Apache log4J 2 커넥터를 사용하여 데이터 수집
Log4J 는 Apache Foundation에서 유지 관리하며 Java 애플리케이션에 널리 사용되는 로깅 프레임워크입니다. Log4j를 사용하시게 되면 개발자가 로거 이름, 로거 수준 및 메시지 패턴을 기반으로 임의 세분성으로 출력되는 로그 문을 제어하실 수 있습니다. Apache Log4J 2는 Log4J의 업그레이드로 이전 Log4j 1.x보다 크게 향상되었습니다. Log4J 2는 Logback 아키텍처의 몇 가지 내재된 문제를 해결하는 동시에 Logback에서 사용할 수 있는 많은 향상된 기능을 제공합니다. 어펜더라고도 하는 Apache log4J 2 싱크는 로그 데이터를 Kusto의 테이블로 스트리밍하여 실시간으로 로그를 분석하고 시각화할 수 있습니다.
데이터 커넥터의 전체 목록은 데이터 통합 개요를 참조하세요.
필수 조건
- Apache Maven
- Microsoft Fabric의 KQL 데이터베이스 또는 Azure Data Explorer 클러스터 및 데이터베이스
환경 설정
이 섹션에서는 Log4J 2 싱크를 사용하도록 환경을 준비합니다.
패키지 설치
애플리케이션에서 싱크를 사용하려면 pom.xml Maven 파일에 다음 종속성을 추가합니다. 싱크에는 log4j-core가 애플리케이션에서 종속성으로 제공되어야 합니다.
<dependency>
<groupId>com.microsoft.azure.kusto</groupId>
<artifactId>azure-kusto-log4j</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
</dependency>
Microsoft Entra 앱 등록 만들기
Azure CLI를 통해 Azure 구독에 로그인합니다. 그런 다음 브라우저에서 인증합니다.
az login서비스 주체를 호스트하는 구독을 선택합니다. 이 단계는 여러 구독이 있는 경우에 필요합니다.
az account set --subscription YOUR_SUBSCRIPTION_GUID서비스 주체를 만듭니다. 이 예시에서는 서비스 주체를
my-service-principal이라고 합니다.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}반환된 JSON 데이터에서 나중에 사용할 수 있도록
appId,password,tenant를 복사합니다.{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
Microsoft Entra 애플리케이션과 서비스 주체를 만들었습니다.
Microsoft Entra 앱 권한 부여
쿼리 환경에서 다음 관리 명령을 실행합니다. 이때 자리 표시자 DatabaseName 및 applicaiton ID를 이전에 저장된 값으로 바꿉니다. 이 명령은 앱에 데이터베이스 수집자 역할을 부여합니다. 자세한 내용은 데이터베이스 보안 역할 관리를 참조하세요.
.add database DatabaseName ingestors ('aadappID=12345-abcd-12a3-b123-ccdd12345a1b') 'App Registration'참고 항목
마지막 매개 변수는 데이터베이스와 연결된 역할을 쿼리할 때 메모로 표시되는 문자열입니다. 자세한 내용은 데이터베이스 역할 관리를 참조하세요.
테이블 및 수집 매핑 만들기
수집된 데이터 열을 대상 테이블의 열에 매핑하여 들어오는 데이터에 대한 대상 테이블을 만듭니다. 다음 단계에서 테이블 스키마 및 매핑은 샘플 앱에서 보낸 데이터에 해당합니다.
쿼리 편집기에서 다음 테이블 만들기 명령을 실행합니다. 이때 자리 표시자 TableName을 대상 테이블의 이름으로 바꿉니다.
.create table log4jTest (timenanos:long,timemillis:long,level:string,threadid:string,threadname:string,threadpriority:int,formattedmessage:string,loggerfqcn:string,loggername:string,marker:string,thrownproxy:string,source:string,contextmap:string,contextstack:string)다음 수집 매핑 명령을 실행합니다. 이때 자리 표시자 TableName을 대상 테이블 이름으로, TableNameMapping을 수집 매핑의 이름으로 바꿉니다.
