자습서: 가용성 그룹 수동 구성 - Azure VM의 SQL Server
적용 대상: ![]() Azure VM 기반 SQL Server
Azure VM 기반 SQL Server
팁
가용성 그룹을 배포하는 방법에는 여러 가지가 있습니다. 동일한 Azure 가상 네트워크 내의 여러 서브넷에 SQL Server VM(가상 머신)을 생성하여 배포를 간소화하고 Always On 가용성 그룹에 대한 Azure Load Balancer 또는 DNN(분산 네트워크 이름)의 필요성을 없앨 수 있습니다. 단일 서브넷에서 가용성 그룹을 이미 만든 경우 이를 다중 서브넷 환경으로 마이그레이션할 수 있습니다.
이 자습서에서는 SQL Server에 대한 Always On 가용성 그룹을 단일 서브넷 내의 Azure VM에 만드는 방법을 보여 줍니다. 전체 자습서에서는 두 개의 SQL Server 인스턴스에서 데이터베이스 복제본이 있는 가용성 그룹을 만듭니다.
이 문서에서는 가용성 그룹 환경을 수동으로 구성합니다. Azure Portal, PowerShell 또는 Azure CLI나 Azure 빠른 시작 템플릿을 사용하여 단계를 자동화할 수도 있습니다.
예상 시간: 이 자습서는 필수 조건을 충족한 후 완료하는 데 약 30분이 걸립니다.
사전 요구 사항
이 자습서는 사용자가 SQL Server Always On 가용성 그룹을 기본적으로 이해하고 있다고 가정합니다. 자세한 내용은 Always On 가용성 그룹(SQL Server) 개요를 참조하세요.
이 자습서의 절차를 시작하기 전에 Azure 가상 머신에 Always On 가용성 그룹을 만들기 위한 필수 조건을 완료해야 합니다. 이 필수 조건을 이미 완료한 경우 클러스터 만들기로 이동할 수 있습니다.
다음 표에서는 이 자습서를 완료하기 전에 필요한 필수 조건을 요약합니다.
| 요구 사항 | Description |
|---|---|
 두 개의 SQL Server 인스턴스 두 개의 SQL Server 인스턴스 |
- Azure 가용성 집합에 - 단일 도메인에 - 장애 조치(failover) 클러스터링이 설치됨 |
| Windows Server |
클러스터 감시를 위한 파일 공유 |
| SQL Server 서비스 계정 |
도메인 계정 |
| SQL Server 에이전트 서비스 계정 |
도메인 계정 |
| 방화벽 포트 열기 |
- SQL Server: 기본 인스턴스에 대해 1433 - 데이터베이스 미러링 엔드포인트: 5022 또는 사용 가능한 모든 포트 - 가용성 그룹에 대한 부하 분산 장치 IP 주소 상태 프로브: 59999 또는 사용 가능한 포트 - 클러스터 코어에 대한 부하 분산 장치 IP 주소 상태 프로브: 58888 또는 사용 가능한 포트 |
| 장애 조치(Failover) 클러스터링 |
두 SQL Server 인스턴스 모두에 필요 |
| 설치 도메인 계정 |
- 각 SQL Server의 로컬 관리자 - 각 SQL Server 인스턴스에 대한 sysadmin 고정 서버 역할의 멤버 |
| NSG(네트워크 보안 그룹) |
환경에서 네트워크 보안 그룹을 사용하는 경우 현재 구성이 방화벽 구성에 설명된 포트를 통한 네트워크 트래픽을 허용하는지 확인하세요. |
클러스터 만들기
첫 번째 작업은 SQL Server VM과 미러링 모니터 서버가 모두 포함된 Windows Server 장애 조치 클러스터를 만드는 것입니다.
RDP(원격 데스크톱 프로토콜)를 사용하여 첫 번째 SQL Server에 연결합니다. SQL Server 및 미러링 모니터 서버 모두에서 관리자인 도메인 계정을 사용합니다.
팁
필수 조건에서 CORP\Install이라는 계정을 만들었습니다. 이 계정을 사용합니다.
서버 관리자 대시보드에서 도구를 선택한 다음, 장애 조치(Failover) 클러스터 관리자를 선택합니다.
왼쪽 창에서 장애 조치(Failover) 클러스터 관리자를 마우스 오른쪽 단추로 클릭한 다음, 클러스터 만들기를 선택합니다.
클러스터 만들기 마법사에서 아래 표에 나온 설정으로 페이지를 단계별로 진행하여 1노드 클러스터를 만듭니다.
페이지 설정 시작하기 전에 기본값을 사용합니다. 서버 선택 서버 이름 입력에서 첫 번째 SQL Server 이름을 입력한 다음, 추가를 선택합니다. 유효성 검사 경고 아니요. 이 클러스터에 대한 Microsoft의 지원이 필요 없으므로 유효성 검사 테스트를 실행하지 않습니다. [다음]을 선택하면 클러스터 만들기를 계속합니다. 를 선택합니다. 클러스터 관리를 위한 액세스 지점 클러스터 이름에 클러스터 이름(예: SQLAGCluster1)을 입력합니다. 확인 스토리지 공간을 사용하지 않는 경우 기본값을 사용합니다.
Windows Server 장애 조치 클러스터의 IP 주소 설정
참고
Windows Server 2019에서 클러스터는 클러스터 네트워크 이름 값 대신 분산 서버 이름 값을 만듭니다. Windows Server 2019를 사용하는 경우 이 자습서의 클러스터 코어 이름을 참조하는 단계를 건너뜁니다. PowerShell을 사용하여 클러스터 네트워크 이름을 만들 수 있습니다. 자세한 내용은 블로그 게시물 장애 조치(failover) 클러스터: 클러스터 네트워크 개체를 검토하세요.
장애 조치(Failover) 클러스터 관리자에서 클러스터 코어 리소스로 아래로 스크롤하여 클러스터 세부 정보를 확장합니다. 이름 및 IP 주소 리소스가 모두 실패 상태여야 합니다.
클러스터에 컴퓨터 자체와 동일한 IP 주소가 할당되므로 IP 주소 리소스는 온라인 상태로 전환할 수 없습니다. 이것은 중복 주소입니다.
마우스 오른쪽 단추로 실패한 IP 주소 리소스를 클릭한 다음, 속성을 선택합니다.
고정 IP 주소를 선택합니다. 가상 머신과 동일한 서브넷에서 사용 가능한 주소를 지정합니다.
클러스터 코어 리소스 섹션에서 클러스터 이름을 마우스 오른쪽 단추로 클릭하고 온라인 상태로 전환을 선택합니다. 두 리소스가 모두 온라인 상태로 전환될 때까지 기다립니다.
클러스터 이름 리소스가 온라인 상태가 되면 새 Active Directory 컴퓨터 계정으로 도메인 컨트롤러 서버를 업데이트합니다. 이 Active Directory 계정을 사용하여 나중에 가용성 그룹의 클러스터형 서비스를 실행합니다.
클러스터에 다른 SQL Server 인스턴스 추가
브라우저 트리에서 마우스 오른쪽 단추로 클러스터를 클릭하고, 노드 추가를 선택합니다.
노드 추가 마법사에서 다음을 선택합니다.
서버 선택 페이지에서 두 번째 SQL Server VM을 추가합니다. 서버 이름 입력에 VM 이름을 입력한 다음, 추가>다음을 선택합니다.
유효성 검사 경고 페이지에서 아니요를 선택합니다. (프로덕션 시나리오에서는 유효성 검사 테스트를 수행해야 합니다.) 이후 다음을 선택합니다.
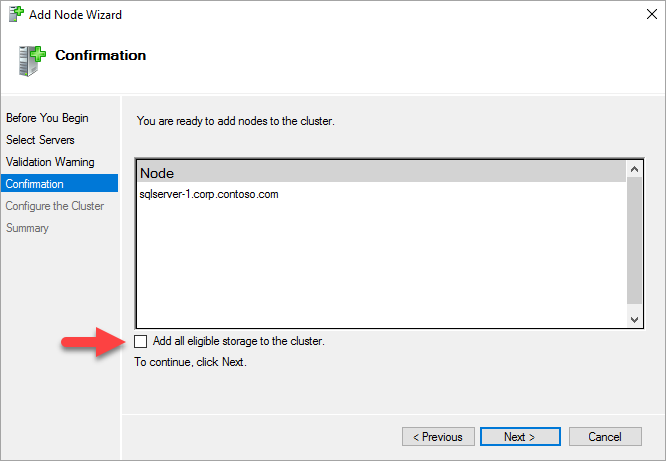
스토리지 공간을 사용 중인 경우 확인 페이지에서 클러스터에 사용할 수 있는 모든 스토리지를 추가하세요. 확인란을 선택 취소합니다.
