매핑 데이터 흐름의 싱크 변환
적용 대상: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
데이터 흐름은 Azure Data Factory 및 Azure Synapse Pipelines 모두에서 사용할 수 있습니다. 이 문서는 매핑 데이터 흐름에 적용됩니다. 변환을 처음 사용하는 경우 매핑 데이터 흐름을 사용하여 데이터 변환 소개 문서를 참조하세요.
데이터 변환을 완료한 후에는 싱크 변환을 사용하여 대상 저장소에 데이터를 씁니다. 모든 데이터 흐름에는 하나 이상의 싱크 변환이 필요하지만 변환 흐름을 완료하는 데 필요한 수 만큼의 싱크에 쓸 수 있습니다. 추가 싱크에 쓰려면 새 분기 및 조건부 분할을 통해 새 스트림을 만듭니다.
각 싱크 변환은 정확히 하나의 데이터 세트 개체나 연결된 서비스와 연결됩니다. 싱크 변환은 작성하려는 데이터의 셰이프와 위치를 결정합니다.
인라인 데이터 세트
싱크 변환을 만들 때 싱크 정보가 데이터 세트 개체 내부에 정의되어 있는지 또는 싱크 변환 내에 정의되어 있는지 여부를 선택합니다. 대부분의 형식은 한 가지만 선택할 수 있습니다. 특정 커넥터를 사용하는 방법을 알아보려면 해당 커넥터 문서를 참조하세요.
특정 형식이 인라인 및 데이터 세트 개체 모두에 지원되는 경우 두 가지 다 이점이 있습니다. 데이터 세트 개체는 다른 데이터 흐름 및 복사와 같은 작업에서 사용될 수 있는 재사용 가능한 엔터티입니다. 이러한 재사용 가능한 엔터티는 강화된 스키마를 사용할 때 특히 유용합니다. 데이터 세트는 Spark를 기반으로 하지 않습니다. 경우에 따라 싱크 변환에서 특정 설정 또는 스키마 프로젝션을 재정의해야 할 수도 있습니다.
유연한 스키마, 일회용 싱크 인스턴스 또는 매개 변수가 있는 싱크를 사용하는 경우 인라인 데이터 세트를 사용하는 것이 좋습니다. 싱크에 매개 변수가 많은 경우 인라인 데이터 세트를 사용하여 "더미" 개체를 만들 수 없습니다. 인라인 데이터 세트는 Spark를 기반으로 하며 해당 속성은 데이터 흐름의 기본입니다.
인라인 데이터 세트를 사용하려면 싱크 형식 선택기에서 원하는 형식을 선택합니다. 싱크 데이터 세트를 선택하는 대신 연결하려는 연결된 서비스를 선택합니다.
작업 영역 DB(Synapse 작업 영역에만 해당)
Azure Synapse 작업 영역에서 데이터 흐름을 사용하는 경우 Synapse 작업 영역 내에 있는 데이터베이스 형식으로 직접 데이터를 싱크하는 추가 옵션이 제공됩니다. 이 옵션을 사용하면 해당 데이터베이스에 대한 연결된 서비스 또는 데이터 세트를 추가할 필요성이 줄어듭니다. Azure Synapse 데이터베이스 템플릿을 통해 만든 데이터베이스는 작업 영역 DB를 선택할 때도 액세스할 수 있습니다.
참고 항목
Azure Synapse 작업 영역 DB 커넥터는 현재 공개 미리 보기로 제공되며 지금은 Spark Lake 데이터베이스와만 사용할 수 있습니다.
지원되는 싱크 형식
매핑 데이터 흐름은 ELT(추출, 로드, 변환) 접근 방식을 따르며 모두 Azure에 있는 준비 데이터 세트와 함께 작동합니다. 현재 다음 데이터 세트를 싱크 변환에 사용할 수 있습니다.
