필요할 때 데이터를 데이터 저장소에서 캐시로 로드합니다. 이렇게 하면 성능이 개선되고 캐시에 저장된 데이터 및 기본 데이터 저장소의 데이터 간 일관성을 유지할 수 있습니다.
컨텍스트 및 문제점
애플리케이션에서 캐시를 사용하여 데이터 저장소에 저장된 정보에 반복되는 액세스를 개선합니다. 그러나, 캐시된 데이터가 언제나 데이터 저장소에 저장된 데이터와 일관성을 완전히 유지하지는 것은 불가능합니다. 애플리케이션은 캐시에 보관된 데이터를 최신 상태로 유지할 수 있도록 지원하는 전략을 구현하는 동시에, 캐시에 보관된 오래된 데이터로 인해 발생하는 상황을 감지하고 처리할 수 있어야 합니다.
해결 방법
많은 상업용 캐싱 시스템은 read-through 및 write-through/write-behind 작업을 제공합니다. 이런 캐싱 시스템에서 애플리케이션은 캐시를 참조해 데이터를 검색합니다. 캐시에 데이터가 없으면 데이터 저장소에서 데이터가 검색된 후 캐시에 추가됩니다. 캐시에 보관된 데이터의 모든 수정 사항도 나중 쓰기 방식으로 데이터 저장소에 자동 기록합니다.
이 기능을 제공하지 않는 캐시의 경우, 데이터 유지를 위해 캐시를 사용하는 것은 애플리케이션의 책임입니다.
애플리케이션은 캐시 배제 전략을 구현해 read-through 캐싱의 기능을 에뮬레이트할 수 있습니다. 이 전략은 데이터를 주문형 캐시에 로드합니다. 아래 그림은 캐시 배제 패턴을 사용해 데이터를 캐시에 저장하는 방법을 보여 줍니다.
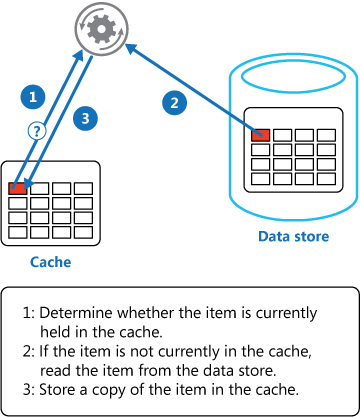
정보를 업데이트한 애플리케이션은 데이터 저장소에 수정 사항을 저장하고 캐시의 해당 항목을 무효화해 write-through 전략을 구현할 수 있습니다.
다음에도 해당 항목이 필요한 경우, 캐시 배제 전략을 사용하면 데이터 저장소에서 업데이트된 데이터가 검색된 후 캐시에 다시 추가됩니다.
문제 및 고려 사항
이 패턴을 구현할 방법을 결정할 때 다음 사항을 고려하세요.
캐시된 데이터의 수명. 대부분의 캐시는 규정된 기간 동안 액세스하지 않은 경우 데이터를 무효화하고 캐시에서 삭제하는 만료 정책을 구현합니다. 캐시 배제가 효과적이려면 만료 정책이 데이터를 사용하는 애플리케이션의 액세스 패턴과 일치해야 합니다. 애플리케이션은 데이터 저장소에서 데이터를 지속적으로 검색해서 캐시에 추가할 수 있기 때문에, 만료 기간이 너무 짧아서도 안 됩니다. 마찬가지로 캐시된 데이터는 오래 유지될 수 있기 때문에 만료 기간이 너무 길어서도 안 됩니다. 캐싱은 비교적 정적인 데이터 또는 자주 읽는 데이터에 가장 효과입니다.
데이터 제거. 대부분의 캐시는 데이터를 가져오는 데이터 저장소에 비해 크기가 제한되기 때문에 필요한 경우 데이터를 제거합니다. 대부분의 캐시는 오래 전에 사용한 항목 정책을 채택해 제거 대상 항목을 선택하지만, 정책을 사용자 지정할 수도 있습니다. 캐시의 전역 만료 속성과 기타 속성 및 각각의 캐시된 항목의 만료 속성을 구성하여 캐시의 경제성을 높입니다. 한편 캐시의 모든 항목에 전역 제거 정책을 적용하는 것이 항상 적절한 것은 아닙니다. 예를 들어 데이터 저장소에서 캐시된 항목을 검색하는 비용이 높은 경우에는 더 자주 액세스하지만 비용이 낮은 항목을 제거하고 비용이 높은 항목을 유지하는 것이 유리할 수 있습니다.
캐시 초기화. 대부분의 솔루션은 시작 처리 과정에서 애플리케이션에 필요할 수 있는 데이터를 미리 캐시에 채워둡니다. 시 배제 패턴은 이런 데이터 중 일부가 만료되거나 제거되는 경우에도 여전히 유용할 수 있습니다.