경고
클러스터에 사용할 수 있는 모든 스토리지를 추가하세요.를 선택 취소하지 않으면 Windows에서 클러스터링 프로세스 중에 가상 디스크를 분리합니다. 결과적으로 클러스터에서 스토리지가 제거되고 PowerShell을 통해 다시 연결될 때까지 디스크 관리자 또는 개체 탐색기에 표시되지 않습니다.
다음을 선택합니다.
마침을 선택합니다.
장애 조치(Failover) 클러스터 관리자에 새 노드가 포함된 클러스터가 표시되고 노드 컨테이너에 목록으로 표시됩니다.
원격 데스크톱 세션에서 로그아웃합니다.
클러스터 쿼럼에 대한 파일 공유 추가
다음 예에서는 Windows 클러스터에서 파일 공유를 사용하여 클러스터 쿼럼을 만듭니다. 이 자습서에서는 NodeAndFileShareMajority 쿼럼을 사용합니다. 자세한 내용은 쿼럼 구성 및 관리를 참조하세요.
원격 데스크톱 세션을 사용하여 파일 공유 미러링 모니터 서버 VM에 연결합니다.
서버 관리자에서 도구를 선택합니다. 컴퓨터 관리를 엽니다.
공유 폴더를 선택합니다.
공유를 마우스 오른쪽 단추로 클릭하고 새 공유를 선택합니다.
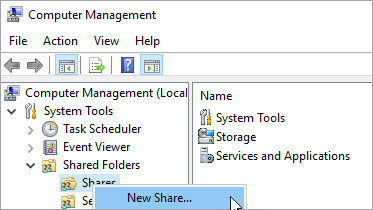
공유 폴더 만들기 마법사를 사용하여 공유를 만듭니다.
폴더 경로 페이지에서 찾아보기를 선택합니다. 공유 폴더의 경로를 찾거나 만든 후 다음을 선택합니다.
이름, 설명 및 설정 페이지에서 공유 이름 및 경로를 확인합니다. 새로 만들기를 선택합니다.
공유 폴더 권한 페이지에서 권한 사용자 지정을 설정합니다. 사용자 지정을 선택합니다.
권한 사용자 지정 대화 상자에서 추가를 선택합니다.
클러스터를 만드는 데 사용되는 계정에 모든 권한이 있는지 확인합니다.
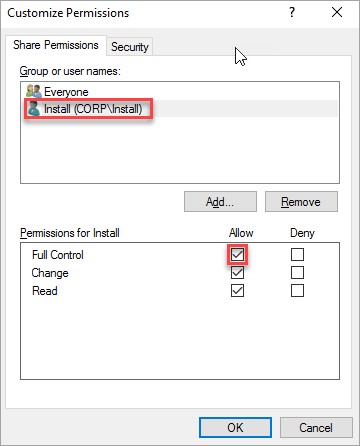
확인을 선택합니다.
공유 폴더 권한 페이지에서 마침을 선택합니다. 그런 다음, 마침을 다시 선택합니다.
서버에서 로그아웃합니다.
클러스터 쿼럼 구성
참고
가용성 그룹의 구성에 따라 Windows Server 장애 조치 클러스터에 참여하는 노드의 쿼럼 투표를 변경해야 할 수 있습니다. 자세한 내용은 Azure VM의 SQL Server를 위한 클러스터 쿼럼 구성을 참조하세요.
원격 데스크톱 세션을 사용하여 첫 번째 클러스터 노드에 연결합니다.
장애 조치(Failover) 클러스터 관리자에서 클러스터를 마우스 오른쪽 단추로 클릭하고, 기타 작업을 가리킨 다음, 클러스터 쿼럼 설정 구성을 선택합니다.
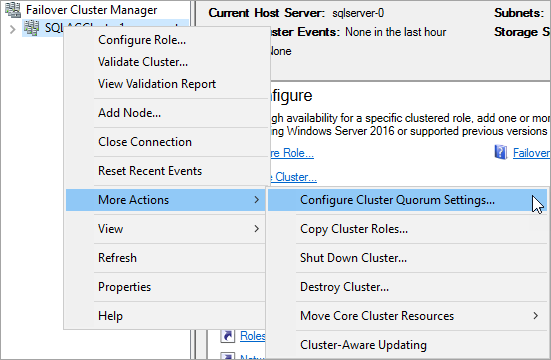
클러스터 쿼럼 구성 마법사에서 다음을 선택합니다.
쿼럼 구성 옵션 선택 페이지에서 쿼럼 감시 선택을 선택하고 다음을 선택합니다.
쿼럼 감시 선택 페이지에서 파일 공유 감시 구성을 선택합니다.
팁
Windows Server 2016은 클라우드 감시를 지원합니다. 이 유형의 감시를 선택한 경우 파일 공유 감시가 필요하지 않습니다. 자세한 내용은 장애 조치(failover) 클러스터에 대한 클라우드 감시 배포를 참조하세요. 이 자습서에서는 이전 운영 체제에서 지원하는 파일 공유 감시를 사용합니다.
파일 공유 감시 구성에서 만든 공유에 대한 경로를 입력합니다. 다음을 선택합니다.
확인 페이지에서 설정을 검토합니다. 다음을 선택합니다.
마침을 선택합니다.
클러스터 코어 리소스는 파일 공유 감시로 구성됩니다.
가용성 그룹 사용
다음으로, Always On 가용성 그룹을 사용하도록 설정합니다. 두 SQL Server VM에서 모두 다음 단계를 완료합니다.
시작 화면에서 SQL Server 구성 관리자를 엽니다.
브라우저 트리에서 SQL Server 서비스를 선택합니다. 그런 다음, SQL Server(MSSQLSERVER) 서비스를 마우스 오른쪽 단추로 클릭하고 속성을 선택합니다.
Always On 고가용성 탭을 선택한 다음, Always On 가용성 그룹 사용을 선택합니다.
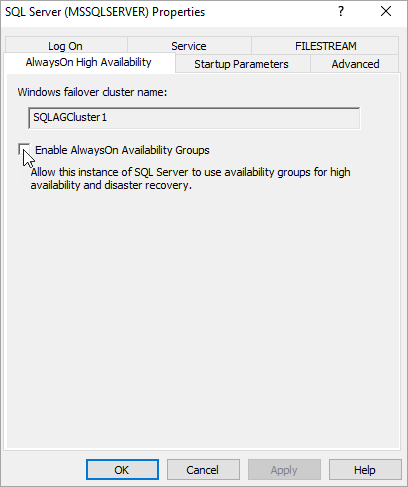
적용을 선택합니다. 팝업 대화 상자에서 확인을 선택합니다.
SQL Server 서비스를 다시 시작합니다.
FILESTREAM 기능 사용 설정
가용성 그룹의 데이터베이스에 FILESTREAM을 사용하지 않는 경우 이 단계를 건너뛰고 다음 단계인 데이터베이스 만들기로 이동합니다.
FILESTREAM을 사용하는 가용성 그룹에 데이터베이스를 추가할 계획인 경우 FILESTREAM이 기본적으로 사용 중지되어 있으므로 해당 기능을 사용하도록 설정해야 합니다. SQL Server 구성 관리자를 사용하여 두 SQL Server 인스턴스에서 이 기능을 사용하도록 설정합니다.
FILESTREAM 기능을 사용하도록 설정하려면 다음 단계를 수행합니다.
필수 구성 요소 문서에서 만든 CORP\Install 도메인 계정과 같이 sysadmin 고정 서버 역할의 멤버인 도메인 계정을 사용하여 RDP 파일을 첫 번째 SQL Server VM(예: SQL-VM-1)에 시작합니다.
SQL Server VM 중 하나의 시작 화면에서 SQL Server 구성 관리자를 시작합니다.
브라우저 트리에서 SQL Server 서비스를 강조 표시하고, 마우스 오른쪽 단추로 SQL Server(MSSQLSERVER) 서비스를 클릭한 다음, 속성을 선택합니다.
FILESTREAM 탭을 선택한 다음 Transact-SQL 액세스에 FILESTREAM 사용 확인란을 선택합니다.
적용을 선택합니다. 팝업 대화 상자에서 확인을 선택합니다.
SQL Server Management Studio에서 새 쿼리를 선택하여 쿼리 편집기를 표시합니다.
쿼리 편집기에서 다음 Transact-SQL 코드를 입력합니다.
EXEC sp_configure filestream_access_level, 2 RECONFIGURE실행을 선택합니다.
SQL Server 서비스를 다시 시작합니다.
이러한 단계를 다른 SQL Server 인스턴스에 대해 반복합니다.