| 커넥터 | 형식 | 데이터 세트/인라인 |
|---|---|---|
| Azure Blob Storage |
Avro 구분된 텍스트 델타 JSON ORC Parquet |
✓/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Cosmos DB for NoSQL | ✓/- | |
| Azure Data Lake Storage Gen1 |
Avro 구분된 텍스트 JSON ORC Parquet |
✓/- ✓/- ✓/- ✓/✓ ✓/- |
| Azure Data Lake Storage Gen2 |
Avro Common Data Model 구분된 텍스트 델타 JSON ORC Parquet |
✓/✓ -/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Database for MySQL | ✓/✓ | |
| Azure Database for PostgreSQL | ✓/✓ | |
| Azure Data Explorer | ✓/✓ | |
| Azure SQL Database | ✓/✓ | |
| Azure SQL Managed Instance | ✓/- | |
| Azure Synapse Analytics | ✓/- | |
| Dataverse | ✓/✓ | |
| Dynamics 365 | ✓/✓ | |
| Dynamics CRM | ✓/✓ | |
| Fabric Lakehouse | ✓/✓ | |
| SFTP |
Avro 구분된 텍스트 JSON ORC Parquet |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Snowflake | ✓/✓ | |
| SQL Server | ✓/✓ |
이러한 커넥터와 관련된 설정은 설정 탭에 있습니다. 이러한 설정에 대한 정보 및 데이터 흐름 스크립트 예제는 커넥터 설명서에 있습니다.
이 서비스는 90가지가 넘는 네이티브 커넥터에 액세스할 수 있습니다. 데이터 흐름에서 다른 원본으로 데이터를 쓰려면 복사 작업을 사용하여 지원되는 싱크에서 해당 데이터를 로드합니다.
싱크 설정
싱크를 추가한 후에는 싱크 탭을 통해 구성합니다. 여기서 싱크가 쓰는 데이터 세트를 선택하거나 만들 수 있습니다. 데이터 세트 매개 변수에 대한 개발 값은 디버그 설정에서 구성할 수 있습니다. (디버그 모드가 켜져 있어야 합니다.)
다음 비디오는 텍스트 구분 파일 형식에 대한 여러 싱크 옵션을 설명합니다.
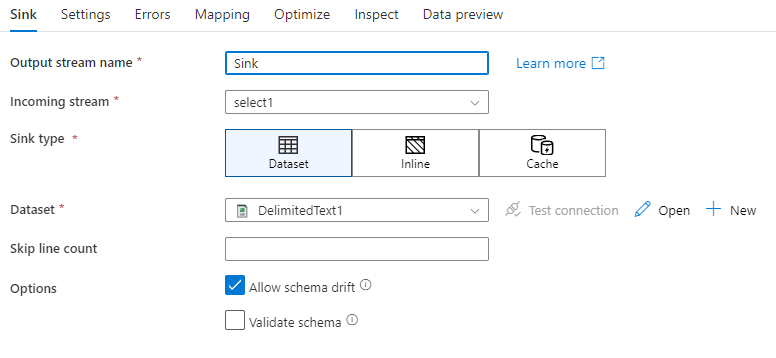
스키마 드리프트: 스키마 드리프트는 열 변경 내용을 명시적으로 정의할 필요 없이 데이터 흐름에서 유연한 스키마를 기본적으로 처리하는 서비스의 기능입니다. 스키마 드리프트 허용을 사용하도록 설정하여 싱크 데이터 스키마에 정의된 내용 위에 추가 열을 씁니다.
스키마 유효성 검사: 스키마 유효성 검사를 선택한 경우, 싱크 프로젝션의 열을 싱크 저장소에서 찾을 수 없거나 데이터 형식이 일치하지 않으면 데이터 흐름이 실패합니다. 이 설정을 사용하여 싱크 스키마가 정의된 프로젝션의 계약을 충족하도록 적용합니다. 데이터베이스 싱크 시나리오에서 열 이름 또는 형식이 변경되었다는 신호를 보내는 데 유용합니다.
캐시 싱크
캐시 싱크는 데이터 흐름이 데이터 저장소 대신 Spark 캐시에 데이터를 쓰는 경우입니다. 매핑 데이터 흐름에서는 캐시 조회를 사용하여 동일한 흐름 내에서 이 데이터를 여러 번 참조할 수 있습니다. 이 방법은 데이터를 식의 일부로 참조하지만 명시적으로 열에 조인하지 않으려는 경우에 유용합니다. 캐시 싱크가 데이터 저장소에서 최대값을 조회하고 오류 코드를 오류 메시지 데이터베이스와 일치시킬 수 있는 일반적인 예입니다.
캐시 싱크에 쓰려면 싱크 변환을 추가하고 싱크 형식으로 캐시를 선택합니다. 외부 저장소에 쓰지 않으므로 다른 싱크 형식과 달리 데이터 세트 또는 연결된 서비스를 선택할 필요가 없습니다.
