AI/ML 도메인 기반 기능 엔지니어링을 위한 데이터 메시 운영
데이터 메시를 사용하면 조직에서 중앙 집중식 데이터 레이크 또는 데이터 웨어하우스에서 도메인 소유권, 제품으로서의 데이터, 셀프 서비스 데이터 플랫폼 및 페더레이션된 계산 거버넌스의 네 가지 원칙에 따라 강조 표시된 분석 데이터의 도메인 기반 분산으로 이동할 수 있습니다. 데이터 메시 분산 데이터 소유권의 이점과 조직의 비즈니스 및 가치 창출 시간을 가속화하는 향상된 데이터 품질 및 거버넌스를 제공합니다.
데이터 메시 구현
일반적인 데이터 메시 구현에는 데이터 파이프라인을 빌드하는 데이터 엔지니어가 있는 도메인 팀이 포함됩니다. 팀은 데이터 레이크, 데이터 웨어하우스 또는 데이터 레이크하우스와 같은 운영 및 분석 데이터 저장소를 유지 관리합니다. 그들은 파이프라인을 다른 도메인 팀이나 데이터 과학 팀이 사용할 수 있는 데이터 제품으로 릴리스합니다. 다른 팀은 다음 다이어그램과 같이 중앙 데이터 거버넌스 플랫폼을 사용하여 데이터 제품을 사용합니다.
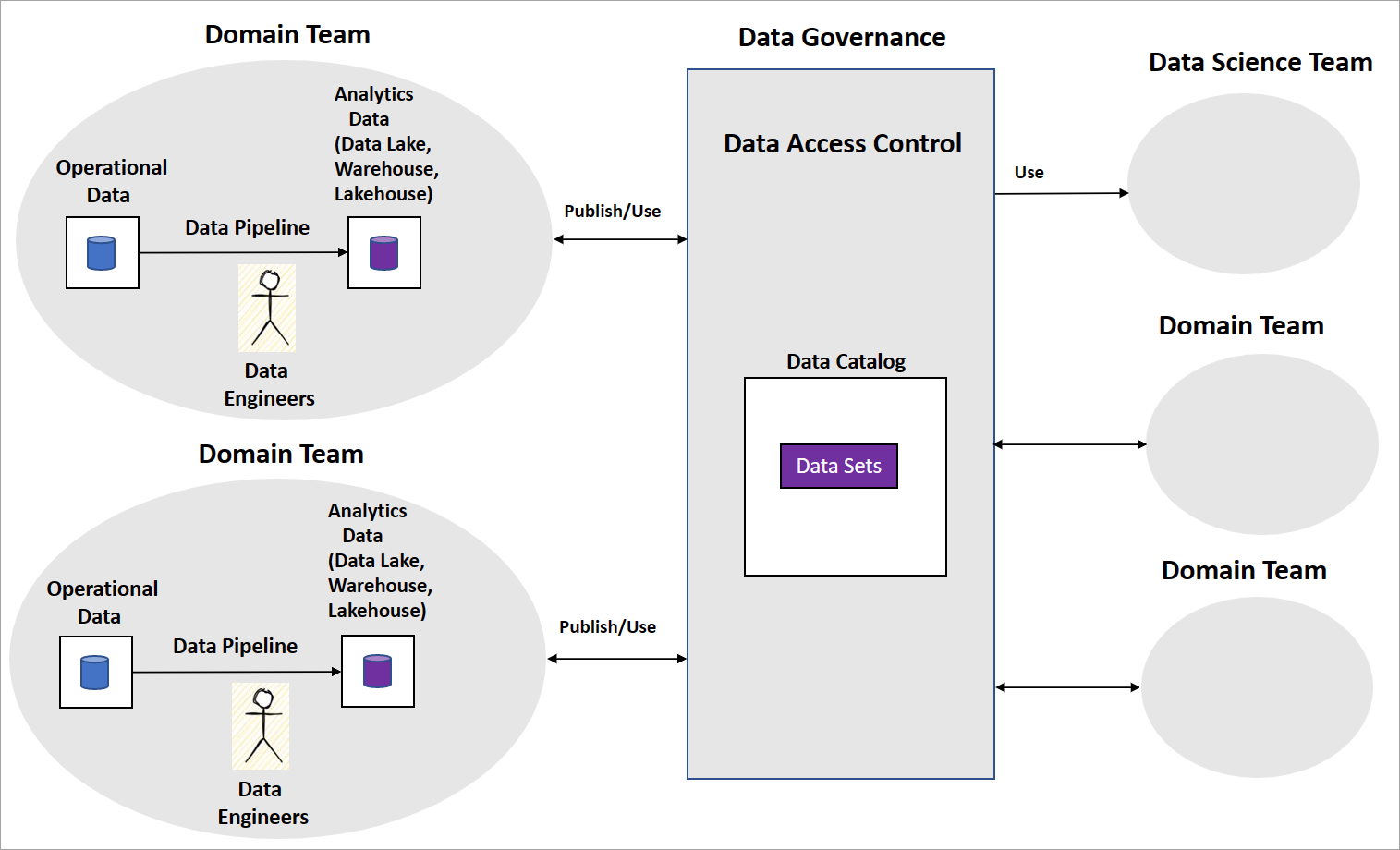
데이터 메시는 데이터 제품이 비즈니스 인텔리전스를 위해 변환되고 집계된 데이터 집합을 제공하는 방법을 명확하게 설명합니다. 그러나 조직이 AI/ML 모델을 빌드하기 위해 취해야 하는 접근 방식에 대해서는 명시적이지 않습니다. 또한 데이터 과학 팀을 구성하는 방법, AI/ML 모델 거버넌스 및 도메인 팀 간에 AI/ML 모델 또는 기능을 공유하는 방법에 대한 지침도 없습니다.
