프로비저닝된 처리량(RU/s) 스케일링 모범 사례
적용 대상: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() 테이블
테이블
이 문서에서는 데이터베이스 또는 컨테이너(컬렉션, 표 또는 그래프)의 처리량(RU/s) 스케일링 모범 사례 및 전략을 설명합니다. 이 개념은 프로비저닝된 수동 RU/s 또는 Azure Cosmos DB API에 대한 리소스의 자동 스케일링 최대 RU/s를 높일 때 적용됩니다.
필수 조건
- Azure Cosmos DB의 분할 및 스케일링을 처음 접하는 경우에는 Azure Cosmos DB의 분할 및 수평적 크기 조정 문서부터 읽는 것이 좋습니다.
- 429개 예외로 인해 RU/s를 스케일링할 계획인 경우 Azure Cosmos DB 요청 빈도 너무 높음(429) 예외 진단 및 문제 해결의 지침을 검토하세요. RU/s를 늘리기 전에, 문제의 근본 원인을 파악하고 RU/s를 늘리는 것이 올바른 솔루션인지 확인합니다.
RU/s 스케일링에 대한 배경 지식
데이터베이스 또는 컨테이너의 RU/s를 늘려 달라고 요청을 보내면, 요청된 RU/s 및 현재 물리적 파티션 레이아웃에 따라 스케일 업 작업이 즉시 또는 비동기적으로 완료됩니다(일반적으로 4-6시간).
- 즉시 스케일 업
- 요청한 RU/s를 현재 물리적 파티션 레이아웃에서 지원할 수 있는 경우 Azure Cosmos DB는 새 파티션을 분할하거나 추가할 필요가 없습니다.
- 따라서 작업이 즉시 완료되고 RU/s를 사용할 수 있게 됩니다.
- 비동기식 스케일 업
- 요청된 RU/s가 물리적 파티션 레이아웃에서 지원할 수 있는 용량보다 많은 경우 Azure Cosmos DB는 기존 물리적 파티션을 분할합니다. 요청된 RU/s를 지원하는 데 필요한 최소 파티션 수가 될 때까지 이 작업이 발생합니다.
- 따라서 작업을 완료하는 데 다소 시간이 걸릴 수 있습니다(일반적으로 4-6시간). 각 물리적 파티션은 최대 10,000RU/s(모든 API에 적용) 처리량과 50GB 스토리지(30GB 스토리지가 있는 Cassandra를 제외한 모든 API에 적용)를 지원할 수 있습니다.
참고 항목
비동기식 스케일 업 작업이 진행되는 동안 수동 지역 장애 조치(failover) 또는 새 지역 추가/제거 작업을 수행하면 처리량 스케일 업 작업이 일시 중지됩니다. 장애 조치(failover) 또는 지역 추가/제거 작업이 완료되면 자동으로 다시 시작됩니다.
- 즉시 스케일 다운
- 스케일 다운 작업의 경우 Azure Cosmos DB는 새 파티션을 분할하거나 추가할 필요가 없습니다.
- 따라서 작업이 즉시 완료되고 RU/s를 사용할 수 있게 됩니다.
- 이 작업의 주요 결과로 물리적 파티션당 RU가 감소합니다.
파티션 레이아웃을 변경하지 않고 RU/s를 스케일 업하는 방법
1단계: 현재 물리적 파티션 수를 확인합니다.
인사이트>처리량>PartitionKeyRangeID별 정규화된 RU 사용량(%)으로 이동합니다. 고유한 PartitionKeyRangeIds 수를 계산합니다.