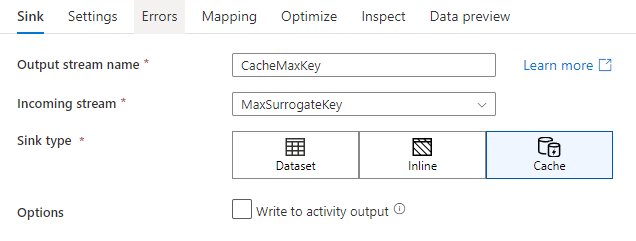
싱크 설정에서 필요에 따라 캐시 싱크의 키 열을 지정할 수 있습니다. 이는 캐시 조회에서 lookup() 함수를 사용할 때 일치 조건으로 사용됩니다. 키 열을 지정하는 경우 캐시 조회에 outputs() 함수를 사용할 수 없습니다. 캐시 조회 구문에 대해 자세히 알아보려면 캐시된 조회를 참조하세요.
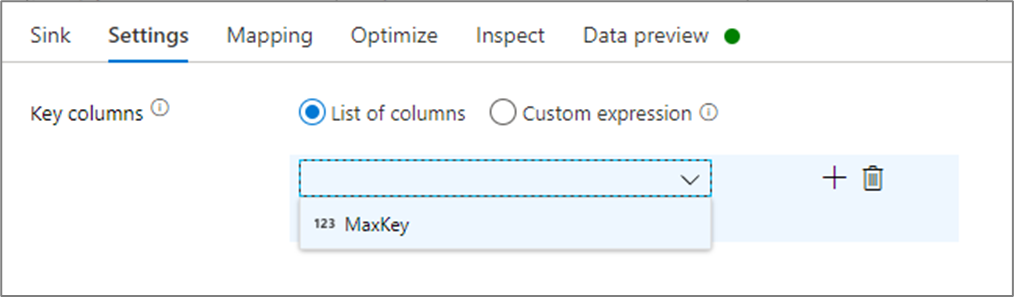
예를 들어, cacheExample이라는 캐시 싱크에 column1의 단일 키 열을 지정하는 경우, cacheExample#lookup()를 호출하면 하나의 매개 변수가 캐시 싱크에서 일치시킬 행을 지정합니다. 함수는 매핑되는 각 열에 대해 하위 열이 있는 단일 복합 열을 출력합니다.
참고 항목
캐시 싱크는 캐시 조회를 통해 참조하는 모든 변환에서 완전히 독립적인 데이터 스트림에 있어야 합니다. 또한 캐시 싱크는 작성된 첫 번째 싱크여야 합니다.
활동 출력에 쓰기
캐시 싱크는 필요에 따라 데이터 흐름 작업의 출력에 데이터를 쓸 수 있으며, 이 작업은 파이프라인의 다른 활동에 대한 입력으로 사용할 수 있습니다. 이렇게 하면 데이터 저장소에 데이터를 유지할 필요 없이 데이터 흐름 작업에서 데이터를 빠르고 쉽게 전달할 수 있습니다.
파이프라인에 직접 삽입되는 데이터 흐름의 출력은 2MB로 제한됩니다. 따라서 데이터 흐름은 2MB 제한 내에 있는 동안 가능한 한 많은 행을 출력에 추가하려고 시도하므로 활동 출력에 모든 행이 표시되지 않을 수 있습니다. 데이터 흐름 작업 수준에서 "첫 번째 행만"을 설정하면 필요한 경우 데이터 흐름의 데이터 출력을 제한하는 데도 도움이 됩니다.
Update 메서드
데이터베이스 싱크 형식의 경우 설정 탭에는 "Update 메서드" 속성이 포함됩니다. 기본값은 삽입이지만 update, upsert 및 delete에 대한 확인란 옵션도 포함됩니다. 이러한 추가 옵션을 활용하려면 싱크 앞에 행 변경 변환을 추가해야 합니다. 행 변경을 사용하면 각 데이터베이스 작업에 대한 조건을 정의할 수 있습니다. 원본이 네이티브 CDC 사용 원본인 경우 ADF가 insert, update, upsert 및 delete에 대한 행 표식을 이미 알고 있으므로 행 변경 없이 update 메서드를 설정할 수 있습니다.
필드 매핑
선택 변환과 마찬가지로 싱크의 매핑 탭에서 쓸 들어오는 열을 결정할 수 있습니다. 기본적으로 초안이 작성된 열을 포함한 모든 입력 열이 매핑됩니다. 이 동작을 automapping이라고 합니다.
