Azure SQL 데이터 동기화는 무엇인가요?
적용 대상: ![]() Azure SQL Database
Azure SQL Database
Important
SQL 데이터 동기화는 2027년 9월 30일에 종료됩니다. 대체 데이터 복제/동기화 솔루션으로 마이그레이션하는 것이 좋습니다.
SQL 데이터 동기화는 온-프레미스 및 클라우드 모두의 여러 데이터베이스에서 양방향으로 선택한 데이터를 동기화할 수 있도록 Azure SQL Database에 구축된 서비스입니다.
Azure SQL 데이터 동기화는 Azure SQL Managed Instance 또는 Azure Synapse Analytics를 지원하지 않습니다.
개요
데이터 동기화는 동기화 그룹의 개념에 기반합니다. 동기화 그룹은 동기화하려는 데이터베이스 그룹입니다.
데이터 동기화는 허브 및 스포크 토폴로지를 사용하여 데이터를 동기화합니다. 동기화 그룹의 데이터베이스 중 하나를 허브 데이터베이스로 정의합니다. 나머지 데이터베이스는 구성원 데이터베이스입니다. 동기화는 허브와 개별 구성원 사이에서만 수행됩니다.
- 허브 데이터베이스는 Azure SQL Database여야 합니다.
- 구성원 데이터베이스는 Azure SQL Database 또는 SQL Server의 인스턴스에 있는 데이터베이스일 수 있습니다.
- 동기화 메타데이터 데이터베이스에는 데이터 동기화를 위한 메타데이터 및 로그가 포함됩니다. 동기화 메타데이터 데이터베이스는 허브 데이터베이스와 동일한 지역에 있는 Azure SQL Database여야 합니다. 동기화 메타데이터 데이터베이스는 고객이 생성하고 소유합니다. 동기화 메타데이터 데이터베이스는 지역 및 구독당 하나만 있을 수 있습니다. 동기화 그룹 또는 동기화 에이전트가 존재할 경우 동기화 메타데이터 데이터베이스를 삭제하거나 이름을 바꿀 수 없습니다. 동기화 메타데이터 데이터베이스로 사용할 비어 있는 새 데이터베이스를 생성하는 것이 좋습니다. 데이터 동기화는 이 데이터베이스에서 테이블을 생성하고 빈번한 워크로드를 실행합니다.
참고 항목
온-프레미스 데이터베이스를 구성원 데이터베이스로 사용하는 경우 로컬 동기화 에이전트를 설치 및 구성해야 합니다.
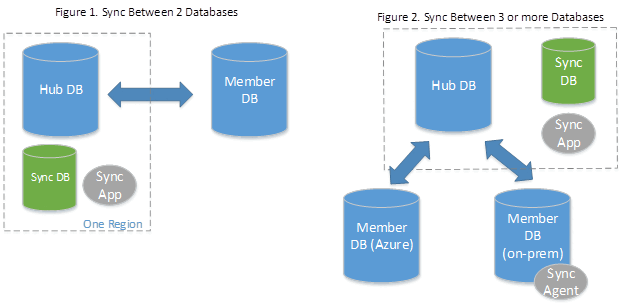
동기화 그룹에는 다음과 같은 속성이 있습니다.
- 동기화 스키마는 동기화할 데이터를 설명합니다.
- 동기화 방향은 양방향일 수도 있고 한 방향으로만 흐를 수도 있습니다. 즉, 동기화 방향은 허브에서 구성원, 구성원에서 허브 또는 둘 다일 수 있습니다.
- 동기화 간격은 동기화가 발생하는 빈도를 설명합니다.
- 충돌 해결 정책은 그룹 수준 정책으로, 허브 우선이거나 구성원 우선일 수 있습니다.
사용 시기
데이터 동기화는 Azure SQL Database 또는 SQL Server의 여러 데이터베이스에서 데이터를 최신 상태로 업데이트해야 하는 경우에 유용합니다. 데이터 동기화에 대한 주요 사용 사례는 다음과 같습니다.
- 하이브리드 데이터 동기화: 데이터 동기화를 사용하면 SQL Server의 데이터베이스와 Azure SQL Database 간에 데이터를 동기화하여 하이브리드 애플리케이션을 활성화할 수 있습니다. 이 기능은 클라우드로 이동하려는 고객에게 표시되고 Azure에 애플리케이션의 일부를 배치할 수 있습니다.
