Azure VM에서 SAP HANA 데이터베이스 복원
이 문서에서는 Azure VM(가상 머신)에서 실행되는 SAP HANA 데이터베이스와 Azure Backup 서비스에서 Recovery Services 자격 증명 모음에 백업한 SAP HANA 데이터베이스를 복원하는 방법을 설명합니다. 복원된 데이터를 사용하여 개발 및 테스트 시나리오를 위한 데이터 복사본을 만들거나 이전 상태로 되돌릴 수 있습니다.
이제 Azure Backup은 SAP HSR(HANA 시스템 복제) 인스턴스의 백업 및 복원을 지원합니다.
참고 항목
- HSR을 사용하는 HANA 데이터베이스의 복원 프로세스는 HSR을 사용하지 않는 HANA 데이터베이스의 복원 프로세스와 동일합니다. SAP 권고에 따라 HSR 모드를 사용하여 데이터베이스를 독립형 데이터베이스로 복원할 수 있습니다. 대상 시스템에서 HSR 모드가 사용하도록 설정된 경우 이 모드를 사용하지 않도록 설정한 다음, 데이터베이스를 복원합니다. 그러나 파일로 복원하는 경우 HSR 모드를 사용하지 않도록 설정(HSR 중단)할 필요가 없습니다.
- OLR(원래 위치 복구)은 현재 HSR에서 지원되지 않습니다. 또는 대체 위치 복원을 선택한 다음, 목록에서 원본 VM을 호스트로 선택합니다.
- HSR 인스턴스로 복원은 지원되지 않습니다. 그러나 HANA 인스턴스로 복원만 지원됩니다.
지원되는 구성 및 시나리오에 대한 내용은 SAP HANA 백업 지원 매트릭스를 참조하세요.
특정 시점 또는 복구 지점으로 복원
Azure Backup은 Azure VM에서 실행되는 SAP HANA 데이터베이스를 복원합니다. 다음과 같은 기능이 있습니다.
로그 백업을 사용하여 특정 날짜 또는 시간(초)으로 복원합니다. Azure Backup은 선택한 시간을 기준으로 복원해야 하는 적절한 전체 백업, 차등 백업 및 로그 백업 체인을 자동으로 결정합니다.
특정 복구 지점으로 복원하려면 특정 전체 또는 차등 백업으로 복원합니다.
필수 조건
데이터베이스 복원을 시작하기 전에 다음 사항에 유의하세요.
동일한 지역에 있는 SAP HANA 인스턴스로만 데이터베이스를 복원할 수 있습니다.
대상 인스턴스를 원본과 동일한 자격 증명 모음에 등록해야 합니다. SAP HANA 데이터베이스 백업에 대해 자세히 알아보세요.
Azure Backup은 동일한 VM에 있는 두 개의 서로 다른 SAP HANA 인스턴스를 구분할 수 없습니다. 따라서 한 인스턴스의 데이터를 동일한 VM의 다른 인스턴스에 복원하는 것은 불가능합니다.
대상 SAP HANA 인스턴스를 복원할 준비가 되었는지 확인하려면 해당 백업 준비 상태를 확인합니다.
Azure Portal에서 백업 센터로 이동한 다음, 백업을 선택합니다.
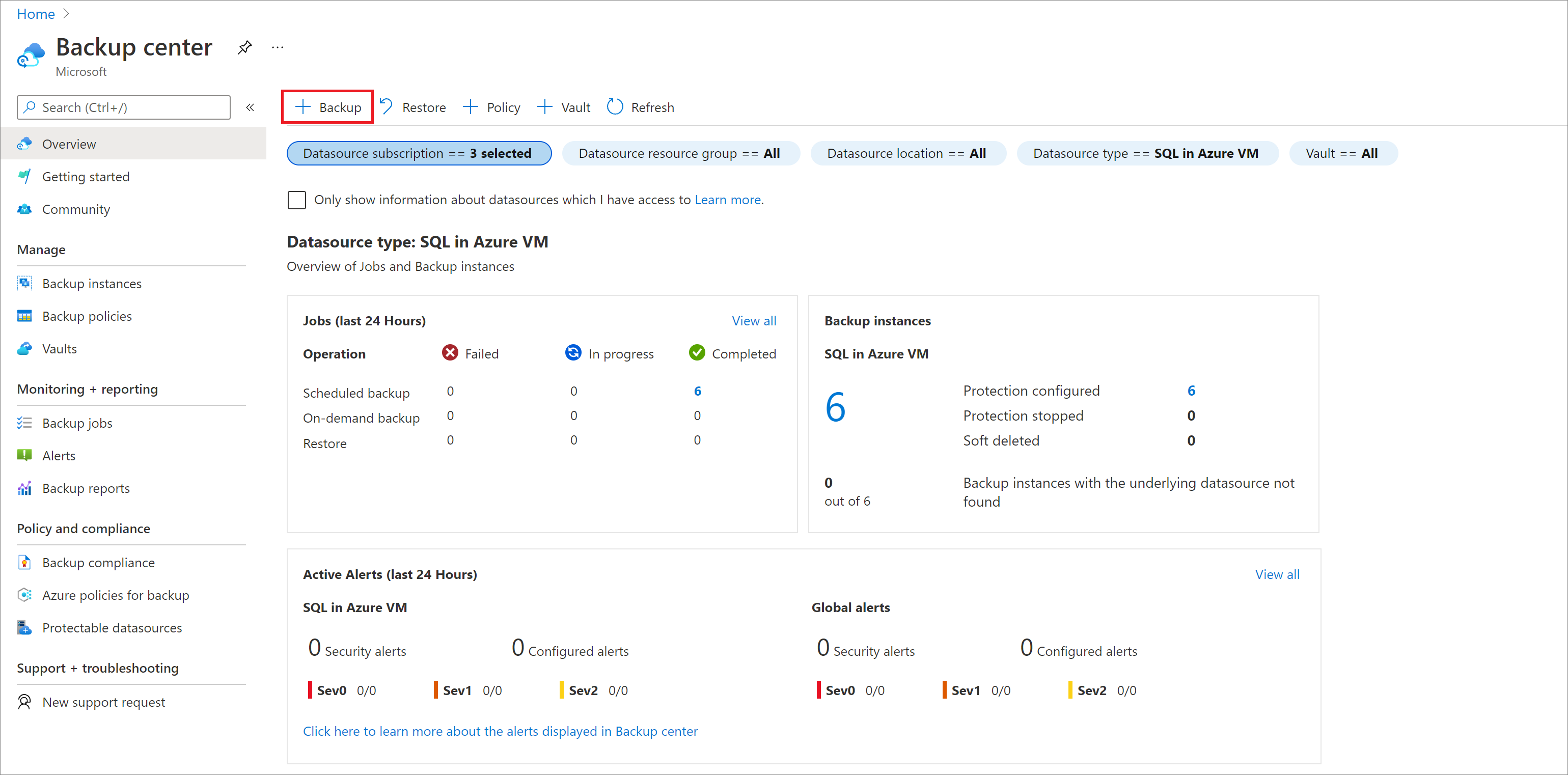
시작: 백업 구성 창에서 데이터 원본 유형으로 Azure VM의 SAP HANA를 선택하고 SAP HANA 인스턴스가 등록된 자격 증명 모음을 선택한 다음, 계속을 선택합니다.
