자습서: Azure Cache for Redis를 사용하여 Azure OpenAI 포함에서 벡터 유사성 검색 수행
이 자습서에서는 기본 벡터 유사성 검색 사용 사례를 안내합니다. Azure OpenAI Service에서 생성된 포함 및 Azure Cache for Redis 엔터프라이즈 계층의 기본 제공 벡터 검색 기능을 사용하여 영화 데이터 세트를 쿼리하여 가장 관련성이 큰 일치 항목을 찾습니다.
이 자습서에서는 1901년부터 2017년까지 Wikipedia에서 35,000편 이상의 영화 줄거리 설명을 제공하는 데이터 세트를 사용합니다. 이 데이터 세트에는 각 영화에 대한 줄거리 요약과 영화가 출시된 연도, 감독, 주요 캐스팅 및 장르와 같은 메타데이터가 포함됩니다. 자습서의 단계에 따라 줄거리 요약을 기준으로 포함을 생성하고 다른 메타데이터를 사용하여 하이브리드 쿼리를 실행합니다.
이 자습서에서는 다음을 하는 방법을 알아볼 수 있습니다.
- 벡터 검색을 위해 구성된 Azure Cache for Redis 인스턴스 만들기
- Azure OpenAI 및 기타 필요한 Python 라이브러리를 설치합니다.
- 영화 데이터 세트를 다운로드하고 분석을 위해 준비합니다.
- text-embedding-ada-002(버전 2) 모델을 사용하여 포함을 생성합니다.
- Azure Cache for Redis에서 벡터 인덱스 만들기
- 코사인 유사성을 사용하여 검색 결과의 순위를 지정합니다.
- RediSearch를 통해 하이브리드 쿼리 기능을 사용하여 데이터를 미리 필터링하고 벡터 검색을 더욱 강력하게 만듭니다.
Important
이 자습서에서는 Jupyter Notebook 빌드 과정을 안내합니다. Python 코드 파일(.py)을 사용하여 이 자습서를 수행하고 비슷한 결과를 얻을 수 있지만, 이 자습서의 모든 코드 블록을 .py 파일에 추가하고 한 번 실행하여 결과를 확인해야 합니다. 즉, Jupyter Notebook은 셀을 실행할 때 중간 결과를 제공하지만 Python 코드 파일에서 작업할 때 예상되는 동작은 아닙니다.
Important
대신, 완성된 Jupyter Notebook을 따라 작업하려면 새 redis-vector 폴더에 tutorial.ipynb라는 Jupyter Notebook 파일을 다운로드합니다.
필수 조건
- Azure 구독 - 체험 구독 만들기
- 원하는 Azure 구독의 Azure OpenAI에 대한 액세스 권한. 현재 Azure OpenAI에 대한 액세스를 신청해야 합니다. https://aka.ms/oai/access에서 양식을 작성하여 Azure OpenAI에 대한 액세스를 신청할 수 있습니다.
- Python 3.8 이상 버전
- Jupyter Notebook(선택 사항)
- text-embedding-ada-002(버전 2) 모델이 배포된 Azure OpenAI 리소스. 이 모델은 현재 특정 지역에서만 사용할 수 있습니다. 모델을 배포하는 방법에 대한 지침은 리소스 배포 가이드를 참조하세요.