자동 매핑을 끄는 경우, 고정 열 기반 매핑 또는 규칙 기반 매핑을 추가할 수 있습니다. 규칙 기반 매핑을 추가하면 패턴 일치를 사용하여 식을 쓸 수 있습니다. 고정 매핑은 논리적 및 물리적 열 이름을 매핑합니다. 규칙 기반 매핑에 대한 자세한 내용은 매핑 데이터 흐름의 열 패턴을 참조하세요.
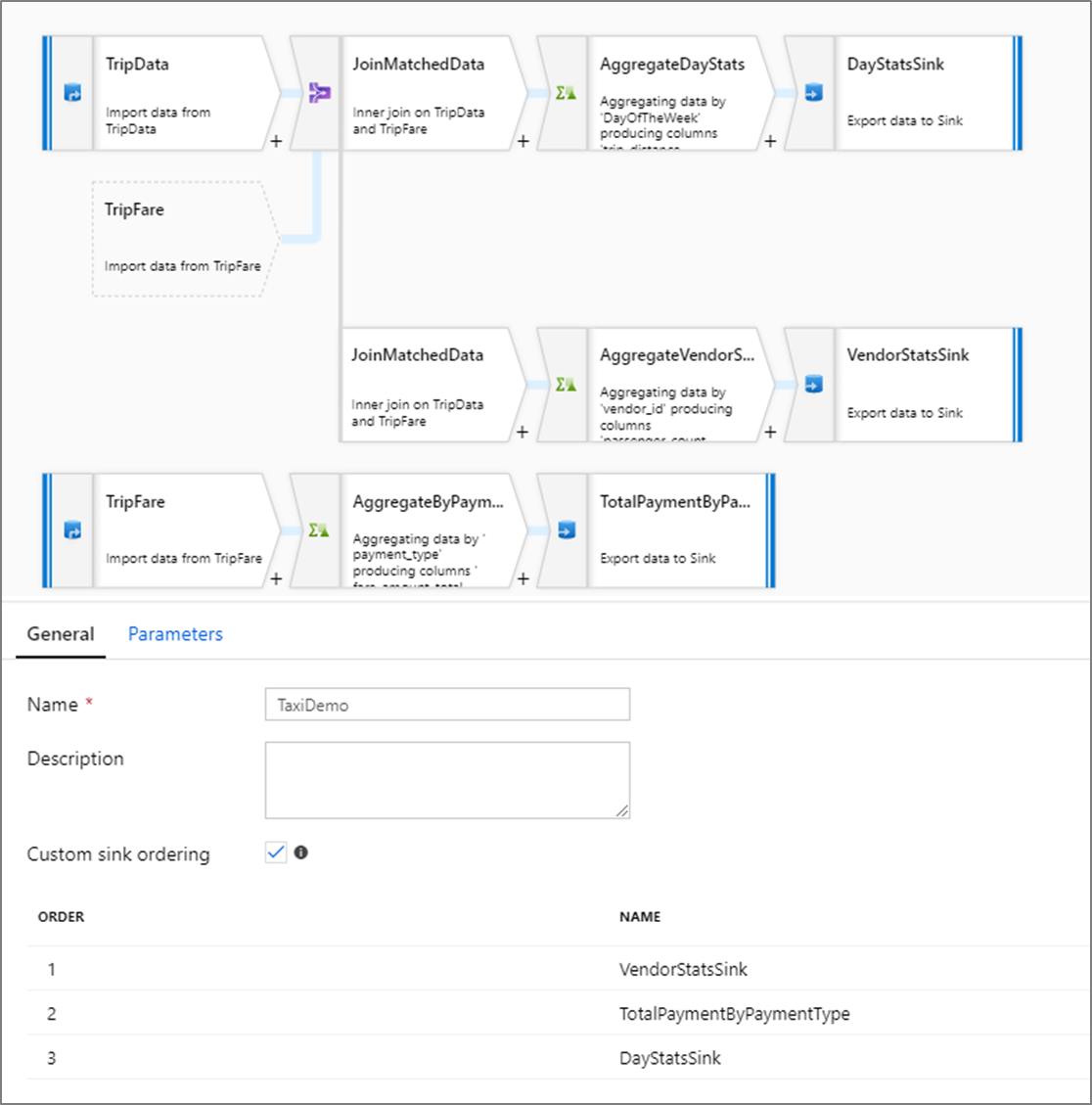
사용자 지정 싱크 순서
기본적으로 데이터는 비결정적 순서로 여러 싱크에 쓰여집니다. 변환 논리가 완료되면 실행 엔진이 데이터를 병렬로 쓰고 싱크 순서가 각 실행 마다 다를 수 있습니다. 정확한 싱크 순서를 지정하려면 데이터 흐름의 일반 탭에서 사용자 지정 싱크 를 사용하도록 설정합니다. 이렇게 설정하면 싱크가 오름차순으로 쓰여집니다.