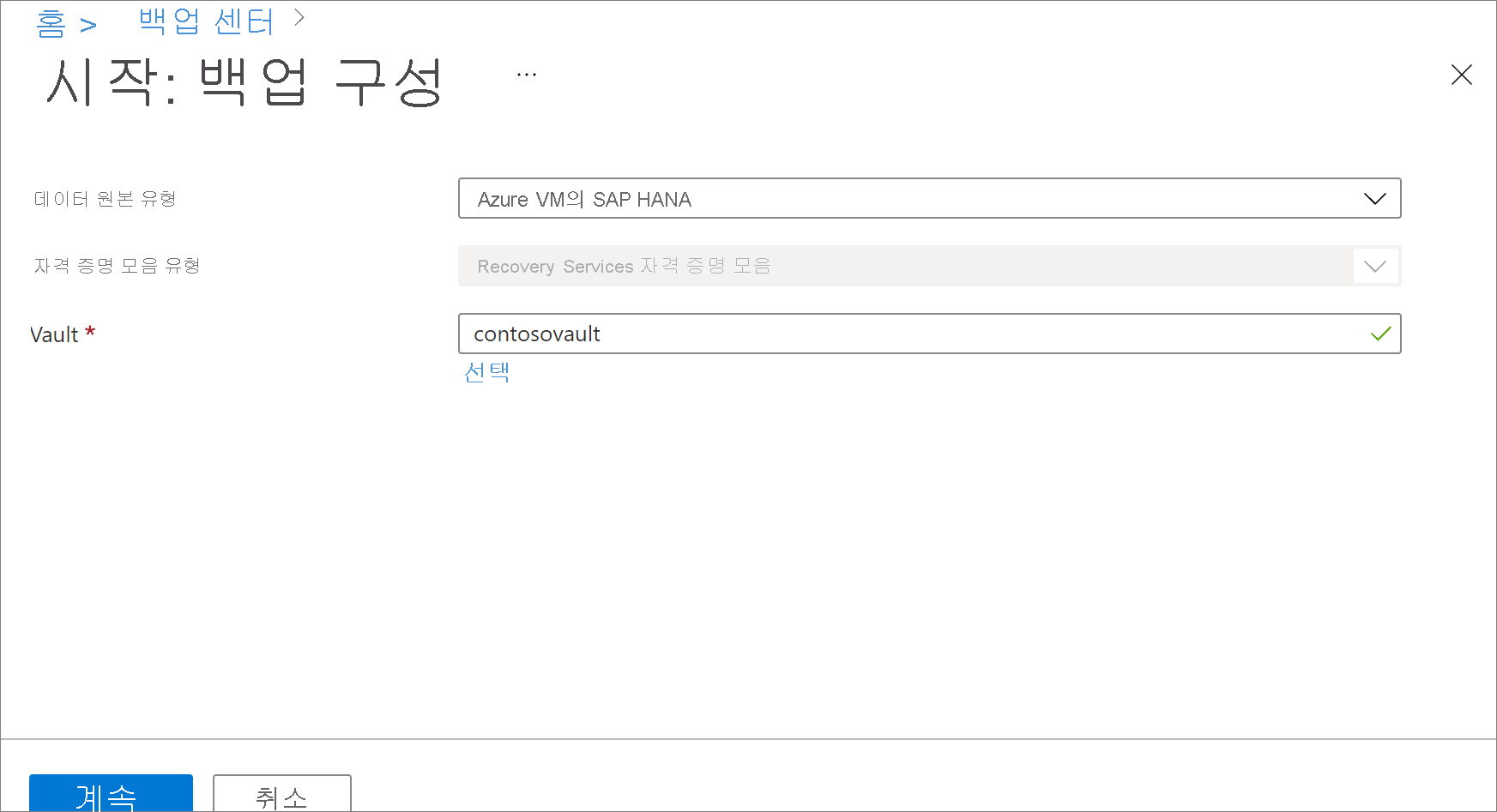
VM에서 DB 검색 아래에서 자세히 보기를 선택합니다.
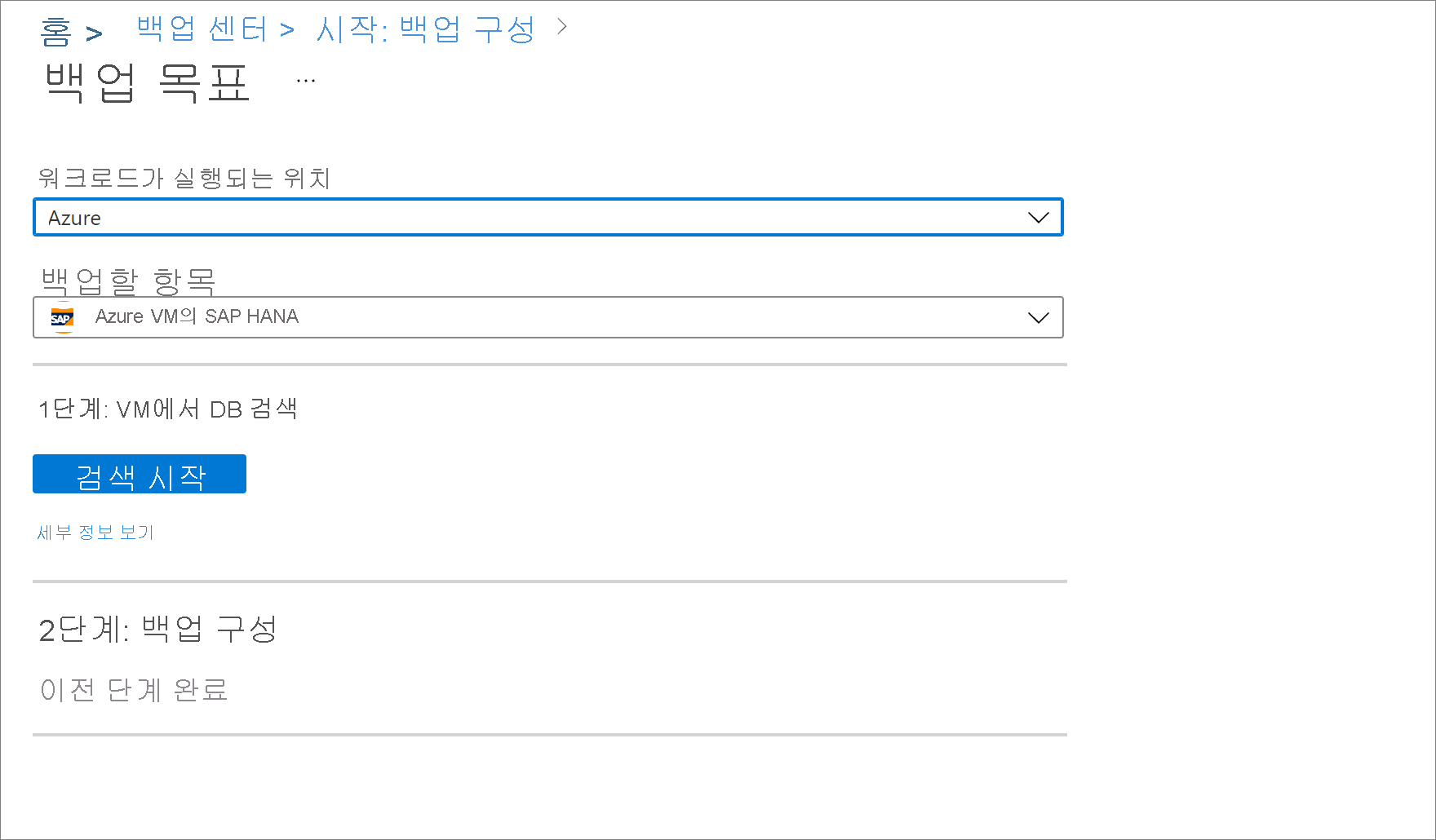
대상 VM의 백업 준비 상태를 검토합니다.
SAP HANA가 지원하는 복원 유형에 대한 자세한 내용은 SAP HANA Note 1642148을 참조하세요.


데이터베이스 복원
데이터베이스를 복원하려면 다음 권한이 필요합니다.
- 백업 운영자: 복원하려는 자격 증명 모음의 권한을 제공합니다.
- 기여자(쓰기): 백업된 원본 VM에 대한 액세스 권한을 제공합니다.
- 기여자(쓰기): 대상 VM에 대한 액세스 권한을 제공합니다.
- 동일한 VM으로 복원하는 경우 원본 VM입니다.
- 대체 위치로 복원하는 경우 새 대상 VM입니다.
Azure Portal에서 백업 센터로 이동한 다음, 복원을 선택합니다.
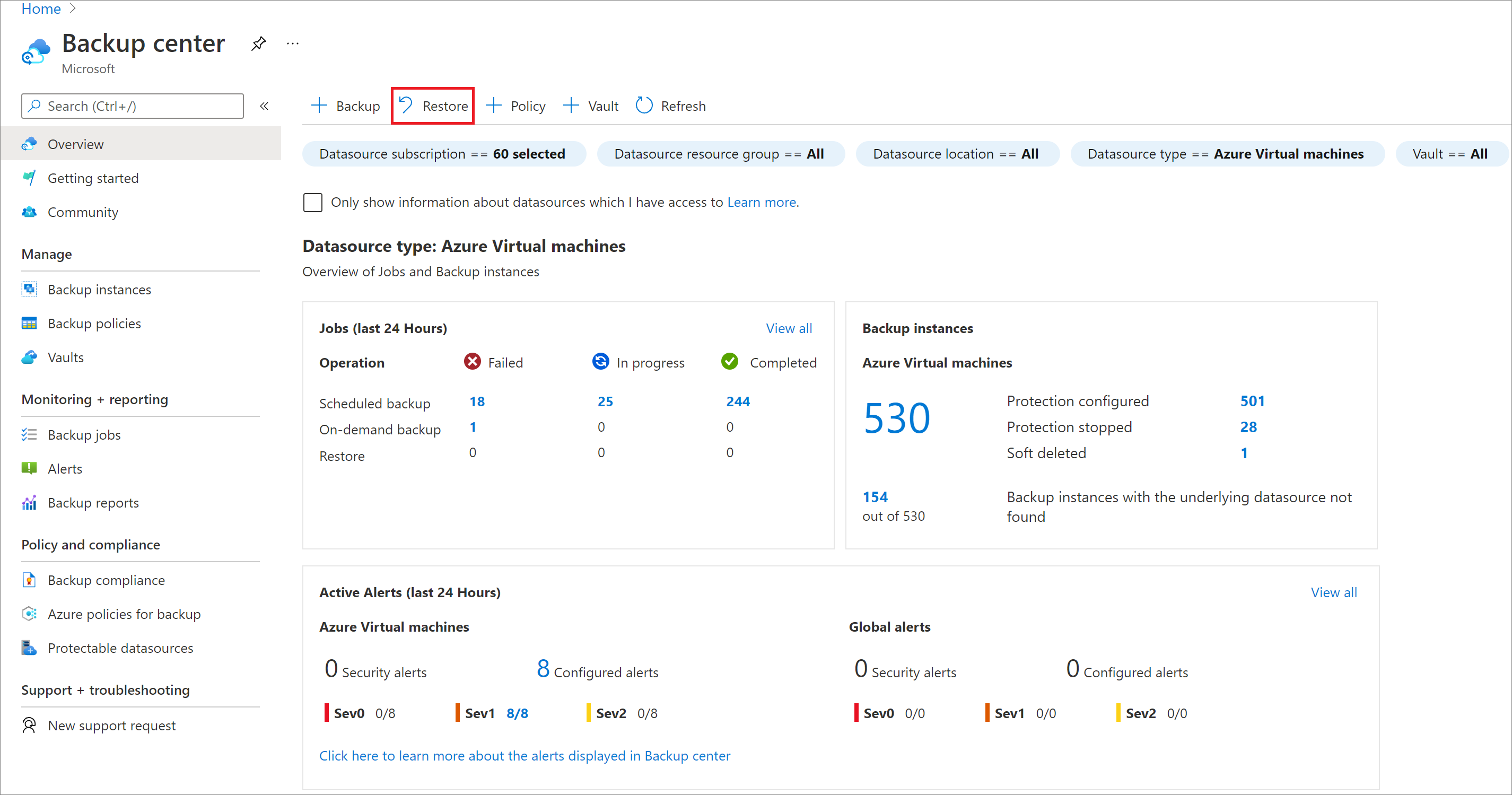
데이터 원본 유형으로 Azure VM의 SAP HANA를 선택하고 복원할 데이터베이스를 선택한 다음, 계속을 선택합니다.