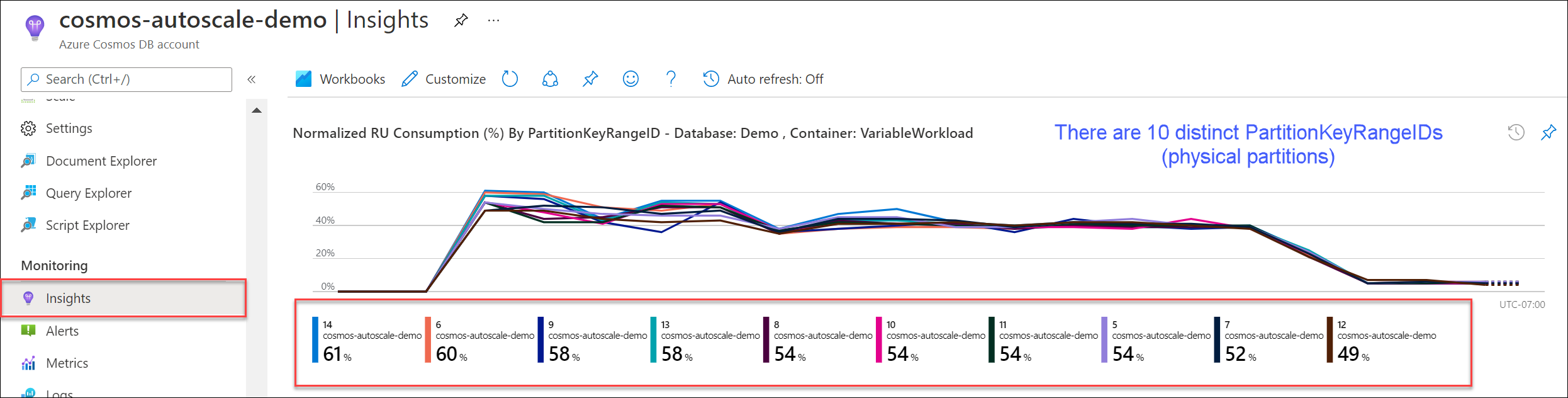
참고 항목
이 차트에는 최대 50개의 PartitionKeyRangeIds가 표시됩니다. 리소스에 50개 넘게 있는 경우에는 Azure Cosmos DB REST API를 사용하여 총 파티션 수를 계산할 수 있습니다.
각 PartitionKeyRangeId는 하나의 물리적 파티션에 매핑되며 가능한 해시 값 범위의 데이터를 보유하도록 할당됩니다.
Azure Cosmos DB는 파티션 키를 기반으로 논리 파티션 및 물리 파티션에 데이터를 분산하여 수평적 스케일링을 가능하게 합니다. 데이터가 작성되면 Azure Cosmos DB는 파티션 키 값의 해시를 사용하여 데이터가 있는 논리 및 물리 파티션을 파악합니다.
2단계: 기본 최대 처리량 계산
파티션을 분할하도록 Azure Cosmos DB를 트리거하지 않고 스케일링할 수 있는 최대 RU/s는 Current number of physical partitions * 10,000 RU/s와 동일합니다. Azure Cosmos DB 리소스 공급자에서 이 값을 가져올 수 있습니다. 데이터베이스 또는 컨테이너 처리량 설정 개체에 대해 GET 요청을 수행하고 instantMaximumThroughput 속성을 검색합니다. 이 값은 포털에서 데이터베이스 또는 컨테이너의 스케일링 및 설정 페이지에서도 사용할 수 있습니다.
예시
5개의 물리적 파티션과 30,000RU/s의 처리량이 수동으로 프로비저닝된 기존 컨테이너가 있다고 가정하겠습니다. RU/s를 5 * 10,000 RU/s = 50,000RU/s로 즉시 늘릴 수 있습니다. 마찬가지로 자동 스케일링 최대 RU/s가 30,000RU/s인(3000~30,000RU/s 사이에서 스케일링) 컨테이너가 있는 경우 최대 RU/s를 즉시 50,000RU/s로 늘릴 수 있습니다(5000~50,000RU/s 사이에서 스케일링).
팁
요청 비율이 너무 큰 예외(429초)에 응답하기 위해 RU/s를 스케일 업하는 경우 먼저 RU/s를 현재 물리적 파티션 레이아웃에서 지원되는 최대 RU/s로 늘리고 새 RU/s가 충분한지 평가한 후 더 늘리는 것이 좋습니다.
비동기 스케일링 중에 데이터가 분산되도록 하는 방법
배경
현재 물리적 파티션 수 * 10,000RU/s를 초과하도록 RU/s를 늘리면 Azure Cosmos DB는 새 파티션 수 = ROUNDUP(requested RU/s / 10,000 RU/s)이 될 때까지 기존 파티션을 분할합니다. 분할하는 동안 부모 파티션은 2개의 자식 파티션으로 분할됩니다.
예를 들어 3개의 물리적 파티션과 30,000RU/s의 처리량이 수동으로 프로비저닝된 컨테이너가 있다고 가정하겠습니다. 처리량을 45,000RU/s로 늘렸다면 Azure Cosmos DB는 기존 물리적 파티션 2개를 분할하므로, 총 ROUNDUP(45,000 RU/s / 10,000 RU/s) = 5개의 물리적 파티션이 있습니다.
참고 항목
애플리케이션은 분할하는 동안 언제든지 데이터를 수집하거나 쿼리할 수 있습니다. Azure Cosmos DB 클라이언트 SDK 및 서비스는 이 시나리오를 자동으로 처리하고 요청이 올바른 물리적 파티션으로 라우팅되도록 하므로 추가적인 사용자 작업이 필요하지 않습니다.
