vCore 기반 Azure Cosmos DB for MongoDB를 사용한 RAG(검색 보강 생성)
빠르게 진화하는 생성형 AI 부문에서 GPT-3.5와 같은 LLM(대규모 언어 모델)은 자연어 처리를 변화시켰습니다. 그러나 AI의 새로운 추세는 AI 애플리케이션을 향상하는 데 중요한 역할을 하는 벡터 저장소를 사용하는 것입니다.
이 자습서에서는 Azure Cosmos DB for MongoDB(vCore), LangChain, OpenAI를 사용하여 RAG(검색 증강 생성)로 뛰어난 AI 성능을 구현하는 방법을 살펴보고 LLM과 그 제한 사항을 설명합니다. 빠르게 채택된 "RAG(검색 증강 생성)" 패러다임을 살펴보고 LangChain 프레임워크인 Azure OpenAI 모델을 간략하게 설명합니다. 마지막으로 이러한 개념을 실제 애플리케이션에 통합합니다. 이 자습서를 마친 독자는 이러한 개념을 확실하게 이해하게 될 것입니다.
LLM(대규모 언어 모델)과 그 제한 사항 이해
LLM(큰 언어 모델)은 광범위한 텍스트 데이터 세트에 대해 학습된 고급 심층 신경망 모델로, 인간이 쓴 듯한 텍스트를 이해하고 생성할 수 있습니다. 자연어 처리 분야에서 혁명적이지만 LLM에는 제한 사항이 내재되어 있습니다.
- 환각: LLM은 때때로 "환각"으로 알려진 사실상 틀리거나 근거 없는 정보를 생성합니다.
- 부실 데이터: LLM은 최신 정보를 포함하지 않을 수 있는 정적 데이터 세트로 학습되어 현재 정보와의 관련성이 제한적입니다.
- 사용자의 로컬 데이터에 대한 액세스 권한 없음: LLM은 개인 데이터 또는 로컬 데이터에 직접 액세스할 수 없으므로 개인화된 응답을 제공하는 능력이 제한됩니다.
- 토큰 제한: LLM에는 상호 작용당 최대 토큰 제한이 있으므로 한 번에 처리할 수 있는 텍스트 양이 제한됩니다. 예를 들어 OpenAI의 gpt-3.5-turbo의 토큰 제한은 4096입니다.
RAG(검색 증강 생성) 활용
RAG(검색 증강 생성)는 LLM 제한 사항을 극복하도록 설계된 아키텍처입니다. RAG는 벡터 검색을 사용하여 입력 쿼리를 기반으로 관련 문서를 검색하여 이러한 문서를 LLM에 대한 컨텍스트로 제공함으로써 보다 정확한 응답을 생성합니다. RAG는 미리 학습된 패턴에만 의존하는 대신 최신 관련 정보를 통합하여 응답을 향상합니다. 이 방법은 다음과 같은 이점이 있습니다.
- 환각 최소화: 사실 정보에 입각하여 응답의 근거를 마련합니다.
- 현재 정보 확인: 최신 응답을 보장하기 위해 최신 데이터를 검색합니다.
- 외부 데이터베이스 활용: 개인 데이터에 대한 직접적인 액세스 권한을 부여하지는 않지만 RAG는 외부 사용자별 기술 자료와의 통합을 허용합니다.
- 토큰 사용 최적화: 가장 관련성이 높은 문서에 집중함으로써 RAG는 토큰을 더 효율적으로 사용합니다.
이 자습서에서는 Azure Cosmos DB for MongoDB(vCore)로 RAG를 구현하여 데이터에 맞춘 질문 답변 애플리케이션을 빌드하는 방법을 보여 줍니다.
애플리케이션 아키텍처 개요
아래 아키텍처 다이어그램은 RAG 구현의 주요 구성 요소를 보여 줍니다.
