Azure API Management의 생성 AI 게이트웨이 기능 개요
적용 대상: 모든 API Management 계층
이 문서에서는 Azure OpenAI Service에서 제공하는 것과 같은 생성 AI API를 관리하는 데 도움이 되는 Azure API Management의 기능을 소개합니다. Azure API Management는 지능형 앱에 서비스를 제공하는 API에 대한 보안, 성능 및 안정성을 향상시키기 위해 다양한 정책, 메트릭 및 기타 기능을 제공합니다. 전체적으로 이러한 기능을 생성 AI API에 대한 GenAI(생성 AI) 게이트웨이 기능이라고 합니다.
참고 항목
- 이 문서에서는 Azure OpenAI 서비스에서 노출하는 API를 관리하는 기능에 중점을 둡니다. 대부분의 GenAI 게이트웨이 기능은 Azure AI 모델 유추 API를 통해 사용할 수 있는 API를 포함하여 다른 LLM(대규모 언어 모델) API에 적용됩니다.
- 생성 AI 게이트웨이 기능은 별도의 API 게이트웨이가 아니라 API Management의 기존 API 게이트웨이의 기능입니다. API Management에 대한 자세한 내용은 Azure API Management 개요를 참조하세요.
생성 AI API 관리의 과제
생성 AI 서비스에 있는 주요 리소스 중 하나는 토큰입니다. Azure OpenAI Service는 TPM(분당 토큰)으로 표현된 모델 배포에 대한 할당량을 할당합니다. 그러면 모델 소비자(예: 다른 애플리케이션, 개발자 팀, 회사 내 부서 등)에 분산됩니다.
Azure를 사용하면 단일 앱을 Azure OpenAI 서비스에 쉽게 연결할 수 있습니다. 모델 배포 수준에서 직접 구성된 TPM 제한으로 API 키를 사용하여 직접 연결할 수 있습니다. 그러나 애플리케이션 포트폴리오를 확장하기 시작하면 종량제 또는 PTU(프로비전된 처리량 단위) 인스턴스로 배포된 단일 또는 여러 Azure OpenAI 서비스 엔드포인트를 호출하는 여러 앱이 제공됩니다. 이는 다음과 같은 특정 과제와 함께 제공됩니다.
- 토큰 사용량은 여러 애플리케이션에서 어떻게 추적합니까? Azure OpenAI 서비스 모델을 사용하는 여러 애플리케이션/팀에 대해 교차 요금을 계산할 수 있나요?
- 단일 앱이 전체 TPM 할당량을 사용하지 않고 다른 앱에서 Azure OpenAI 서비스 모델을 사용할 수 없도록 하려면 어떻게 해야 하나요?
- API 키는 여러 애플리케이션에 안전하게 분산되는 방법
- 여러 Azure OpenAI 엔드포인트에 부하를 분산하는 방법은 무엇인가요? 종량제 인스턴스로 되돌리기 전에 CPU의 커밋된 용량이 소진되었는지 확인할 수 있나요?
이 문서의 나머지 부분에는 Azure API Management가 이러한 문제를 해결하는 데 어떻게 도움이 되는지 설명합니다.
Azure OpenAI 서비스 리소스를 API로 가져오기
단일 클릭 환경을 사용하여 Azure OpenAI 서비스 엔드포인트 에서 Azure API Management로 API를 가져옵니다. API Management는 Azure OpenAI API에 대한 OpenAPI 스키마를 자동으로 가져와 온보딩 프로세스를 간소화하고 관리 ID를 사용하여 Azure OpenAI 엔드포인트에 대한 인증을 설정하여 수동 구성이 필요하지 않습니다. 동일한 사용자 친화적인 환경 내에서 토큰 제한 및 토큰 메트릭 내보내기 정책을 미리 구성할 수 있습니다.

토큰 제한 정책
Azure OpenAI 서비스 토큰의 사용에 따라 API 소비자당 제한을 관리하고 적용하도록 Azure OpenAI 토큰 제한 정책을 구성합니다. 이 정책을 사용하면 TPM(분당 토큰)으로 표현된 제한을 설정할 수 있습니다.
