Azure Durable Functions의 재해 복구 및 지역 배포
Microsoft는 Azure 서비스를 항상 사용할 수 있도록 하기 위해 노력합니다. 그러나 계획되지 않은 서비스 중단이 발생할 수 있습니다. 애플리케이션에 복원력이 필요한 경우 지역 중복을 위해 앱을 구성하는 것이 좋습니다. 또한 고객은 지역 서비스 중단을 처리하기 위해 재해 복구 계획을 설정하는 것이 좋습니다. 재해 복구 계획의 중요한 부분은 주 복제본을 사용할 수 없게 되는 경우 앱과 스토리지의 보조 복제본으로 장애 조치(failover)를 준비하는 것입니다.
Durable Functions에서 모든 상태는 기본적으로 Azure Storage에 보관됩니다. 작업 허브는 오케스트레이션 및 엔터티에 사용되는 Azure Storage 리소스의 논리적 컨테이너입니다. 오케스트레이터, 작업, 엔터티 함수는 동일한 작업 허브에 속하는 경우에만 상호 작용할 수 있습니다. 이 문서에서는 Azure Storage 리소스의 가용성을 높은 수준으로 유지하기 위한 시나리오를 설명할 때 작업 허브를 참조합니다.
참고 항목
이 문서의 지침에서는 기본 Azure Storage 공급자를 사용하여 Durable Functions 런타임 상태를 저장한다고 가정합니다. 그러나 SQL Server 데이터베이스와 같이 상태를 다른 곳에 저장하는 대체 스토리지 공급자를 구성할 수 있습니다. 대체 스토리지 공급자에는 다른 재해 복구 및 지역 배포 전략이 필요할 수 있습니다. 대체 스토리지 공급자에 대한 자세한 내용은 Durable Functions 스토리지 공급자 설명서를 참조하세요.
오케스트레이션과 엔터티는 HTTP를 통해 자체적으로 트리거된 클라이언트 함수 또는 다른 지원되는 Azure Functions 트리거 형식 중 하나를 사용하여 트리거될 수 있습니다. 기본 제공 HTTP API를 사용하여 트리거될 수도 있습니다. 간단히 하기 위해 이 문서에서는 Azure Storage 및 HTTP 기반 함수 트리거와 관련된 시나리오 및 가용성을 높이고 재해 복구 작업 중 가동 중지 시간을 최소화하는 옵션을 중점적으로 설명합니다. Service Bus 또는 Azure Cosmos DB 트리거와 같은 다른 트리거 형식은 명시적으로 다루지 않습니다.
다음 시나리오는 Azure Storage를 사용하여 진행되므로 활성-수동 구성을 기반으로 합니다. 이 패턴은 다른 지역으로의 백업(수동) 함수 앱 배포로 구성됩니다. Traffic Manager는 기본(활성) 함수 앱의 HTTP 가용성을 모니터링합니다. 기본 함수 앱이 실패하면 백업 함수 앱으로 장애 조치(Failover)됩니다. 자세한 내용은 Azure Traffic Manager의 우선 순위 트래픽 라우팅 방법을 참조하세요.
참고 항목
- 제안된 활성-수동 구성은 클라이언트가 항상 HTTP를 통해 새 오케스트레이션을 트리거할 수 있도록 합니다. 그러나 스토리지에서 동일한 작업 허브를 공유하는 두 개의 함수 앱이 구현되므로 둘 간에 일부 백그라운드 스토리지 트랜잭션이 분산됩니다. 따라서 이 구성에서는 보조 함수 앱을 위한 추가 송신 비용이 발생합니다.
- 기본 스토리지 계정 및 작업 허브가 기본 지역에 생성되고 두 함수 앱에서 공유됩니다.
- 중복 배포된 모든 함수 앱은 HTTP를 통해 활성화될 경우 동일한 함수 액세스 키를 공유해야 합니다. 함수 런타임은 소비자가 프로그래밍 방식으로 함수 키를 추가, 삭제 및 업데이트할 수 있도록 하는 관리 API를 노출합니다. Azure Resource Manager API를 사용하여 키를 관리할 수도 있습니다.
시나리오 1 - 공유 스토리지에서 컴퓨팅 부하 분산
Azure의 컴퓨팅 인프라가 실패하면 함수 앱을 사용하지 못할 수 있습니다. 이러한 작동 중단 가능성을 최소화하기 위해 이 시나리오에서는 다른 지역에 배포된 두 개의 함수 앱을 사용합니다. Traffic Manager는 기본 함수 앱의 문제를 감지하고, 보조 지역의 함수 앱으로 트래픽을 자동으로 리디렉션하도록 구성됩니다. 이 함수 앱은 동일한 Azure Storage 계정 및 작업 허브를 공유합니다. 따라서 함수 앱의 상태는 손실되지 않으며 정상적으로 다시 시작될 수 있습니다. 기본 지역의 상태가 복원되면 Azure Traffic Manager는 해당 함수 앱으로의 요청 라우팅을 자동으로 시작합니다.