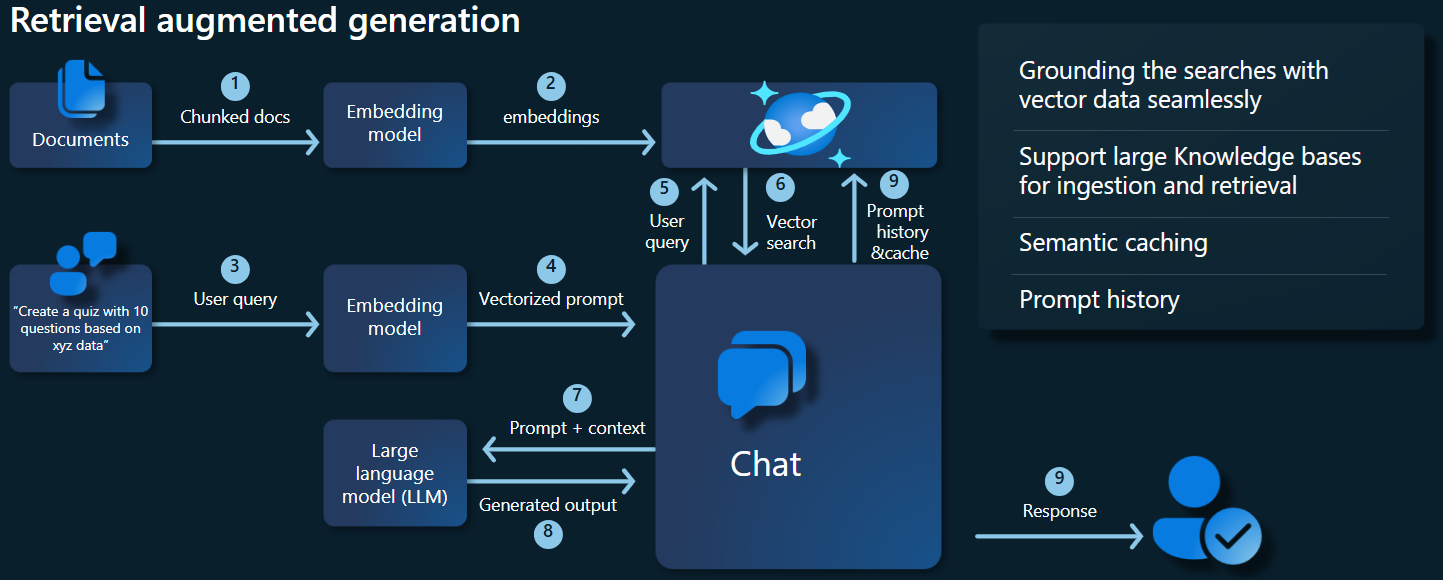
주요 구성 요소 및 프레임워크
이제 이 자습서에서 사용하는 다양한 프레임워크, 모델 및 구성 요소를 설명하고 역할과 뉘앙스를 강조합니다.
Azure Cosmos DB for MongoDB(vCore)
Azure Cosmos DB for MongoDB(vCore)는 AI 기반 애플리케이션에 필수적인 의미론적 유사성 검색 기능을 지원합니다. 다양한 형식의 데이터를 원본 데이터 및 메타데이터와 함께 저장할 수 있는 벡터 임베딩으로 나타낼 수 있습니다. HNSW(Hierarchical Navigable Small World)와 같은 최근접 이웃 검색 알고리즘을 사용하여 이러한 임베딩을 쿼리하면 의미론적 유사성을 빠르게 검색할 수 있습니다.
LangChain 프레임워크
LangChain은 체인의 표준 인터페이스, 여러 도구 통합, 일반 작업에 대한 엔드 투 엔드 체인을 제공하여 LLM 애플리케이션의 생성을 간소화합니다. 이를 통해 AI 개발자는 외부 데이터 원본을 활용하는 LLM 애플리케이션을 빌드할 수 있습니다.
LangChain의 주요 측면:
- 체인: 특정 작업을 해결하는 구성 요소의 시퀀스입니다.
- 구성 요소: LLM 래퍼, 벡터 저장소 래퍼, 프롬프트 템플릿, 데이터 로더, 텍스트 분할기, 검색기 등의 모듈입니다.
- 모듈성: 개발, 디버깅, 유지 관리를 간소화합니다.
- 인기도: 오픈 소스 프로젝트가 빠르게 채택되고 사용자 요구에 맞게 진화합니다.
Azure App Services 인터페이스
App Services는 Gen-AI 애플리케이션을 위한 사용자 친화적인 웹 인터페이스를 빌드할 강력한 플랫폼을 제공합니다. 이 자습서에서는 Azure App Services를 사용하여 애플리케이션에 맞는 대화형 웹 인터페이스를 만듭니다.