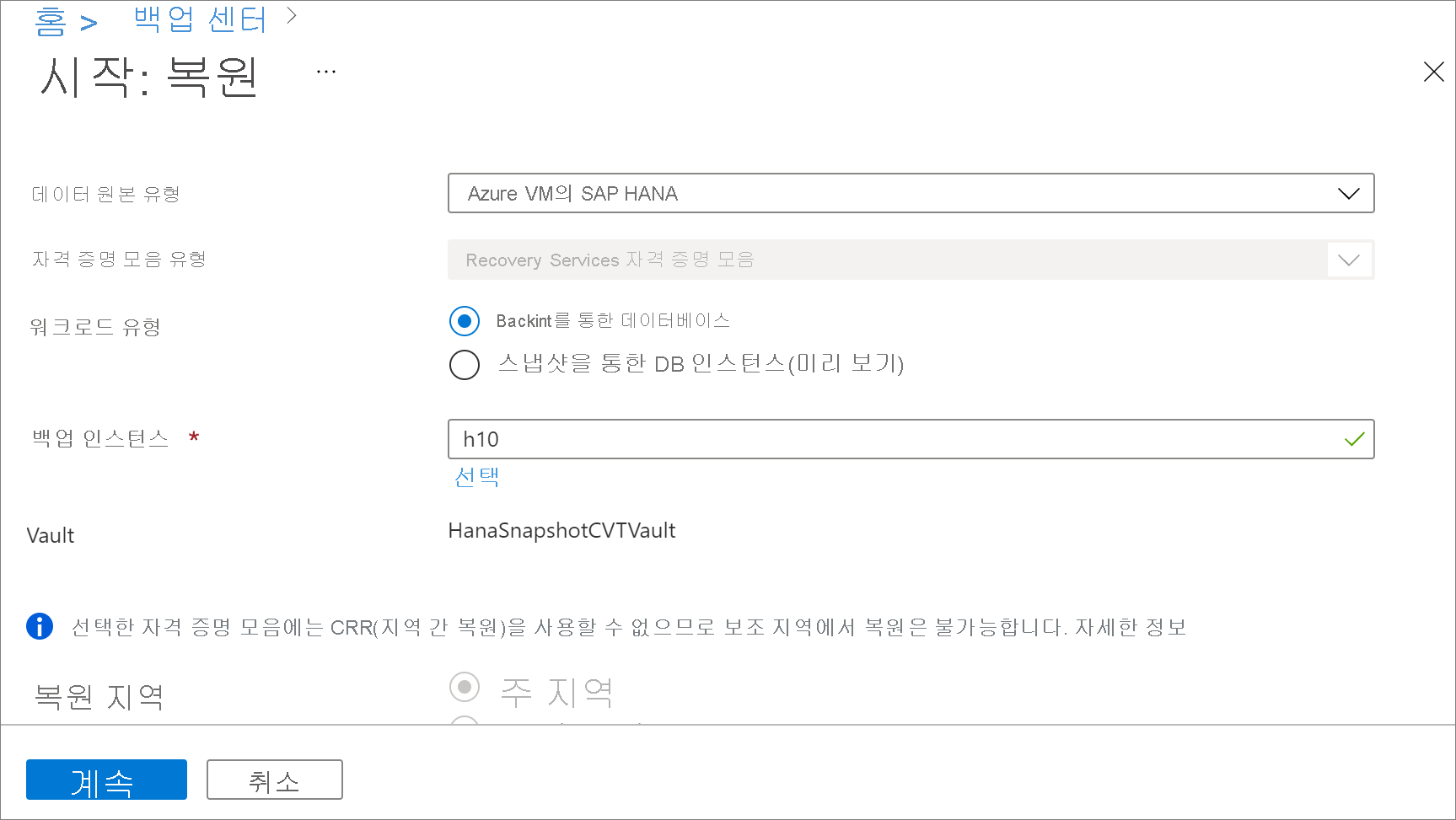
복원 구성에서 데이터를 복원하는 위치 또는 방법을 지정합니다.
- 대체 위치: 대체 위치에 데이터베이스를 복원하고 원래 원본 데이터베이스를 유지합니다.
- DB 덮어쓰기: 원래 원본과 동일한 SAP HANA 인스턴스에 데이터를 복원합니다. 이 옵션은 원래 데이터베이스를 덮어씁니다.

참고 항목
복원하는 동안(가상 IP/부하 분산 장치 프런트 엔드 IP 시나리오에만 적용됨) SAP에서 권장하는 대로 복원하기 전에 HSR 모드를 독립 실행형으로 변경하거나 HSR을 중단한 후 대상 노드로 백업을 복원하려는 경우 Load Balancer가 대상 노드를 가리키는지 확인합니다.
예제 시나리오:
- 사전 등록 스크립트에서 hdbuserstore set SYSTEMKEY localhost를 사용하는 경우 복원 중에 문제가 발생하지 않습니다.
- *hdbuserstore가 사전 등록 스크립트에서
SYSTEMKEY <load balancer host/ip>를 설정했고 백업을 대상 노드로 복원하려는 경우 부하 분산 장치가 복원해야 하는 대상 노드를 가리키는지 확인합니다.
대체 위치에 복원
복원 창의 복원 위치 및 방법에서 대체 위치를 선택합니다.
