Dapper로 탄력적 데이터베이스 클라이언트 라이브러리 사용하기
적용 대상: ![]() Azure SQL Database
Azure SQL Database
이 문서는 Dapper를 기반으로 애플리케이션을 작성하는 개발자뿐만 아니라 데이터 계층 규모를 확장하도록 분할을 구현하는 애플리케이션을 만들기 위해 탄력적 데이터베이스 도구를 받아들이려는 개발자를 대상으로 합니다. 이 문서에서는 탄력적 데이터베이스 도구와 통합하기 위해 필요한 Dapper 기반 애플리케이션의 변경 사항을 설명합니다. 여기서는 Dapper를 사용하여 탄력적 데이터베이스 분할 관리 및 데이터 종속 라우팅을 작성하는 방법에 대해 중점적으로 설명합니다.
샘플 코드: Azure SQL Database - Dapper 통합에 대한 Elastic Database 도구.
Dapper와 DapperExtensions는 Azure SQL Database의 탄력적 데이터베이스 클라이언트와 쉽게 통합할 수 있습니다. 애플리케이션에서는 새로운 SqlConnection 개체를 만들고 열 때 클라이언트 라이브러리의 OpenConnectionForKey 호출을 사용하도록 변경하여 데이터 종속 라우팅을 사용할 수 있습니다. 이 경우 애플리케이션에서 새 연결을 만들고 열 때만 해당 호출을 사용하도록 변경됩니다.
Dapper 개요
Dapper 는 개체 관계형 매퍼입니다. 애플리케이션의 .NET 개체와 관계형 데이터베이스를 서로 매핑합니다. 샘플 코드의 첫 부분에서는 탄력적 데이터베이스 클라이언트 라이브러리를 Dapper 기반 애플리케이션과 통합할 수 있는 방법을 보여 줍니다. 그리고 두 번째 부분에서는 Dapper와 DapperExtensions를 통합하는 방법이 나와 있습니다.
Dapper의 매퍼 기능은 데이터베이스 쿼리 또는 실행을 위해 T-SQL 문을 전송하는 과정을 간소화하는 확장 메서드를 데이터베이스 연결에 대해 제공합니다. 예를 들어 Dapper를 사용하면 Execute 호출을 위한 SQL 문의 매개 변수와 .NET 개체 간 매핑을 쉽게 수행하거나 Dapper에서 Query 호출을 사용하여 SQL 쿼리의 결과를 .NET 개체에 사용할 수 있습니다.
DapperExtensions를 사용할 때는 더 이상 SQL 문을 입력하지 않아도 됩니다. 데이터베이스 연결에 대해 GetList, Insert 등의 확장 메서드를 사용하는 경우 SQL 문이 백그라운드에서 작성됩니다.
Dapper 및 DapperExtensions를 사용할 때 또 다른 이점은 애플리케이션의 데이터베이스 연결 작성을 제어한다는 것입니다. 따라서 데이터베이스에 대한 shardlet 매핑을 기준으로 데이터베이스 연결을 조정하는 탄력적 데이터베이스 클라이언트 라이브러리와 상호 작용이 가능합니다.
Dapper 어셈블리를 확인하려면 Dapper.net을 참조하세요. Dapper 확장은 DapperExtensions를 참조하세요.
탄력적 데이터베이스 클라이언트 라이브러리를 간단히 살펴보기
탄력적 데이터베이스 클라이언트 라이브러리를 사용하면 shardlets라는 애플리케이션 데이터 파티션을 정의하여 데이터베이스에 매핑한 다음, 분할 키로 식별할 수 있습니다. 데이터베이스는 필요한 수만큼 포함할 수 있으며 이러한 데이터베이스에 대해 shardlet을 배포할 수 있습니다. 라이브러리의 API에서 제공하는 분할된 데이터베이스 맵을 통해 데이터베이스에 대한 분할 키 값의 매핑이 저장됩니다. 이 기능을 분할된 데이터베이스 맵 관리라고 합니다. 분할된 데이터베이스 맵은 분할 키를 전송하는 요청에 대한 데이터베이스 연결의 브로커 역할도 합니다. 이 기능을 데이터 종속 라우팅이라고 합니다.