이 배포 시나리오를 사용할 경우 다음과 같은 몇 가지 이점을 얻을 수 있습니다.
- 컴퓨팅 인프라에 장애가 발생할 경우 장애 조치(failover) 지역에서 데이터 손실 없이 계속할 수 있습니다.
- Traffic Manager는 정상 상태의 함수 앱으로 자동 장애 조치(Failover)가 수행되도록 합니다.
- Traffic Manager는 작동 중단이 해결된 후에 기본 함수 앱으로의 트래픽을 자동으로 다시 설정합니다.
그러나 이 시나리오를 사용할 때에는 다음을 고려하세요.
- 함수 앱이 전용 App Service 요금제를 사용하여 배포된 경우 장애 조치(failover) 데이터 센터에서 컴퓨팅 인프라를 복제하면 비용이 늘어납니다.
- 이 시나리오에서는 컴퓨팅 인프라의 작동 중단을 다루지만, 스토리지 계정이 계속해서 함수 앱에 대한 단일 실패 지점이 될 수 있습니다. 스토리지가 중단되면 애플리케이션 가동이 중지됩니다.
- 함수 앱이 장애 조치(Failover)되면 여러 지역에 걸쳐 해당 스토리지 계정에 액세스하게 되므로 대기 시간이 증가합니다.
- 다른 지역에 있는 스토리지 서비스에 액세스하게 되면 네트워크 송신 트래픽으로 인해 더 높은 비용이 발생합니다.
- 이 시나리오는 Traffic Manager에 따라 달라집니다. Traffic Manager 작동 방식을 고려한다면 약간의 시간이 경과된 후에, 지속형 함수를 사용하는 클라이언트 애플리케이션이 Traffic Manager에서 함수 앱 주소를 다시 쿼리해야 할 필요가 발생할 수 있습니다.
참고 항목
Durable Functions 확장 v2.3.0부터 동일한 스토리지 계정 및 작업 허브 구성을 사용하여 두 함수 앱을 동시에 안전하게 실행할 수 있습니다. 시작할 첫 번째 앱은 다른 앱이 작업 허브 큐에서 메시지를 도용하지 못하게 하는 애플리케이션 수준의 Blob 임대를 획득합니다. 첫 번째 앱의 실행이 중지되면 해당 임대가 만료되고 두 번째 앱이 임대를 획득한 후에 작업 허브 메시지를 계속 처리할 수 있습니다.
v2.3.0 이전에는 동일한 스토리지 계정을 사용하도록 구성된 함수 앱이 메시지를 처리하고 스토리지 아티팩트를 동시에 업데이트하므로 전반적인 대기 시간 및 송신 비용이 훨씬 더 높습니다. 기본 앱과 복제본 앱에 일시적으로라도 다른 코드가 배포되어 있는 경우 두 앱에서의 오케스트레이터 함수 불일치로 인해 오케스트레이션이 올바르게 실행되지 않을 수도 있습니다. 따라서 재해 복구를 위해 지역 배포를 필요로 하는 모든 앱에서는 Durable 확장 v2.3.0 이상을 사용하는 것이 좋습니다.
시나리오 2 - 지역 스토리지에서 컴퓨팅 부하 분산
이전 시나리오에서는 컴퓨팅 인프라의 실패 경우만 다루었습니다. 스토리지 서비스가 실패하면 함수 앱이 작동 중단됩니다. 지속형 함수가 계속해서 작동되게 하기 위해 이 시나리오에서는 함수 앱이 배포되는 각 지역에서 로컬 스토리지 계정을 사용합니다.
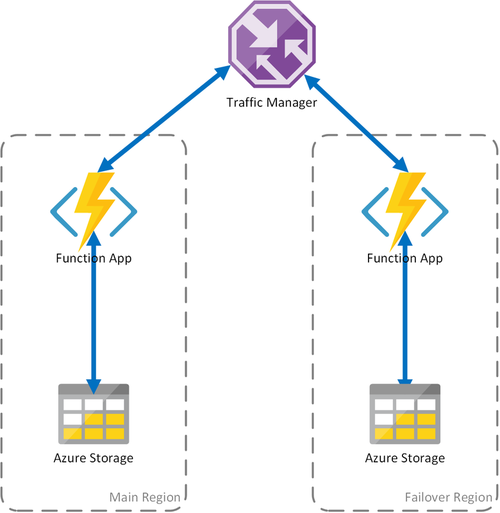
이 방법은 이전 시나리오를 약간 개선합니다.