다음 섹션에서는 조직에서 데이터 메시 내에서 AI/ML 기능을 개발하는 데 사용할 수 있는 몇 가지 전략을 간략하게 설명합니다. 또한 도메인 기반 기능 엔지니어링 또는 기능 메시에 대한 전략에 대한 제안이 표시됩니다.
데이터 메시를 위한 AI/ML 전략 방안
한 가지 일반적인 전략은 조직이 데이터 과학 팀을 데이터 소비자로 채택하는 것입니다. 이러한 팀은 사용 사례에 따라 데이터 메시의 다양한 도메인 데이터 제품에 액세스합니다. 데이터 탐색 및 기능 엔지니어링을 수행하여 AI/ML 모델을 개발하고 빌드합니다. 경우에 따라 도메인 팀은 데이터 및 다른 팀의 데이터 제품을 사용하여 자체 AI/ML 모델을 개발하여 새로운 기능을 확장하고 파생합니다.
기능 엔지니어링 모델 빌드의 핵심이며 일반적으로 복잡하고 도메인 전문 지식이 필요합니다. 데이터 과학 팀은 다양한 데이터 제품을 분석해야 하므로 이 전략은 시간이 많이 걸릴 수 있습니다. 고품질 기능을 빌드하기 위한 완전한 도메인 지식이 없을 수도 있습니다. 도메인 지식이 부족하면 도메인 팀 간에 중복된 기능 엔지니어링 작업이 발생할 수 있습니다. 또한 팀 전체에서 일관되지 않은 기능 집합으로 인한 AI/ML 모델 재현 가능성과 같은 문제도 있습니다. 데이터 과학 또는 도메인 팀은 새 버전의 데이터 제품이 릴리스될 때 지속적으로 기능을 새로 고쳐야 합니다.
또 다른 전략은 도메인 팀이 ONNX(Open Neural Network Exchange)와 같은 형식으로 AI/ML 모델을 릴리스하는 것이지만, 이러한 결과는 블랙박스이며 도메인 간에 AI/ML 모델 또는 기능을 결합하는 것은 어려울 것입니다.