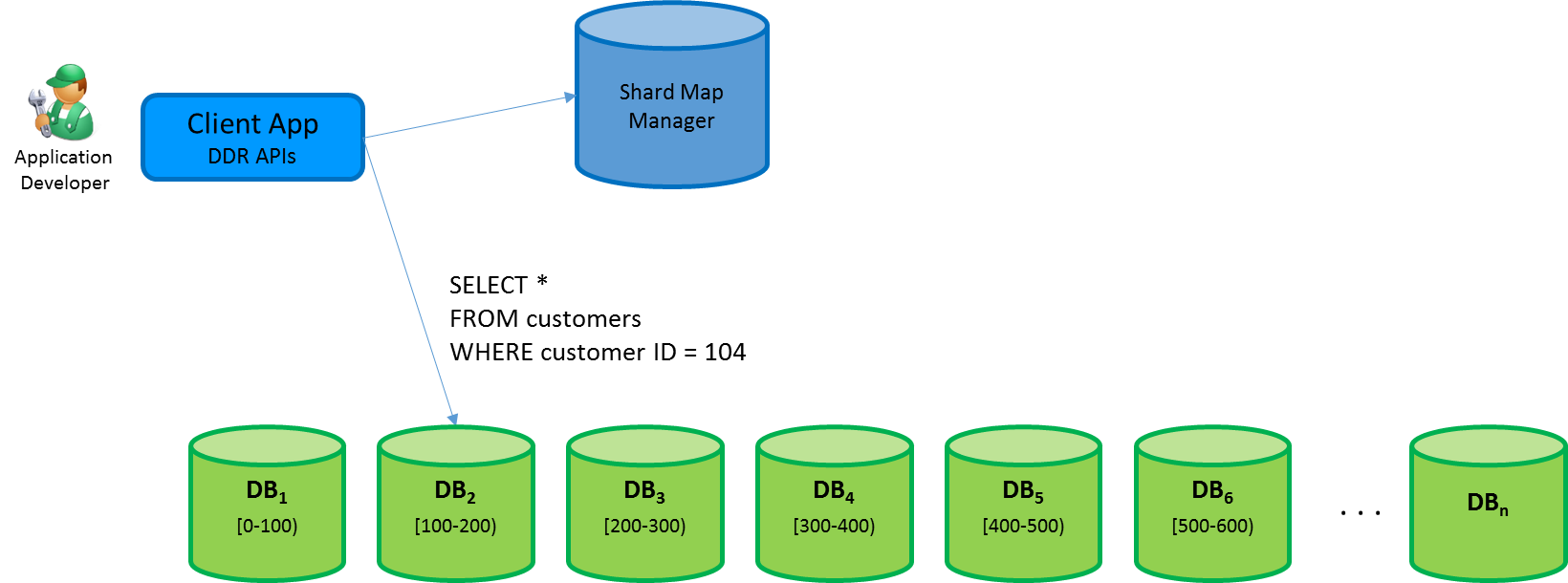
분할된 데이터베이스 맵 관리자는 동시 shardlet 관리 작업이 수행될 때 데이터베이스에서 발생할 수 있는 shardlet 데이터 뷰 불일치 현상을 방지합니다. 이를 위해, 분할된 데이터베이스 맵이 라이브러리내의 기존 애플리케이션용 데이터베이스 연결을 조정합니다. 분할된 데이터베이스 관리 작업 수행 시 shardlet이 영향을 받을 수 있는 경우 분할된 데이터베이스 맵 기능은 데이터베이스 연결을 자동으로 종료할 수 있습니다.
따라서 Dapper에 대한 연결을 만드는 기존 방식을 사용하는 대신 OpenConnectionForKey 메서드를 사용해야 합니다. 이 메서드를 사용하면 분할된 데이터베이스 간 데이터가 이동할 때 모든 유효성 검사가 수행되며 연결이 제대로 관리됩니다.
Dapper 통합을 위한 요구 사항
탄력적 데이터베이스 클라이언트 라이브러리와 Dapper API를 모두 사용할 때는 다음 속성을 유지해야 합니다.
- 규모 확장: 애플리케이션의 용량 요구 사항에 따라 분할된 애플리케이션의 데이터 계층에서 데이터베이스를 필요한 만큼 추가하거나 제거합니다.
- 일관성: 애플리케이션은 분할을 사용하여 규모가 확장되므로 데이터 종속 라우팅을 수행해야 합니다. 이를 위해 라이브러리의 데이터 종속 라우팅 기능을 사용합니다. 특히 손상이나 잘못된 쿼리 결과를 방지하기 위해 분할된 데이터베이스 맵을 통해 조정되는 연결에서 보장하는 유효성 검사 및 일관성을 유지해야 합니다. 이렇게 하면 예를 들어 지정된 shardlet이 분할/병합 API를 사용하여 현재 다른 분할된 데이터베이스로 이동되어 있는 경우 해당 shardlet에 대한 연결이 거부되거나 중지됩니다.
- 개체 매핑: 애플리케이션의 클래스와 기본 데이터베이스 구조 간 변환을 수행하기 위해 Dapper에서 제공하는 편리한 매핑 기능을 유지합니다.
다음 섹션에서는 Dapper 및 DapperExtensions를 기반으로 하는 애플리케이션에 대한 이러한 요구 사항 관련 지침을 제공합니다.