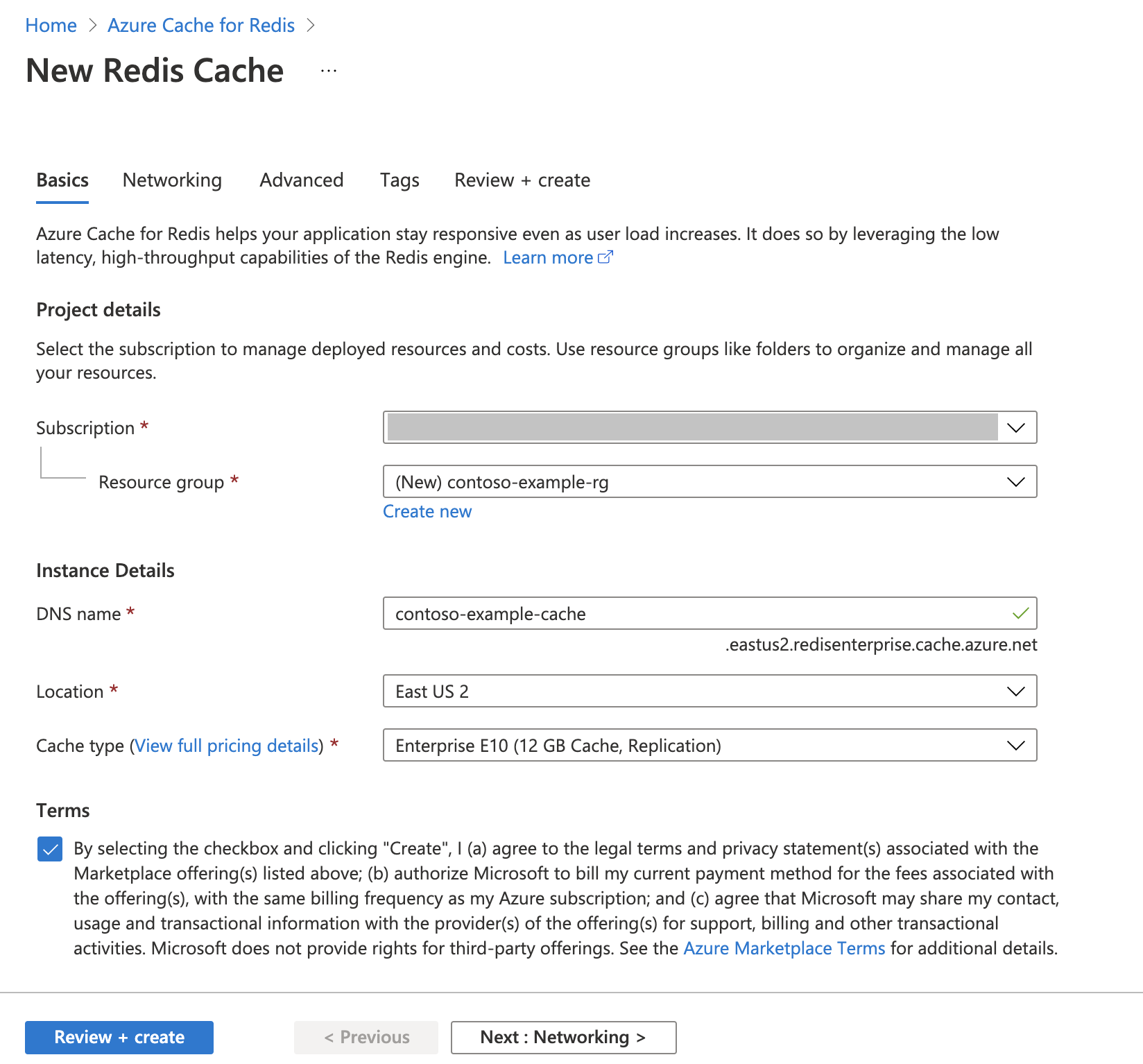
Azure Cache for Redis 인스턴스 만들기
빠른 시작: Redis Enterprise 캐시 만들기 가이드를 따릅니다. 고급 페이지에서 RediSearch 모듈을 추가하고 엔터프라이즈 클러스터 정책을 선택했는지 확인합니다. 다른 모든 설정은 빠른 시작에 설명된 기본값과 일치할 수 있습니다.
캐시를 만드는 데 몇 분 정도 걸립니다. 그 동안 다음 단계로 이동할 수 있습니다.
개발 환경 설정
일반적으로 로컬 컴퓨터에서 프로젝트를 저장하는 위치에 redis-vector라는 폴더를 만듭니다.