도메인 및 데이터 과학 팀에서 AI/ML 모델 빌드를 분산하여 문제를 해결할 수 있는 방법이 있나요? 제안된 도메인 기반 기능 엔지니어링 또는 기능 메시 전략은 옵션입니다.
도메인 기반 기능 엔지니어링 또는 기능 메시
도메인 기반 기능 엔지니어링 또는 기능 메시 전략은 데이터 메시 설정에서 AI/ML 모델 빌드에 대한 분산된 접근 방식을 제공합니다. 다음 다이어그램에서는 전략과 데이터 메시의 네 가지 주요 원칙을 해결하는 방법을 보여 줍니다.
도메인 기반 기능 엔지니어링 및 기능 메시 전략을 보여 주는 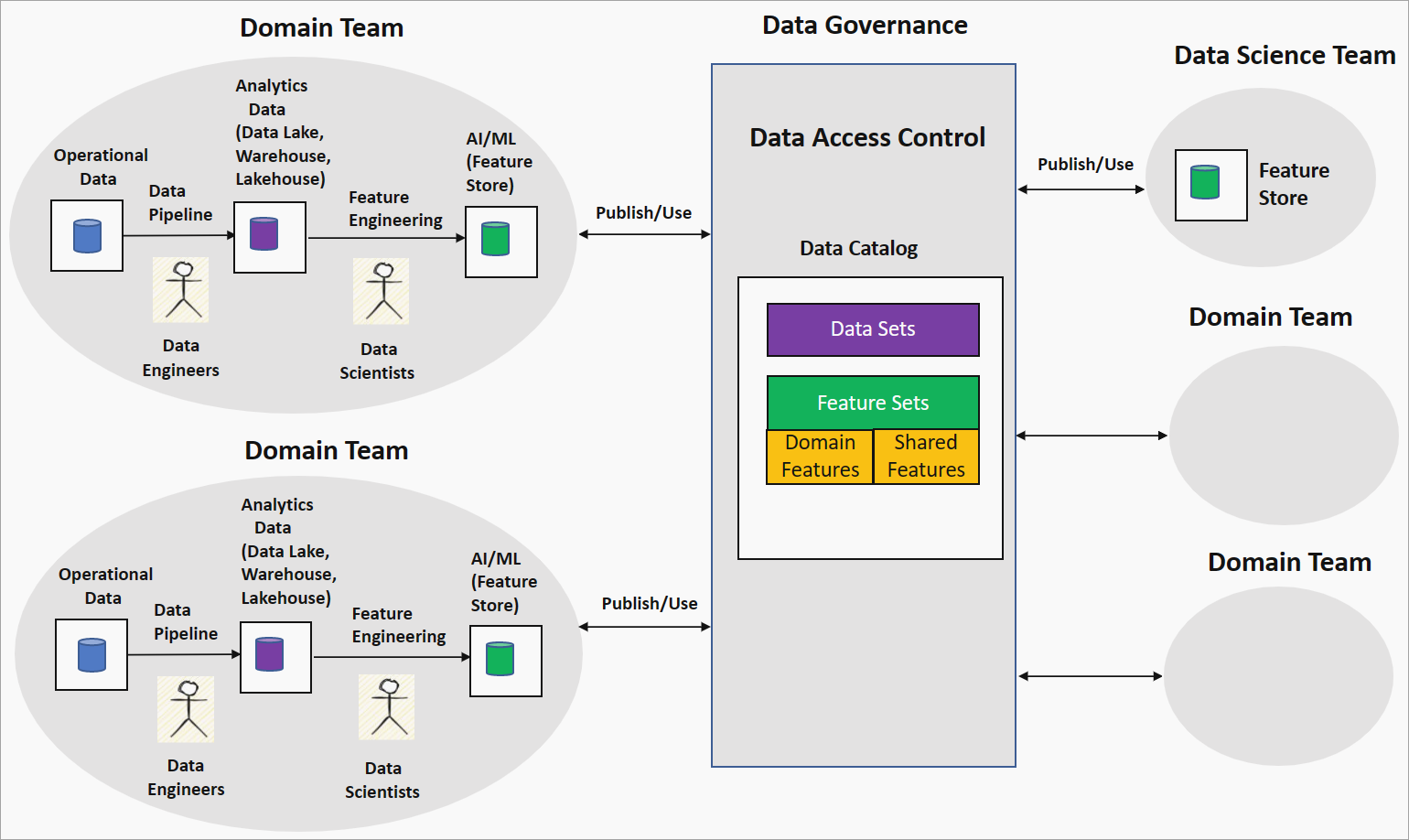
도메인 팀에 의한 도메인 소유권 기능 설계
이 전략에서 조직은 데이터 과학자를 도메인 팀의 데이터 엔지니어와 연결하여 데이터 레이크와 같이 정리되고 변환된 데이터에 대한 데이터 탐색을 실행합니다. 엔지니어링은 기능 저장소에 저장하는 기능을 생성합니다. 기능 저장소는 학습 및 유추를 위한 기능을 제공하고 기능 버전, 메타데이터 및 통계를 추적하는 데 도움이 되는 데이터 리포지토리입니다. 이 기능을 사용하면 도메인 팀의 데이터 과학자가 도메인 전문가와 긴밀히 협력하고 도메인의 데이터가 변경될 때 기능을 새로 고칠 수 있습니다.
제품으로서의 데이터: 기능 집합
도메인 또는 로컬 기능이라고 하는 도메인 팀에서 생성한 기능은 데이터 거버넌스 플랫폼의 데이터 카탈로그에 기능 집합으로 게시됩니다. 이러한 기능 집합은 AI/ML 모델을 빌드하기 위해 데이터 과학 팀 또는 다른 도메인 팀에서 사용합니다. AI/ML 모델 개발 중에 데이터 과학 또는 도메인 팀은 도메인 기능을 결합하여 공유 또는 글로벌 기능이라는 새로운 기능을 생성할 수 있습니다. 이러한 공유 기능은 사용할 기능 집합 카탈로그에 다시 게시됩니다.