- 배포된 애플리케이션: 많은 경우 다양한 데이터베이스에서 다양한 워크로드를 구분하는 데 도움이 됩니다. 예를 들어 대형 프로덕션 데이터베이스가 있지만 이 데이터에 대한 보고 또는 분석 워크로드를 실행해야 하는 경우, 해당 추가 워크로드에 대한 두 번째 데이터베이스를 만드는 데 도움이 됩니다. 이 방법을 사용하면 프로덕션 워크로드에 미치는 영향을 최소화합니다. 데이터 동기화를 사용하여 이러한 두 데이터베이스의 동기화를 유지할 수 있습니다.
- 글로벌 분산 애플리케이션: 많은 비즈니스는 여러 지역, 심지어 여러 국가와 지역에서 활동합니다. 네트워크 대기 시간을 최소화하려면 가까운 지역에 데이터가 위치하는 것이 좋습니다. 데이터 동기화를 사용하면 전 세계 여러 지역에서 데이터베이스를 쉽게 동기화할 수 있습니다.
다음과 같은 시나리오에서 데이터 동기화는 기본 설정된 솔루션이 아닙니다.
| 시나리오 | 몇 가지 권장 솔루션 |
|---|---|
| 재해 복구 | Azure SQL Database의 자동 백업 |
| 읽기 확장 | 읽기 전용 복제본을 사용하여 읽기 전용 쿼리 워크로드의 오프로드 |
| ETL(OLTP 및 OLAP 간) | Azure Data Factory 또는 SQL Server Integration Services |
| SQL Server에서 Azure SQL Database로 마이그레이션 그러나, 마이그레이션이 완료된 후 SQL 데이터 동기화를 사용하여 원본과 대상이 동기화를 유지하도록 할 수 있습니다. | Azure Database Migration Service |
작동 방식
- 데이터 변경 내용 추적: 데이터 동기화는 삽입, 업데이트 및 삭제 트리거를 사용하여 변경 내용을 추적합니다. 변경 내용은 사용자 데이터베이스에 있는 추가 표에 기록됩니다. BULK INSERT는 기본값으로 트리거를 실행하지 않습니다. FIRE_TRIGGERS가 지정되지 않았으면 삽입 트리거가 실행되지 않습니다. 데이터 동기화 해당 삽입을 추적할 수 있도록 FIRE_TRIGGERS 옵션을 추가합니다.
- 데이터 동기화: 데이터 동기화는 허브 및 스포크 모델에서 설계됩니다. 허브는 개별적으로 각 구성원과 동기화됩니다. 허브의 변경 내용이 구성원에 다운로드된 다음 구성원의 변경 내용은 허브에 업로드됩니다.
- 충돌 해결: 데이터 동기화는 충돌 해결을 위해 허브 우선 또는 멤버 우선이라는 두 가지 옵션을 제공합니다.
- 사용자가 허브 우선을 선택하면 항상 허브의 변경 내용으로 구성원의 변경 내용을 덮어씁니다.
- 구성원 우선을 선택하면 구성원의 변경 내용으로 허브의 변경 내용을 덮어씁니다. 구성원이 둘 이상인 경우 최종 값은 먼저 동기화된 구성원에 따라 달라집니다.
트랜잭션 복제와 비교
| 데이터 동기화 | 트랜잭션 복제 | |
|---|---|---|
| 장점 | - 활성-활성 지원 - 온-프레미스 및 Azure SQL Database 간 양방향 |
- 낮은 대기 시간 - 트랜잭션 일관성 - 마이그레이션 후 기존 토폴로지 다시 사용 - Azure SQL Managed Instance 지원 |
| 단점 | - 트랜잭션 일관성 부족 - 성능에 더 많은 영향을 미침 |
- Azure SQL Database에서 게시할 수 없음 - 높은 유지 관리 비용 |
데이터 동기화를 위한 프라이빗 링크
참고 항목
SQL 데이터 동기화 프라이빗 링크는 Azure Private Link와 다릅니다.
새 프라이빗 링크 기능을 사용하면 데이터 동기화 프로세스 중 동기화 서비스와 구성원/허브 데이터베이스 사이의 보안 연결을 설정하기 위해 서비스 관리 프라이빗 엔드포인트를 선택할 수 있습니다. 서비스 관리 프라이빗 엔드포인트는 특정 가상 네트워크 및 서브넷 내의 개인 IP 주소입니다. 데이터 동기화 내에서 서비스 관리형 프라이빗 엔드포인트는 Microsoft에서 생성되며, 특정 동기화 작업을 위해 데이터 동기화 서비스에서 독점적으로 사용됩니다.