첫 번째 SQL Server 인스턴스에서 데이터베이스 만들기
- sysadmin 고정 서버 역할의 멤버인 도메인 계정을 사용하여 첫 번째 SQL Server VM에서 RDP 파일을 엽니다.
- SSMS(SQL Server Management Studio)를 열고 첫 번째 SQL Server 인스턴스에 연결합니다.
- 개체 탐색기에서 마우스 오른쪽 단추로 데이터베이스를 클릭하고, 새 데이터베이스를 선택합니다.
- 데이터베이스 이름에 MyDB1을 입력한 다음, 확인을 선택합니다.
백업 공유 만들기
서버 관리자의 첫 번째 SQL Server VM에서 도구를 선택합니다. 컴퓨터 관리를 엽니다.
공유 폴더를 선택합니다.
공유를 마우스 오른쪽 단추로 클릭하고 새 공유를 선택합니다.
공유 폴더 만들기 마법사를 사용하여 공유를 만듭니다.
폴더 경로 페이지에서 찾아보기를 선택합니다. 데이터베이스 백업 공유 폴더의 경로를 찾거나 만든 후 다음을 선택합니다.
이름, 설명 및 설정 페이지에서 공유 이름 및 경로를 확인합니다. 다음을 선택합니다.
공유 폴더 권한 페이지에서 권한 사용자 지정을 설정합니다. 그런 다음, 사용자 지정을 선택합니다.
권한 사용자 지정 대화 상자에서 추가를 선택합니다.
모든 권한을 선택하여 공유에 대한 전체 액세스 권한을 SQL Server 서비스 계정(
Corp\SQLSvc)에 부여합니다.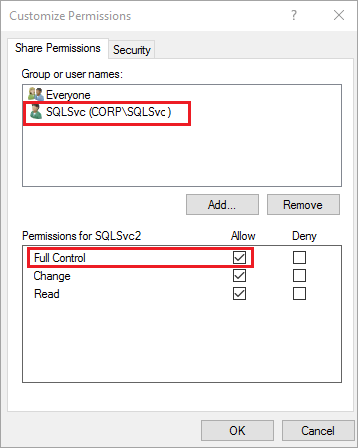
확인을 선택합니다.
공유 폴더 권한 페이지에서 마침을 선택합니다. 다시 마침을 선택합니다.
데이터베이스의 전체 백업 수행
새 데이터베이스를 백업하여 로그 체인을 초기화해야 합니다. 새 데이터베이스를 백업하지 않으면 해당 데이터베이스를 가용성 그룹에 포함할 수 없습니다.
개체 탐색기에서 데이터베이스를 마우스 오른쪽 단추로 클릭하고, 작업을 가리킨 다음, 백업을 선택합니다.
확인을 선택하여 기본 백업 위치로 전체 백업을 수행합니다.
가용성 그룹 만들기
이제 다음 작업을 수행하여 가용성 그룹을 만들고 구성할 준비가 되었습니다.
- 첫 번째 SQL Server에서 데이터베이스를 만듭니다.
- 데이터베이스의 전체 백업 및 트랜잭션 로그 백업을 수행합니다.
NO RECOVERY옵션을 사용하여 전체 및 로그 백업을 두 번째 SQL Server 인스턴스로 복원합니다.- 동기 커밋, 자동 장애 조치 및 읽을 수 있는 보조 복제본을 사용하여 가용성 그룹(MyTestAG)을 만듭니다.
가용성 그룹 만들기
원격 데스크톱을 사용하여 SQL Server VM에 연결하고 SQL Server Management Studio를 엽니다.
SSMS의 개체 탐색기에서 Always On 고가용성을 마우스 오른쪽 단추로 클릭하고 새 가용성 그룹 마법사를 선택합니다.
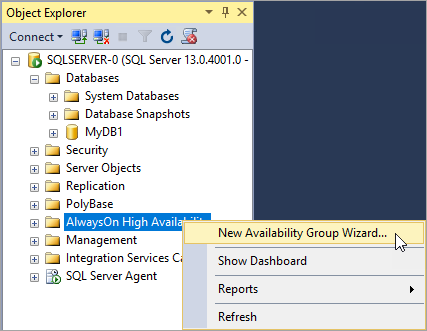
소개 페이지에서 다음을 선택합니다. 가용성 그룹 옵션 지정 페이지의 가용성 그룹 이름 상자에 가용성 그룹의 이름을 입력합니다. 예를 들어, MyTestAG를 입력합니다. 다음을 선택합니다.
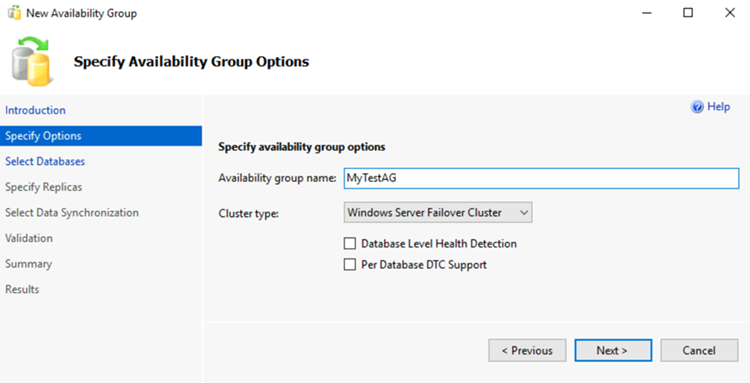
데이터베이스 선택 페이지에서 데이터베이스를 선택하고, 다음을 선택합니다.
참고
원하는 주 복제본에서 전체 백업을 하나 이상 생성했으므로 데이터베이스는 가용성 그룹에 대한 필수 조건을 충족합니다.
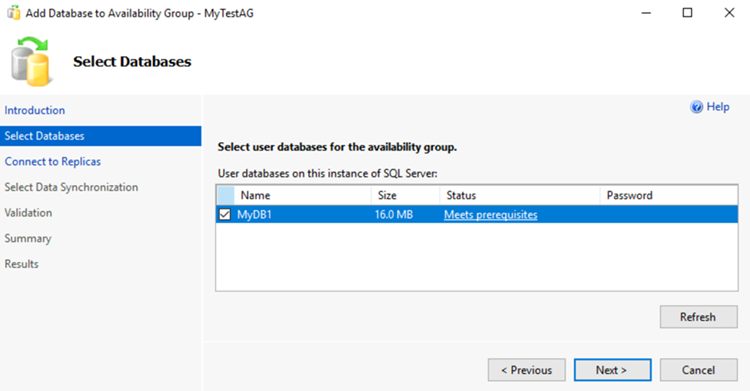
복제본 지정 페이지에서 복제본 추가를 선택합니다.
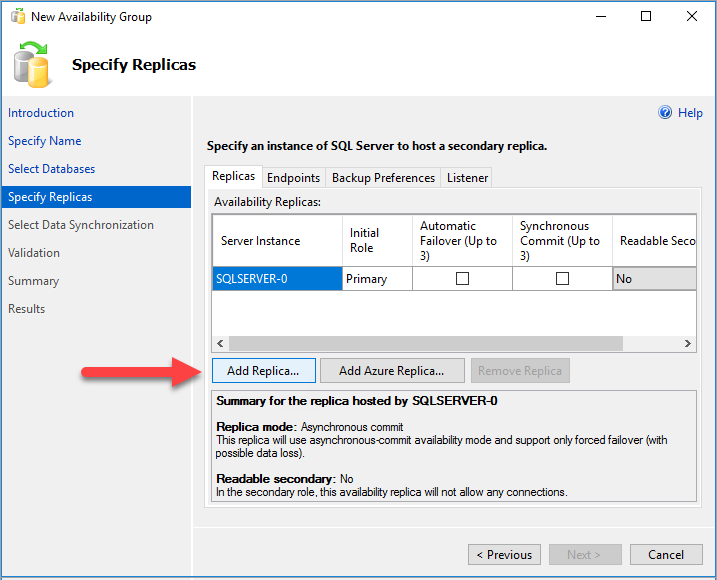
서버에 연결 대화 상자에서 서버 이름에 두 번째 SQL Server 인스턴스의 이름을 입력합니다. 그런 다음 연결을 선택합니다.
복제본 지정 페이지로 돌아가면 이제 가용성 복제본 아래에 두 번째 서버가 표시됩니다. 아래와 같이 복제본을 구성합니다.