셀프 서비스 데이터 플랫폼 및 페더레이션된 계산 거버넌스: 기능 표준화 및 품질
이 전략을 통해 기능 엔지니어링 파이프라인에 대해 다른 기술 스택을 채택하고 도메인 팀 간에 일관되지 않은 기능 정의를 채택할 수 있습니다. 셀프 서비스 데이터 플랫폼 원칙은 도메인 팀이 공통 인프라 및 도구를 사용하여 기능 엔지니어링 파이프라인을 빌드하고 액세스 제어를 적용하도록 합니다. 페더레이션된 계산 거버넌스 원칙은 글로벌 표준화를 통해 기능 집합의 상호 운용성을 보장하고 기능 품질을 확인합니다.
도메인 기반 기능 엔지니어링 또는 기능 메시 전략을 사용하면 조직에서 AI/ML 모델 개발 시간을 줄이는 데 도움이 되는 탈중앙화된 AI/ML 모델 빌드 접근 방식을 제공합니다. 이 전략은 도메인 팀 전체에서 기능을 일관되게 유지하는 데 도움이 됩니다. 이 기능은 노력의 중복을 방지하고 더 정확한 AI/ML 모델을 위한 고품질 기능을 생성하여 비즈니스 가치를 높입니다.
Azure의 데이터 메시 구현
이 문서에서는 데이터 메시에서 AI/ML을 조작하는 개념에 대해 설명하고 이러한 전략을 빌드하기 위한 도구 또는 아키텍처를 다루지 않습니다. Azure에는 Azure Databricks 기능 저장소와 LinkedIn의 Feathr 같은 기능 저장소 제품이 있습니다. Microsoft Purview 사용자 지정 커넥터를