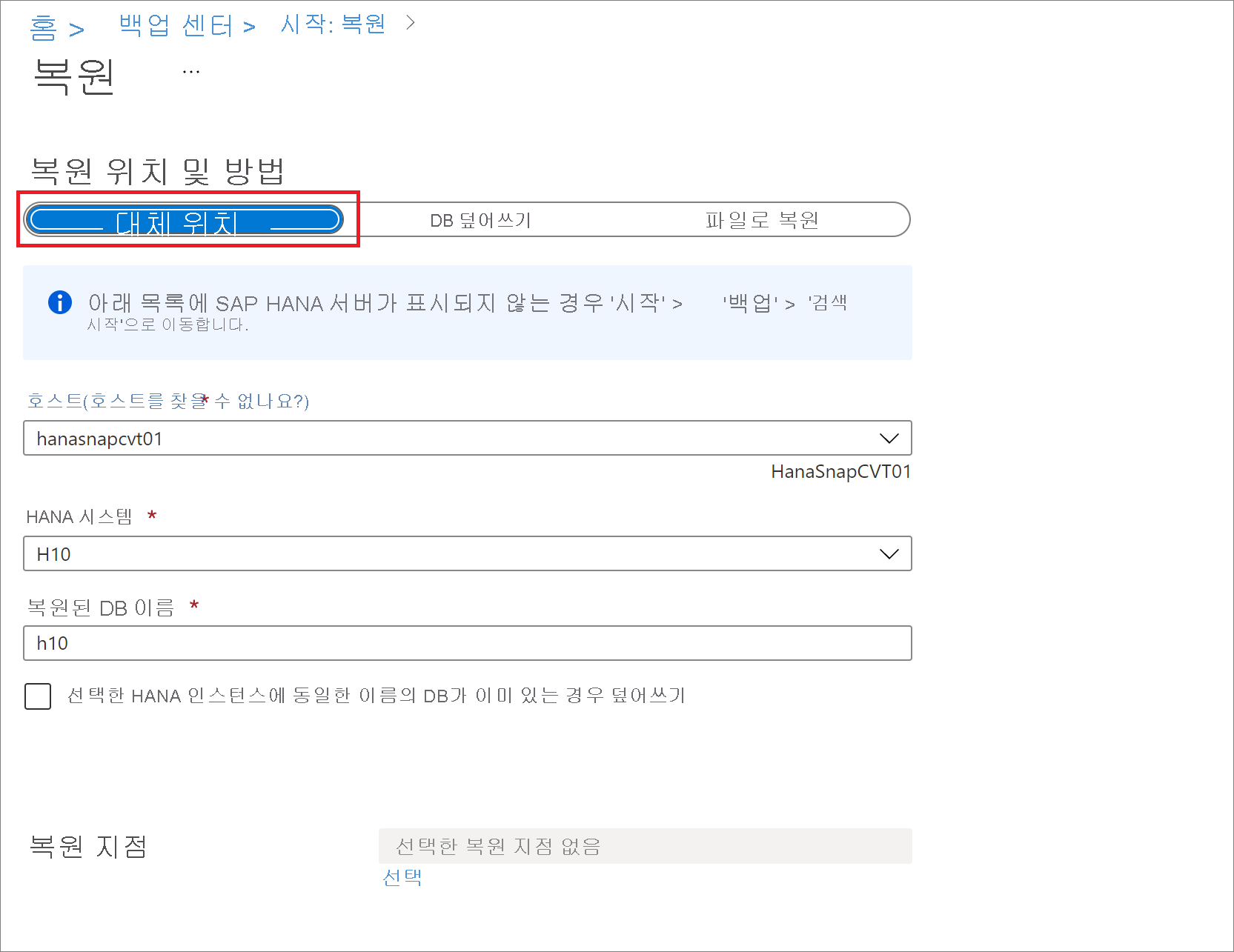
데이터베이스를 복원할 SAP HANA 호스트 이름 및 인스턴스 이름을 선택합니다.
대상 SAP HANA 인스턴스의 백업 준비 상태를 확인하여 복원할 준비가 되었는지 확인합니다. 자세한 내용은 필수 구성 요소를 참조하세요.
복원된 DB 이름 상자에 대상 데이터베이스의 이름을 입력합니다.
참고 항목
SDC(Single Database Container) 복원은 다음 검사를 수행해야 합니다.
해당되는 경우 선택한 HANA 인스턴스에 이름이 같은 DB가 있으면 덮어쓰기 확인란을 선택합니다.
복원 지점 선택에서 로그(특정 시점 복원)을 선택하여 특정 시점으로 복원합니다. 또는 전체 및 차등을 선택하여 특정 복구 지점으로 복원합니다.
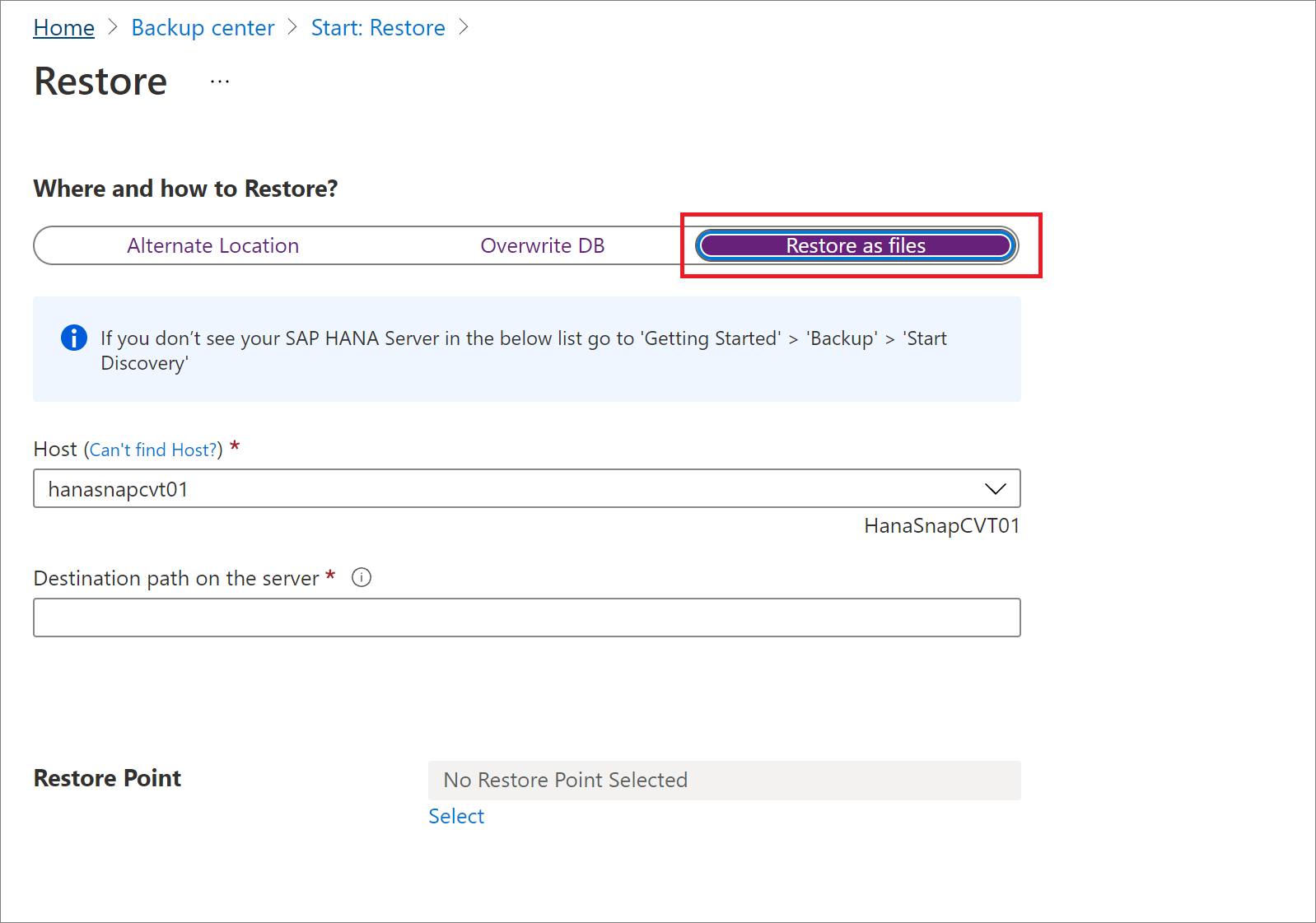
파일로 복원
참고 항목
파일로 복원은 CIFS(Common Internet File System) 공유에서 작동하지 않지만 NFS(네트워크 파일 시스템)에서는 작동합니다.
백업 데이터를 데이터베이스가 아닌 파일로 복원하려면 파일로 복원을 선택합니다. 파일이 지정된 경로에 덤프되면 파일을 데이터베이스로 복원하려는 SAP HANA 머신으로 가져올 수 있습니다. 파일을 임의의 머신으로 이동할 수 있으므로 이제 구독 및 지역 간에 데이터를 복원할 수 있습니다.
복원 창의 복원 위치 및 방법에서 파일로 복원을 선택합니다.
백업 파일을 복원할 호스트 또는 HANA 서버 이름을 선택합니다.
서버의 대상 경로 상자에 이전 단계에서 선택한 서버의 폴더 경로를 입력합니다. 서비스에서 필요한 모든 백업 파일을 덤프하는 위치입니다.
덤프되는 파일은 다음과 같습니다.
- 데이터베이스 백업 파일
- JSON 메타데이터 파일(관련된 각 백업 파일)
일반적으로 네트워크 공유 경로 또는 탑재된 Azure 파일 공유 경로가 대상 경로로 지정되면 동일한 네트워크의 다른 머신 또는 동일한 Azure 파일 공유가 탑재된 다른 머신에서 이러한 파일에 더 쉽게 액세스할 수 있습니다.
참고 항목
등록된 대상 VM에 탑재된 Azure 파일 공유에서 데이터베이스 백업 파일을 복원하려면 루트 계정에 공유에 대한 읽기/쓰기 권한이 있어야 합니다.
모든 백업 파일 및 폴더를 복원할 복원 지점을 선택합니다.