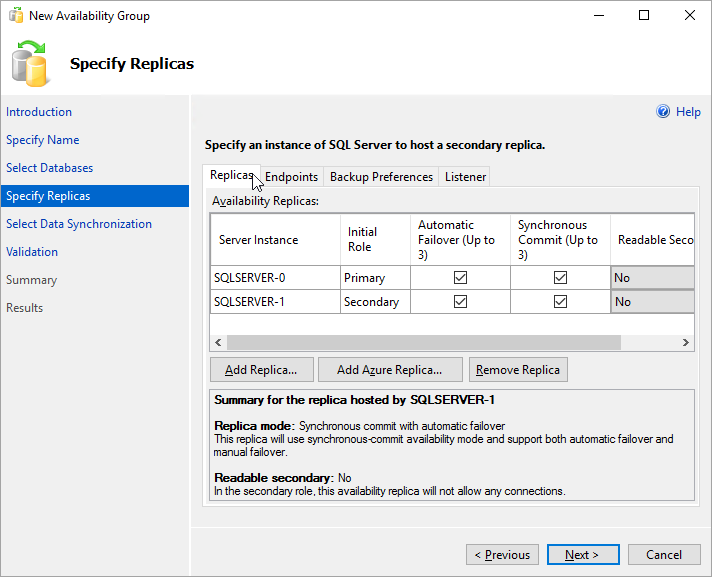
엔드포인트를 선택하여 이 가용성 그룹에 대한 데이터베이스 미러링 엔드포인트를 확인합니다. 데이터베이스 미러링 엔드포인트에 대한 방화벽 규칙을 설정할 때 사용한 것과 동일한 포트를 사용합니다.
초기 데이터 동기화 선택 페이지에서 전체를 선택하고 공유 네트워크 위치를 지정합니다. 위치의 경우 만든 백업 공유를 사용합니다. 예제에서는 \\<First SQL Server Instance>\Backup\이었습니다. 새로 만들기를 선택합니다.
참고
전체 동기화는 SQL Server의 첫 번째 인스턴스에서 데이터베이스의 전체 백업을 수행하고 두 번째 인스턴스로 복원합니다. 대규모 데이터베이스의 경우 시간이 오래 걸릴 수 있으므로 전체 동기화는 권장하지 않습니다.
수동으로 데이터베이스의 백업을 수행하고
NO RECOVERY를 통해 복원하여 이 시간을 줄일 수 있습니다. 가용성 그룹을 구성하기 전에 이미 두 번째 SQL Server 인스턴스에서NO RECOVERY를 사용하여 데이터베이스를 복원한 경우 조인만을 선택합니다. 가용성 그룹을 구성한 후 백업을 수행하려면 초기 데이터 동기화 건너뛰기를 선택합니다.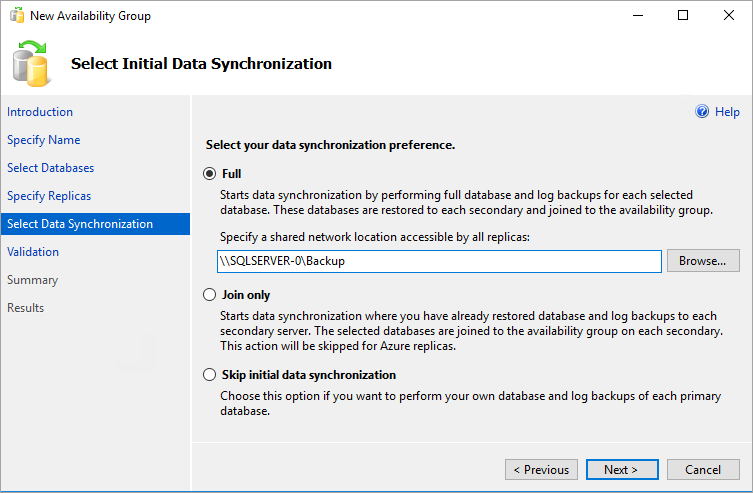
유효성 검사 페이지에서 다음을 선택합니다. 이 페이지는 다음 이미지와 유사하게 나타납니다.
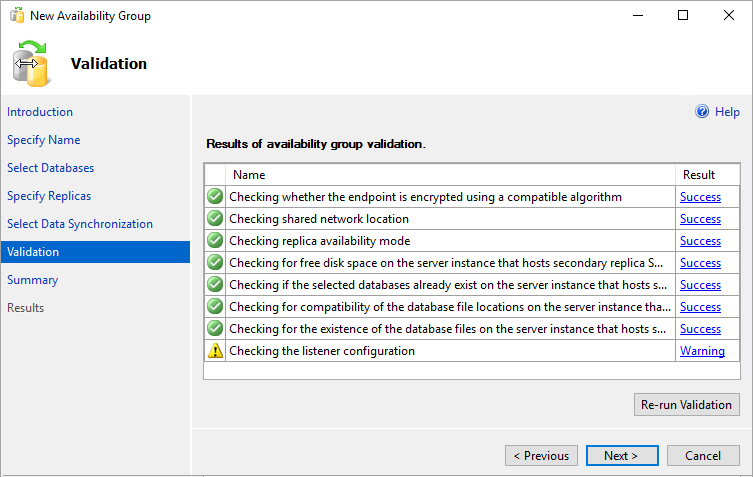
참고
가용성 그룹 수신기가 구성되어 있지 않으므로 수신기 구성에 대한 경고가 표시됩니다. Azure 가상 머신에서 Azure 부하 분산 장치를 만든 후 수신기를 만들기 때문에 이 경고는 무시할 수 있습니다.
요약 페이지에서 마침을 선택한 다음, 마법사에서 새 가용성 그룹을 구성하는 동안 기다립니다. 진행률 페이지에서 자세한 내용을 선택하여 자세한 진행 상황을 확인할 수 있습니다.
마법사가 구성을 완료하면 결과 페이지를 검토하여 가용성 그룹이 올바르게 만들어졌는지 확인합니다.
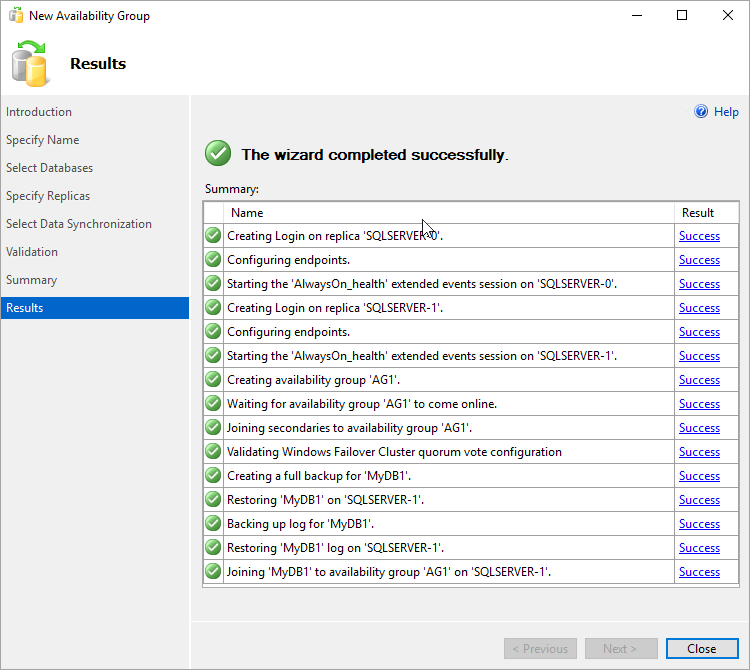
닫기를 선택하여 마법사를 닫습니다.

가용성 그룹 확인
개체 탐색기에서 Always On 고가용성을 확장하고 가용성 그룹을 확장합니다. 이 컨테이너에 새 가용성 그룹이 표시됩니다. 가용성 그룹을 마우스 오른쪽 단추로 클릭하고 대시보드 표시를 선택합니다.
가용성 그룹 대시보드는 다음 스크린샷과 유사하게 표시됩니다.
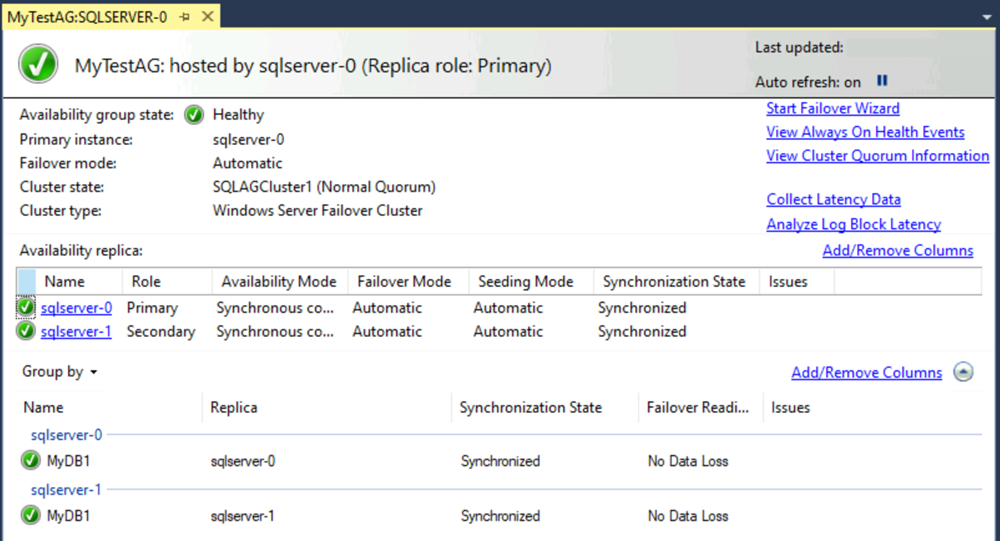
대시보드에는 복제본, 각 복제본의 장애 조치 모드 및 동기화 상태가 표시됩니다.