스토리지 및 요청 볼륨과 관련하여 매우 균등하게 분산된 워크로드가 있는 경우 일반적으로 /id와 같은 높은 카디널리티 필드로 분할하여 수행되며, 스케일 업할 때 모든 파티션이 균등하게 분할되도록 RU/s를 설정하는 것이 좋습니다.
그 이유를 살펴보기 위해 물리적 파티션 2개, 20,000RU/s 및 80GB 데이터가 있는 기존 컨테이너를 예로 들겠습니다.
카디널리티가 높은 좋은 파티션 키를 선택하기 때문에 데이터는 두 물리적 파티션에 대체적으로 균등하게 분산됩니다. 각 물리적 파티션에는 가능한 해시 값의 총 범위로 정의되는 키스페이스의 약 50%가 할당됩니다.
또한 Azure Cosmos DB는 모든 물리적 파티션에 RU/s를 균등하게 분산합니다. 따라서 각 물리적 파티션에는 10,000RU/s와 전체 데이터의 50%(40GB)가 있습니다. 다음 다이어그램은 현재 상태를 보여줍니다.

이제 RU/s를 20,000RU/s에서 30,000RU/s로 늘리려 한다고 가정합니다.
간단하게 RU/s를 30,000RU/s로 늘리면 파티션 중 하나만 분할됩니다. 분할 후에는 다음과 같이 바뀝니다.
- 데이터의 50%를 포함하는 파티션 1개(이 파티션은 분할되지 않음)
- 각각 데이터의 25%를 포함하는 파티션 2개(분할된 부모의 결과로 생성된 자식 파티션)
Azure Cosmos DB는 모든 물리적 파티션에 RU/s를 균등하게 분산하므로, 각 물리적 파티션은 여전히 10,000RU/s를 얻습니다. 그러나 이제 스토리지 및 요청 분산에 차이가 있습니다.
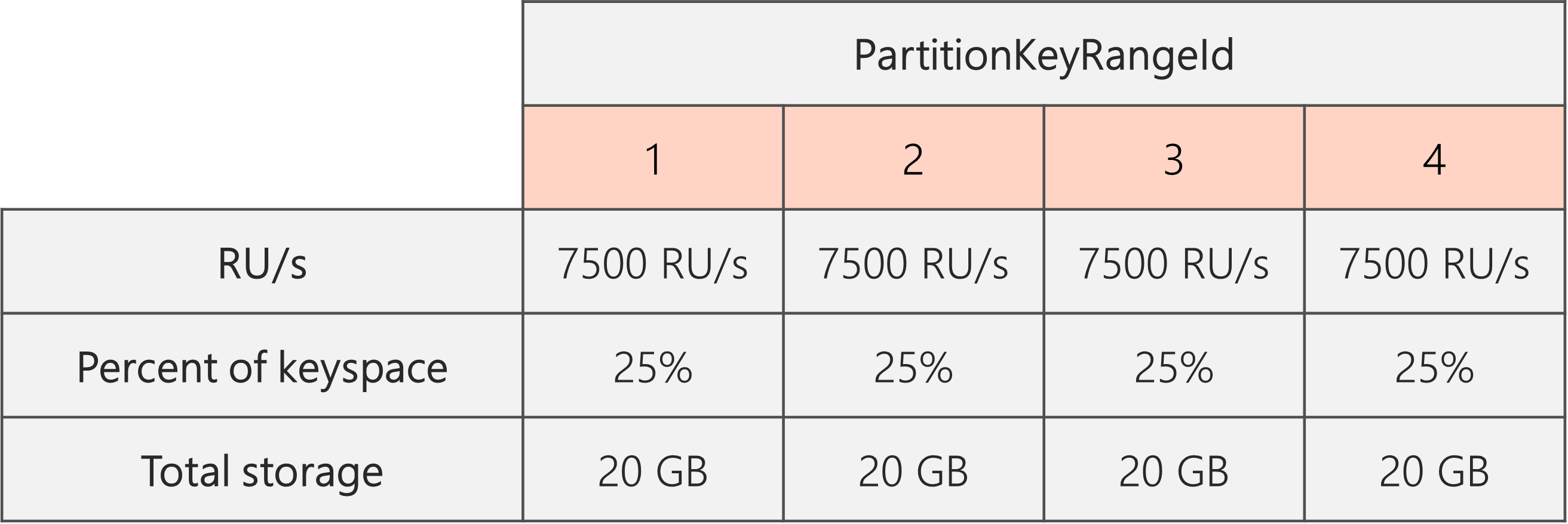
다음 다이어그램에서 파티션 3과 4(파티션 2의 자식 파티션)에는 20GB 데이터 요청을 처리하도록 각각 10,000RU/s가 있고, 파티션 1에는 데이터 양의 2배(40GB)에 해당하는 요청을 처리하도록 10,000RU/s가 있습니다.

