Azure Data Factory를 사용하여 Amazon S3에서 Azure Storage로 데이터 마이그레이션
적용 대상:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
Azure Data Factory는 Amazon S3에서 Azure Blob 스토리지 또는 Azure Data Lake Storage Gen2으로 대규모로 데이터를 마이그레이션하는 데 강력하고 비용 효율적인 고성능 메커니즘을 제공합니다. 이 문서에서는 데이터 엔지니어 및 개발자를 위한 다음 정보를 제공합니다.
- 성능
- 복사 복원력
- 네트워크 보안
- 개괄적인 솔루션 아키텍처
- 구현 모범 사례
성능
ADF는 서로 다른 수준에서 병렬 처리를 허용하는 서버리스 아키텍처를 제공합니다. 이 아키텍처를 통해 개발자는 네트워크 대역폭과 스토리지 IOPS 및 대역폭을 최대한 활용하여 환경에 대한 데이터 이동 처리량을 최대화하는 파이프라인을 빌드할 수 있습니다.
고객은 2GBps 이상의 처리량을 유지하면서 수억 개의 파일로 구성된 페타바이트 크기 데이터를 Amazon S3에서 Azure Blob 스토리지로 마이그레이션했습니다.
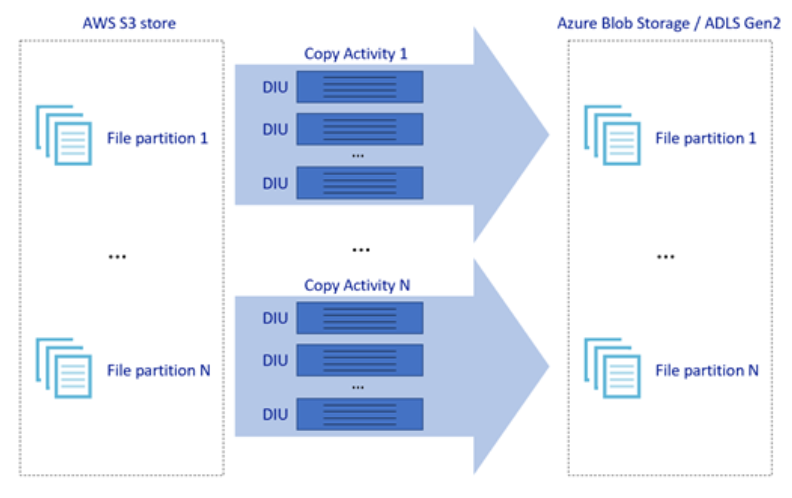
위의 그림은 다양한 병렬 처리 수준을 통해 뛰어난 데이터 이동 속도를 달성할 수 있는 방법을 보여 줍니다.
- 단일 복사 작업은 확장 가능한 컴퓨팅 리소스를 활용할 수 있습니다. Azure Integration Runtime을 사용하는 경우 서버리스 방식으로 각 복사 작업에 대해 최대 256 DIU를 지정할 수 있습니다. 자체 호스팅 Integration Runtime을 사용하는 경우 수동으로 머신을 스케일 업하거나 여러 머신(최대 4개의 노드)으로 스케일 아웃할 수 있으며 단일 복사 작업은 모든 노드에서 해당 파일 세트를 분할합니다.
- 단일 복사 작업은 여러 스레드를 사용하여 데이터 저장소에서 읽고 씁니다.
- ADF 제어 흐름은 여러 복사 작업을 병렬로 시작할 수 있습니다(예: For Each 루프 사용).
복원력
단일 복사 작업 실행 내에서 ADF에는 기본 제공 재시도 메커니즘이 있으므로 데이터 저장소나 기본 네트워크에서 특정 수준의 일시적 오류를 처리할 수 있습니다.
S3에서 Blob으로, S3에서 ADLS Gen2로 이진 복사를 수행하면 ADF는 검사점 설정을 자동으로 수행합니다. 복사 작업 실행이 실패하거나 시간 초과하면 후속 다시 시도 시 복사가 처음부터 시작되지 않고, 마지막 오류 지점부터 다시 시작됩니다.