프라이빗 링크를 설정하기 전에 기능에 대한 일반 요구 사항을 참조하세요.

참고 항목
예, 동기화 그룹 배포 중에 또는 PowerShell을 사용하여 Azure Portal의 프라이빗 엔드포인트 연결 페이지에서 서비스 관리형 프라이빗 엔드포인트를 수동으로 승인해야 합니다.
시작하기
Azure Portal에서 데이터 동기화 설정
- 자습서: Azure SQL Database의 데이터베이스와 SQL Server 간에 SQL 데이터 동기화 설정
- Data Sync Agent - SQL 데이터 동기화용 Data Sync Agent
PowerShell을 사용하여 데이터 동기화 설정
- PowerShell을 사용하여 Azure SQL Database의 여러 데이터베이스 간에 데이터 동기화
- PowerShell을 사용하여 Azure SQL데이터베이스 및 SQL Server 간에 데이터 동기화
REST API를 사용하여 데이터 동기화 설정
데이터 동기화의 모범 사례 검토
문제가 발생한 경우
일관성 및 성능
최종 일관성
데이터 동기화는 트리거에 기반하므로 트랜잭션 일관성이 보장되지 않습니다. Microsoft는 결과적으로 모든 변경 내용을 적용하고 데이터 동기화가 데이터 손실을 발생하지 않도록 보장합니다.
성능에 미치는 영향
데이터 동기화는 삽입, 업데이트 및 삭제 트리거를 사용하여 변경 내용을 추적합니다. 변경 내용 추적을 위해 사용자 데이터베이스에 추가 테이블을 만듭니다. 이러한 변경 내용 추적 활동은 데이터베이스 워크로드에 영향을 줍니다. 서비스 계층을 평가하고 필요한 경우 업그레이드합니다.
동기화 그룹의 생성, 업데이트 및 삭제 중에 프로비전 및 프로비전 해제도 데이터베이스 성능에 영향을 줄 수 있습니다.
요구 사항 및 제한 사항
일반 요구 사항
- 각 표에는 기본 키가 있어야 합니다. 행에서 기본 키의 값을 변경하지 마세요. 기본 키 값을 변경해야 하는 경우 행을 삭제하고 새 기본 키 값으로 다시 생성합니다.
Important
기존 기본 키의 값을 변경하면 다음과 같은 잘못된 동작이 발생합니다.
- 동기화에서 문제를 보고하지 않더라도 허브와 구성원 사이에서 데이터는 손실될 수 있습니다.
- 기본 키 변경으로 인해 추적 테이블에 원본의 기존 행이 없으므로 동기화에 실패할 수 있습니다.
동기화 구성원 및 허브 모두에 대해 스냅샷 격리를 사용하도록 설정해야 합니다. 자세한 내용은 SQL Server에서의 스냅샷 격리를 참조하세요.
데이터 동기화 프라이빗 링크를 사용하려면 구성원 및 허브 데이터베이스 모두 동일한 클라우드 유형(예: 퍼블릭 클라우드 모두 또는 정부 클라우드 모두)으로 Azure(동일 또는 다른 지역)에 호스트되어야 합니다. 또한 프라이빗 링크를 사용하려면 허브 및 구성원 서비스를 호스트하는 구독에 대해
Microsoft.Network리소스 공급자를 등록해야 합니다. 마지막으로 Azure Portal의 “프라이빗 엔드포인트 연결” 섹션 내에서 또는 PowerShell을 통해 동기화 구성 중에 데이터 동기화에 대한 프라이빗 링크를 수동으로 승인해야 합니다. 프라이빗 링크를 승인하는 방법에 대한 자세한 내용은 자습서: Azure SQL Database 및 SQL Server의 데이터베이스 간에 SQL 데이터 동기화 설정을 참조하세요. 서비스 관리 프라이빗 엔드포인트를 승인한 후에는 동기화 서비스와 구성원/허브 데이터베이스 사이의 모든 통신이 프라이빗 링크를 통해 수행됩니다. 이 기능을 사용하도록 기존 동기화 그룹을 업데이트할 수 있습니다.
일반적인 제한 사항
- 테이블은 기본 키가 아닌 ID 열을 포함할 수 없습니다.