이 폴더에 새 python 파일(tutorial.py) 또는 Jupyter Notebook(tutorial.ipynb)을 만듭니다.
필요한 Python 패키지를 설치합니다.
pip install "openai==1.6.1" num2words matplotlib plotly scipy scikit-learn pandas tiktoken redis langchain
데이터 세트 다운로드
웹 브라우저에서 https://www.kaggle.com/datasets/jrobischon/wikipedia-movie-plots으로 이동합니다.
Kaggle에 로그인하거나 등록합니다. 파일을 다운로드하려면 등록해야 합니다.
Kaggle에서 다운로드 링크를 선택하여 archive.zip 파일을 다운로드합니다.
archive.zip 파일을 추출하고 wiki_movie_plots_deduped.csv를 redis-vector 폴더로 이동합니다.
라이브러리 가져오기 및 연결 정보 설정
Azure OpenAI에 대해 성공적으로 호출하려면 엔드포인트와 키가 필요합니다. 또한 Azure Cache for Redis에 연결하려면 엔드포인트 및 키가 필요합니다.
Azure Portal에서 Azure OpenAI 리소스로 이동합니다.
엔드포인트 및 키를 리소스 관리 섹션에서 찾습니다. 엔드포인트 및 액세스 키를 복사합니다. API 호출을 인증하는 데 모두 필요합니다. 예제 엔드포인트는
https://docs-test-001.openai.azure.com입니다.KEY1또는KEY2를 사용할 수 있습니다.Azure Portal에서 Azure Cache for Redis 리소스의 개요 페이지로 이동합니다. 엔드포인트를 복사합니다.
설정 섹션에서 액세스 키를 찾습니다. 액세스 키를 복사합니다.
Primary또는Secondary를 사용할 수 있습니다.새 코드 셀에 다음 코드를 추가합니다.
# Code cell 2 import re from num2words import num2words import os import pandas as pd import tiktoken from typing import List from langchain.embeddings import AzureOpenAIEmbeddings from langchain.vectorstores.redis import Redis as RedisVectorStore from langchain.document_loaders import DataFrameLoader API_KEY = "<your-azure-openai-key>" RESOURCE_ENDPOINT = "<your-azure-openai-endpoint>" DEPLOYMENT_NAME = "<name-of-your-model-deployment>" MODEL_NAME = "text-embedding-ada-002" REDIS_ENDPOINT = "<your-azure-redis-endpoint>" REDIS_PASSWORD = "<your-azure-redis-password>"Azure OpenAI 배포의 키 및 엔드포인트 값으로
API_KEY및RESOURCE_ENDPOINT값을 업데이트합니다.DEPLOYMENT_NAME을text-embedding-ada-002 (Version 2)포함 모델을 사용하여 배포의 이름으로 설정해야 하며MODEL_NAME은 사용되는 특정 포함 모델이어야 합니다.REDIS_ENDPOINT및REDIS_PASSWORD를 Azure Cache for Redis 인스턴스의 엔드포인트 및 키 값으로 업데이트합니다.Important
환경 변수 또는 Azure Key Vault와 같은 비밀 관리자를 사용하여 API 키, 엔드포인트 및 배포 이름 정보를 전달하는 것이 좋습니다. 이러한 변수는 단순성을 위해 여기에서 일반 텍스트로 설정됩니다.
코드 셀 2를 실행합니다.
pandas로 데이터 세트 가져오기 및 데이터 처리
다음으로, csv 파일을 pandas DataFrame으로 읽어옵니다.
새 코드 셀에 다음 코드를 추가합니다.