참고 항목
캐시된 조회를 활용하는 경우 싱크 순서에서 캐시된 싱크가 가장 낮은 순서인 1 또는 first로 설정되어 있는지 확인합니다.
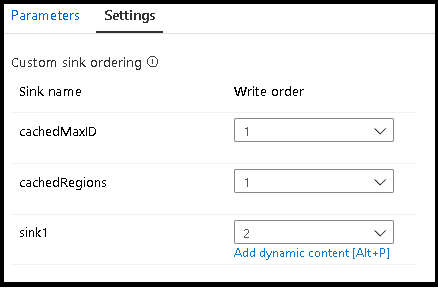
싱크 그룹
일련의 싱크에 동일한 순서 번호를 적용하여 싱크를 함께 그룹화할 수 있습니다. 이 서비스는 해당 싱크를 병렬로 실행할 수 있는 그룹으로 처리합니다. 병렬 실행 옵션은 파이프라인 데이터 흐름 작업에 노출됩니다.
Errors
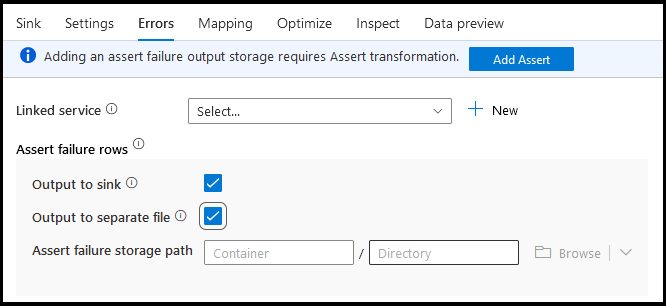
싱크 오류 탭에서 데이터베이스 드라이버 오류 및 실패한 어설션에 대한 출력을 캡처하고 리디렉션하도록 오류 행 처리를 구성할 수 있습니다.
데이터베이스에 쓸 때 대상에서 설정된 제약 조건으로 인해 특정 데이터 행이 실패할 수 있습니다. 기본적으로 첫 번째 오류가 발생할 때 데이터 흐름 실행이 실패합니다. 특정 커넥터에서 오류 발생 시 계속을 선택하여 개별 행에 오류가 있는 경우에도 데이터 흐름이 완료되도록 할 수 있습니다. 현재 이 기능은 Azure SQL Database와 Azure Synapse에서만 사용할 수 없습니다. 자세한 내용은 Azure SQL DB의 오류 행 처리를 참조하세요.
다음은 싱크 변환에서 자동으로 데이터베이스 오류 행 처리를 사용하는 방법에 대한 비디오 자습서입니다.
어설션 실패 행의 경우 데이터 흐름에서 어설션 변환 업스트림을 사용한 다음, 실패한 어설션을 싱크 오류 탭의 출력 파일로 리디렉션할 수 있습니다. 어설션 오류가 발생한 행을 무시하고 해당 행을 싱크 대상 데이터 저장소에 전혀 출력하지 않는 옵션도 있습니다.
싱크의 데이터 미리 보기
디버그 모드에서 데이터 미리 보기를 페치하는 경우 싱크에 데이터가 쓰여지지 않습니다. 데이터가 어떻게 표시되는지 보여 주는 스냅샷은 반환되지만 대상에는 아무것도 쓰여지지 않습니다. 싱크에 대한 데이터 쓰기를 테스트하려면 파이프라인 캔버스에서 파이프라인 디버그를 실행합니다.
데이터 흐름 스크립트
예시
다음은 싱크 변환 및 해당 데이터 흐름 스크립트의 예입니다.
sink(input(
movie as integer,
title as string,
genres as string,
year as integer,
Rating as integer
),
allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:false,
updateable:true,
upsertable:false,
keys:['movie'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
saveOrder: 1,
errorHandlingOption: 'stopOnFirstError') ~> sink1
관련 콘텐츠
데이터 흐름을 만들었으므로 파이프라인에 데이터 흐름 작업을 추가합니다.