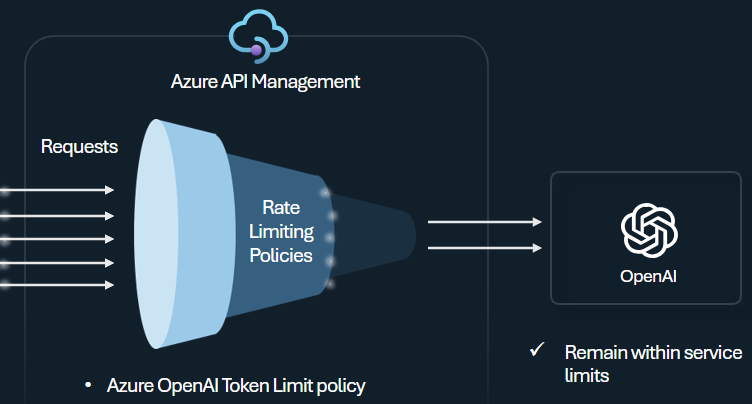
이 정책은 구독 키, 원래 IP 주소 또는 정책 식을 통해 정의된 임의 키와 같은 카운터 키에 토큰 기반 제한을 유연하게 할당할 수 있습니다. 또한 이 정책을 사용하면 Azure API Management 쪽에서 프롬프트 토큰을 미리 계산할 수 있으므로 프롬프트가 이미 제한을 초과하는 경우 Azure OpenAI 서비스 백 엔드에 대한 불필요한 요청을 최소화할 수 있습니다.
다음 기본 예제에서는 구독 키당 TPM 제한을 500으로 설정하는 방법을 보여 줍니다.
<azure-openai-token-limit counter-key="@(context.Subscription.Id)"
tokens-per-minute="500" estimate-prompt-tokens="false" remaining-tokens-variable-name="remainingTokens">
</azure-openai-token-limit>
팁
Azure AI 모델 유추 API를 통해 사용할 수 있는 LLM API에 대한 토큰 제한을 관리하고 적용하기 위해 API Management는 동등한 llm-token-limit 정책을 제공합니다.
토큰 메트릭 정책 내보내기
Azure OpenAI 내보내기 토큰 메트릭 정책은 Azure OpenAI 서비스 API를 통해 LLM 토큰 사용에 대한 메트릭을 Application Insights에 보냅니다. 이 정책은 여러 애플리케이션 또는 API 소비자에서 Azure OpenAI 서비스 모델의 사용률에 대한 개요를 제공하는 데 도움이 됩니다. 이 정책은 차지백 시나리오, 모니터링 및 용량 계획에 유용할 수 있습니다.
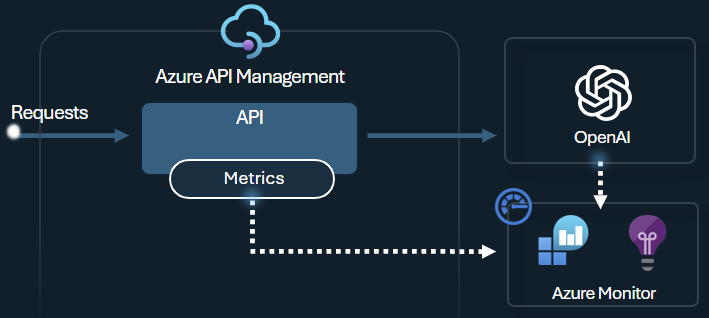
이 정책은 프롬프트, 완료 및 총 토큰 사용 메트릭을 캡처하고 선택한 Application Insights 네임스페이스로 보냅니다. 또한 미리 정의된 차원에서 분할 토큰 사용 메트릭으로 구성하거나 선택할 수 있으므로 구독 ID, IP 주소 또는 선택한 사용자 지정 차원별로 메트릭을 분석할 수 있습니다.