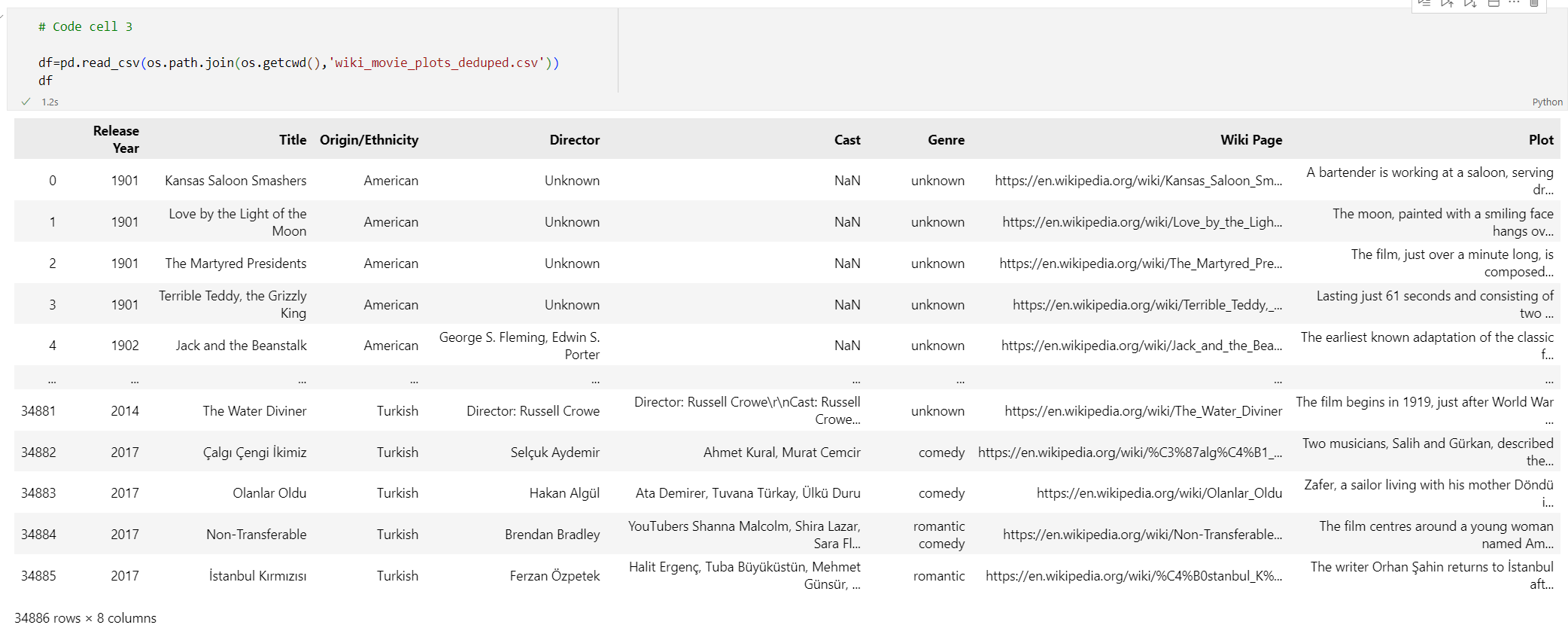
# Code cell 3 df=pd.read_csv(os.path.join(os.getcwd(),'wiki_movie_plots_deduped.csv')) df코드 셀 3을 실행합니다. 다음과 같은 출력이 표시됩니다.