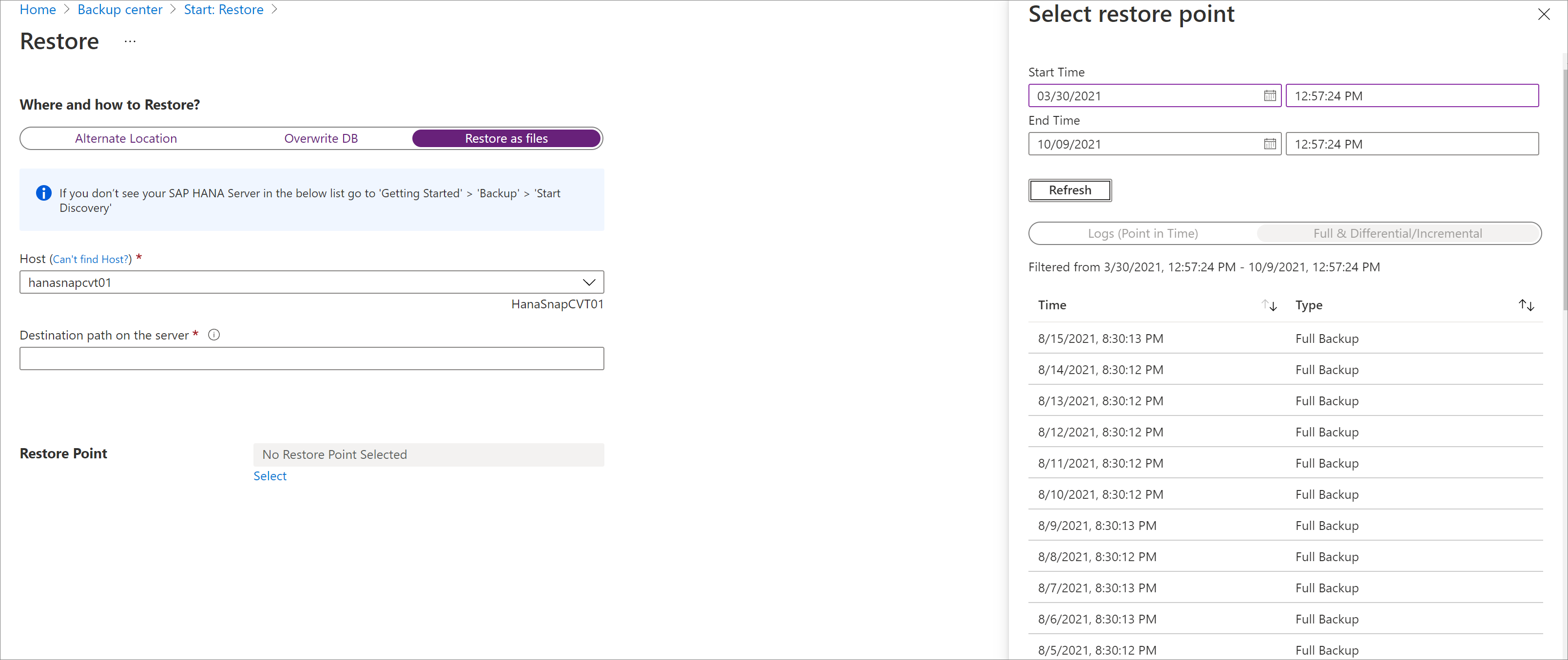
선택한 복원 지점과 연결된 모든 백업 파일은 대상 경로로 덤프됩니다.
선택한 복원 지점 유형(특정 시점 또는 전체 및 차등)에 따라 대상 경로에 하나 이상의 폴더가 만들어집니다. Data_<date and time of restore>라는 폴더에는 전체 백업이 포함되고, Log라는 폴더에는 로그 백업 및 기타 백업(예: 차등 및 증분)이 포함됩니다.
참고 항목
특정 시점으로 복원을 선택한 경우 대상 VM에 덤프된 로그 파일에는 복원을 위해 선택한 특정 시점 이외의 로그가 가끔 포함될 수 있습니다. Azure Backup은 모든 HANA 서비스에 대한 로그 백업을 사용하여 선택한 특정 시점으로 일관적이면서도 성공적으로 복원할 수 있도록 이 작업을 수행합니다.
복원된 파일을 데이터베이스로 복원하려는 SAP HANA 서버로 이동하고, 다음을 수행합니다.
a. 다음 명령을 실행하여 백업 파일이 저장되는 폴더 또는 디렉터리에 대한 권한을 설정합니다.
chown -R <SID>adm:sapsys <directory>b. 다음 명령 세트를
<SID>adm으로 실행합니다.su: <sid>admc. 복원에 사용할 카탈로그 파일을 생성합니다. 전체 백업에 대한 JSON 메타데이터 파일에서 BackupId를 추출합니다. 나중에 복원 작업에서 사용됩니다. 전체 및 로그 백업(전체 백업 복구를 위한 것이 아님)이 서로 다른 폴더에 있는지 확인하고, 이러한 폴더에서 JSON 메타데이터 파일을 삭제합니다. 다음을 실행합니다.
hdbbackupdiag --generate --dataDir <DataFileDir> --logDirs <LogFilesDir> -d <PathToPlaceCatalogFile><DataFileDir>: 전체 백업을 포함하는 폴더입니다.<LogFilesDir>: 로그 백업, 차등 및 증분 백업을 포함하는 폴더입니다. 전체 백업 복원의 경우 로그 폴더가 만들어지지 않으므로 빈 디렉터리를 추가합니다.<PathToPlaceCatalogFile>: 생성된 카탈로그 파일을 배치해야 하는 폴더입니다.
d. HANA Studio를 통해 새로 생성된 카탈로그 파일을 사용하여 복원하거나, 새로 생성된 카탈로그를 사용하여 SAP HANA HDBSQL 도구 복원 쿼리를 실행할 수 있습니다. HDBSQL 쿼리는 다음과 같습니다.
HDBSQL 프롬프트를 열려면 다음 명령을 실행합니다.
hdbsql -U AZUREWLBACKUPHANAUSER -d systemDB특정 시점으로 복원하려면 다음을 수행합니다.
복원된 새 데이터베이스를 만드는 경우 HDBSQL 명령을 실행하여 새
<DatabaseName>데이터베이스를 만든 다음,ALTER SYSTEM STOP DATABASE <db> IMMEDIATE명령을 사용하여 복원에 사용할 데이터베이스를 중지합니다. 그러나 기존 데이터베이스만 복원하는 경우 HDBSQL 명령을 실행하여 데이터베이스를 중지합니다.그런 다음, 다음 명령을 실행하여 데이터베이스를 복원합니다.
RECOVER DATABASE FOR <db> UNTIL TIMESTAMP <t1> USING CATALOG PATH <path> USING LOG PATH <path> USING DATA PATH <path> USING BACKUP_ID <bkId> CHECK ACCESS USING FILE<DatabaseName>: 복원하려는 새 데이터베이스 또는 기존 데이터베이스의 이름입니다.<Timestamp>: 특정 시점 복원에 대한 정확한 타임스탬프입니다.<DatabaseName@HostName>: 백업이 복원에 사용되는 데이터베이스의 이름과 이 데이터베이스가 있는 호스트 또는 SAP HANA 서버 이름입니다.USING SOURCE <DatabaseName@HostName>옵션은 데이터 백업(복원에 사용됨)이 대상 SAP HANA 컴퓨터와 다른 SID 또는 이름을 사용하는 데이터베이스임을 지정합니다. 백업이 수행된 HANA 서버에서 이루어지는 복원에 대해서는 지정할 필요가 없습니다.<PathToGeneratedCatalogInStep3>: "C단계"에서 생성된 카탈로그 파일의 경로입니다.<DataFileDir>: 전체 백업을 포함하는 폴더입니다.<LogFilesDir>: 로그 백업, 차등 및 증분 백업(있는 경우)을 포함하는 폴더입니다.<BackupIdFromJsonFile>: "c단계"에서 추출된 BackupId입니다.
특정 전체 또는 차등 백업으로 복원하려면 다음을 수행합니다.
복원된 새 데이터베이스를 만드는 경우 HDBSQL 명령을 실행하여 새
<DatabaseName>데이터베이스를 만든 다음,ALTER SYSTEM STOP DATABASE <db> IMMEDIATE명령을 사용하여 복원에 사용할 데이터베이스를 중지합니다. 그러나 기존 데이터베이스만 복원하는 경우 HDBSQL 명령을 실행하여 데이터베이스를 중지합니다.RECOVER DATA FOR <DatabaseName> USING BACKUP_ID <BackupIdFromJsonFile> USING SOURCE '<DatabaseName@HostName>' USING CATALOG PATH ('<PathToGeneratedCatalogInStep3>') USING DATA PATH ('<DataFileDir>') CLEAR LOG<DatabaseName>: 복원하려는 새 데이터베이스 또는 기존 데이터베이스의 이름입니다.<Timestamp>: 특정 시점 복원에 대한 정확한 타임스탬프입니다.<DatabaseName@HostName>: 백업이 복원에 사용되는 데이터베이스의 이름과 이 데이터베이스가 있는 호스트 또는 SAP HANA 서버 이름입니다.USING SOURCE <DatabaseName@HostName>옵션은 데이터 백업(복원에 사용됨)이 대상 SAP HANA 컴퓨터와 다른 SID 또는 이름을 사용하는 데이터베이스임을 지정합니다. 따라서 백업이 수행된 HANA 서버에서 이루어지는 복원에 대해서는 지정할 필요가 없습니다.<PathToGeneratedCatalogInStep3>: "C단계"에서 생성된 카탈로그 파일의 경로입니다.<DataFileDir>: 전체 백업을 포함하는 폴더입니다.<LogFilesDir>: 로그 백업, 차등 및 증분 백업(있는 경우)을 포함하는 폴더입니다.<BackupIdFromJsonFile>: "c단계"에서 추출된 BackupId입니다.
