이터를 추출하거나jsonPathDefinition에서 지정하지 않고 건너뛸 수 있습니다. - 동일한 수준에 중복된 이름이 있는 경우 복사 활동에서는 마지막 이름이 선택됩니다.
- 속성 이름은 대/소문자를 구분합니다. 이름은 같지만 대/소문자가 다른 두 속성은 별도의 두 속성으로 간주됩니다.
사례 2: JSON 파일에 데이터 쓰기
SQL Database에 다음 테이블이 있는 경우:
| ID | order_date | order_price | order_by |
|---|---|---|---|
| 1 | 20170119 | 2000 | David |
| 2 | 20170120 | 3500 | Patrick |
| 3 | 20170121 | 4000 | Jason |
각 레코드에 대해 다음과 같은 형식으로 JSON 개체에 쓰려는 경우:
{
"id": "1",
"order": {
"date": "20170119",
"price": 2000,
"customer": "David"
}
}
JsonFormat 형식의 출력 데이터 세트는 다음과 같이 정의됩니다(관련 부분만 있는 부분 정의). 좀 더 구체적으로 말하면, structure 섹션은 대상 파일의 사용자 지정된 속성 이름을 정의하며 nestingSeparator(기본값: ".")는 이름에서 중첩 레이어를 식별하는 데 사용됩니다. 이 섹션은 원본 열 이름과 비교하여 속성 이름을 변경하거나 일부 속성을 중첩하지 않으려는 경우를 제외하고는 선택적입니다.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "order.date",
"type": "String"
},
{
"name": "order.price",
"type": "Int64"
},
{
"name": "order.customer",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat"
}
}
}
Parquet 형식(레거시)
참고 항목
Parquet 형식 문서의 새 모델에 대해 알아봅니다. 파일 기반 데이터 저장소 데이터 세트에 대한 다음 구성은 이전 버전과의 호환성을 위해 그대로 지원됩니다. 앞으로는 새 모델을 사용하는 것이 좋습니다.
Parquet 파일을 구문 분석하거나 데이터를 Parquet 형식으로 쓰려면 format type 속성을 ParquetFormat으로 설정합니다. typeProperties 섹션 내의 Format 섹션에서는 속성을 지정할 필요가 없습니다. 예시:
"format":
{
"type": "ParquetFormat"
}
다음 사항에 유의하세요.
- 복합 데이터 형식(MAP, LIST)은 지원되지 않습니다.
- 열 이름에는 공백이 지원되지 않습니다.
- Parquet 파일에는 압축 관련 옵션인 NONE, SNAPPY, GZIP 및 LZO가 포함되어 있습니다. 서비스는 LZO를 제외한 압축 형식의 Parquet 파일에서 데이터 읽기를 지원합니다. 메타데이터에 있는 압축 코덱을 사용하여 데이터를 읽습니다. 그러나 Parquet 파일에 쓸 때 서비스는 Parquet 서식에 대한 기본값인 SNAPPY를 선택합니다. 현재 이 동작을 재정의할 수 있는 옵션은 없습니다.
Important
자체 호스팅 Integration Runtime에 권한을 부여한 복사(예: 온-프레미스 및 클라우드 데이터 저장소 간)의 경우 Parquet 파일을 있는 그대로 복사하지 않으면 IR 머신에 64비트 JRE(Java Runtime Environment) 8 또는 OpenJDK를 설치해야 합니다. 자세한 내용은 다음 단락을 참조하세요.
자체 호스팅 IR에서 Parquet 파일 serialization/deserialization을 사용하여 실행되는 복사의 경우 서비스는 먼저 JRE에 대한 (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) 레지스트리를 검사하고, 없는 경우 OpenJDK에 대한 JAVA_HOME 시스템 변수를 검사하여 Java 런타임을 찾습니다.
- JRE 사용: 64비트 IR에는 64비트 JRE가 필요합니다. 여기서 찾을 수 있습니다.