네트워크 보안
기본적으로 ADF는 HTTPS 프로토콜을 통한 암호화된 연결을 사용하여 Amazon S3에서 Azure Blob 스토리지 또는 Azure Data Lake Storage Gen2 데이터를 전송합니다. HTTPS는 전송 중인 데이터의 암호화를 제공하고, 도청 및 메시지 가로채기(man-in-the-middle) 공격을 방지합니다.
또는 퍼블릭 인터넷을 통해 데이터를 전송하지 않으려면 AWS Direct Connect와 Azure Express 경로 간의 개인 피어링 링크를 통해 데이터를 전송하여 더 높은 수준의 보안을 달성할 수 있습니다. 이를 달성하는 방법은 다음 섹션의 솔루션 아키텍처를 참조하세요.
솔루션 아키텍처
퍼블릭 인터넷을 통해 데이터 마이그레이션:
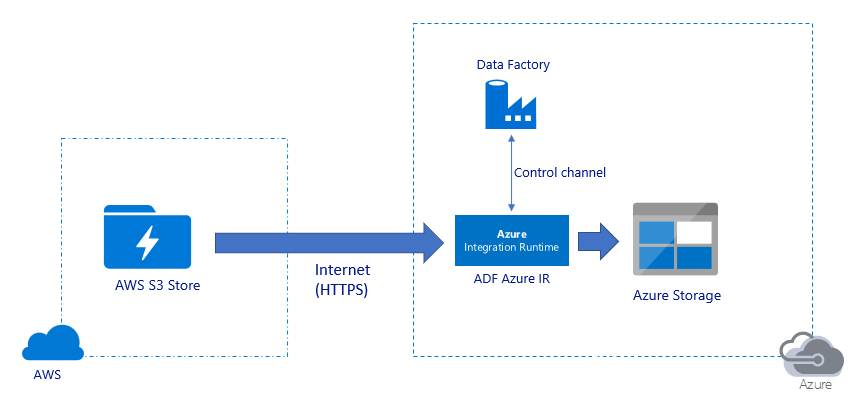
- 이 아키텍처에서 데이터는 퍼블릭 인터넷을 통해 HTTPS를 사용하여 안전하게 전송됩니다.
- 원본 Amazon S3과 대상 Azure Blob 스토리지 또는 Azure Data Lake Storage Gen2는 모두 모든 네트워크 IP 주소의 트래픽을 허용하도록 구성되어 있습니다. 특정 IP 범위에 대한 네트워크 액세스를 제한하는 방법에 대해서는 이 페이지 뒷부분에서 참조되는 두 번째 아키텍처를 참조하세요.
- 네트워크 및 스토리지 대역폭을 최대한 활용하여 사용자 환경에 가장 적합한 처리량을 얻을 수 있도록 하기 위해 서버리스 방식으로 처리량을 쉽게 스케일 업할 수 있습니다.
- 초기 스냅샷 마이그레이션과 델타 데이터 마이그레이션은 모두 이 아키텍처를 사용하여 달성할 수 있습니다.