OpenAI 모델
OpenAI는 AI 연구의 선두 주자로서, 언어 생성, 텍스트 벡터화, 이미지 만들기, 오디오-텍스트 변환을 위한 다양한 모델을 제공합니다. 이 자습서에서는 언어 기반 애플리케이션을 이해하고 생성하는 데 중요한 OpenAI의 임베딩 및 언어 모델을 사용합니다.
임베딩 모델 대 언어 생성 모델
| 범주 | 텍스트 임베딩 모델 | 언어 모델 |
|---|---|---|
| 용도 | 텍스트를 벡터 임베딩으로 변환합니다. | 자연어를 이해하고 생성합니다. |
| Function | 텍스트 데이터를 고차원 숫자 배열로 변환하여 텍스트에 담긴 의미를 포착합니다. | 지정된 입력을 이해하고 이를 기반으로 인간이 쓴 듯한 텍스트를 생성합니다. |
| 출력 | 숫자 배열(벡터 임베딩). | 텍스트, 답변, 번역, 코드 등. |
| 예제 출력 | 각 임베딩은 텍스트에 담긴 의미를 숫자 형식으로 나타내며, 모델이 차원을 결정합니다. 예를 들어 text-embedding-ada-002는 1536개 차원의 벡터를 생성합니다. |
입력한 내용에 따라 생성되는 상황에 맞고 일관된 텍스트입니다. 예를 들어 gpt-3.5-turbo는 질문의 답변을 생성하고, 텍스트를 번역하고, 코드를 작성하는 등의 작업을 수행할 수 있습니다. |
| 일반적인 사용 사례 | - 의미론적 검색 | - 챗봇 |
| - 추천 시스템 | - 자동화된 콘텐츠 만들기 | |
| - 텍스트 데이터의 클러스터링 및 분류 | - 언어 번역 | |
| - 정보 검색 | - 요약 | |
| 데이터 표현 | 숫자 표현(임베딩) | 자연어 텍스트 |
| 차원 | 배열의 길이는 임베딩 공간의 차원 수(예: 1536개 차원)에 해당합니다. | 일반적으로 토큰 시퀀스로 표현되며, 상황에 맞게 길이가 결정됩니다. |
애플리케이션의 기본 구성 요소
- Azure Cosmos DB for MongoDB vCore: 벡터 임베딩을 저장하고 쿼리합니다.
- LangChain: 애플리케이션의 LLM 워크플로를 생성합니다. 다음과 같은 도구를 활용합니다.
- 문서 로더: 디렉터리에서 문서를 로드하고 처리합니다.
- 벡터 저장소 통합: Azure Cosmos DB에 벡터 임베딩을 저장하고 쿼리합니다.
- AzureCosmosDBVectorSearch: Cosmos DB 벡터 검색에 사용되는 래퍼입니다.
- Azure App Services: Cosmic Food 앱의 사용자 인터페이스를 빌드합니다.
- Azure OpenAI: 다음을 포함하는 LLM 및 임베딩 모델을 제공합니다.
- text-embedding-ada-002: 텍스트를 1536개 차원의 벡터 임베딩으로 변환하는 텍스트 임베딩 모델입니다.
- gpt-3.5-turbo: 자연어를 이해하고 생성하는 언어 모델입니다.
환경 설정
Azure Cosmos DB for MongoDB(vCore)를 사용하여 RAG(검색 증강 생성) 최적화를 시작하려면 다음 단계를 수행합니다.
- Microsoft Azure에서 다음 리소스를 만듭니다.
- Azure Cosmos DB for MongoDB vCore 클러스터: 여기에서 빠른 시작 가이드를 참조하세요.
- 다음을 사용하는 Azure OpenAI 리소스:
- 임베딩 모델 배포(예:
text-embedding-ada-002). - 채팅 모델 배포(예:
gpt-35-turbo).
- 임베딩 모델 배포(예:
샘플 문서
이 자습서에서는 문서를 사용하여 단일 텍스트 파일을 로드합니다. 이러한 파일은 src 폴더의 data라는 이름의 디렉터리에 저장되어야 합니다. 그 내용은 다음과 같습니다.
food_items.json
{
"category": "Cold Dishes",
"name": "Hamachi Fig",
"description": "Hamachi sashimi lightly tossed in a fig sauce with rum raisins, and serrano peppers then topped with fried lotus root.",
"price": "16.0 USD"
},
문서 로드
Cosmos DB for MongoDB(vCore) 연결 문자열, 데이터베이스 이름, 컬렉션 이름, 인덱스를 설정합니다.