- 기본 키는 sql_variant, binary, varbinary, image, xml 데이터 형식을 포함할 수 없습니다.
- 지원되는 전체 자릿수가 보조 키에만 해당하므로 time, datetime, datetime2, datetimeoffset 같은 데이터 형식을 기본 키로 사용하는 경우 주의하세요.
- 개체(데이터베이스, 테이블 및 열) 이름에는 인쇄 가능한 문자 마침표(
.), 왼쪽 대괄호([) 또는 오른쪽 대괄호(])를 사용할 수 없습니다. - 테이블 이름에는 인쇄 가능한 문자(
! " # $ % ' ( ) * + -또는 공백)를 포함할 수 없습니다. - Microsoft Entra(이전의 Azure Active Directory) 인증은 지원되지 않습니다.
- 이름이 같지만 스키마가 다른 테이블이 있으면(예:
dbo.customers및sales.customers) 테이블 중 하나만 동기화에 추가할 수 있습니다. - 사용자 정의 데이터 형식이 있는 열은 지원되지 않습니다.
- 서로 다른 구독 간의 서버 이동은 지원되지 않습니다.
- 두 개의 기본 키만 다른 경우(예:
Foo및foo) 데이터 동기화에서 이 시나리오를 지원하지 않습니다. - 테이블 잘림은 데이터 동기화에서 지원되는 작업이 아닙니다(변경 내용은 추적되지 않음).
- Azure SQL 하이퍼스케일 데이터베이스를 허브 또는 동기화 메타데이터 데이터베이스로 사용하는 것은 지원되지 않습니다. 그러나 하이퍼스케일 데이터베이스는 데이터 동기화 토폴로지의 구성원 데이터베이스일 수 있습니다.
- 메모리 액세스에 최적화된 테이블은 지원되지 않습니다.
- 스키마 변경 사항은 자동으로 복제되지 않습니다. 스키마 변경 내용의 복제를 자동화하기 위해 사용자 지정 솔루션을 만들 수 있습니다.
- 데이터 동기화는 Unique, Clustered/Non-Clustered라는 두 가지 인덱스 속성만 지원합니다.
IGNORE_DUP_KEY또는WHERE필터 조건자와 같은 인덱스의 다른 속성은 지원되지 않으며, 소스 인덱스에 이러한 속성이 설정되어 있어도 대상 인덱스는 이러한 속성 없이 프로비저닝됩니다. - Azure 탄력적 작업 데이터베이스를 SQL 데이터 동기화 메타데이터 데이터베이스로 사용할 수 없으며 그 반대의 경우도 마찬가지입니다.
- SQL 데이터 동기화는 원장 데이터베이스에서 지원되지 않습니다.
지원되지 않는 데이터 형식
- FileStream
- SQL/CLR UDT
- XMLSchemaCollection(XML 지원)
- Cursor, RowVersion, Timestamp, Hierarchyid
지원되지 않는 열 형식
데이터 동기화는 읽기 전용 또는 시스템 생성 열을 동기화할 수 없습니다. 예시:
- 계산된 열.
- 임시 테이블에 대한 시스템 생성 열입니다.
서비스 및 데이터베이스 차원에 대한 제한 사항
| 차원 | 한도 | 해결 방법 |
|---|---|---|
| 모든 데이터베이스가 속할 수 있는 최대 동기화 그룹 수입니다. | 5 | |
| 단일 동기화 그룹에서 엔드포인트의 최대 수 | 30 | |
| 단일 동기화 그룹에서 온-프레미스 엔드포인트의 최대 수입니다. | 5 | 여러 동기화 그룹 만들기 |
| 데이터베이스, 테이블, 스키마 및 열 이름 | 이름당 50자 | |
| 동기화 그룹의 테이블 | 500 | 여러 동기화 그룹 만들기 |
| 동기화 그룹의 테이블 열 | 1000 | |
| 테이블의 데이터 행 크기 | 24Mb |
참고 항목
동기화 그룹이 하나뿐인 경우 단일 동기화 그룹에 최대 30개의 엔드포인트가 있을 수 있습니다. 둘 이상의 동기화 그룹이 있는 경우 모든 동기화 그룹의 총 엔드포인트 수는 30개를 초과할 수 없습니다. 데이터베이스가 여러 동기화 그룹에 속하는 경우 하나가 아닌 여러 엔드포인트로 계산됩니다.