기술 지침
Dapper를 사용한 데이터 종속 라우팅
Dapper를 사용하는 경우 대개 애플리케이션에서 기본 데이터베이스에 대한 연결을 만들고 엽니다. Dapper는 T 형식 .NET 컬렉션으로 쿼리 결과를 반환합니다(애플리케이션에서 T 형식을 지정함). Dapper는 T-SQL 결과 행에서 T 형식 개체로의 매핑을 수행합니다. 마찬가지로 Dapper는 .NET 개체를 DML(데이터 조작 언어) 문의 SQL 값이나 매개 변수로 매핑합니다. Dapper는 ADO.NET SQL 클라이언트 라이브러리의 일반 SqlConnection 개체에 대한 확장 메서드를 통해 이 기능을 제공합니다. DDR용 탄력적인 확장 API에서 반환하는 SQL 연결도 일반 SqlConnection 개체입니다. 따라서 클라이언트 라이브러리의 DDR API에서 반환하는 형식은 단순 SQL 클라이언트 연결이기도 하므로 이 형식에 대해 Dapper 확장을 직접 사용할 수 있습니다.
이와 같이 확인된 정보를 통해 탄력적 데이터베이스 클라이언트 라이브러리에서 조정하는 연결을 Dapper에 쉽게 사용할 수 있습니다.
함께 제공되는 샘플에 포함된 이 코드 예제에서는 연결을 올바르게 분할된 데이터베이스로 조정하기 위해 애플리케이션에서 라이브러리에 분할 키를 제공하는 방식을 보여 줍니다.
using (SqlConnection sqlconn = shardingLayer.ShardMap.OpenConnectionForKey(
key: tenantId1,
connectionString: connStrBldr.ConnectionString,
options: ConnectionOptions.Validate))
{
var blog = new Blog { Name = name };
sqlconn.Execute(@"
INSERT INTO
Blog (Name)
VALUES (@name)", new { name = blog.Name }
);
}
OpenConnectionForKey API 호출에서 SQL 클라이언트 연결의 기본 만들기 및 열기가 바뀝니다. OpenConnectionForKey 호출은 데이터 종속 라우팅에 필요한 다음과 같은 인수를 사용합니다.
- 데이터 종속 라우팅 인터페이스에 액세스하는 분할된 데이터베이스 맵
- shardlet을 식별하는 분할 키
- 분할된 데이터베이스에 연결하기 위한 자격 증명(사용자 이름 및 암호)
분할된 데이터베이스 맵 개체는 지정된 분할 키용 shardlet을 포함하는 분할된 데이터베이스에 대한 연결을 만듭니다. 또한 탄력적 데이터베이스 클라이언트 API는 일관성을 보장하기 위해 연결에 태그를 지정합니다. OpenConnectionForKey 호출에서는 일반 SQL 클라이언트 연결 개체를 반환하므로 Dapper에서 후속 Execute 확장 메서드를 호출할 때는 표준 Dapper 방식을 따릅니다.
쿼리는 거의 비슷한 방식으로 작동합니다. 즉, 먼저 탄력적인 확장 API에서 OpenConnectionForKey를 사용하여 연결을 엽니다. 그런 다음 일반 Dapper 확장 메서드를 사용하여 SQL 쿼리 결과를 .NET 개체에 매핑합니다.
using (SqlConnection sqlconn = shardingLayer.ShardMap.OpenConnectionForKey(
key: tenantId1,
connectionString: connStrBldr.ConnectionString,
options: ConnectionOptions.Validate ))
{
// Display all Blogs for tenant 1
IEnumerable<Blog> result = sqlconn.Query<Blog>(@"
SELECT *
FROM Blog
ORDER BY Name");
Console.WriteLine("All blogs for tenant id {0}:", tenantId1);
foreach (var item in result)
{
Console.WriteLine(item.Name);
}
}
DDR 연결이 포함된 using 블록에서는 블록 내의 모든 데이터베이스 작업 범위가 tenantId1이 저장된 분할된 데이터베이스 하나로 지정됩니다. 이 쿼리는 현재 분할된 데이터베이스에 저장되어 있는 블로그만 반환하며 다른 분할된 데이터베이스에 저장된 블로그는 반환하지 않습니다.
Dapper 및 DapperExtensions를 사용한 데이터 종속 라우팅
Dapper에는 데이터베이스 애플리케이션을 개발할 때 데이터베이스에서 추가적인 편의 기능과 추상화를 제공할 수 있는 추가 확장 에코시스템이 포함되어 있습니다. 이러한 기능의 한 가지 예가 DapperExtensions입니다.