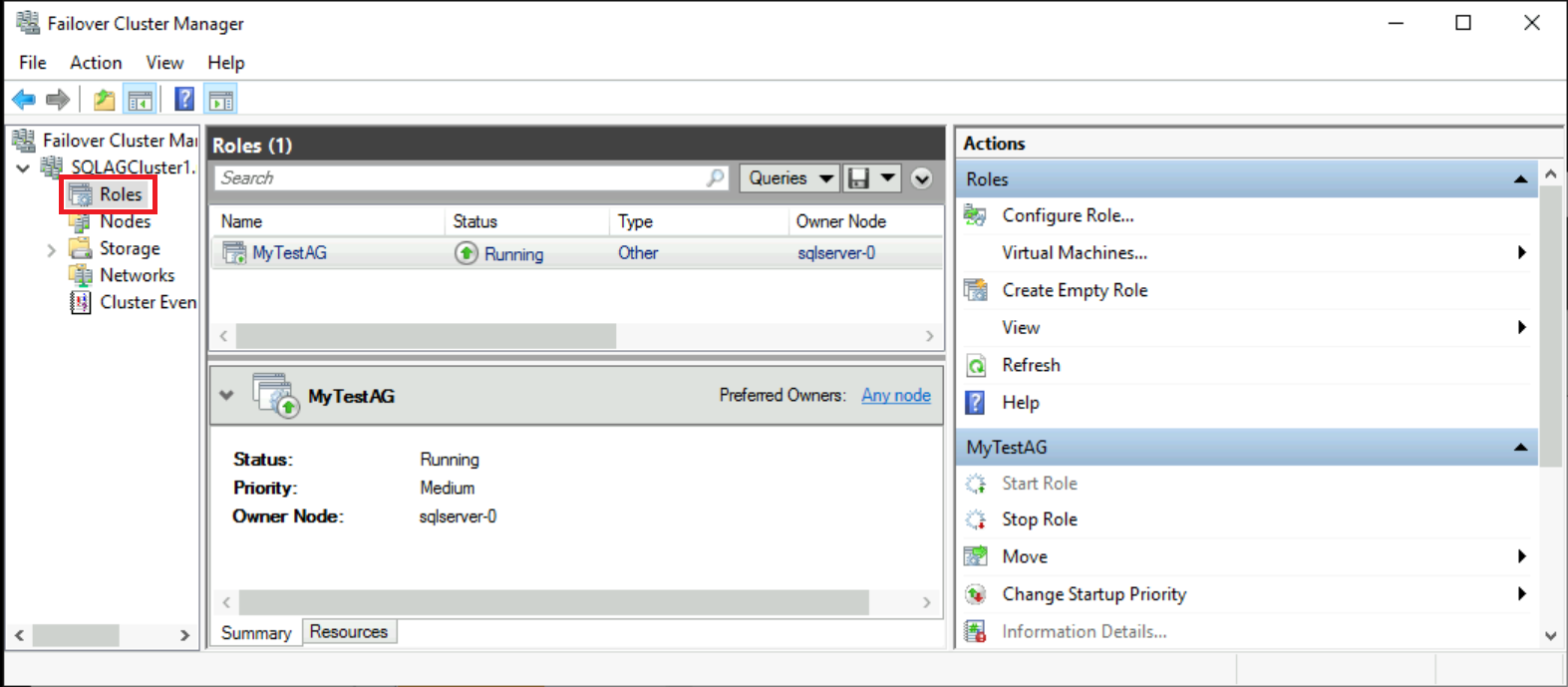
장애 조치(Failover) 클러스터 관리자에서 클러스터를 선택합니다. 역할을 선택합니다.
사용한 가용성 그룹 이름은 클러스터의 역할입니다. 수신기를 구성하지 않았으므로 해당 가용성 그룹에는 클라이언트 연결에 대한 IP 주소가 없습니다. Azure 부하 분산 장치를 만든 후에 수신기를 구성하게 됩니다.
경고
장애 조치 클러스터 관리자에서 가용성 그룹을 장애 조치하지 마세요. 모든 장애 조치 작업은 SSMS의 가용성 그룹 대시보드에서 수행해야 합니다. 가용성 그룹과 함께 장애 조치 클러스터 관리자 사용에 대한 제한 사항에 관해 자세히 알아봅니다.


이 시점에 두 개의 SQL Server 복제본을 포함하는 가용성 그룹이 있습니다. 가용성 그룹을 인스턴스 간에 이동할 수 있습니다. 수신기가 없으므로 아직 가용성 그룹에 연결할 수 없습니다.
Azure Virtual Machines에서 수신기에는 분산 장치가 필요합니다. 다음 단계는 Azure에서 부하 분산 장치를 만드는 것입니다.
Azure Load Balancer 만들기
참고
여러 서브넷에 가용성 그룹을 배포하는 데는 부하 분산 장치가 필요하지 않습니다. 단일 서브넷 환경의 경우 Windows 2016 이상에서 SQL Server 2019 CU8 이상을 사용하는 고객은 기존 VNN(가상 네트워크 이름) 수신기 및 Azure Load Balancer를 DNN(분산 네트워크 이름) 수신기로 바꿀 수 있습니다. DNN을 사용하려면 가용성 그룹에 대한 Azure Load Balancer를 구성하는 자습서 단계를 건너뜁니다.
단일 서브넷의 Azure 가상 머신에서 SQL Server 가용성 그룹에는 부하 분산 장치가 필요합니다. 부하 분산 장치는 가용성 그룹 수신기 및 Windows Server 장애 조치 클러스터에 대한 IP 주소를 보유합니다. 이 섹션에서는 Azure Portal에서 부하 분산 장치를 만드는 방법을 요약합니다.
Azure의 부하 분산 장치는 표준 또는 기본일 수 있습니다. 표준 부하 분산 장치에는 기본 부하 분산 장치보다 더 많은 기능이 있습니다. 가용성 그룹의 경우 가용성 집합 대신 가용성 영역을 사용하는 경우 표준 부하 분산 장치가 필요합니다. SKU 간의 차이점에 대한 자세한 내용은 Azure Load Balancer SKU를 참조하세요.
중요
2025년 9월 30일에 Azure Load Balancer의 기본 SKU가 사용 중지됩니다. 자세한 내용은 공식 공지를 참조하세요. 현재 기본 Load Balancer를 사용 중인 경우 사용 중지 날짜 전에 표준 Load Balancer로 업그레이드합니다. 참고 자료는 Load Balancer 업그레이드를 검토하세요.
Azure Portal에서 SQL Server VM이 있는 리소스 그룹으로 이동하고 + 추가를 선택합니다.
부하 분산 장치를 검색합니다. Microsoft에서 게시하는 부하 분산 장치를 선택합니다.
만들기를 선택합니다.