네트워크 요구 사항
참고 항목
동기화 프라이빗 링크를 사용하는 경우 이러한 네트워크 요구 사항이 적용되지 않습니다.
동기화 그룹이 설정되었으면 데이터 동기화 서비스를 허브 데이터베이스에 연결해야 합니다. 동기화 그룹을 설정할 때 Azure SQL Server는 해당 Firewalls and virtual networks 설정에 다음 구성을 포함해야 합니다.
- 공용 네트워크 액세스 거부는 해제로 설정해야 합니다.
- Azure 서비스 및 리소스가 이 서버에 액세스하도록 허용하려면 예로 설정하거나 데이터 동기화 서비스에서 사용하는 IP 주소에 대한 IP 규칙을 생성해야 합니다.
동기화 그룹을 생성하고 프로비전한 후에 이 설정을 사용하지 않도록 설정할 수 있습니다. 동기화 에이전트는 허브 데이터베이스에 직접 연결되며, 서버의 방화벽 IP 규칙 또는 프라이빗 엔드포인트를 사용하여 에이전트가 허브 서버에 액세스하도록 할 수 있습니다.
참고 항목
동기화 그룹의 스키마 설정을 변경하는 경우, 허브 데이터베이스를 다시 프로비전할 수 있도록 데이터 동기화 서비스가 서버에 액세스하도록 허용해야 합니다.
지역 데이터 보존
동일한 지역 내에 있는 데이터를 동기화하는 경우 SQL 데이터 동기화는 서비스 인스턴스가 배포된 지역 외부에 있는 고객 데이터를 저장/처리하지 않습니다. 여러 지역에서 데이터를 동기화하는 경우 SQL 데이터 동기화는 고객 데이터를 쌍을 이루는 지역에 복제합니다.
SQL 데이터 동기화에 대한 FAQ
SQL 데이터 동기화 서비스의 요금은 얼마인가요?
SQL 데이터 동기화 서비스 자체에는 요금이 부과되지 않습니다. 그러나 SQL Database 인스턴스 내부 및 외부로의 데이터 이동에 대해 데이터 전송 요금이 계속 청구됩니다. 자세한 내용은 데이터 전송 요금을 참조하세요.
데이터 동기화를 지원하는 지역은 무엇인가요?
SQL 데이터 동기화는 모든 지역에서 사용할 수 있습니다.
SQL Database 계정이 필요한가요?
예. 허브 데이터베이스를 호스트하려면 SQL Database 계정이 필요합니다.
데이터 동기화를 사용하여 SQL Server 데이터베이스 사이에서만 동기화할 수 있나요?
직접 끌 수는 없습니다. 그러나 Azure에서 허브 데이터베이스를 생성한 다음, 온-프레미스 데이터베이스를 동기화 그룹에 추가하여 간접적으로 SQL Server 데이터베이스 사이에서 동기화할 수 있습니다.
데이터 동기화를 구성해서 서로 다른 구독에 속해 있는 Azure SQL Database의 데이터베이스 간에 동기화를 수행할 수 있나요?
예. 구독이 다른 테넌트에 속해 있는 경우에도 다른 구독에서 소유한 리소스 그룹에 속한 데이터베이스 간에 동기화를 구성할 수 있습니다.
- 구독이 동일한 테넌트에 속하며 모든 구독에 대해 사용 권한이 있는 경우, Azure Portal에서 동기화 그룹을 구성할 수 있습니다.
- 그렇지 않으면 PowerShell을 사용하여 동기화 멤버를 추가해야 합니다.
데이터 동기화를 설정해서 서로 다른 클라우드(예: Azure 퍼블릭 클라우드 및 21Vianet 지원 Azure)에 속해 있는 SQL Database의 데이터베이스 간에 동기화를 수행할 수 있나요?
예. 다른 클라우드에 속하는 데이터베이스 간에 동기화를 설정할 수 있습니다. PowerShell을 사용하여 서로 다른 구독에 속하는 동기화 멤버를 추가해야 합니다.
데이터 동기화를 사용하여 프로덕션 데이터베이스에서 빈 데이터베이스로 데이터를 시드한 다음, 동기화할 수 있나요?
예. 원본에서 스크립팅하여 수동으로 새 데이터베이스에 스키마를 만듭니다. 스키마를 생성한 후 동기화 그룹에 테이블을 추가하여 데이터를 복사하고 동기화된 상태로 유지합니다.
내 데이터베이스를 백업 및 복원하는 데 SQL 데이터 동기화를 사용해야 할까요?