다음으로, 인덱스를
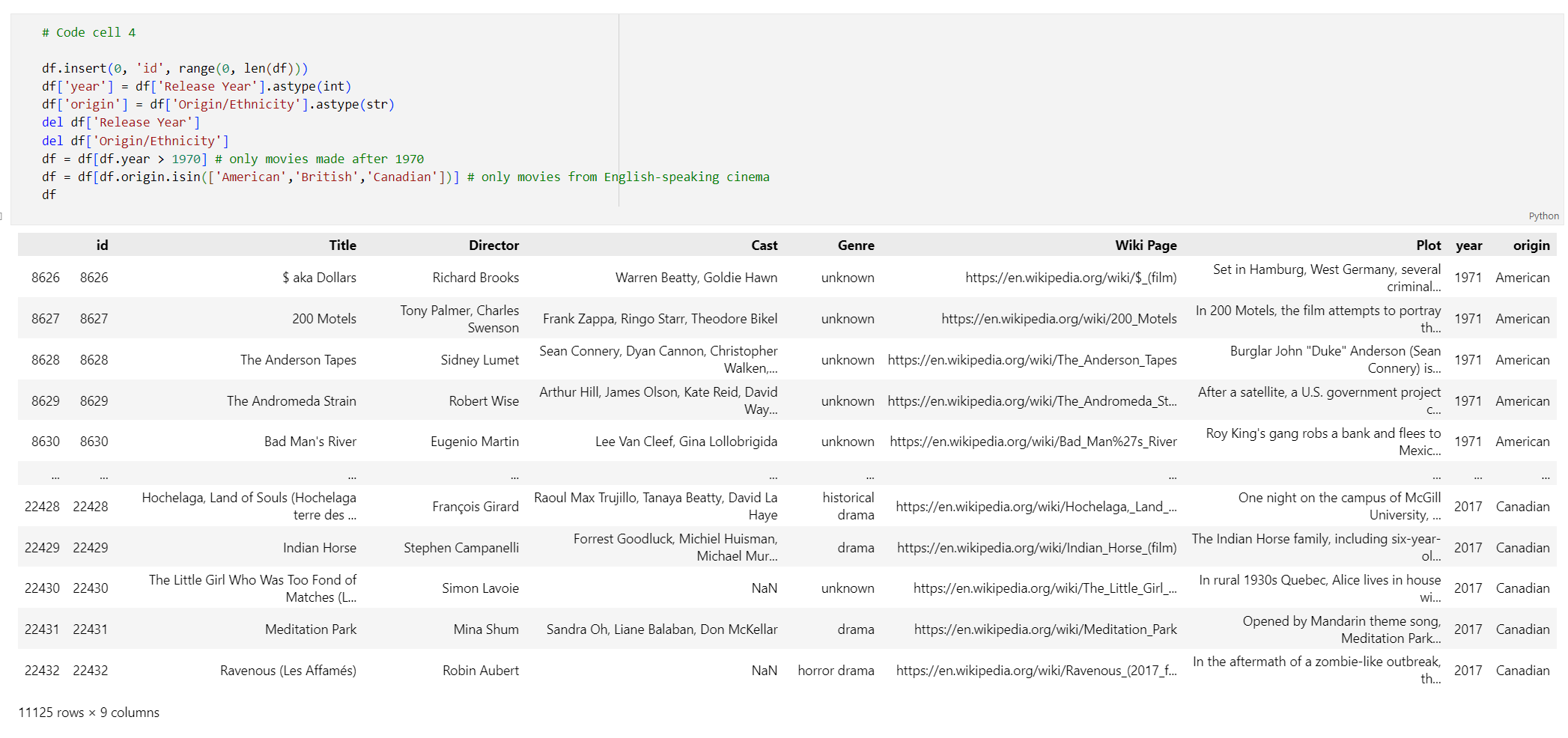
id추가하고 열 제목에서 공백을 제거하여 데이터를 처리하고, 1970년 이후에 만들어진 영화와 영어권 국가 또는 지역에서 만든 영화만 찍도록 영화를 필터링합니다. 이 필터링 단계는 데이터 세트의 영화 수를 줄여 포함을 생성하는 데 필요한 비용과 시간을 줄여줍니다. 기본 설정에 따라 필터 매개 변수를 자유롭게 변경하거나 제거할 수 있습니다.데이터를 필터링하려면 새 코드 셀에 다음 코드를 추가합니다.
# Code cell 4 df.insert(0, 'id', range(0, len(df))) df['year'] = df['Release Year'].astype(int) df['origin'] = df['Origin/Ethnicity'].astype(str) del df['Release Year'] del df['Origin/Ethnicity'] df = df[df.year > 1970] # only movies made after 1970 df = df[df.origin.isin(['American','British','Canadian'])] # only movies from English-speaking cinema df코드 셀 4를 실행합니다. 다음 결과가 보일 것입니다.