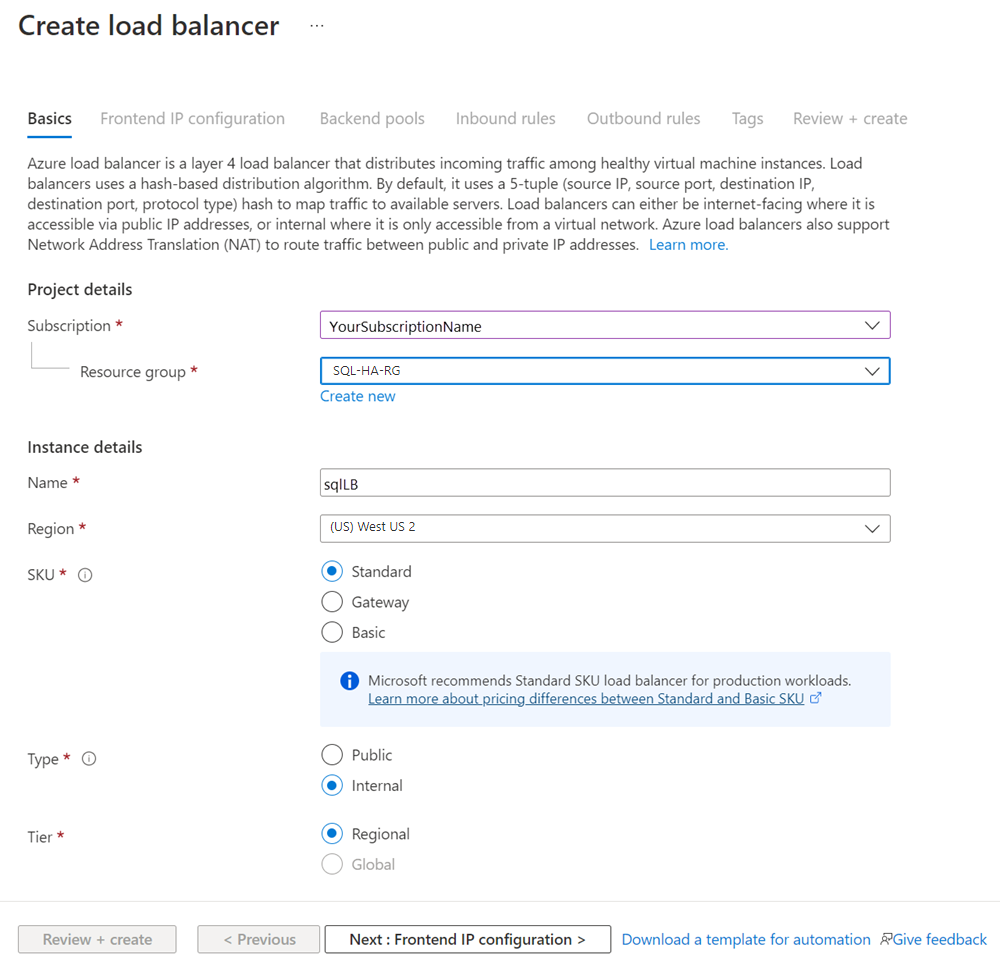
부하 분산 장치 만들기 페이지에서 부하 분산 장치에 대해 다음 매개 변수를 구성합니다.
설정 항목 또는 선택 구독 가상 머신과 동일한 구독을 사용합니다. 리소스 그룹 가상 머신과 동일한 리소스 그룹을 사용합니다. 이름 부하 분산 장치에 대한 텍스트 이름을 사용합니다(예: sqlLB). 지역 가상 머신과 동일한 지역을 사용합니다. SKU 표준을 선택합니다. 유형 내부를 선택합니다. 페이지가 다음과 같이 표시됩니다.
다음: 프런트 엔드 IP 구성을 선택합니다.
+ 프런트 엔드 IP 구성 추가를 선택합니다.
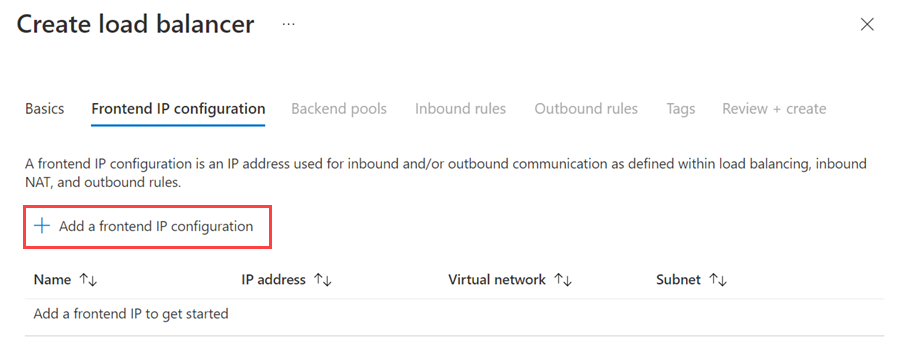
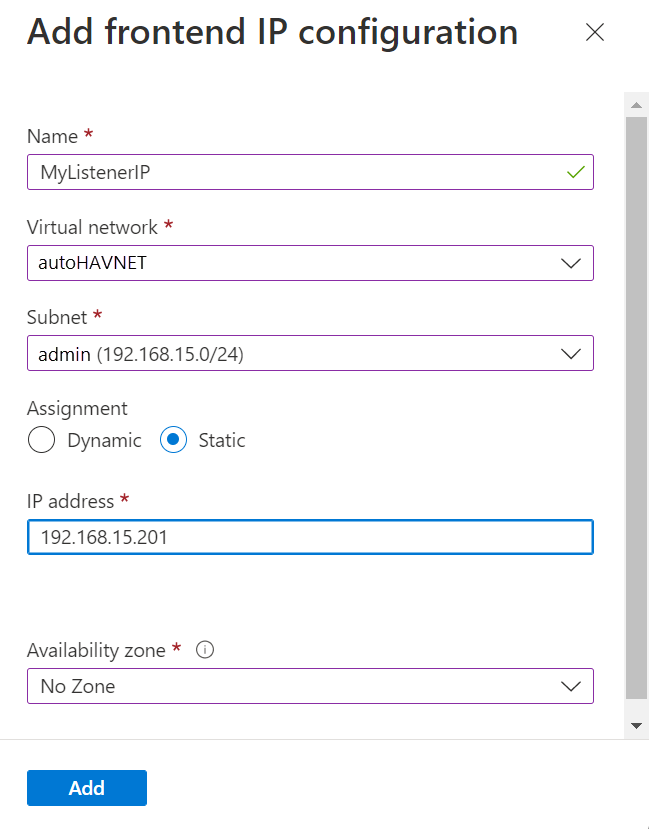
다음 값을 사용하여 프런트 엔드 IP 주소를 설정합니다.
- 이름: 프런트 엔드 IP 구성을 식별하는 이름을 입력합니다.
- 가상 네트워크: 가상 머신과 동일한 네트워크를 선택합니다.
- 서브넷: 가상 머신과 동일한 서브넷을 선택합니다.
- 할당: 고정을 선택합니다.
- IP 주소: 서브넷에서 사용 가능한 주소를 사용합니다. 가용성 그룹 수신기에 대해 이 주소를 사용합니다. 이 주소는 클러스터 IP 주소와 다릅니다.
- 가용성 영역: 필요에 따라 IP 주소를 배포할 가용성 영역을 선택합니다.
다음 이미지에서는 프런트 엔드 IP 구성 추가 대화 상자를 보여 줍니다.
추가를 선택합니다.
검토 + 만들기를 선택하여 구성의 유효성을 검사합니다. 그런 다음, 만들기를 선택하여 부하 분산 장치 및 프런트 엔드 IP 주소를 만듭니다.


부하 분산 장치를 구성하려면 백 엔드 풀, 프로브를 만들고 부하 분산 규칙을 설정해야 합니다.
가용성 그룹 수신기에 대한 백 엔드 풀 추가
Azure Portal에서 리소스 그룹으로 이동합니다. 새로 만든 부하 분산 장치를 보려면 보기를 새로 고쳐야 할 수도 있습니다.
부하 분산 장치를 선택하고, 백 엔드 풀을 선택한 다음, +추가를 선택합니다.
이름에 백 엔드 풀의 이름을 입력합니다.
백 엔드 풀 구성에서 NIC를 선택합니다.
추가를 선택하여 VM이 포함된 가용성 집합과 백 엔드 풀을 연결합니다.
가상 머신에서 가용성 그룹 복제본을 호스트할 가상 머신을 선택합니다. 파일 공유 미러링 모니터 서버를 포함하지 마세요.
참고
가상 머신을 둘 다 지정하지 않은 경우 주 복제본에 대한 연결만 성공합니다.
추가를 선택하여 백 엔드 풀에 가상 머신을 추가합니다.
저장을 선택하여 백엔드 풀을 만듭니다.

프로브 설정
Azure Portal에서 부하 분산 장치를 선택하고, 상태 프로브를 선택한 다음, +추가를 선택합니다.
다음과 같이 수신기 상태 프로브를 설정합니다.
설정 설명 예제 이름 텍스트 SQLAlwaysOnEndPointProbe 프로토콜 TCP 선택 TCP 포트 사용하지 않는 모든 포트 59999 간격 프로브 시도 간격(초)입니다. 5 추가를 선택합니다.
부하 분산 규칙 설정
Azure Portal에서 부하 분산 장치를 선택하고 부하 분산 규칙을 선택한 다음, +추가를 선택합니다.
다음과 같이 수신기의 부하 분산 규칙을 설정합니다.