.create table log4jTest ingestion csv mapping 'log4jCsvTestMapping' '[{"Name":"timenanos","DataType":"","Ordinal":"0","ConstValue":null},{"Name":"timemillis","DataType":"","Ordinal":"1","ConstValue":null},{"Name":"level","DataType":"","Ordinal":"2","ConstValue":null},{"Name":"threadid","DataType":"","Ordinal":"3","ConstValue":null},{"Name":"threadname","DataType":"","Ordinal":"4","ConstValue":null},{"Name":"threadpriority","DataType":"","Ordinal":"5","ConstValue":null},{"Name":"formattedmessage","DataType":"","Ordinal":"6","ConstValue":null},{"Name":"loggerfqcn","DataType":"","Ordinal":"7","ConstValue":null},{"Name":"loggername","DataType":"","Ordinal":"8","ConstValue":null},{"Name":"marker","DataType":"","Ordinal":"9","ConstValue":null},{"Name":"thrownproxy","DataType":"","Ordinal":"10","ConstValue":null},{"Name":"source","DataType":"","Ordinal":"11","ConstValue":null},{"Name":"contextmap","DataType":"","Ordinal":"12","ConstValue":null},{"Name":"contextstack","DataType":"","Ordinal":"13","ConstValue":null}]'
앱에 Log4j 2 싱크 추가
다음 단계에 따라 다음을 수행합니다.
- 앱에 Log4j 2 싱크 추가
- 싱크에서 사용하는 변수를 구성
- 앱 빌드 및 실행
애플리케이션에 다음 코드를 추가합니다.
package com.microsoft.azure.kusto.log4j.sample; import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger;log4j2.xml 파일에
KustoStrategy항목을 추가하여 Log4j 2 싱크를 구성합니다. 이때 다음 표의 정보를 사용하여 자리 표시자를 바꿉니다.log4J 2 커넥터는 RollingFileAppender에 사용되는 사용자 지정 전략을 사용합니다. Kusto 클러스터에 연결하는 동안 네트워크 오류로 인해 발생하는 데이터 손실을 방지하기 위해 로그가 롤링 파일에 기록됩니다. 데이터는 롤링 파일에 저장된 후 Kusto 클러스터로 플러시됩니다.
<KustoStrategy clusterIngestUrl = "${env:LOG4J2_ADX_INGEST_CLUSTER_URL}" appId = "${env:LOG4J2_ADX_APP_ID}" appKey = "${env:LOG4J2_ADX_APP_KEY}" appTenant = "${env:LOG4J2_ADX_TENANT_ID}" dbName = "${env:LOG4J2_ADX_DB_NAME}" tableName = "<MyTable>" logTableMapping = "<MyTableCsvMapping>" mappingType = "csv" flushImmediately = "false" />속성 설명 clusterIngestUrl https://ingest-<cluster>.<region>.kusto.windows.net 형식의 클러스터에 대한 수집 URI. dbname 대상 데이터베이스의 대/소문자 구분 이름입니다. tableName 기존 대상 테이블의 대/소문자 구분 이름. 예를 들어 Log4jTest는 테이블 및 수집 매핑 만들기에서 만든 테이블의 이름입니다. appId 인증에 필요한 애플리케이션 클라이언트 ID. Microsoft Entra 앱 등록 만들기에서 이 값을 저장했습니다. appKey 인증에 필요한 애플리케이션 키. Microsoft Entra 앱 등록 만들기에서 이 값을 저장했습니다. appTenant 애플리케이션이 등록된 테넌트 ID. Microsoft Entra 앱 등록 만들기에서 이 값을 저장했습니다. logTableMapping 매핑 이름입니다. mappingType 사용할 매핑의 유형. 기본값은 csv입니다. flushImmediately true로 설정하면 싱크는 각 로그 이벤트 후 버퍼를 플러시합니다. 기본값은 false입니다. 자세한 옵션은 싱크 옵션을 참조하세요.