SQL 데이터 동기화를 사용하여 데이터의 백업을 생성하는 작업은 권장되지 않습니다. SQL 데이터 동기화에서는 동기화의 버전이 지정되지 않으므로 특정 시점으로 백업하고 복원할 수 없습니다. 또한, SQL 데이터 동기화는 저장 프로시저와 같은 다른 SQL 개체를 백업하지 않고, 복원 작업과 동급의 작업을 빠르게 수행하지 못합니다.
권장되는 백업 방법 중 하나는 Azure SQL Database에서 트랜잭션이 일관된 데이터베이스 복사본 복사를 참조하세요.
데이터 동기화로 암호화된 테이블 및 열을 동기화할 수 있나요?
- 데이터베이스에서 Always Encrypted를 사용하는 경우 암호화되지 않은 테이블 및 열만 동기화할 수 있습니다. 데이터 동기화는 데이터 암호를 해독할 수 없으므로 암호화된 열을 동기화할 수 없습니다.
- 열에서 CLE(열 수준 암호화)를 사용하는 경우, 행 크기가 최대 크기인 24Mb보다 작기만 하면 열을 동기화할 수 있습니다. 데이터 동기화는 키로 암호화된 열(CLE)을 일반 이진 데이터로 처리합니다. 다른 동기화 구성원에서 데이터 암호를 해독하려면 동일한 인증서가 있어야 합니다.
SQL 데이터 동기화에서 데이터 정렬을 지원하나요?
예. SQL 데이터 동기화는 다음 시나리오에서 데이터 정렬 설정 구성을 지원합니다.
- 선택한 동기화 스키마 테이블이 허브 또는 구성원 데이터베이스에 아직 없는 경우 동기화 그룹을 배포할 때 서비스는 빈 목적지 데이터베이스에서 데이터 정렬 설정이 선택된 해당 테이블과 열을 자동으로 생성합니다.
- 동기화할 테이블이 사용자의 허브와 구성원 데이터베이스에 이미 포함되어 있다면, 허브와 구성원 데이터베이스의 기본 키 열이 동일한 데이터 정렬을 갖는 경우에만 동기화 그룹이 성공적으로 배포됩니다. 기본 키 열 이외의 열에는 데이터 정렬 제한 사항이 없습니다.
SQL 데이터 동기화에서 페더레이션이 지원되나요?
페더레이션 루트 데이터베이스는 제한 사항 없이 SQL 데이터 동기화 서비스에서 사용할 수 있습니다. 페더레이션된 데이터베이스 엔드포인트는 현재 버전의 SQL 데이터 동기화에 추가할 수 없습니다.
데이터 동기화를 사용하여 BYOD(Bring Your Own Database) 기능을 통해 Dynamics 365에서 내보낸 데이터를 동기화할 수 있나요?
Dynamics 365에서는 고유의 데이터베이스 기능을 사용하여 관리자가 애플리케이션에서 자체 Microsoft Azure SQL Database로 데이터 엔터티를 내보낼 수 있습니다. 증분 푸시를 사용하여 데이터를 내보내고(전체 푸시가 지원되지 않음) 대상 데이터베이스에서 트리거 사용을 예로 설정한 경우 데이터 동기화를 사용하여 이 데이터를 다른 데이터베이스에 동기화할 수 있습니다.
장애 조치(failover) 그룹에서 재해 복구를 지원하는 데이터 동기화를 만들려면 어떻게 해야 하나요?
- 장애 조치(failover) 지역의 데이터 동기화 작업이 주 지역과 동등하도록 하려면 장애 조치(failover) 후 주 지역과 동일한 설정을 사용하여 장애 조치(failover) 지역에서 동기화 그룹을 수동으로 다시 만들어야 합니다.
관련 콘텐츠
동기화된 데이터베이스의 스키마 업데이트
동기화 그룹에서 데이터베이스의 스키마를 업데이트해야 하나요? 스키마 변경 사항은 자동으로 복제되지 않습니다. 일부 솔루션의 경우 다음 문서를 참조하세요.
모니터링 및 문제 해결
SQL 데이터 동기화가 예상대로 수행되고 있나요? 활동을 모니터링하고 문제를 해결하려면 다음 문서를 참조하세요.
Azure SQL Database에 대해 자세히 알아보기
Azure SQL Database에 대한 자세한 내용은 다음 문서를 참조하세요.