프라이빗 링크를 통해 데이터 마이그레이션:
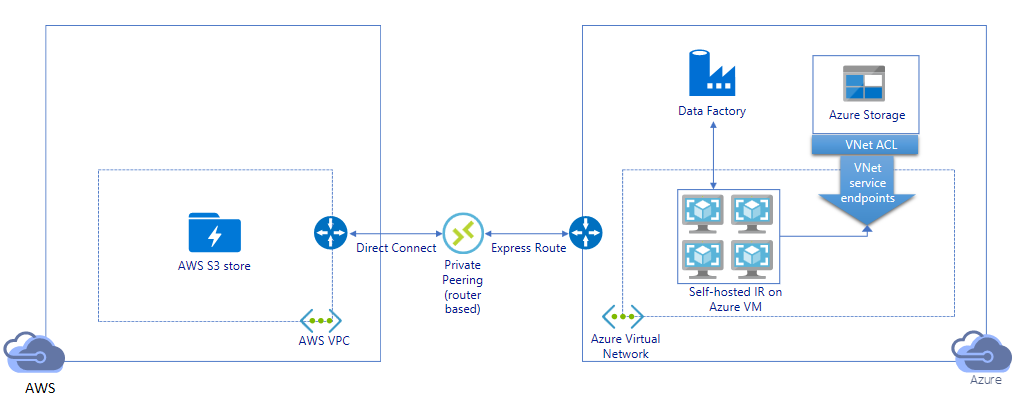
- 이 아키텍처에서 데이터 마이그레이션은 데이터가 퍼블릭 인터넷을 통해 트래버스되지 않도록 AWS Direct Connect와 Azure Express 경로 간의 프라이빗 피어링 링크를 통해 수행됩니다. AWS VPC 및 Azure Virtual Network를 사용해야 합니다.
- 이 아키텍처를 구현하려면 Azure Virtual Network 내의 Windows VM에 ADF 자체 호스팅 Integration Runtime을 설치해야 합니다. 자체 호스팅 IR VM을 수동으로 스케일 업하거나 여러 VM(최대 4개 노드)으로 스케일 아웃하여 네트워크 및 스토리지 IOPS/대역폭을 최대한 활용할 수 있습니다.
- 초기 스냅샷 데이터 마이그레이션과 델타 데이터 마이그레이션은 모두 이 아키텍처를 사용하여 달성할 수 있습니다.
구현 모범 사례
인증 및 자격 증명 관리
- Amazon S3 계정 인증을 받으려면 IAM 계정에 대 한 액세스 키를 사용해야 합니다.
- Azure Blob 스토리지에 연결하기 위해 여러 인증 유형이 지원됩니다. Azure 리소스용 관리 ID를 사용하는 것이 좋습니다. Microsoft Entra ID에서 자동으로 관리되는 ADF ID를 토대로 구축되므로 연결된 서비스 정의에서 자격 증명을 제공하지 않고 파이프라인을 구성할 수 있습니다. 또는 서비스 주체, 공유 액세스 서명 또는 스토리지 계정 키를 사용하여 Azure Blob 스토리지에서 인증을 받을 수 있습니다.
- Azure Data Lake Storage Gen2에 연결하는 데도 여러 인증 형식이 지원됩니다. 서비스 주체 또는 스토리지 계정 키도 사용할 수 있지만 Azure 리소스에 대해 관리 ID를 사용하는 것이 좋습니다.
- Azure 리소스에 대해 관리 ID를 사용하지 않는 경우 ADF 연결된 서비스를 수정하지 않고 보다 쉽게 키를 중앙에서 관리하고 순환하기 위해 Azure Key Vault에 자격 증명을 저장하는 것이 좋습니다. CI/CD에 대한 모범 사례 중 하나이기도 합니다.
초기 스냅샷 데이터 마이그레이션
데이터 파티션은 100TB 이상의 데이터를 마이그레이션할 때 특히 권장됩니다. 데이터를 분할하려면 '접두사' 설정을 사용하여 Amazon S3의 폴더와 파일을 이름으로 필터링합니다. 그러면 각 ADF 복사 작업에서 한 번에 하나의 파티션을 복사할 수 있습니다. 더 나은 처리량을 위해 여러 ADF 복사 작업을 동시에 실행할 수 있습니다.
네트워크 또는 데이터 저장소의 일시적 문제로 인해 복사 작업이 실패하는 경우 실패한 복사 작업을 다시 실행하여 AWS S3에서 특정 파티션을 다시 로드할 수 있습니다. 다른 파티션을 로드하는 다른 모든 복사 작업은 영향을 받지 않습니다.