- OpenJDK 사용: IR 버전 3.13부터 지원됩니다. 다른 모든 필수 OpenJDK 어셈블리와 함께 jvm.dll을 자체 호스팅 IR 머신으로 패키지하고, 이에 따라 JAVA_HOME 시스템 환경 변수를 설정합니다.
팁
자체 호스팅 Integration Runtime을 사용하여 데이터를 Parquet 형식으로 또는 그 반대로 복사하고 “java를 호출할 때 오류가 발생함, 메시지: java.lang.OutOfMemoryError:Java heap space”라는 오류가 발생하는 경우 JVM의 최소/최대 힙 크기를 조정하도록 자체 호스팅 IR을 호스트하는 머신에서 _JAVA_OPTIONS 환경 변수를 추가하여 그러한 복사 기능을 강화한 다음, 파이프라인을 다시 실행할 수 있습니다.
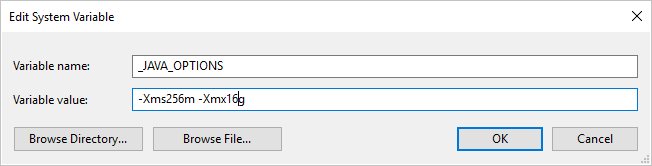
예: 변수 _JAVA_OPTIONS를 -Xms256m -Xmx16g 값으로 설정합니다. 플래그 Xms는 JVM(Java Virtual Machine)의 초기 메모리 할당 풀을 지정하고, Xmx는 최대 메모리 할당 풀을 지정합니다. 즉, JVM은 Xms의 메모리 양으로 시작하고 최대 Xmx의 메모리 양을 사용할 수 있음을 의미합니다. 기본적으로 서비스는 최소 64MB 및 최대 1G를 사용합니다.
Parquet 파일에 대한 데이터 형식 매핑
| 중간 서비스 데이터 형식 | Parquet 기본 형식 | Parquet 원본 형식(역직렬화) | Parquet 원본 형식(Serialize) |
|---|---|---|---|
| 부울 | 부울 | 해당 없음 | 해당 없음 |
| SByte | Int32 | Int8 | Int8 |
| Byte | Int32 | UInt8 | Int16 |
| Int16 | Int32 | Int16 | Int16 |
| UInt16 | Int32 | UInt16 | Int32 |
| Int32 | Int32 | Int32 | Int32 |
| UInt32 | Int64 | UInt32 | Int64 |
| Int64 | Int64 | Int64 | Int64 |
| UInt64 | Int64/이진 | UInt64 | 소수 |
| 단일 | Float | 해당 없음 | 해당 없음 |
| Double | 두 배 | 해당 없음 | 해당 없음 |
| 소수 | 이진 | 소수 | Decimal |
| 문자열 | 이진 | Utf8 | Utf8 |
| DateTime | Int96 | 해당 없음 | 해당 없음 |
| TimeSpan | Int96 | 해당 없음 | 해당 없음 |
| DateTimeOffset | Int96 | 해당 없음 | 해당 없음 |
| ByteArray | 이진 | 해당 없음 | 해당 없음 |
| GUID | 이진 | Utf8 | Utf8 |
| Char | 이진 | Utf8 | Utf8 |
| CharArray | 지원되지 않음 | 해당 없음 | 해당 없음 |
ORC 형식(레거시)
참고 항목
ORC 형식 문서의 새 모델에 대해 알아봅니다. 파일 기반 데이터 저장소 데이터 세트에 대한 다음 구성은 이전 버전과의 호환성을 위해 그대로 지원됩니다. 앞으로는 새 모델을 사용하는 것이 좋습니다.
ORC 파일을 구문 분석하거나 데이터를 ORC 형식으로 쓰려면 format type 속성을 OrcFormat으로 설정합니다. typeProperties 섹션 내의 Format 섹션에서는 속성을 지정할 필요가 없습니다. 예시:
"format":
{
"type": "OrcFormat"
}
다음 사항에 유의하세요.