Log4j 2 싱크를 사용하여 Kusto로 데이터를 보냅니다. 예시:
import java.util.concurrent.Executors; import java.util.concurrent.ScheduledExecutorService; import java.util.concurrent.TimeUnit; public class MyClass { private static final Logger logger = LogManager.getLogger(KustoLog4JSampleApp.class); public static void main(String[] args) { Runnable loggingTask = () -> { logger.trace(".....read_physical_netif: Home list entries returned = 7"); logger.debug(".....api_reader: api request SENDER"); logger.info(".....read_physical_netif: index #0, interface VLINK1 has address 129.1.1.1, ifidx 0"); logger.warn(".....mailslot_create: setsockopt(MCAST_ADD) failed - EDC8116I Address not available."); logger.error(".....error_policyAPI: APIInitializeError: ApiHandleErrorCode = 98BDFB0, errconnfd = 22"); logger.fatal(".....fatal_error_timerAPI: APIShutdownError: ReadBuffer = 98BDFB0, RSVPGetTSpec = error"); }; ScheduledExecutorService executor = Executors.newScheduledThreadPool(1); executor.scheduleAtFixedRate(loggingTask, 0, 3, TimeUnit.SECONDS); } }앱을 빌드하고 실행합니다.
데이터가 클러스터에 있는지 확인합니다. 쿼리 환경에서 다음 쿼리를 실행합니다. 이때 자리 표시자를 이전에 사용한 테이블 이름으로 바꿉니다.
<TableName> | take 10
샘플 앱 실행
다음 git 명령을 사용하여 log4J 2 git 리포지토리를 복제합니다.
git clone https://github.com/Azure/azure-kusto-log4j.gitLog4J 2 싱크를 구성하려면 다음 환경 변수를 설정합니다.
참고 항목
git 리포지토리에 포함된 샘플 프로젝트에서 기본 구성 형식은 log4j2.xml 파일에 정의됩니다. 이 구성 파일은 \azure-kusto-log4j\samples\src\main\resources\log4j2.xml 파일 경로 아래에 있습니다.
터미널에서 복제된 리포지토리의 샘플 폴더로 이동하고 다음 Maven 명령을 실행합니다.
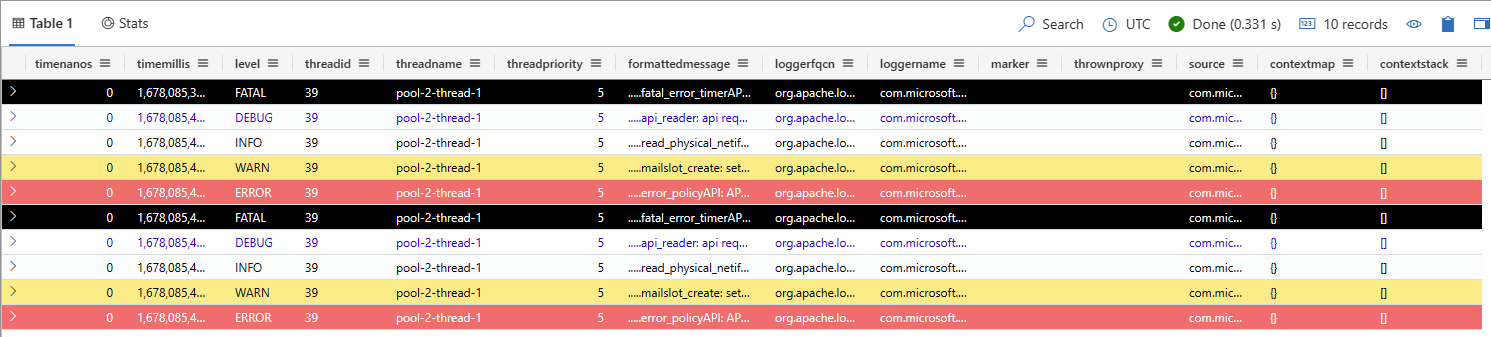
mvn compile exec:java -Dexec.mainClass="org.example.KustoLog4JSampleApp"쿼리 환경에서 대상 데이터베이스를 선택하고 다음 쿼리를 실행하여 수집된 데이터를 탐색합니다. 이때 자리 표시자 TableName 을 대상 테이블의 이름으로 바꿉니다.
<TableName> | take 10출력은 다음 테이블과 유사해야 합니다.

관련 콘텐츠
- 데이터 커넥터 개요
- KQL(Kusto 쿼리 언어) 개요
- Azure Data Explorer에 대한 Azure Databricks Log4J 시작 Git 리포지토리
- Log4j2 - Azure Data Explorer 커넥터 커뮤니티 블로그를 사용하여 Azure Databricks 로그를 Azure Data Explorer에 수집