델타 데이터 마이그레이션
AWS S3에서 새 파일 또는 변경된 파일을 식별하는 가장 효율적인 방법은 시간 분할 명명 규칙을 사용하는 것입니다. 즉, AWS S3의 데이터가 파일 또는 폴더 이름(예: /yyyy/mm/dd/file.csv)의 시간 조각 정보를 사용하여 분할된 경우 파이프라인은 증분 복사할 파일/폴더를 쉽게 식별할 수 있습니다.
또는 AWS S3의 데이터가 시간 분할되지 않은 경우 ADF는 새 파일 또는 변경된 파일을 LastModifiedDate에 따라 식별할 수 있습니다. ADF는 AWS S3의 모든 파일을 검색하고 마지막으로 수정된 타임스탬프가 특정 값보다 큰 새 파일 및 업데이트된 파일만 복사하는 방식으로 작동합니다. S3에 많은 파일이 있는 경우 초기 파일 검색은 필터 조건과 일치하는 파일 수에 관계없이 시간이 오래 걸릴 수 있습니다. 이 경우 파일 검색이 병렬로 수행될 수 있도록 초기 스냅샷 마이그레이션에 동일한 '접두사' 설정을 사용하여 데이터를 먼저 분할하는 것이 좋습니다.
Azure VM에서 자체 호스팅 Integration Runtime이 필요한 시나리오
프라이빗 링크를 통해 데이터를 마이그레이션하거나 Amazon S3 방화벽에서 특정 IP 범위를 허용하려면 Azure Windows VM에 자체 호스팅 Integration Runtime을 설치해야 합니다.
- 각 Azure VM에 대해 권장되는 구성은 32 vCPU 및 128GB 메모리를 포함하는 Standard_D32s_v3입니다. 데이터 마이그레이션 중에 IR VM의 CPU 및 메모리 사용률을 계속 모니터링하여 더 나은 성능을 위해 VM을 스케일 업하거나 비용을 절약하기 위해 VM을 스케일 다운해야 하는지 확인할 수 있습니다.
- 단일 자체 호스팅 IR을 통해 최대 4개의 VM 노드를 연결하여 스케일 아웃할 수도 있습니다. 자체 호스팅 IR에 대해 실행되는 단일 복사 작업은 파일 세트를 자동으로 분할하고 모든 VM 노드를 사용하여 파일을 병렬로 복사합니다. 고가용성을 위해서는 데이터 마이그레이션 중에 단일 실패 지점을 방지하기 위해 두 개의 VM 노드로 시작하는 것이 좋습니다.
속도 제한
모범 사례로, 대표적인 샘플 데이터 세트를 사용하여 성능 POC를 수행함으로써 적절한 파티션 크기를 결정할 수 있습니다.
단일 파티션과 기본 DIU 설정을 사용하는 단일 복사 작업으로 시작합니다. 네트워크의 대역폭 제한 또는 데이터 저장소의 IOPS/대역폭 제한에 도달하거나 단일 복사 작업에서 허용되는 최대 256 DIU에 도달할 때까지 DIU 설정을 점차적으로 늘립니다.
다음으로, 사용자 환경의 제한에 도달할 때까지 동시 복사 작업의 수를 점진적으로 늘립니다.
ADF 복사 작업에서 보고하는 제한 오류가 발생하는 경우 ADF에서 동시성 또는 DIU 설정을 줄이거나 네트워크 및 데이터 저장소의 대역폭/IOPS 제한을 늘리는 것이 좋습니다.