공백 및 문장 부호를 제거하여 데이터를 정리하는 함수를 만든 다음, 줄거리가 포함된 데이터 프레임에 사용합니다.
새 코드 셀에 다음 코드를 추가하고 실행합니다.
# Code cell 5 pd.options.mode.chained_assignment = None # s is input text def normalize_text(s, sep_token = " \n "): s = re.sub(r'\s+', ' ', s).strip() s = re.sub(r". ,","",s) # remove all instances of multiple spaces s = s.replace("..",".") s = s.replace(". .",".") s = s.replace("\n", "") s = s.strip() return s df['Plot']= df['Plot'].apply(lambda x : normalize_text(x))마지막으로 포함 모델에 비해 너무 긴 줄거리 설명이 포함된 항목을 제거합니다. 즉, 8192개 토큰 제한보다 더 많은 토큰이 필요합니다. 그런 다음, 포함을 생성하는 데 필요한 토큰 수를 계산합니다. 이것은 포함 생성에 대한 가격 책정에도 영향을 줍니다.
새 코드 셀에 다음 코드를 추가합니다.
# Code cell 6 tokenizer = tiktoken.get_encoding("cl100k_base") df['n_tokens'] = df["Plot"].apply(lambda x: len(tokenizer.encode(x))) df = df[df.n_tokens<8192] print('Number of movies: ' + str(len(df))) print('Number of tokens required:' + str(df['n_tokens'].sum()))코드 셀 6을 실행합니다. 다음 출력이 표시됩니다.
Number of movies: 11125 Number of tokens required:7044844Important
필요한 토큰 수에 따라 embedding을 생성하는 비용을 계산하려면 Azure OpenAI 서비스 가격 책정 을 참조하세요.


LangChain에 DataFrame 로드
DataFrameLoader 클래스를 사용하여 DataFrame을 LangChain에 로드합니다. 데이터가 LangChain 문서에 있으면 LangChain 라이브러리를 사용하여 포함 항목을 생성하고 유사성 검색을 수행하는 것이 훨씬 더 쉽습니다. 이 열에 포함이 생성되도록 Plot을 page_content_column으로 설정합니다.
새 코드 셀에 다음 코드를 추가하고 실행합니다.
# Code cell 7 loader = DataFrameLoader(df, page_content_column="Plot" ) movie_list = loader.load()
포함을 생성하고 Redis에 로드
이제 데이터가 필터링되어 LangChain으로 로드되었으므로 각 영화에 대한 줄거리를 쿼리할 수 있도록 포함을 만듭니다. 다음 코드는 Azure OpenAI를 구성하고, 포함을 생성하며, 포함 벡터를 Azure Cache for Redis에 로드합니다.
다음 코드를 새 코드 셀에 추가합니다.
# Code cell 8 embedding = AzureOpenAIEmbeddings( deployment=DEPLOYMENT_NAME, model=MODEL_NAME, azure_endpoint=RESOURCE_ENDPOINT, openai_api_type="azure", openai_api_key=API_KEY, openai_api_version="2023-05-15", show_progress_bar=True, chunk_size=16 # current limit with Azure OpenAI service. This will likely increase in the future. ) # name of the Redis search index to create index_name = "movieindex" # create a connection string for the Redis Vector Store. Uses Redis-py format: https://redis-py.readthedocs.io/en/stable/connections.html#redis.Redis.from_url # This example assumes TLS is enabled. If not, use "redis://" instead of "rediss:// redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT # create and load redis with documents vectorstore = RedisVectorStore.from_documents( documents=movie_list, embedding=embedding, index_name=index_name, redis_url=redis_url ) # save index schema so you can reload in the future without re-generating embeddings vectorstore.write_schema("redis_schema.yaml")코드 셀 8을 실행합니다. 완료하려면 30분 이상 걸릴 수 있습니다.
redis_schema.yaml파일도 생성됩니다. 이 파일은 포함을 다시 생성하지 않고 Azure Cache for Redis 인스턴스의 인덱스에 연결하려는 경우에 유용합니다.
