SAP CDC 고급 토픽
적용 대상: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
메타데이터 기반 데이터 통합, 디버깅 등과 같은 SAP CDC 커넥터에 대한 고급 항목에 대해 알아봅니다.
SAP CDC 매핑 데이터 흐름 매개 변수화
Azure Data Factory 및 Azure Synapse Analytics의 파이프라인 및 매핑 데이터 흐름의 주요 장점 중 하나는 메타데이터 기반 데이터 통합에 대한 지원입니다. 이 기능을 사용하면 잠재적으로 수백 또는 수천 개의 원본 통합을 처리하는 데 사용할 수 있는 단일(또는 소수) 매개 변수화된 파이프라인을 설계할 수 있습니다. SAP CDC 커넥터는 이 원칙을 염두에 두고 설계되었습니다. 원본 개체, 실행 모드, 키 열 등 모든 관련 속성은 매개 변수를 통해 제공되어 SAP CDC 매핑 데이터 흐름의 유연성과 재사용 가능성을 최대화할 수 있습니다.
매핑 데이터 흐름을 매개 변수화하는 기본 개념을 이해하려면 매핑 데이터 흐름 매개 변수화를 읽 어 줍니다.
Azure Data Factory 및 Azure Synapse Analytics의 템플릿 갤러리에서 SAP CDC 데이터 수집을 매개 변수화하는 방법을 보여 주는 템플릿 파이프라인 및 데이터 흐름을 찾을 수 있습니다.
원본 및 실행 모드 매개 변수화
매핑 데이터 흐름에는 반드시 데이터 세트 아티팩트가 필요하지 않습니다. 원본 및 싱크 변환 모두 원본 형식(또는 싱크 형식) 인라인을 제공합니다. 이 경우 ADF 데이터 세트에 정의된 모든 원본 속성은 원본 변환의 원본 옵션(또는 싱크 변환의 설정 탭)에서 구성할 수 있습니다. 인라인 데이터 세트를 사용하면 전체 원본(또는 싱크) 구성이 한 곳에서 유지 관리되므로 더 나은 개요를 제공하고 매핑 데이터 흐름을 매개 변수화할 수 있습니다.
SAP CDC의 경우 매개 변수를 통해 가장 일반적으로 설정되는 속성은 원본 옵션 및 최적화 탭에 있습니다. 원본 형식이 인라인인 경우 원본 옵션에서 다음 속성을 매개 변수화할 수 있습니다.
-
ODP 컨텍스트: 유효한 매개 변수 값은 다음과 같습니다.
- ABAP_CDS ABAP Core Data Services 보기용
- BW SAP BW 또는 SAP BW/4HANA InfoProvider용
- HANA SAP HANA 정보 보기용
- SAPI SAP DataSources/추출기용
- SLT(SAP Landscape Transformation) 복제 서버가 원본으로 사용되는 경우 ODP 컨텍스트 이름은 SLT~<큐 별칭>입니다. 큐 별칭 값은 SLT cockpit(SAP 트랜잭션 LTRC)의 SLT 구성에 있는 관리 데이터에서 찾을 수 있습니다.
- ODP_SELF 및 RANDOM은 기술 유효성 검사 및 테스트에 사용되는 ODP 컨텍스트이며 일반적으로 관련이 없습니다.
- ODP 이름: 데이터를 추출하려는 ODP 이름을 제공합니다.
-
실행 모드: 유효한 매개 변수 값은 다음과 같습니다.
- fullAndIncrementalLoad for Full은 첫 번째 실행에서 증분으로, 변경 데이터 캡처 프로세스를 시작하고 현재 전체 데이터 스냅샷을 추출합니다.
- fullLoad모든 실행 시 전체, 변경 데이터 캡처 프로세스를 시작하지 않고 현재 전체 데이터 스냅샷을 추출합니다.
- incrementalLoad증분 변경만, 현재 전체 스냅샷을 추출하지 않고 변경 데이터 캡처 프로세스를 시작합니다.
- 키 열: 키 열은(큰따옴표로 묶인) 문자열 배열로 제공됩니다. 예를 들어, SAP 테이블 VBAP(판매 주문 항목)으로 작업할 때 키 정의는 ["VBELN", "POSNR"]이어야 합니다(또는 클라이언트 필드도 고려되는 경우 ["MANDT","VBELN","POSNR"]).