애플리케이션에서 DapperExtensions를 사용하더라도 데이터베이스 연결 작성 및 관리 방식은 변경되지 않습니다. 즉, 애플리케이션이 계속 연결을 열며 확장 메서드에는 일반 SQL 클라이언트 연결 개체가 사용됩니다. 위에서 설명한 것처럼 OpenConnectionForKey 를 사용할 수 있습니다. 다음 코드 샘플에서 볼 수 있듯이 유일한 변경 사항은 더 이상 T-SQL 문을 작성할 필요가 없다는 것입니다.
using (SqlConnection sqlconn = shardingLayer.ShardMap.OpenConnectionForKey(
key: tenantId2,
connectionString: connStrBldr.ConnectionString,
options: ConnectionOptions.Validate))
{
var blog = new Blog { Name = name2 };
sqlconn.Insert(blog);
}
쿼리의 코드 샘플은 다음과 같습니다.
using (SqlConnection sqlconn = shardingLayer.ShardMap.OpenConnectionForKey(
key: tenantId2,
connectionString: connStrBldr.ConnectionString,
options: ConnectionOptions.Validate))
{
// Display all Blogs for tenant 2
IEnumerable<Blog> result = sqlconn.GetList<Blog>();
Console.WriteLine("All blogs for tenant id {0}:", tenantId2);
foreach (var item in result)
{
Console.WriteLine(item.Name);
}
}
일시적인 오류 처리
Microsoft Patterns & Practices 팀은 애플리케이션 개발자들이 클라우드에서 실행 시에 일반적으로 발생하는 일시적인 오류 상황을 완화할 수 있도록 일시적인 오류 처리 응용 프로그램 블록을 게시했습니다. 더 자세한 정보는 인내, 모든 승리의 비밀: 일시적인 오류 처리 애플리케이션 블록 사용(영문)을 참조하세요.
코드 샘플에서는 일시적인 오류 라이브러리를 사용하여 일시적인 오류를 방지합니다.
SqlDatabaseUtils.SqlRetryPolicy.ExecuteAction(() =>
{
using (SqlConnection sqlconn =
shardingLayer.ShardMap.OpenConnectionForKey(tenantId2, connStrBldr.ConnectionString, ConnectionOptions.Validate))
{
var blog = new Blog { Name = name2 };
sqlconn.Insert(blog);
}
});
위 코드의 SqlDatabaseUtils.SqlRetryPolicy는 다시 시도 횟수가 10이고 다시 시도 간의 대기 시간이 5초인 SqlDatabaseTransientErrorDetectionStrategy로 정의됩니다. 트랜잭션을 사용하는 경우에는 일시적인 오류 발생 시 다시 시도 범위를 트랜잭션 시작 위치로 설정해야 합니다.
제한 사항
이 문서에서 설명하는 접근 방식에는 몇 가지 제한 사항이 따릅니다.
- 이 문서의 샘플 코드에서는 분할된 데이터베이스 간에 스키마를 관리하는 방법을 설명하지 않습니다.
- 요청이 있는 경우 모든 데이터베이스 처리가 요청에서 제공된 분할 키로 식별되는 단일 분할된 데이터베이스에 포함된다고 가정합니다. 그러나 분할 키를 제공할 수 없는 등의 경우도 있으므로 이 가정이 항상 적용되는 것은 아닙니다. 이를 해결하려면 탄력적 데이터베이스 클라이언트 라이브러리가 MultiShardQuery class를 포함해야 합니다. 이 클래스는 여러 분할된 데이터베이스에 대한 쿼리를 위해 연결 추상화를 구현합니다. MultiShardQuery와 Dapper를 함께 사용하는 방법에 대해서는 이 문서에서 설명하지 않습니다.
결론
Dapper 및 DapperExtensions를 사용하는 애플리케이션에서는 Azure SQL Database의 탄력적 데이터베이스 도구를 쉽게 활용할 수 있습니다. 이 문서에서 대략적으로 설명한 단계를 수행하면 이러한 애플리케이션은 새로운 SqlConnection 개체를 만들고 열 때 탄력적 데이터베이스 클라이언트 라이브러리의 OpenConnectionForKey 호출을 사용하도록 변경하여 도구의 데이터 종속 라우팅 기능을 사용할 수 있습니다. 이 경우 애플리케이션에서 새 연결을 만들고 여는 위치에서만 해당 호출을 사용하도록 변경하면 됩니다.
관련 콘텐츠
아직 탄력적인 데이터베이스 도구를 사용 하지 않나요? 시작 가이드를 확인합니다. 질문이 있는 경우 SQL Database에 대한 Microsoft Q&A 질문 페이지에서 문의하고, 기능 요청이 있는 경우 SQL Database 사용자 의견 포럼에서 새로운 아이디어를 추가하거나 기존 아이디어에 투표해 주세요.