- 함수 앱이 실패하면 Traffic Manager는 보조 지역으로 장애 조치(Failover)되도록 합니다. 그러나 함수 앱은 자체 스토리지 계정을 사용하므로 지속형 함수는 계속 작동합니다.
- 장애 조치(failover) 중에는 함수 앱과 스토리지 계정이 함께 배치되므로 장애 조치(failover) 지역에서 추가 대기 시간이 발생하지 않습니다.
- 스토리지 계층의 오류는 지속형 함수 오류로 이어지며, 장애 조치(failover) 지역으로 리디렉션이 트리거됩니다. 다시 말해서, 함수 앱 및 스토리지 계정이 지역별로 구분되어 있으므로 지속형 함수는 계속 작동합니다.
이 시나리오에 대한 중요한 고려 사항:
- 함수 앱이 전용 App Service 요금제를 사용하여 배포된 경우 장애 조치(failover) 데이터 센터에서 컴퓨팅 인프라를 복제하면 비용이 늘어납니다.
- 현재 상태는 장애 조치(failover) 되지 않습니다. 즉, 주 지역이 복구될 때까지 기존 오케스트레이션과 엔터티는 사실상 일시 중지되고 사용할 수 없게 됩니다.
요약하자면, 첫 번째와 두 번째 시나리오 간의 장단점은 대기 시간이 유지되고 송신 비용이 최소화되지만 가동 중지 시간 동안 기존 오케스트레이션과 엔터티를 사용할 수 없게 된다는 것입니다. 장단점의 허용 여부는 애플리케이션의 요구 사항에 따라 달라 집니다.
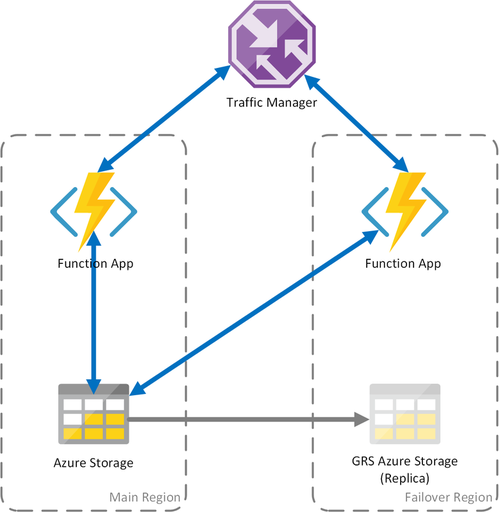
시나리오 3 - GRS 공유 스토리지에서 컴퓨팅 부하 분산
이 시나리오는 첫 번째 시나리오를 수정하고 공유 스토리지 계정을 구현합니다. 주요 차이점은 지역 복제가 사용하도록 설정된 스토리지 계정을 만든다는 것입니다. 기능적으로 볼 때, 이 시나리오는 시나리오 1과 동일한 이점을 제공하지만 데이터 복구 측면에서 추가적인 이점을 제공합니다.
- GRS(지역 중복 스토리지) 및 RA-GRS(읽기 액세스 GRS)는 스토리지 계정의 가용성을 최대화합니다.
- Storage 서비스의 지역 중단이 발생할 경우 보조 복제본으로 장애 조치(failover)를 수동으로 시작할 수 있습니다. 중대한 재해로 인해 지역이 손실되는 극단적인 경우 Microsoft는 지역 장애 조치(failover)를 시작할 수 있습니다. 이 경우에 사용자의 조치가 필요하지 않습니다.
- 장애 조치(failover)가 수행되면 지속성 함수의 상태가 일반적으로 몇 분 간격으로 발생하는 스토리지 계정의 마지막 복제까지 유지됩니다.
다른 시나리오와 마찬가지로 다음과 같은 중요한 고려 사항이 있습니다.
- 복제본으로 장애 조치(failover)하는 데 시간이 걸릴 수 있습니다. 장애 조치(failover)가 완료되고 Azure Storage DNS 레코드가 업데이트될 때까지 함수 앱이 중단됩니다.
- 지역 복제 스토리지 계정을 사용할 경우 추가 비용이 발생합니다.
- GRS 복제는 데이터를 비동기적으로 복사합니다. 일부 최신 트랜잭션은 복제 프로세스의 대기 시간으로 인해 손실될 수 있습니다.
참고 항목
시나리오 1에서 설명한 것처럼 이 전략으로 배포된 함수 앱에서는 v2.3.0 이상의 Durable Functions 확장을 사용하는 것이 좋습니다.
자세한 내용은 Azure Storage 재해 복구 및 스토리지 계정 장애 조치(failover) 설명서를 참조하세요.