설정 설명 예제 이름 텍스트 SQLAlwaysOnEndPointListener 프런트 엔드 IP 주소 주소 선택 부하 분산 장치를 만들 때 생성된 주소를 사용합니다. 백 엔드 풀 백 엔드 풀 선택 부하 분산 장치의 대상이 되는 가상 머신이 포함된 백 엔드 풀을 선택합니다. 프로토콜 TCP 선택 TCP 포트 가용성 그룹 수신기용 포트 사용 1433 백 엔드 포트 이 필드는 부동 IP가 직접 서버 반환에 대해 설정된 경우 사용하지 않습니다. 1433 상태 프로브 프로브에 대해 지정한 이름 SQLAlwaysOnEndPointProbe 세션 지속성 드롭다운 목록 없음 유휴 시간 제한 TCP 연결을 열린 상태로 유지하는 시간(분) 4 부동 IP(Direct Server Return) 흐름 토폴로지와 IP 주소 매핑 구성표 Enabled 경고
직접 서버 반환은 만드는 동안 설정됩니다. 변경할 수 없습니다.
저장을 선택합니다.
Windows Server 장애 조치 클러스터에 대한 클러스터 코어 IP 주소 추가
Windows Server 장애 조치 클러스터의 IP 주소도 부하 분산 장치에 있어야 합니다. Windows Server 2019를 사용하는 경우 클러스터가 클러스터 네트워크 이름 값 대신 분산 서버 이름 값을 만들기 때문에 이 프로세스를 건너뜁니다.
Azure Portal에서 동일한 Azure 부하 분산 장치로 이동합니다. 프런트 엔드 IP 구성, +추가를 차례로 선택합니다. 클러스터 코어 리소스에서 Windows Server 장애 조치 클러스터에 대해 구성한 IP 주소를 사용합니다. IP 주소를 고정으로 설정합니다.
부하 분산 장치에서 상태 프로브, + 추가를 차례로 선택합니다.
다음과 같이 Windows Server 장애 조치 클러스터에 대한 클러스터 코어 IP 주소 상태 프로브를 설정합니다.
설정 설명 예제 이름 텍스트 WSFCEndPointProbe 프로토콜 TCP 선택 TCP 포트 사용하지 않는 모든 포트 58888 간격 프로브 시도 간격(초)입니다. 5 추가를 선택하여 상태 프로브를 설정합니다.
부하 분산 규칙을 선택한 다음, +추가를 선택합니다.
다음과 같이 클러스터 코어 IP 주소에 대한 부하 분산 규칙을 설정합니다.
설정 설명 예제 이름 텍스트 WSFCEndPoint 프런트 엔드 IP 주소 주소 선택 Windows Server 장애 조치 클러스터에 대한 IP 주소를 구성할 때 만든 주소를 사용합니다. 수신기 IP 주소와는 다릅니다. 백 엔드 풀 백 엔드 풀 선택 부하 분산 장치의 대상이 되는 가상 머신이 포함된 백 엔드 풀을 선택합니다. 프로토콜 TCP 선택 TCP 포트 클러스터 IP 주소에 대한 포트를 사용합니다. 수신기 프로브 포트에 사용되지 않는 사용 가능한 포트입니다. 58888 백 엔드 포트 이 필드는 부동 IP가 직접 서버 반환에 대해 설정된 경우 사용하지 않습니다. 58888 프로브 프로브에 대해 지정한 이름 WSFCEndPointProbe 세션 지속성 드롭다운 목록 없음 유휴 시간 제한 TCP 연결을 열린 상태로 유지하는 시간(분) 4 부동 IP(Direct Server Return) 흐름 토폴로지와 IP 주소 매핑 구성표 Enabled 경고
직접 서버 반환은 만드는 동안 설정됩니다. 변경할 수 없습니다.
확인을 선택합니다.
수신기 구성
다음에 수행할 작업은 장애 조치 클러스터에서 가용성 그룹 수신기를 구성하는 것입니다.
참고
이 자습서에서는 내부 부하 분산 장치에 대한 하나의 IP 주소를 사용하여 단일 수신기를 만드는 방법을 보여 줍니다. 하나 이상의 IP 주소를 사용하여 수신기를 만들려면 하나 이상의 Always On 가용성 그룹 수신기 구성을 참조하세요.
가용성 그룹 수신기는 SQL Server 가용성 그룹에서 수신하는 IP 주소 및 네트워크 이름입니다. 가용성 그룹 수신기를 만들려면:
-
a. RDP를 사용하여 주 복제본을 호스트하는 Azure 가상 머신에 연결합니다.
b. 장애 조치(Failover) 클러스터 관리자를 엽니다.
다. 네트워크 노드를 선택하고 클러스터 네트워크 이름을 확인합니다. 이 이름을 PowerShell 스크립트에서
$ClusterNetworkName변수에 사용합니다. 다음 이미지에서 클러스터 네트워크 이름은 클러스터 네트워크 1입니다.
클라이언트 액세스 지점을 추가합니다. 클라이언트 액세스 지점은 애플리케이션이 가용성 그룹의 데이터베이스에 연결하는 데 사용하는 네트워크 이름입니다.
a. 장애 조치(failover) 클러스터 관리자에서 클러스터 이름을 확장하고 역할을 선택합니다.
b. 역할 창에서 가용성 그룹 이름을 마우스 오른쪽 단추로 클릭한 다음, 리소스 추가>클라이언트 액세스 지점을 선택합니다.

다. 이름 상자에서 이 새 수신기의 이름을 만듭니다. 새 수신기의 이름은 애플리케이션에서 SQL Server 가용성 그룹의 데이터베이스에 연결하는 데 사용하는 네트워크 이름입니다.
d. 수신기 만들기를 완료하려면 다음을 두 번 선택한 다음, 마침을 선택합니다. 현재 온라인 상태에서 수신기 또는 리소스를 가져오지 마세요.
가용성 그룹에 대한 클러스터 역할을 오프라인으로 전환합니다. 장애 조치(Failover) 클러스터 관리자의 역할 아래에서 역할을 마우스 오른쪽 단추로 클릭한 다음, 역할 중지를 선택합니다.
-
a. 리소스 탭을 선택한 다음, 직접 만든 클라이언트 액세스 지점을 확장합니다. 클라이언트 액세스 지점은 오프라인입니다.

b. IP 리소스를 마우스 오른쪽 단추로 클릭한 다음, 속성을 선택합니다. IP 주소의 이름을 적어두고 PowerShell 스크립트의
$IPResourceName변수에 사용합니다.다. IP 주소에서 고정 IP 주소를 선택합니다. Azure Portal에서 부하 분산 장치 주소를 설정할 때 사용한 주소와 동일한 주소로 IP 주소를 설정합니다.

SQL Server 가용성 그룹이 클라이언트 액세스 지점에 종속되게 합니다.
a. 장애 조치(failover) 클러스터 관리자에서 역할을 선택한 다음, 가용성 그룹을 선택합니다.
b. 리소스 탭의 기타 리소스에서 가용성 그룹 리소스를 마우스 오른쪽 단추로 클릭한 다음, 속성을 선택합니다.
c. 종속성 탭에서 클라이언트 액세스 지점(수신기)의 이름을 추가합니다.

d. 확인을 선택합니다.
클라이언트 액세스 지점이 IP 주소에 종속되게 합니다.
a. 장애 조치(failover) 클러스터 관리자에서 역할을 선택한 다음, 가용성 그룹을 선택합니다.
b. 리소스 탭의 서버 이름 아래에서 클라이언트 액세스 지점을 마우스 오른쪽 단추로 클릭한 다음, 속성을 선택합니다.

c. 종속성 탭을 선택합니다. IP 주소가 종속성인지 확인합니다. 그렇지 않으면 IP 주소에 대한 종속성을 설정합니다. 여러 리소스가 나열되면 IP 주소에 AND가 아니라 OR 종속성이 있는지 확인합니다. 그런 다음, 확인을 선택합니다.

팁
종속성이 올바르게 구성되었는지 확인할 수 있습니다. 장애 조치(failover) 클러스터 관리자에서 역할로 이동하고, 가용성 그룹을 마우스 오른쪽 단추로 클릭하고, 기타 작업을 선택한 다음, 종속성 보고서 표시를 선택합니다. 종속성이 올바르게 구성되면 가용성 그룹은 네트워크 이름에 종속되고 네트워크 이름은 IP 주소에 종속됩니다.
PowerShell에서 클러스터 매개 변수를 설정합니다.
a. 다음 PowerShell 스크립트를 SQL Server 인스턴스 중 하나에 복사합니다. 사용자 환경에 맞게 변수를 업데이트합니다.