- 복합 데이터 형식(구조체, 매핑, 목록, 공용 구조체)은 지원되지 않습니다.
- 열 이름에는 공백이 지원되지 않습니다.
- ORC 파일에는 3개의 압축 관련 옵션(NONE, ZLIB, SNAPPY)이 있습니다. 서비스에서는 이러한 압축 형식으로 된 데이터를 ORC 파일에서 읽을 수 있습니다. 메타데이터에 있는 압축 코덱을 사용하여 데이터를 읽습니다. 그러나 ORC 파일에 쓸 때 서비스는 ORC에 대한 기본값인 ZLIB를 선택합니다. 현재 이 동작을 재정의할 수 있는 옵션은 없습니다.
Important
자체 호스팅 Integration Runtime에 권한을 부여한 복사(예: 온-프레미스 및 클라우드 데이터 저장소 간)의 경우 ORC 파일을 있는 그대로 복사하지 않으면 IR 머신에 64비트 JRE(Java Runtime Environment) 8 또는 OpenJDK를 설치해야 합니다. 자세한 내용은 다음 단락을 참조하세요.
자체 호스팅 IR에서 ORC 파일 serialization/deserialization을 사용하여 실행되는 복사의 경우 서비스는 먼저 JRE에 대한 (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) 레지스트리를 검사하고, 없는 경우 OpenJDK에 대한 JAVA_HOME 시스템 변수를 검사하여 Java 런타임을 찾습니다.
- JRE 사용: 64비트 IR에는 64비트 JRE가 필요합니다. 여기서 찾을 수 있습니다.
- OpenJDK 사용: IR 버전 3.13부터 지원됩니다. 다른 모든 필수 OpenJDK 어셈블리와 함께 jvm.dll을 자체 호스팅 IR 머신으로 패키지하고, 이에 따라 JAVA_HOME 시스템 환경 변수를 설정합니다.
ORC 파일에 대한 데이터 형식 매핑
| 중간 서비스 데이터 형식 | ORC 형식 |
|---|---|
| 부울 | 부울 |
| SByte | Byte |
| Byte | Short |
| Int16 | Short |
| UInt16 | 정수 |
| Int32 | 정수 |
| UInt32 | Long |
| Int64 | Long |
| UInt64 | 문자열 |
| 단일 | Float |
| Double | 두 배 |
| 소수 | Decimal |
| 문자열 | 문자열 |
| DateTime | 타임스탬프 |
| DateTimeOffset | 타임스탬프 |
| TimeSpan | 타임스탬프 |
| ByteArray | 이진 |
| GUID | 문자열 |
| Char | Char(1) |
AVRO 형식(레거시)
참고 항목
Avro 형식 문서의 새 모델에 대해 알아봅니다. 파일 기반 데이터 저장소 데이터 세트에 대한 다음 구성은 이전 버전과의 호환성을 위해 그대로 지원됩니다. 앞으로는 새 모델을 사용하는 것이 좋습니다.
Avro 파일을 구문 분석하거나 데이터를 Avro 형식으로 쓰려면 format type 속성을 AvroFormat으로 설정합니다. typeProperties 섹션 내의 Format 섹션에서는 속성을 지정할 필요가 없습니다. 예시:
"format":
{
"type": "AvroFormat",
}
Hive 테이블에서 Avro 형식을 사용하려면 Apache Hive의 자습서를 참조하세요.
다음 사항에 유의하세요.
- 복합 데이터 형식은 지원되지 않습니다(레코드, 열거형, 배열, 매핑, 공용 구조체 및 고정).
압축 지원(레거시)
서비스에서는 복사하는 동안 압축/압축 풀기 데이터를 지원합니다. 입력 데이터 세트에서 compression 속성을 지정하는 경우 복사 작업은 원본에서 압축된 데이터를 읽고 압축을 풉니다. 출력 데이터 세트에서 속성을 지정하는 경우 복사 작업은 데이터를 압축하고 싱크에 작성합니다. 다음은 몇 가지 샘플 시나리오입니다.