mongo_client = MongoClient(mongo_connection_string) database_name = "Contoso" db = mongo_client[database_name] collection_name = "ContosoCollection" index_name = "ContosoIndex" collection = db[collection_name]임베딩 클라이언트를 초기화합니다.
from langchain_openai import AzureOpenAIEmbeddings openai_embeddings_model = os.getenv("AZURE_OPENAI_EMBEDDINGS_MODEL_NAME", "text-embedding-ada-002") openai_embeddings_deployment = os.getenv("AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT_NAME", "text-embedding") azure_openai_embeddings: AzureOpenAIEmbeddings = AzureOpenAIEmbeddings( model=openai_embeddings_model, azure_deployment=openai_embeddings_deployment, )데이터에서 임베딩을 만들고, 데이터베이스에 저장하고, 벡터 저장소인 Cosmos DB for MongoDB(vCore)에 대한 연결을 반환합니다.
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_documents( json_data, azure_openai_embeddings, collection=collection, index_name=index_name, )컬렉션에 다음 HNSW 벡터 인덱스를 만듭니다(인덱스의 이름은 위와 동일).
num_lists = 100 dimensions = 1536 similarity_algorithm = CosmosDBSimilarityType.COS kind = CosmosDBVectorSearchType.VECTOR_HNSW m = 16 ef_construction = 64 vector_store.create_index( num_lists, dimensions, similarity_algorithm, kind, m, ef_construction )
Cosmos DB for MongoDB(vCore)를 사용하여 벡터 검색 수행
벡터 저장소에 연결합니다.
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_connection_string( connection_string=mongo_connection_string, namespace=f"{database_name}.{collection_name}", embedding=azure_openai_embeddings, )쿼리에 Cosmos DB 벡터 검색을 사용하여 의미론적 유사성 검색을 수행하는 함수를 정의합니다(이 코드 조각은 테스트 함수).
query = "beef dishes" docs = vector_store.similarity_search(query) print(docs[0].page_content)RAG 함수를 구현하도록 채팅 클라이언트를 초기화합니다.
azure_openai_chat: AzureChatOpenAI = AzureChatOpenAI( model=openai_chat_model, azure_deployment=openai_chat_deployment, )RAG 함수를 만듭니다.
history_prompt = ChatPromptTemplate.from_messages( [ MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ( "user", """Given the above conversation, generate a search query to look up to get information relevant to the conversation""", ), ] ) context_prompt = ChatPromptTemplate.from_messages( [ ("system", "Answer the user's questions based on the below context:\n\n{context}"), MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ] )벡터 저장소를 검색기로 변환하여, 지정된 매개 변수를 기반으로 관련 문서를 검색할 수 있습니다.
vector_store_retriever = vector_store.as_retriever( search_type=search_type, search_kwargs={"k": limit, "score_threshold": score_threshold} )대화 내용을 인식하는 검색기 체인을 만들어 azure_openai_chat 모델 및 vector_store_retriever를 사용하여 상황에 맞는 관련 문서 검색을 보장합니다.
retriever_chain = create_history_aware_retriever(azure_openai_chat, vector_store_retriever, history_prompt)언어 모델(azure_openai_chat)과 지정된 프롬프트(context_prompt)를 사용하여 검색된 문서를 일관된 응답으로 결합하는 체인을 만듭니다.
context_chain = create_stuff_documents_chain(llm=azure_openai_chat, prompt=context_prompt)전체 검색 프로세스를 처리하는 체인을 만들어 내용 인식 검색기 체인과 문서 조합 체인을 통합합니다. 이 RAG 체인을 실행하여 상황에 맞는 정확한 응답을 검색하고 생성합니다.