Important
포함이 생성되는 속도는 Azure OpenAI 모델에서 사용할 수 있는 할당량에 따라 달라집니다. 분당 240k 토큰의 할당량을 사용하는 경우 데이터 세트에서 7M 토큰을 처리하는 데 약 30분이 걸립니다.
벡터 검색 쿼리 실행
이제 데이터 세트, Azure OpenAI 서비스 API 및 Redis 인스턴스가 설정되었으므로 벡터를 사용하여 검색할 수 있습니다. 이 예제에서는 지정된 쿼리에 대한 상위 10개 결과가 반환됩니다.
Python 파일에 다음 코드를 추가합니다.
# Code cell 9 query = "Spaceships, aliens, and heroes saving America" results = vectorstore.similarity_search_with_score(query, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')코드 셀 9를 실행합니다. 다음과 같은 출력이 표시됩니다.
Independence Day (Score: 0.8348) The Flying Machine (Score: 0.8332) Remote Control (Score: 0.8301) Bravestarr: The Legend (Score: 0.83) Xenogenesis (Score: 0.8291) Invaders from Mars (Score: 0.8291) Apocalypse Earth (Score: 0.8287) Invasion from Inner Earth (Score: 0.8287) Thru the Moebius Strip (Score: 0.8283) Solar Crisis (Score: 0.828)유사성 점수는 유사성에 따라 영화의 서수 순위와 함께 반환됩니다. 더 구체적인 쿼리의 경우 유사성 점수가 목록 아래로 갈수록 더 빠르게 작아집니다.
하이브리드 검색
RediSearch는 벡터 검색을 기준으로 다양한 검색 기능을 제공하므로 영화 장르, 캐스팅, 개봉 연도 또는 감독과 같은 데이터 세트의 메타데이터를 기준으로 결과를 필터링할 수 있습니다. 이 경우 장르
comedy를 기준으로 필터링합니다.새 코드 셀에 다음 코드를 추가합니다.
# Code cell 10 from langchain.vectorstores.redis import RedisText query = "Spaceships, aliens, and heroes saving America" genre_filter = RedisText("Genre") == "comedy" results = vectorstore.similarity_search_with_score(query, filter=genre_filter, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')코드 셀 10을 실행합니다. 다음과 같은 출력이 표시됩니다.
Remote Control (Score: 0.8301) Meet Dave (Score: 0.8236) Elf-Man (Score: 0.8208) Fifty/Fifty (Score: 0.8167) Mars Attacks! (Score: 0.8165) Strange Invaders (Score: 0.8143) Amanda and the Alien (Score: 0.8136) Suburban Commando (Score: 0.8129) Coneheads (Score: 0.8129) Morons from Outer Space (Score: 0.8121)
Azure Cache for Redis 및 Azure OpenAI Service를 사용하면 포함 및 벡터 검색을 사용하여 애플리케이션에 강력한 검색 기능을 추가할 수 있습니다.
리소스 정리
이 문서에서 만든 리소스를 계속 사용하려면 리소스 그룹을 유지합니다.
그렇지 않고 리소스 사용을 완료하는 경우 요금이 부과되지 않도록 하려면 만든 Azure 리소스 그룹을 삭제하면 됩니다.
Important
리소스 그룹을 삭제하면 다시 되돌릴 수 없습니다. 리소스 그룹을 삭제하는 경우 그 안의 모든 리소스가 영구적으로 삭제됩니다. 잘못된 리소스 그룹 또는 리소스를 자동으로 삭제하지 않도록 해야 합니다. 유지하려는 리소스가 포함된 기존 리소스 그룹 내에서 리소스를 만든 경우 리소스 그룹을 삭제하는 대신 각 리소스를 개별적으로 삭제할 수 있습니다.