- Azure Blob에서 GZIP 압축 데이터를 읽고 압축을 풀고 Azure SQL Database에 결과 데이터를 작성합니다.
compressiontype속성을 GZIP으로 설정하여 입력 Azure Blob 데이터 세트를 정의합니다. - 온-프레미스 파일 시스템에서 일반 텍스트 파일에서 데이터를 읽고 GZip 형식을 사용하여 압축하고 Azure Blob에 압축된 데이터를 작성합니다.
compressiontype속성을 GZip으로 설정하여 출력 Azure Blob 데이터 세트를 정의합니다. - FTP 서버에서 .zip 파일을 읽고, 압축을 풀어서 내부에 있는 파일을 가져오고, Azure Data Lake Store에 해당 파일을 보관합니다.
compressiontype속성을 ZipDeflate으로 설정하여 입력 FTP 데이터 세트를 정의합니다. - Azure Blob에서 GZIP 압축 데이터를 읽고 압축을 풀고 BZIP2를 사용하여 압축하고 Azure Blob에 결과 데이터를 작성합니다.
compressiontype속성을 GZIP으로 설정하여 입력 Azure Blob 데이터 세트를 정의하고compressiontype속성을 BZIP2로 설정하여 출력 데이터 세트를 정의합니다.
데이터 세트에 대한 압축을 지정하려면 다음 예제와 같이 데이터 세트 JSON의 압축 속성을 사용합니다.
{
"name": "AzureBlobDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": {
"referenceName": "StorageLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"fileName": "pagecounts.csv.gz",
"folderPath": "compression/file/",
"format": {
"type": "TextFormat"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
압축 섹션에는 두 가지 속성이 있습니다.
유형:GZIP, Deflate, BZIP2 또는 ZipDeflate 등의 압축 코덱입니다. 참고 복사 작업을 사용하여 ZipDeflate 파일의 압축을 풀고 파일 기반 싱크 데이터 저장소에 쓰면 파일이
<path specified in dataset>/<folder named as source zip file>/폴더에 추출됩니다.수준:최적 또는 가장 빠름이 될 수 있는 압축 비율입니다.
가장 빠름: 결과 파일이 최적으로 압축되지 않은 경우에도 압축 작업을 최대한 빨리 완료해야 합니다.
최적: 작업이 완료되는데 시간이 오래 걸리더라도 압축 작업이 최적으로 압축되어야 합니다.
자세한 내용은 압축 수준 항목을 참조하세요.
참고 항목
현재 AvroFormat, OrcFormat 또는 ParquetFormat의 데이터에 대한 압축 설정은 지원되지 않습니다. 이러한 형식의 파일을 읽을 때에는 서비스는 메타데이터에 있는 압축 코덱을 감지하여 사용합니다. 이러한 형식의 파일에 쓸 때에는 서비스는 해당 형식에 대한 기본 압축 코덱을 선택합니다. 예를 들어 OrcFormat에 대해 ZLIB를 사용하고 ParquetFormat에 대해 SNAPPY를 사용합니다.
지원되는 파일 형식 및 압축 형식
확장성 기능을 사용하여 지원되지 않는 파일을 변환할 수 있습니다. 두 가지 옵션으로 Azure Functions를 사용하는 것과 Azure Batch를 사용한 사용자 지정 작업이 있습니다.
Azure 함수를 사용하여 tar 파일의 내용을 추출하는 샘플을 볼 수 있습니다. 자세한 내용은 Azure Functions 작업을 참조하세요.
사용자 지정 dotnet 작업을 사용하여 이 기능을 빌드할 수도 있습니다. 여기서 자세한 내용을 확인할 수 있습니다.
관련 콘텐츠
지원되는 파일 형식 및 압축에서 지원되는 최신 파일 형식 및 압축에 대해 알아봅니다.