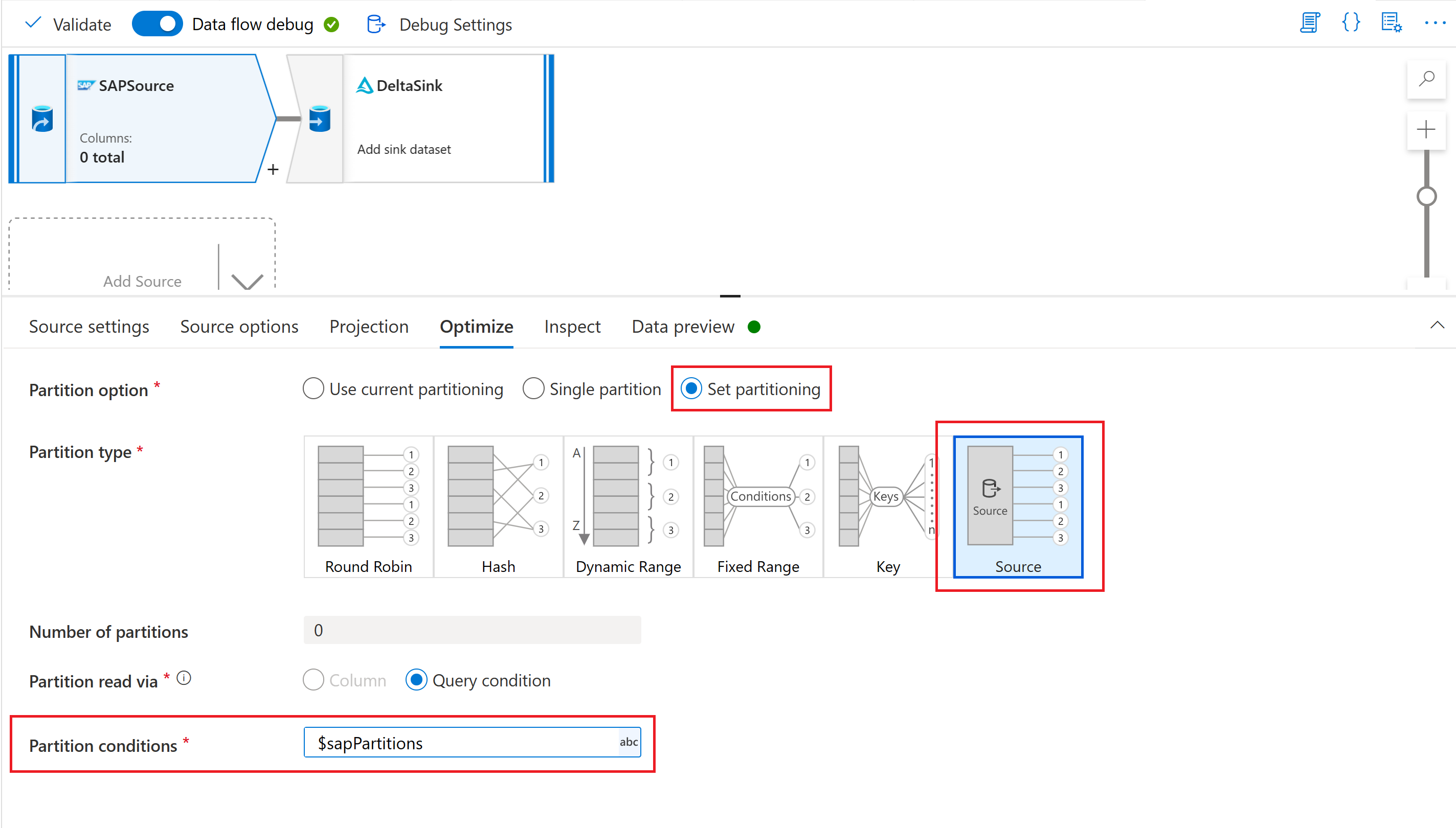
원본 분할에 대한 필터 조건 매개 변수화
최적화 탭에서 매개 변수를 통해 원본 파티션 구성표(전체 또는 초기 로드에 대한 성능 최적화 참조)를 정의할 수 있습니다. 일반적으로 다음 두 단계가 필요합니다.
- 원본 분할 체계를 정의합니다.
- 분할 매개 변수를 매핑 데이터 흐름에 수집합니다.
원본 분할 체계 정의
1단계의 형식은 파티션 정의 배열로 구성된 JSON 표준을 따르며, 각 정의 자체는 개별 필터 조건의 배열입니다. 이러한 조건 자체는 SAP의 소위 선택 옵션에 맞춰 정렬된 구조를 가진 JSON 개체입니다. 실제로 SAP ODP 프레임워크에 필요한 형식은 기본적으로 SAP BW의 동적 DTP 필터와 동일합니다.
{ "fieldName": <>, "sign": <>, "option": <>, "low": <>, "high": <> }
예를 들면 다음과 같습니다.
{ "fieldName": "VBELN", "sign": "I", "option": "EQ", "low": "0000001000" }
SQL WHERE 절에 해당... WHERE "VBELN" = '0000001000', or
{ "fieldName": "VBELN", "sign": "I", "option": "BT", "low": "0000000000", "high": "0000001000" }
SQL WHERE 절에 해당... WHERE "VBELN" BETWEEN '0000000000' AND '0000001000'
따라서 두 개의 파티션을 포함하는 파티션 구성표의 JSON 정의는 다음과 같습니다.
[
[
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2011", "high": "2015" }
],
[
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2016", "high": "2020" }
]
]
여기서 첫 번째 파티션에는 회계 연도(GJAHR) 2011~2015가 포함되고, 두 번째 파티션에는 회계 연도 2016~2020이 포함됩니다.