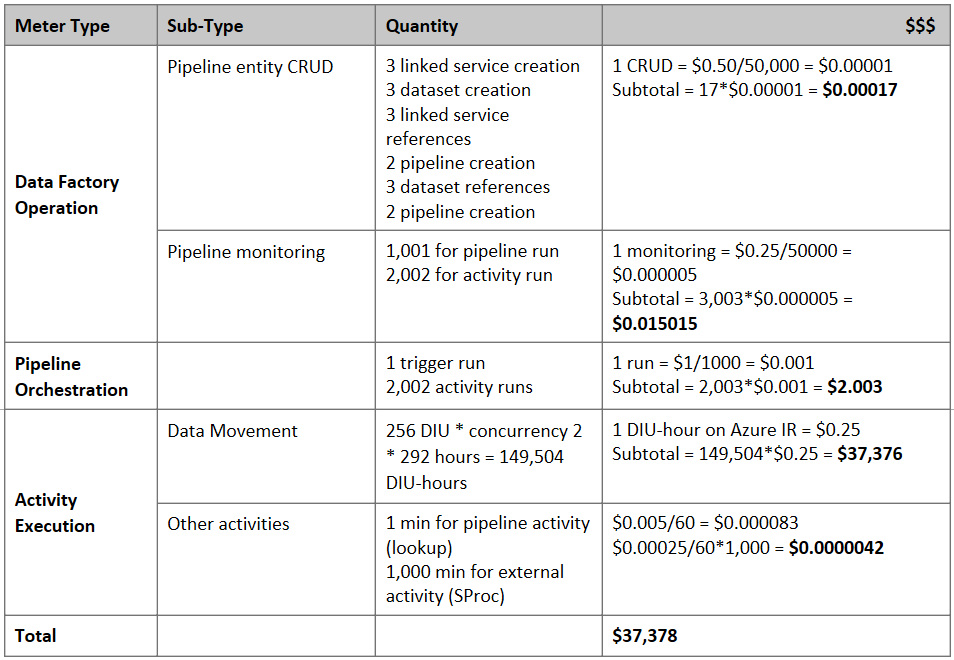
가격 예측
참고 항목
가상의 가격 책정 예제입니다. 실제 가격은 사용자 환경의 실제 처리량에 따라 달라집니다.
S3에서 Azure Blob 스토리지로 데이터를 마이그레이션하기 위해 생성된 다음 파이프라인을 고려하세요.
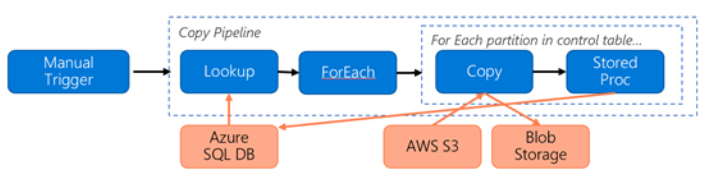
다음을 가정해 보세요.
- 총 데이터 볼륨은 2PB입니다.
- 첫 번째 솔루션 아키텍처를 사용하여 HTTPS를 통해 데이터를 마이그레이션합니다.
- 2PB는 1KB 파티션으로 나뉘고 각 복사 작업은 하나의 파티션을 이동합니다.
- 각 복사 작업은 DIU=256으로 구성되고 1GBps 처리량을 달성합니다.
- ForEach 동시성은 2로 설정되고 집계 처리량은 2GBps입니다.
- 마이그레이션을 완료하는 데 총 292시간이 소요됩니다.
위의 가정을 바탕으로 한 예상 가격은 다음과 같습니다.
추가 참조
- Amazon Simple Storage Service 커넥터
- Azure Blob Storage 커넥터
- Azure Data Lake Storage Gen2 커넥터
- 복사 작업 성능 조정 가이드
- 자체 호스팅 Integration Runtime 만들기 및 구성
- 자체 호스팅 Integration Runtime HA 및 확장성
- 데이터 이동 보안 고려 사항
- Azure Key Vault에 자격 증명 저장.
- 시간 분할 파일 이름에 따라 증분 방식으로 파일 복사
- LastModifiedDate에 따라 새 파일 및 변경된 파일 복사
- ADF 가격 책정 페이지
템플릿
다음은 수억 개의 파일로 구성된 페타바이트 크기 데이터를 Amazon S3에서 Azure Data Lake Storage Gen2으로 마이그레이션하기 위해 시작할 템플릿입니다.