균등한 스토리지 분산을 유지하려면 먼저 모든 파티션이 분할되도록 RU/s를 스케일 업합니다. 그런 다음, RU/s를 다시 원하는 상태로 줄이면 됩니다.
따라서 물리적 파티션 2개로 시작하는 경우 파티션이 분할 후 균등하게 분산되도록 보장하려면 최종적으로 물리적 파티션 4개가 되도록 RU/s를 설정해야 합니다. 이렇게 하려면 먼저 RU/s = 4 * 파티션당 10,000RU/s = 40,000RU/s를 설정합니다. 그런 다음, 분할이 완료되면 RU/s를 30,000RU/s로 낮출 수 있습니다.
결과적으로 다음 다이어그램처럼 각 물리적 파티션은 20GB 데이터에 대한 요청을 처리하도록 30,000RU/s/4 = 7500RU/s를 얻게 됩니다. 전체적으로 모든 파티션에서 스토리지 및 요청 배포가 균등하게 유지됩니다.
일반 수식
1단계: 모든 파티션이 균등하게 분할되도록 RU/s 늘리기
일반적으로 물리적 파티션 P개로 시작한 후 RU/s를 S로 설정하려는 경우:
RU/s를 10,000 * P * (2 ^ (ROUNDUP(LOG_2 (S/(10,000 * P))))로 늘립니다. 이렇게 하면 모든 파티션이 균등하게 분할되는 원하는 값에 가장 가까운 RU/s를 제공할 수 있습니다.
참고 항목
데이터베이스 또는 컨테이너의 RU/s를 늘리면 향후 낮출 수 있는 최소 RU/s에 영향을 줄 수 있습니다. 일반적으로 최소 RU/s는 MAX(400RU/s, 현재 스토리지(GB) * 1RU/s, 지금까지 프로비저닝된 최대 RU/s/100)와 동일합니다. 예를 들어 지금까지 스케일링한 최대 RU/s가 100,000RU/s인 경우 향후 설정할 수 있는 최소 RU/s는 1000RU/s입니다. 최소 RU/s에 대해 자세히 알아보세요.
2단계: RU/s를 원하는 RU/s로 낮추기
예를 들어 5개의 물리적 파티션, 50,000RU/s가 있는데 150,000RU/s로 스케일링하려 한다고 가정하겠습니다. 먼저 10,000 * 5 * (2 ^ (ROUND(LOG_2(150,000/(10,000 * 5)))) = 200,000RU/s로 설정한 다음, 150,000RU/s로 낮춰야 합니다.
200,000RU/s까지 스케일 업하면 향후 설정할 수 있는 최소 수동 RU/s는 2000RU/s입니다. 우리가 설정할 수 있는 최소 자동 스케일링 최대 RU/s는 20,000RU/s입니다(2000~20,000RU/s에서 스케일링). 대상 RU/s는 150,000RU/s이므로 최소 RU/s의 영향을 받지 않습니다.
대규모 데이터 수집을 위해 RU/s를 최적화하는 방법
Azure Cosmos DB로 대량의 데이터를 마이그레이션하거나 수집할 계획인 경우 수집하려는 전체 데이터 양을 저장하는 데 필요한 물리적 파티션을 Azure Cosmos DB에서 미리 프로비저닝할 수 있도록 컨테이너의 RU/s를 설정하는 것이 좋습니다. 그렇지 않으면 데이터를 수집하는 동안 Azure Cosmos DB에서 파티션을 분할해야 할 수 있으며, 이 경우 데이터 수집에 걸리는 시간이 늘어납니다.
컨테이너를 만드는 동안 Azure Cosmos DB는 시작 RU/s 휴리스틱 수식을 사용하여 시작할 물리적 파티션 수를 계산할 수 있습니다.
1단계: 파티션 키 옵션 검토
요청 볼륨과 마이그레이션 후 스토리지가 균등하게 분산되도록 파티션 키 선택에 대한 모범 사례를 따릅니다.