참고 항목
Azure Data Factory는 이러한 조건에 대해 어떠한 검사도 수행하지 않습니다. 예를 들어, 파티션 조건이 겹치지 않도록 하는 것은 사용자의 책임입니다.
파티션 조건은 여러 기본 필터 조건 자체로 구성되어 더 복잡할 수 있습니다. 하나의 파티션 내에서 여러 기본 조건을 결합하는 방법을 명시적으로 정의하는 논리적 접속사는 없습니다. SAP의 암시적 정의는 다음과 같습니다.
- 동일한 필드 이름에 대한 포함 조건("기호": "I")은 OR과 결합됩니다(내부적으로 결과 조건을 괄호로 묶음).
- 동일한 필드 이름에 대한 제외 조건("기호": "E")은 OR과 결합됩니다(내부적으로 결과 조건을 괄호로 묶음).
- 1단계와 2단계의 결과 조건은 다음과 같습니다.
- 포함 조건의 경우 AND와 결합됩니다.
- 제외 조건을 위해 AND NOT과 결합됩니다.
예를 들어, 파티션 조건
[
{ "fieldName": "BUKRS", "sign": "I", "option": "EQ", "low": "1000" },
{ "fieldName": "BUKRS", "sign": "I", "option": "EQ", "low": "1010" },
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2010", "high": "2025" },
{ "fieldName": "GJAHR", "sign": "E", "option": "EQ", "low": "2023" },
{ "fieldName": "GJAHR", "sign": "E", "option": "EQ", "low": "2021" }
]
는 SQL WHERE 절에 해당합니다. WHERE ("BUKRS" = '1000' 또는 "BUKRS" = '1010') AND ("GJAHR" BETWEEN '2010' and '2025') AND NOT ("GJAHR" = '2021' 또는 "GJARH" = '2023')
참고 항목
낮은 값과 높은 값에 대해 SAP 내부 형식을 사용하고, 앞에 0을 포함하고, 달력 날짜를 "YYYYMMDD" 형식의 8자 문자열로 표현해야 합니다.
매핑 데이터 흐름에 분할 매개 변수 수집
분할 체계를 매핑 데이터 흐름으로 수집하려면 데이터 흐름 매개 변수(예: "sapPartitions")를 만듭니다. JSON 형식을 이 매개 변수에 전달하려면 @string() 함수를 사용하여 문자열로 변환해야 합니다.

마지막으로 매핑 데이터 흐름에 있는 원본 변환의 최적화 탭에서 파티션 형식 "원본"를 선택하고 파티션 조건 속성에 데이터 흐름 매개 변수를 입력합니다.
검사점 키 매개 변수화
매개 변수화된 데이터 흐름을 사용하여 여러 SAP CDC 원본에서 데이터를 추출하는 경우 파이프라인의 데이터 흐름 작업에서 검사점 키를 매개 변수화해야 합니다. 검사점 키는 Azure Data Factory에서 변경 데이터 캡처 프로세스의 상태를 관리하는 데 사용됩니다. 한 CDC 프로세스의 상태가 다른 프로세스의 상태를 덮어쓰는 것을 방지하려면 검사점 키 값이 데이터 흐름에 사용되는 각 매개 변수 집합에 대해 고유한지 확인해야 합니다.
참고 항목
데이터 흐름의 매개 변수 집합에 검사점 키 값을 추가하는 것이 검사점 키의 고유성을 보장하는 가장 좋은 방법입니다.
검사점 키에 대한 자세한 내용은 SAP CDC 커넥터를 사용하여 데이터 변환을 참조하세요.
디버깅
Azure Data Factory 파이프라인은 트리거 실행 또는 디버그 실행을 통해 실행될 수 있습니다. 이 두 옵션의 근본적인 차이점은 디버그 실행이 사용자 인터페이스에 모델링된 현재 버전을 기반으로 데이터 흐름과 파이프라인을 실행하는 반면, 트리거 실행은 데이터 흐름 및 파이프라인의 마지막 게시된 버전을 실행한다는 것입니다.
SAP CDC의 경우 이해해야 할 측면이 한 가지 더 있습니다. 디버그 실행이 기존 변경 데이터 캡처 프로세스에 미치는 영향을 방지하기 위해 디버그 실행은 트리거 실행과 다른 "구독자 프로세스" 값(SAP CDC 데이터 흐름 모니터링 참조)을 사용합니다. 따라서 SAP 시스템 내에서 별도의 구독(즉, 변경 데이터 캡처 프로세스)을 만듭니다. 또한 디버그 실행을 위한 "구독자 프로세스" 값의 수명은 브라우저 UI 세션으로 제한됩니다.
참고 항목
장기간(예: 며칠) SAP CDC를 사용하여 변경 데이터 캡처 프로세스의 안정성을 테스트하려면 데이터 흐름과 파이프라인을 게시하고 트리거 실행을 실행해야 합니다.