$ClusterNetworkName은 네트워크를 선택하여 장애 조치(failover) 클러스터 관리자에서 이름을 찾습니다. 네트워크를 마우스 오른쪽 단추로 클릭하고 속성을 선택합니다. $ClusterNetworkName은 일반 탭의 이름 아래에 있습니다.$IPResourceName은 장애 조치(failover) 클러스터 관리자의 IP 주소 리소스에 지정된 이름입니다. 이 이름은 역할을 선택하여 장애 조치(failover) 클러스터 관리자에서 찾을 수 있습니다. SQL Server AG 또는 FCI 이름을 선택하고, 서버 이름 아래에서 리소스 탭을 선택하고, IP 주소 리소스를 마우스 오른쪽 단추로 클릭하고, 속성을 선택합니다. 올바른 값은 일반 탭의 이름 아래에 있습니다.$ListenerILBIP는 가용성 그룹 수신기에 대해 Azure 부하 분산 장치에서 만든 IP 주소입니다. SQL Server AG/FCI 수신기 리소스 이름과 동일한 속성 페이지의 장애 조치(failover) 클러스터 관리자에서 $ListenerILBIP를 찾습니다.$ListenerProbePort는 가용성 그룹 수신기에 대해 Azure 부하 분산 장치에서 구성한 포트(예: 59999)입니다. 사용하지 않는 모든 TCP 포트는 유효합니다.
$ClusterNetworkName = "<MyClusterNetworkName>" # The cluster network name. Use Get-ClusterNetwork on Windows Server 2012 or later to find the name. $IPResourceName = "<IPResourceName>" # The IP address resource name. $ListenerILBIP = "<n.n.n.n>" # The IP address of the internal load balancer. This is the static IP address for the load balancer that you configured in the Azure portal. [int]$ListenerProbePort = <nnnnn> Import-Module FailoverClusters Get-ClusterResource $IPResourceName | Set-ClusterParameter -Multiple @{"Address"="$ListenerILBIP";"ProbePort"=$ListenerProbePort;"SubnetMask"="255.255.255.255";"Network"="$ClusterNetworkName";"EnableDhcp"=0}b. 클러스터 노드 중 하나에서 PowerShell 스크립트를 실행하여 클러스터 매개 변수를 설정합니다.
참고
SQL Server 인스턴스가 별도의 지역에 있는 경우 PowerShell 스크립트를 두 번 실행해야 합니다. 먼저 첫 번째 지역에서
$ListenerILBIP및$ListenerProbePort값을 사용합니다. 다음으로 두 번째 지역에서$ListenerILBIP및$ListenerProbePort값을 사용합니다. 클러스터 네트워크 이름과 클러스터 IP 리소스 이름은 각 지역에 마다 다릅니다.가용성 그룹에 대한 클러스터 역할을 온라인 상태로 전환합니다. 장애 조치(failover) 클러스터 관리자의 역할에서 역할을 마우스 오른쪽 단추로 클릭한 다음, 역할 시작을 선택합니다.
필요한 경우 이전 단계를 반복하여 Windows Server 장애 조치 클러스터의 IP 주소에 대한 클러스터 매개 변수를 설정합니다.
Windows Server 장애 조치 클러스터의 IP 주소 이름을 가져옵니다. 장애 조치(failover) 클러스터 관리자의 클러스터 코어 리소스에서 서버 이름을 찾습니다.
IP 주소를 마우스 오른쪽 단추로 클릭한 다음, 속성을 선택합니다.
이름에서 IP 주소의 이름을 복사합니다. 클러스터 IP 주소일 수 있습니다.
PowerShell에서 클러스터 매개 변수를 설정합니다.
a. 다음 PowerShell 스크립트를 SQL Server 인스턴스 중 하나에 복사합니다. 사용자 환경에 맞게 변수를 업데이트합니다.
$ClusterCoreIP는 Windows Server 장애 조치 클러스터의 코어 클러스터 리소스에 대해 Azure 부하 분산 장치에서 만든 IP 주소입니다. 가용성 그룹 수신기의 IP 주소와는 다릅니다.$ClusterProbePort는 Windows Server 장애 조치 클러스터의 상태 프로브에 대해 Azure 부하 분산 장치에서 구성한 포트입니다. 가용성 그룹 수신기의 프로브와는 다릅니다.
$ClusterNetworkName = "<MyClusterNetworkName>" # The cluster network name. Use Get-ClusterNetwork on Windows Server 2012 or later to find the name. $IPResourceName = "<ClusterIPResourceName>" # The IP address resource name. $ClusterCoreIP = "<n.n.n.n>" # The IP address of the cluster IP resource. This is the static IP address for the load balancer that you configured in the Azure portal. [int]$ClusterProbePort = <nnnnn> # The probe port from WSFCEndPointprobe in the Azure portal. This port must be different from the probe port for the availability group listener. Import-Module FailoverClusters Get-ClusterResource $IPResourceName | Set-ClusterParameter -Multiple @{"Address"="$ClusterCoreIP";"ProbePort"=$ClusterProbePort;"SubnetMask"="255.255.255.255";"Network"="$ClusterNetworkName";"EnableDhcp"=0}b. 클러스터 노드 중 하나에서 PowerShell 스크립트를 실행하여 클러스터 매개 변수를 설정합니다.
49152에서 65536 사이(TCP/IP의 기본 동적 포트 범위)의 포트를 사용하도록 SQL 리소스가 구성된 경우 각 포트에 대한 제외를 추가합니다. 이러한 리소스에는 다음이 포함될 수 있습니다.
- SQL Server 데이터베이스 엔진
- Always On 가용성 그룹 수신기
- 장애 조치 클러스터 인스턴스에 대한 상태 프로브
- 데이터베이스 미러링 엔드포인트
- 클러스터 코어 IP 리소스
제외를 추가하면 다른 시스템 프로세스에 동적으로 동일한 포트가 할당되는 것을 방지할 수 있습니다. 이 시나리오의 경우 모든 클러스터 노드에서 다음 제외를 구성합니다.
netsh int ipv4 add excludedportrange tcp startport=58888 numberofports=1 store=persistentnetsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
포트가 사용되지 않는 경우 포트 제외를 구성하는 것이 중요합니다. 그렇지 않으면 “프로세스가 다른 프로세스에서 사용 중이므로 파일에 액세스할 수 없습니다.”와 같은 메시지와 함께 명령이 실패합니다. 제외가 올바르게 구성되었는지 확인하려면 netsh int ipv4 show excludedportrange tcp 명령을 사용합니다.
경고
가용성 그룹 수신기의 상태 프로브에 대한 포트는 클러스터 코어 IP 주소의 상태 프로브에 대한 포트와 달라야 합니다. 이러한 예제에서 수신기 포트는 59999이며 클러스터 코어 IP 주소의 상태 프로브 포트는 58888입니다. 두 포트는 모두 “인바운드” 방화벽 규칙을 허용해야 합니다.
수신기 포트 설정
SQL Server Management Studio에서 수신기 포트를 설정합니다.
SQL Server Management Studio를 열고 주 복제본에 연결합니다.
Always On 고가용성>가용성 그룹>가용성 그룹 수신기로 이동합니다.
장애 조치 클러스터 관리자에서 만든 수신기 이름을 마우스 오른쪽 단추로 클릭한 다음, 속성을 선택합니다.
포트 상자에서 가용성 그룹 수신기에 대한 포트 번호를 지정합니다. 기본값은 1433입니다. 확인을 선택합니다.
이제 Azure Resource Manager 모드에서 실행되는 Azure VM의 SQL Server에 대한 가용성 그룹이 있습니다.
수신기에 대한 연결 테스트
연결을 테스트하려면
RDP를 사용하여 동일한 가상 네트워크에 있지만 다른 복제본과 같은 복제본을 소유하지 않는 SQL Server VM에 연결합니다.
sqlcmd 유틸리티를 사용하여 연결을 테스트합니다. 예를 들어 다음 스크립트는 Windows 인증을 사용하여 수신기를 통해 주 복제본에 대한 sqlcmd 연결을 설정합니다.
sqlcmd -S <listenerName> -E수신기가 기본 포트(1433) 이외의 포트를 사용하는 경우 연결 문자열에서 포트를 지정합니다. 예를 들어 다음 명령은 1435 포트에서 수신기에 연결합니다.
sqlcmd -S <listenerName>,1435 -E
sqlcmd 유틸리티는 가용성 그룹의 현재 주 복제본인 SQL Server 인스턴스에 자동으로 연결됩니다.
팁
지정한 포트가 두 SQL Server VM의 방화벽에서 열려 있는지 확인합니다. 두 서버 모두 사용하는 TCP 포트에 대한 인바운드 규칙이 필요합니다. 자세한 내용은 방화벽 규칙 추가 또는 편집을 참조하세요.