일관성. 캐시 배제 패턴의 구현이 데이터 저장소와 캐시의 일관성을 보증하는 것은 아닙니다. 데이터 저장소의 항목은 외부 프로세스를 통해 언제든 변경될 수 있고, 이와 같은 변경은 해당 항목을 다시 로드할 때까지 캐시에 반영되지 않습니다. 여러 데이터 저장소에 데이터를 복제하는 시스템에서 동기화가 자주 이루어질 경우 이와 같은 문제가 심각한 문제로 발전할 수 있습니다.
로컬(메모리 내) 캐싱. 캐시는 애플리케이션 인스턴스에 대해 로컬일 수 있으며 메모리 내에 저장될 수 있습니다. 캐시 배제는 애플리케이션이 동일한 데이터에 반복적으로 액세스하는 경우 로컬 환경에서 유용할 수 있습니다. 그러나 로컬 캐시는 프라이빗용이므로, 다양한 애플리케이션 인스턴스 각각은 동일한 캐시된 데이터의 사본을 보유할 수 있습니다. 이런 데이터는 캐시 사이에서 일관성을 빠르게 상실할 수 있으므로, 프라이빗 캐시에 보관된 데이터는 만료시키고 더 자주 새로 고칠 필요가 있습니다. 이런 시나리오에서는 공유 또는 분산 캐싱 메커니즘의 사용 여부 검토를 고려해야 합니다.
이 패턴을 사용해야 하는 경우
다음 경우에 이 패턴을 사용합니다.
- 캐시가 기본 read-through 및 write-through 작업을 제공하지 않는 경우.
- 리소스 수요를 예측할 수 없는 경우. 이 패턴을 사용하면 애플리케이션이 주문형 데이터를 로드할 수 있습니다. 이 패턴은 애플리케이션에 필요할 데이터에 대해 사전에 가정하지 않습니다.
다음 경우에는 이 패턴이 적합하지 않습니다.
- 캐시된 데이터 집합이 정적인 경우. 사용 가능한 캐시 공간에 데이터가 가득 차면 시작 시 데이터가 채워진 캐시를 초기화하고 데이터의 만료를 방지하는 정책을 적용합니다.
- 웹 팜에 호스트되는 웹 애플리케이션 내 캐싱 세션 상태 정보. 이런 환경에서는 클라이언트-서버 선호도를 기반으로 하는 종속성 도입을 피해야 합니다.
워크로드 디자인
설계자는 Azure Well-Architected Framework 핵심 요소에서 다루는 목표와 원칙을 해결하기 위해 워크로드 디자인에서 Cache-Aside 패턴을 사용하는 방법을 평가해야 합니다. 예시:
| 핵심 요소 | 이 패턴으로 핵심 목표를 지원하는 방법 |
|---|---|
| 안정성 디자인 결정은 워크로드가 오작동에 대한 복원력을 갖도록 하고 오류가 발생한 후 완전히 작동하는 상태로 복구 되도록 하는 데 도움이 됩니다. | 캐싱은 데이터 복제를 만들고, 제한된 방법으로 원본 데이터 저장소를 일시적으로 사용할 수 없는 경우 자주 액세스하는 데이터의 가용성을 유지하는 데 사용할 수 있습니다. 또한 캐시에 오작동이 있는 경우 워크로드는 원본 데이터 저장소로 대체됩니다. - RE:05 중복성 |
| 성능 효율성은 크기 조정, 데이터, 코드의 최적화를 통해 워크로드가 수요를 효율적으로 충족하는 데 도움이 됩니다. | 자주 변경되지 않는 읽기가 많은 데이터에 캐시를 사용할 때 워크로드의 성능 향상을 얻을 수 있으며 워크로드는 일정량의 부실을 허용하도록 설계되었습니다. - PE:08 데이터 성능 - PE:12 연속 성능 최적화 |
디자인 결정과 마찬가지로 이 패턴을 통해 도입 가능한 다른 핵심 요소의 목표에 관한 절충을 고려합니다.
예시
Microsoft Azure에서는 Azure Cache for Redis를 사용하여 애플리케이션의 여러 인스턴스가 공유할 수 있는 분산 캐시를 생성할 수 있습니다.
다음 코드 예제에서는 .NET용 으로 작성된 Redis 클라이언트 라이브러리인 StackExchange.Redis 클라이언트를 사용합니다. Azure Cache for Redis 인스턴스에 연결하려면 정적 ConnectionMultiplexer.Connect 메서드를 호출하고 연결 문자열을 제공합니다. 이 메서드는 연결을 나타내는 ConnectionMultiplexer를 반환합니다. 애플리케이션의 ConnectionMultiplexer 인스턴스를 공유하는 방법은 다음 예제와 비슷하게 연결된 인스턴스를 반환하는 정적 속성을 갖는 것입니다. 이 방법은 스레드가 안전하도록 단일 연결된 인스턴스를 초기화하는 방법을 제공합니다.
private static ConnectionMultiplexer Connection;
// Redis connection string information
private static Lazy<ConnectionMultiplexer> lazyConnection = new Lazy<ConnectionMultiplexer>(() =>
{
string cacheConnection = ConfigurationManager.AppSettings["CacheConnection"].ToString();
return ConnectionMultiplexer.Connect(cacheConnection);
});
public static ConnectionMultiplexer Connection => lazyConnection.Value;
다음 코드 예제의 GetMyEntityAsync 메서드는 캐시 배제 패턴의 구현을 보여줍니다. 이 메서드는 read-through 접근 방식을 사용해 캐시에서 개체를 검색합니다.