rag_chain: Runnable = create_retrieval_chain( retriever=retriever_chain, combine_docs_chain=context_chain, )
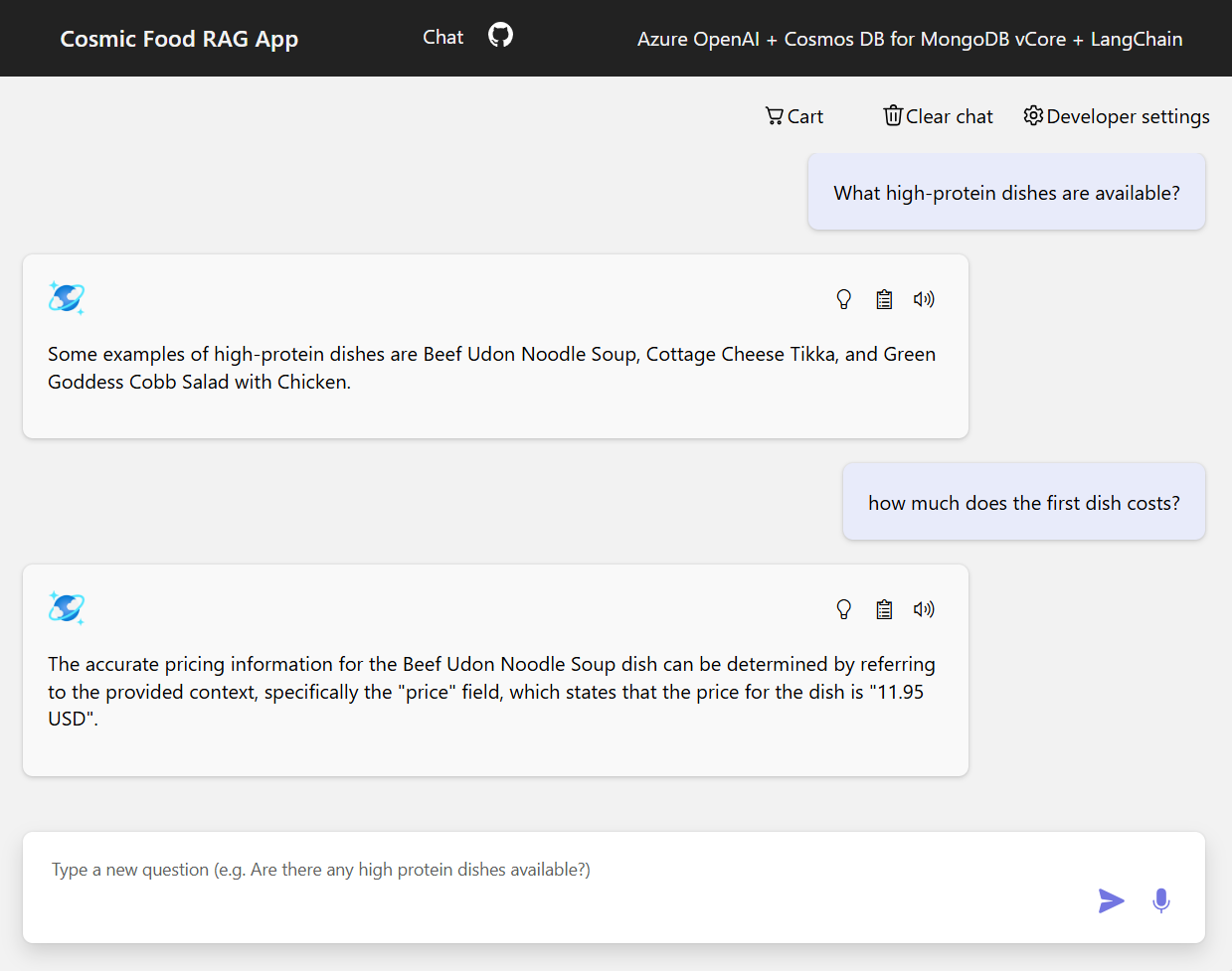
샘플 출력
아래 스크린샷은 다양한 질문에 대한 출력 내용을 보여 줍니다. 순수한 의미론적 유사성 검색은 원본 문서의 원시 텍스트를 반환하는 반면 RAG 아키텍처를 사용하는 질문 답변 앱은 검색된 문서 콘텐츠를 언어 모델과 결합하여 정확하고 개인화된 답변을 생성합니다.
결론
이 자습서에서 Cosmos DB를 벡터 저장소로 사용하여 개인 데이터와 상호 작용gkf 질문 답변 앱을 빌드하는 방법을 알아보았습니다. LangChain과 Azure OpenAI과 함께 RAG(검색 증강 생성) 아키텍처를 활용하여 LLM 애플리케이션에 벡터 저장소가 얼마나 중요한지 설명했습니다.
RAG는 특히 자연어 처리 분야에서 상당히 발전한 AI 기술로, 이러한 기술을 결합하면 다양한 사용 사례에 맞는 강력한 AI 기반 애플리케이션을 만들 수 있습니다.