백업 ID를 사용하여 복원하려면 다음을 수행합니다.
RECOVER DATA FOR <db> USING BACKUP_ID <bkId> USING CATALOG PATH <path> USING LOG PATH <path> USING DATA PATH <path> CHECK ACCESS USING FILE예:
동일한 서버에 SAP HANA 시스템 복원:
RECOVER DATABASE FOR SYSTEM UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILE동일한 서버에 SAP HANA 테넌트 복원:
RECOVER DATABASE FOR DHI UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILE다른 서버에 SAP HANA 시스템 복원:
RECOVER DATABASE FOR SYSTEM UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING SOURCE <sourceSID> USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILE다른 서버에 SAP HANA 테넌트 복원:
RECOVER DATABASE FOR DHI UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING SOURCE <sourceSID> USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILE

파일로 부분 복원
Azure Backup 서비스는 파일로 복원하는 동안 다운로드할 파일 체인을 결정합니다. 그러나 전체 콘텐츠를 다시 다운로드하지 않으려는 시나리오가 있습니다.
예를 들어 주간 전체, 일간 차등 및 로그의 백업 정책이 있고 특정 차등 백업에 사용할 파일을 이미 다운로드했습니다. 올바른 복구 지점이 아닌 것을 확인하고 다음 날의 차등 백업을 다운로드하기로 결정했습니다. 이미 전체 백업이 시작되었으므로 차등 파일만 필요합니다. Azure Backup에서 제공하는 파일로 부분 복원 기능을 사용하면 다운로드 체인에서 전체 백업을 제외하고 차등 백업만 다운로드할 수 있습니다.
백업 파일 형식 제외
ExtensionSettingOverrides.json은 SQL용 Azure Backup 서비스의 여러 설정에 대한 재정의가 포함된 JSON(JavaScript Object Notation) 파일입니다. 파일로 부분 복원 작업의 경우 새 JSON 필드 RecoveryPointsToBeExcludedForRestoreAsFiles를 추가해야 합니다. 이 필드에는 다음 파일로 복원 작업에서 제외해야 하는 복구 지점 유형을 나타내는 문자열 값이 있습니다.
파일을 다운로드할 대상 머신에서 opt/msawb/bin 폴더로 이동합니다.
ExtensionSettingOverrides.JSON이라는 JSON 파일이 아직 없으면 새로 만듭니다.
다음 JSON 키 값 쌍을 추가합니다.
{ "RecoveryPointsToBeExcludedForRestoreAsFiles": "ExcludeFull" }파일의 권한과 소유권을 다음과 같이 변경합니다.
chmod 750 ExtensionSettingsOverrides.json chown root:msawb ExtensionSettingsOverrides.json서비스를 다시 시작할 필요가 없습니다. Azure Backup 서비스는 이 파일에 설명된 대로 복원 체인에서 백업 유형을 제외하려고 시도합니다.
RecoveryPointsToBeExcludedForRestoreAsFiles는 복원 중에 제외할 복구 지점을 나타내는 특정 값만 사용합니다. SAP HANA의 경우 이러한 값은 다음과 같습니다.
ExcludeFull. 차등, 증분 및 로그와 같은 다른 백업 유형이 다운로드됩니다(복원 지점 체인에 있는 경우).ExcludeFullAndDifferential. 증분 및 로그와 같은 다른 백업 유형이 다운로드됩니다(복원 지점 체인에 있는 경우).ExcludeFullAndIncremental. 차등 및 로그와 같은 다른 백업 유형이 다운로드됩니다(복원 지점 체인에 있는 경우).ExcludeFullAndDifferentialAndIncremental. 로그와 같은 다른 백업 유형이 다운로드됩니다(복원 지점 체인에 있는 경우).
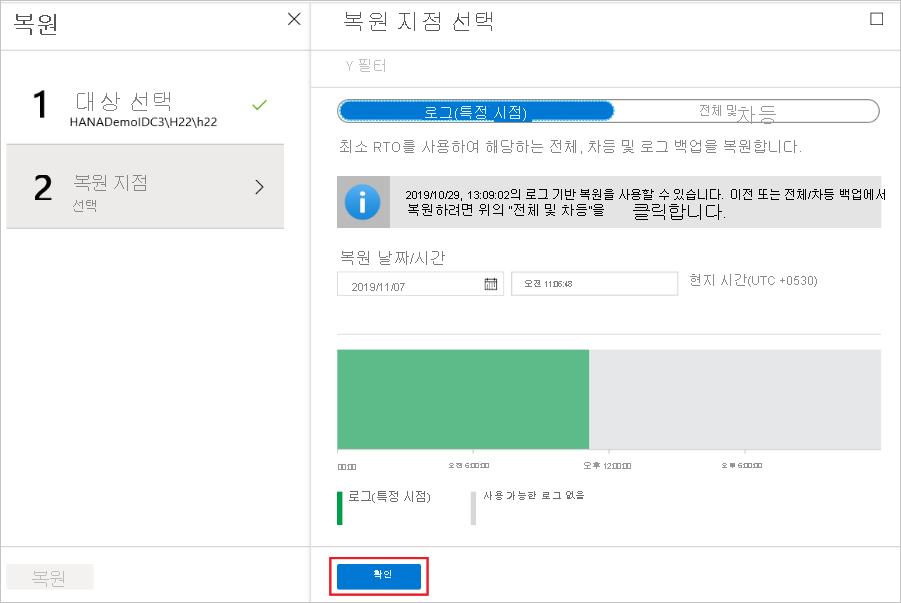
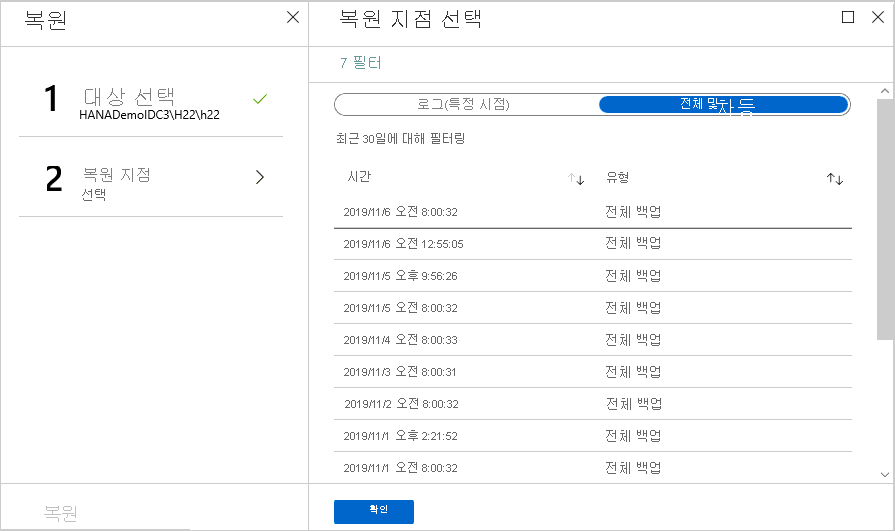
특정 시점으로 복원
복원 유형으로 로그(시점)을 선택한 경우 다음을 수행합니다.
로그 그래프에서 복구 지점을 선택하고 확인을 선택하여 복원 지점을 선택합니다.
복원 메뉴에서 복원을 선택하여 복원 작업을 시작합니다.
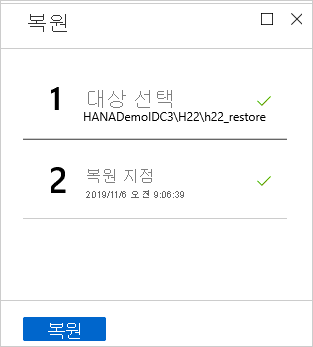
알림 영역에서 복원 진행률을 추적하거나 데이터베이스 메뉴에서 복원 작업을 선택하여 추적합니다.

특정 복구 지점으로 복원
복원 유형으로 전체 및 차등을 선택한 경우 다음을 수행합니다.
목록에서 복구 지점을 선택하고 확인을 선택하여 복원 지점을 선택합니다.
복원 메뉴에서 복원을 선택하여 복원 작업을 시작합니다.
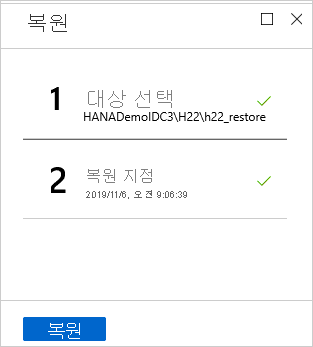
알림 영역에서 복원 진행률을 추적하거나 데이터베이스 메뉴에서 복원 작업을 선택하여 추적합니다.