개체 식별 키는 정수 ID입니다. GetMyEntityAsync 메서드는 이 키를 포함한 항목을 캐시에서 검색하려고 합니다. 일치하는 항목이 발견되면 해당 항목이 반환됩니다. 캐시에 일치하는 항목이 없으면 GetMyEntityAsync 메서드는 개체를 데이터 저장소에서 검색해 캐시에 추가한 후 반환합니다. 데이터 저장소의 종속성 때문에, 데이터 저장소에서 데이터를 실제로 읽는 코드는 여기에 표시되지 않습니다. 캐시된 항목을 만료 방식으로 구성하여 다른 위치에서 업데이트되더라도 오래되지 않도록 조치해야 합니다.
// Set five minute expiration as a default
private const double DefaultExpirationTimeInMinutes = 5.0;
public async Task<MyEntity> GetMyEntityAsync(int id)
{
// Define a unique key for this method and its parameters.
var key = $"MyEntity:{id}";
var cache = Connection.GetDatabase();
// Try to get the entity from the cache.
var json = await cache.StringGetAsync(key).ConfigureAwait(false);
var value = string.IsNullOrWhiteSpace(json)
? default(MyEntity)
: JsonConvert.DeserializeObject<MyEntity>(json);
if (value == null) // Cache miss
{
// If there's a cache miss, get the entity from the original store and cache it.
// Code has been omitted because it is data store dependent.
value = ...;
// Avoid caching a null value.
if (value != null)
{
// Put the item in the cache with a custom expiration time that
// depends on how critical it is to have stale data.
await cache.StringSetAsync(key, JsonConvert.SerializeObject(value)).ConfigureAwait(false);
await cache.KeyExpireAsync(key, TimeSpan.FromMinutes(DefaultExpirationTimeInMinutes)).ConfigureAwait(false);
}
}
return value;
}
이 예제에서는 Azure Cache for Redis를 사용하여 저장소에 액세스하고 캐시에서 정보를 검색합니다. 자세한 내용은 Azure Cache for Redis 사용 및 Azure Cache for Redis를 사용하여 웹앱을 만드는 방법을 참조하세요.
아래에 표시된 UpdateEntityAsync 메서드는 애플리케이션에서 값이 변경될 때 캐시의 개체를 무효화하는 방법을 보여 줍니다. 다음 코드는 원래 데이터 저장소를 업데이트한 다음, 캐시에서 캐시된 항목을 제거합니다.
public async Task UpdateEntityAsync(MyEntity entity)
{
// Update the object in the original data store.
await this.store.UpdateEntityAsync(entity).ConfigureAwait(false);
// Invalidate the current cache object.
var cache = Connection.GetDatabase();
var id = entity.Id;
var key = $"MyEntity:{id}"; // The key for the cached object.
await cache.KeyDeleteAsync(key).ConfigureAwait(false); // Delete this key from the cache.
}
참고
이 시퀀스에서는 단계의 순서가 중요합니다. 캐시에서 항목을 제거하기 전에 데이터 저장소를 업데이트합니다. 캐시된 항목을 먼저 제거하면 데이터 저장소가 업데이트되기 전에 클라이언트 응용 프로그램이 데이터를 가져오는 시간이 짧아집니다. 이 경우 캐시에서 항목이 제거되었으므로 캐시 누락이 발생하며, 이전 버전의 항목을 데이터 저장소에서 가져온 후 캐시에 다시 추가하는 결과를 가져옵니다. 따라서 캐시는 오래된 데이터를 포함하게 됩니다.
관련 참고 자료
이 패턴의 구현과 관련된 정보는 다음과 같습니다.
신뢰할 수 있는 웹앱 패턴 은 클라우드에서 수렴되는 웹 애플리케이션에 캐시 배제 패턴을 적용하는 방법을 보여 줍니다.
캐싱 지침 클라우드 솔루션에서 데이터를 캐시할 수 있는 방법에 대한 추가 정보뿐 아니라 캐시 구현 시 고려해야 하는 문제를 제공합니다.
Data Consistency Primer(데이터 일관성 입문서). 보통 클라우드 애플리케이션은 여러 데이터 저장소에 걸쳐 있는 데이터를 사용합니다. 이런 환경에서는 데이터 일관성의 관리와 유지가 시스템에서 중요한 측면으로 작용하는데, 구체적으로 동시성과 가용성 문제가 발생할 수 있습니다. 이 입문서는 분산 데이터의 일관성 문제를 설명할 뿐 아니라 애플리케이션에서 일관성을 구현해 데이터의 가용성을 유지하는 방법도 요약하고 있습니다.