리소스 그룹을 삭제하려면
Azure Portal에 로그인한 다음, 리소스 그룹을 선택합니다.
삭제하려는 리소스 그룹을 선택합니다.
리소스 그룹이 많은 경우 필드 필터링... 상자를 사용하여 이 문서에 대해 만든 리소스 그룹의 이름을 입력합니다. 결과 목록에서 리소스 그룹을 선택합니다.
리소스 그룹 삭제를 선택합니다.
리소스 그룹 삭제를 확인하는 메시지가 표시됩니다. 리소스 그룹의 이름을 입력하여 확인한 다음, 삭제를 선택합니다.
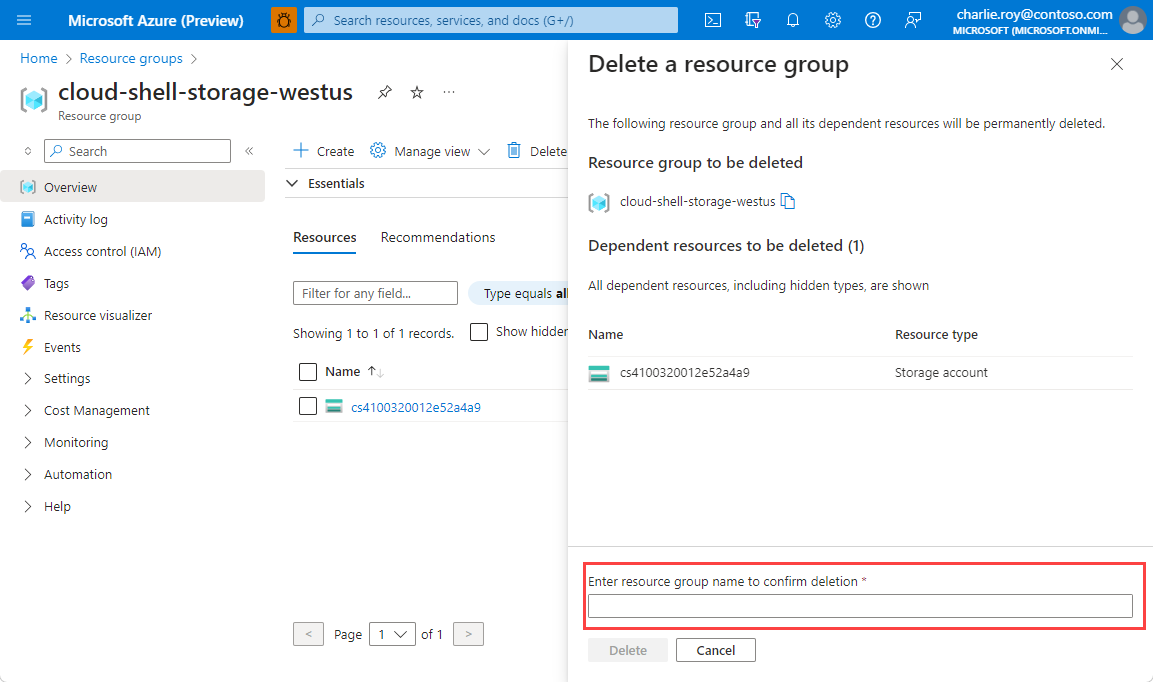
잠시 후, 리소스 그룹 및 모든 해당 리소스가 삭제됩니다.
관련 내용
- Azure Cache for Redis에 대해 자세히 알아보기
- Azure Cache for Redis 벡터 검색 기능에 대해 자세히 알아보기
- Azure OpenAI Service에서 생성된 포함에 대해 자세히 알아보기
- 코사인 유사성에 대해 자세히 알아보기
- OpenAI 및 Redis를 사용하여 AI 기반 앱을 빌드하는 방법 읽기
- 의미 체계 답변을 사용하여 Q&A 앱 빌드