참고 항목
MDC(Multiple Database Container) 복원에서는 시스템 데이터베이스가 대상 인스턴스로 복원된 후, 등록 전 스크립트를 다시 실행해야 합니다. 그러면 후속 테넌트 데이터베이스 복원이 성공합니다. 자세한 내용은 여러 컨테이너 데이터베이스 복원 문제 해결을 참조하세요.
지역 간 복원
복원 옵션 중 하나인 CRR(지역 간 복원)을 사용하면 Azure 쌍으로 연결된 지역인 보조 지역에서 Azure VM에 호스트된 SAP HANA 데이터베이스를 복원할 수 있습니다.
이 기능을 시작하려면 지역 간 복원 설정을 참조하세요.
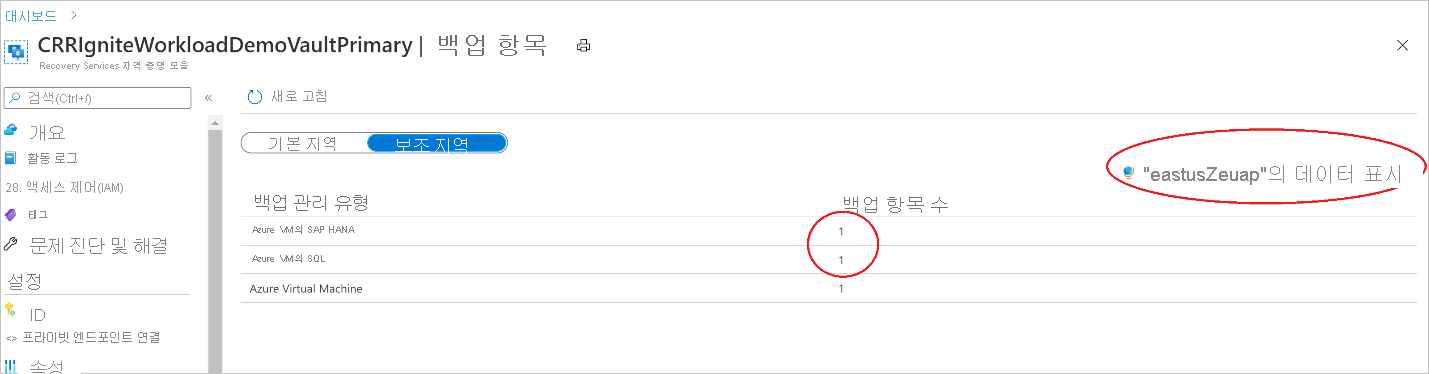
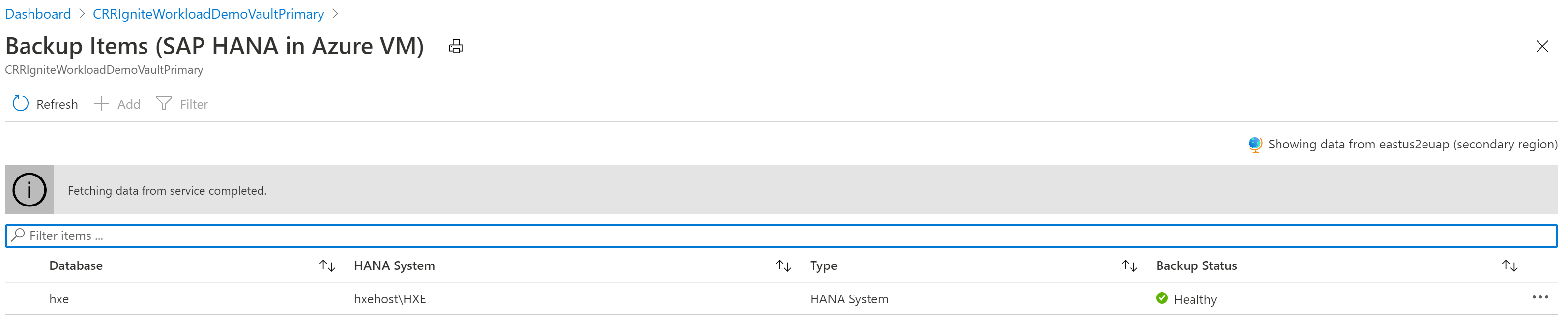
보조 지역의 백업 항목 보기
CRR을 사용하도록 설정된 경우 보조 지역에서 백업 항목을 볼 수 있습니다.
- Azure Portal에서 Recovery Services 자격 증명 모음으로 이동하고 백업 항목을 선택합니다.
- 보조 지역을 선택하여 보조 지역의 항목을 봅니다.
참고 항목
CRR 기능을 지원하는 백업 관리 유형만 목록에 표시됩니다. 현재 보조 지역에 대한 보조 지역 데이터 복원만 지원됩니다.
보조 지역에 복원
보조 지역 복원 사용자 환경은 주 지역 복원 사용자 환경과 유사합니다. 복원 구성 창에서 세부 정보를 구성할 때 보조 지역 매개 변수만 입력하라는 메시지가 표시됩니다. 보조 지역에 자격 증명 모음이 있어야 하고, 보조 지역의 자격 증명 모음에 SAP HANA 서버를 등록해야 합니다.
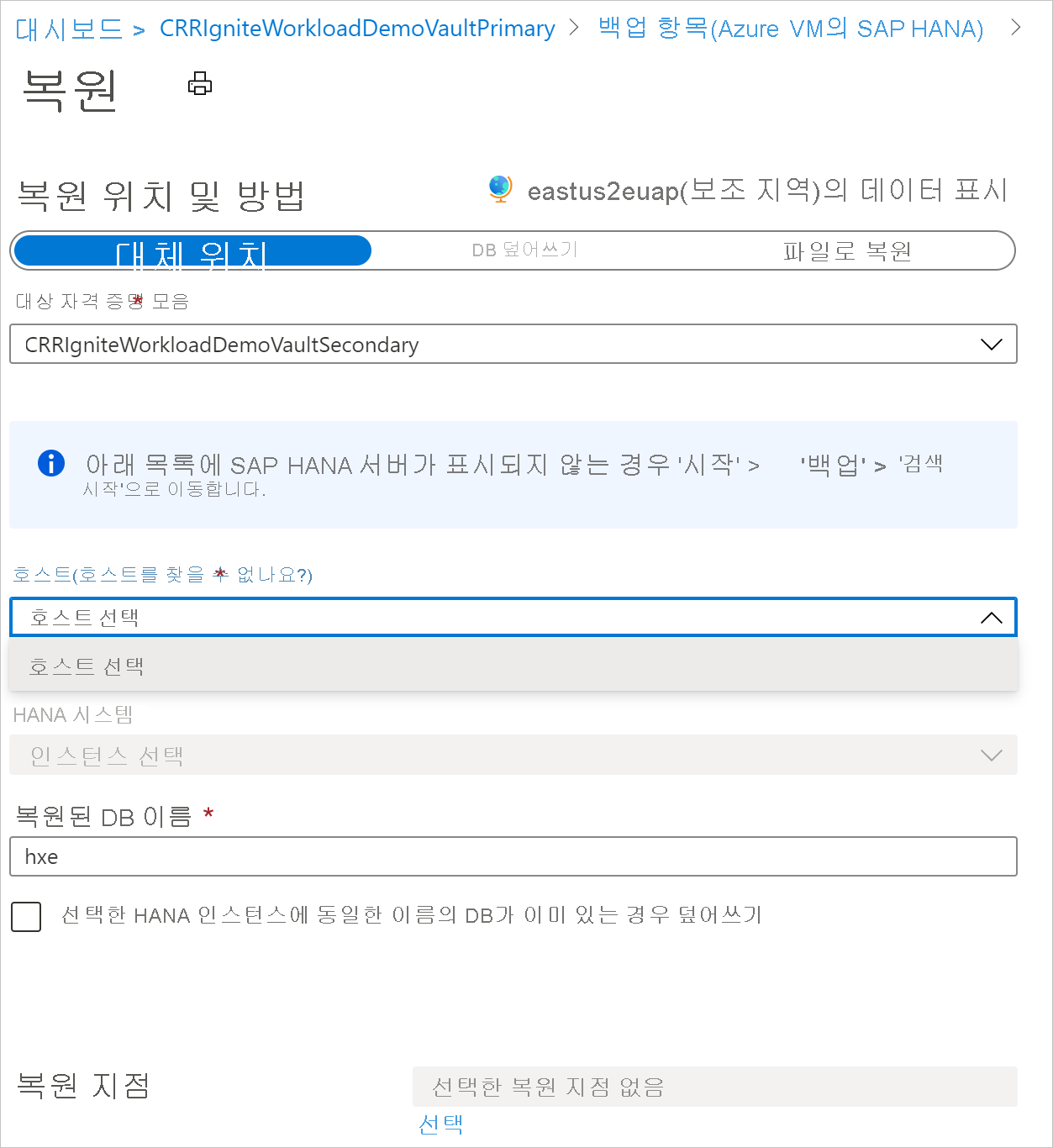
참고 항목
- 복원이 트리거된 후에는 데이터 전송 단계에서 복원 작업을 취소할 수 없습니다.