2단계: 필요한 실제 파티션 수 계산
Number of physical partitions = Total data size in GB / Target data per physical partition in GB
각 물리적 파티션은 최대 50GB의 스토리지를 보유할 수 있습니다(API for Cassandra는 30GB). Target data per physical partition in GB에 대해 선택해야 하는 값은 물리적 파티션을 얼마나 가득 패킹할 것인지, 마이그레이션 후 스토리지를 얼마나 늘릴 것인지에 따라 달라집니다.
예를 들어 스토리지가 계속 증가할 것으로 예상되면 값을 30GB로 설정할 수 있습니다. 스토리지를 균등하게 분산하는 좋은 파티션 키를 선택했다면 각 파티션은 60%(50GB 중 30GB)까지 채워집니다. 향후 데이터가 기록되면 물리적 파티션을 즉시 추가하도록 서비스에 요구하지 않고도 기존 물리적 파티션 세트에 저장할 수 있습니다.
반면 스토리지가 마이그레이션 후에 크게 증가하지 않을 것으로 예상되면 값을 더 높게(예: 45GB) 설정할 수 있습니다. 즉, 각 파티션이 90%(50GB 중 45GB)까지 채워집니다. 이렇게 하면 데이터가 분산되는 물리적 파티션의 수가 최소화됩니다. 즉, 각 물리적 파티션은 프로비저닝된 총 RU/s를 더 많이 얻을 수 있습니다.
3단계: 모든 파티션에 대해 시작할 RU/s 계산
Starting RU/s for all partitions = Number of physical partitions * Initial throughput per physical partition;
실제 파티션당 임의의 수의 대상 RU/s를 사용하는 예제로 시작해 보겠습니다.
Initial throughput per physical partition= 자동 스케일링 또는 공유 처리량 데이터베이스를 사용하는 경우 실제 파티션당 10,000RU/sInitial throughput per physical partition= 수동 처리량을 사용하는 경우 실제 파티션당 6000 RU/s
예시
데이터 1TB(1000GB)를 수집할 계획이고 수동 처리량을 사용하려 한다고 가정하겠습니다. Azure Cosmos DB의 각 물리적 파티션에는 50GB의 용량이 있습니다. 파티션을 80%(40GB)까지 채우고, 나머지는 향후 성장을 위해 남겨 두기로 한다고 가정하겠습니다.
즉, 1TB 데이터에는 1000GB/40GB = 25개의 물리적 파티션이 필요합니다. 25개의 물리적 파티션을 얻으려면 수동 처리량을 사용할 경우 먼저 25 * 6000RU/s = 150,000RU/s를 프로비저닝해야 합니다. 그런 다음, 컨테이너를 만든 후 데이터를 더 빨리 수집할 수 있도록 수집이 시작되기 전에 RU/s를 250,000RU/s로 늘립니다(이미 25개의 물리적 파티션이 있기 때문에 즉시 발생합니다). 이렇게 하면 각 파티션에서 최대 10,000RU/s를 얻게 됩니다.
25개의 물리적 파티션을 얻기 위해 자동 스케일링 작업량 또는 공유 처리량 데이터베이스를 사용하는 경우 먼저 25 * 10,000RU/s = 250,000RU/s를 프로비저닝해야 합니다. 25개의 물리적 파티션으로 지원할 수 있는 최대 RU/s에 이미 도달했으므로, 데이터 수집 전에 프로비저닝된 RU/s를 더 이상 늘리지 않겠습니다.
이론적으로 250,000RU/s 및 1TB 데이터가 있고 쓰기에 1kb 문서와 10RU가 필요하다고 가정하면 이론적으로 1000GB * (1,000,000kb/1GB) * (1개 문서/1kb) * (10RU/문서) * (1초/250,000RU) * (1시간/3600초) = 11.1시간 후에 수집이 완료될 수 있습니다.
이 계산은 데이터를 수집하는 클라이언트가 모든 물리적 파티션에 쓰기를 완전히 채우고 분산할 수 있다는 가정을 전제로 합니다. 클라이언트 쪽에서 데이터를 "셔플"하는 것이 가장 좋습니다. 이렇게 하면 1초마다 클라이언트가 여러 고유한 논리적(그리고 따라서 물리적) 파티션에 데이터를 씁니다.
마이그레이션이 완료된 후에는 RU/s를 낮추거나 필요한 경우 자동 스케일링을 사용하도록 설정할 수 있습니다.
다음 단계
- 데이터베이스 또는 컨테이너의 정규화 RU/초 사용량을 모니터링합니다.
- 요청 빈도 너무 높음(429) 예외를 진단하고 문제를 해결합니다.
- 데이터베이스 또는 컨테이너에서 자동 스케일링을 사용하도록 설정합니다.