- 지역 간 복원 작업을 수행하는 데 필요한 역할 및 액세스 수준은 구독의 백업 운영자 역할과 원본 및 대상 가상 머신의 기여자(쓰기) 액세스 권한입니다. 백업 작업을 보기 위해 구독에서 필요한 최소 권한은 백업 읽기 권한자입니다.
- 보조 지역에서 백업 데이터를 사용하기 위한 RPO(복구 지점 목표)는 12시간입니다. 따라서 CRR을 켜면 보조 지역의 RPO는 12시간 + 로그 빈도 기간(최소 15분으로 설정할 수 있음)입니다.
지역 간 복원을 위한 최소 역할 요구 사항에 대해 알아봅니다.
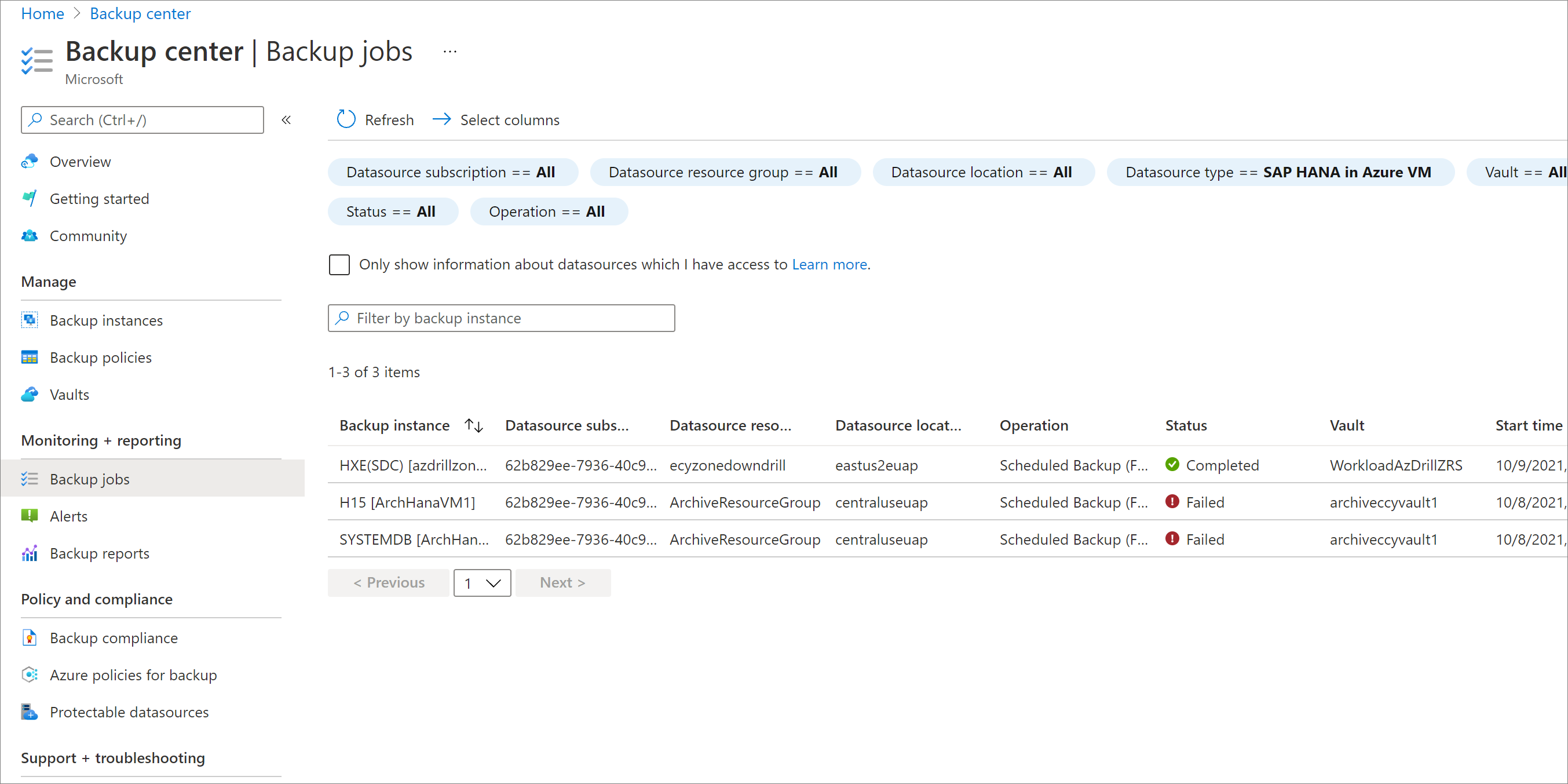
보조 지역 복원 작업 모니터링
Azure Portal에서 백업 센터로 이동한 다음, 백업 작업을 선택합니다.
보조 지역의 작업을 보려면 CrossRegionRestore에 대한 작업을 필터링합니다.

구독 간 복원
이제 Azure Backup을 사용하면 복원 지점에서 모든 구독(다음 Azure RBAC 요구 사항에 따라)으로 SAP HANA 데이터베이스를 복원할 수 있습니다. 기본적으로 Azure Backup은 복원 지점을 사용할 수 있는 동일한 구독으로 복원합니다.
CSR(구독 간 복원)을 사용하면 복원 권한을 사용할 수 있는 경우 테넌트에서 모든 구독 및 자격 증명 모음으로 복원할 수 있습니다. 기본적으로 CSR은 모든 Recovery Services 자격 증명 모음(기존 및 새로 만든 자격 증명 모음)에서 사용하도록 설정됩니다.
참고 항목
- Recovery Services 자격 증명 모음에서 구독 간 복원을 트리거할 수 있습니다.
- CSR은 스트리밍/Backint 기반 백업에 대해서만 지원되며 스냅샷 기반 백업에는 지원되지 않습니다.
- CSR을 사용한 CRR(지역 간 복원)은 지원되지 않습니다.
프라이빗 엔드포인트 사용 자격 증명 모음으로 구독 간 복원
프라이빗 엔드포인트 지원 자격 증명 모음에 구독 간 복원을 수행하려면 다음을 수행합니다.
- 원본 Recovery Services 자격 증명 모음에서 네트워킹 탭으로 이동합니다.
- 프라이빗 액세스 섹션으로 이동하여 프라이빗 엔드포인트를 만듭니다.
- 복원하려는 대상 자격 증명 모음의 구독을 선택합니다.
- 가상 네트워크 섹션에서 구독 전체에서 복원하려는 대상 VM의 VNet을 선택합니다.
- 프라이빗 엔드포인트를 만들고 복원 프로세스를 트리거합니다.
Azure RBAC 요구 사항
| 작업 유형 | 백업 운영자 | Recovery Services 자격 증명 모음 | 대체 연산자 |
|---|---|---|---|
| 데이터베이스 복원 또는 파일로 복원 | Virtual Machine Contributor |
백업된 원본 VM | 기본 제공 역할 대신 다음과 같은 권한이 있는 사용자 지정 역할을 고려할 수 있습니다. - Microsoft.Compute/virtualMachines/write - Microsoft.Compute/virtualMachines/read |
Virtual Machine Contributor |
데이터베이스가 복원되거나 파일이 생성되는 대상 VM | 기본 제공 역할 대신 다음과 같은 권한이 있는 사용자 지정 역할을 고려할 수 있습니다. - Microsoft.Compute/virtualMachines/write - Microsoft.Compute/virtualMachines/read |
|
Backup Operator |
대상 Recovery Services 자격 증명 모음 |
기본적으로 CSR은 Recovery Services 자격 증명 모음에서 사용하도록 설정됩니다. Recovery Services 자격 증명 모음 복원 설정을 업데이트하려면 속성>구독 간 복원으로 이동하여 필요한 변경을 수행합니다.

Azure CLI를 사용하여 구독 간 복원
az backup vault create
자격 증명 모음을 만들고 업데이트하는 동안 자격 증명 모음의 CSR 상태를 설정할 수 있는 cross-subscription-restore-state 매개 변수를 추가합니다.
az backup recoveryconfig show
SQL 또는 HANA 데이터 원본에 대한 구독 간 복원을 트리거하는 동안 대상 구독을 입력으로 제공할 수 있는 --target-subscription-id 매개 변수를 추가합니다.
예제:
az backup vault create -g {rg_name} -n {vault_name} -l {location} --cross-subscription-restore-state Disable
az backup recoveryconfig show --restore-mode alternateworkloadrestore --backup-management-type azureworkload -r {rp} --target-container-name {target_container} --target-item-name {target_item} --target-resource-group {target_rg} --target-server-name {target_server} --target-server-type SQLInstance --target-subscription-id {target_subscription} --target-vault-name {target_vault} --workload-type SQLDataBase --ids {source_item_id}