예를 들어 다음 정책은 클라이언트 IP 주소, API 및 사용자로 분할된 Application Insights에 메트릭을 보냅니다.
<azure-openai-emit-token-metric namespace="openai">
<dimension name="Client IP" value="@(context.Request.IpAddress)" />
<dimension name="API ID" value="@(context.Api.Id)" />
<dimension name="User ID" value="@(context.Request.Headers.GetValueOrDefault("x-user-id", "N/A"))" />
</azure-openai-emit-token-metric>
팁
Azure AI 모델 유추 API를 통해 사용할 수 있는 LLM API에 대한 메트릭을 보내기 위해 API Management는 동등한 llm-emit-token-metric 정책을 제공합니다.
백 엔드 부하 분산 장치 및 회로 차단기
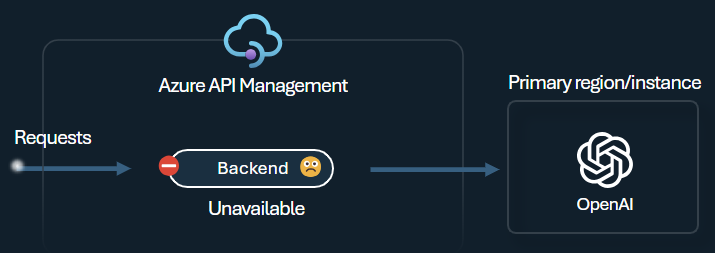
인텔리전트 애플리케이션을 빌드할 때의 과제 중 하나는 애플리케이션이 백 엔드 오류에 복원력이 있고 높은 부하를 처리할 수 있도록 하는 것입니다. Azure API Management에서 백 엔드를 사용하여 Azure OpenAI 서비스 엔드포인트를 구성하면 부하를 분산할 수 있습니다. 응답성이 없는 경우 Azure OpenAI 서비스 백 엔드에 대한 요청 전달을 중지하도록 회로 차단기 규칙을 정의할 수도 있습니다.
백 엔드 부하 분산 장치 는 라운드 로빈, 가중치 및 우선 순위 기반 부하 분산을 지원하므로 특정 요구 사항을 충족하는 부하 분산 전략을 유연하게 정의할 수 있습니다. 예를 들어 부하 분산 장치 구성 내에서 우선 순위를 정의하여 특정 Azure OpenAI 엔드포인트, 특히 PTU로 구매한 엔드포인트의 최적 사용률을 보장합니다.
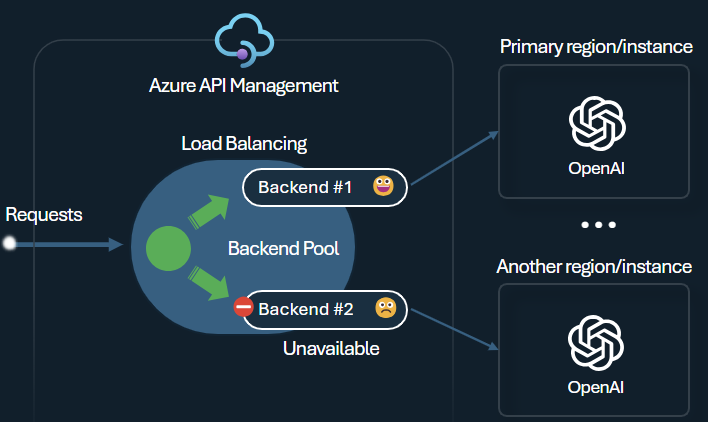
백 엔드 회로 차단기는 백 엔드에서 제공하는 Retry-After 헤더의 값을 적용하는 동적 이동 기간을 제공합니다. 이렇게 하면 백 엔드를 정확하고 시기 적절하게 복구하여 우선 순위 백 엔드의 사용률을 극대화할 수 있습니다.
의미 체계 캐싱 정책
유사한 프롬프트에 대한 완성을 저장하여 토큰 사용을 최적화하도록 Azure OpenAI 의미 체계 캐싱 정책을 구성합니다.
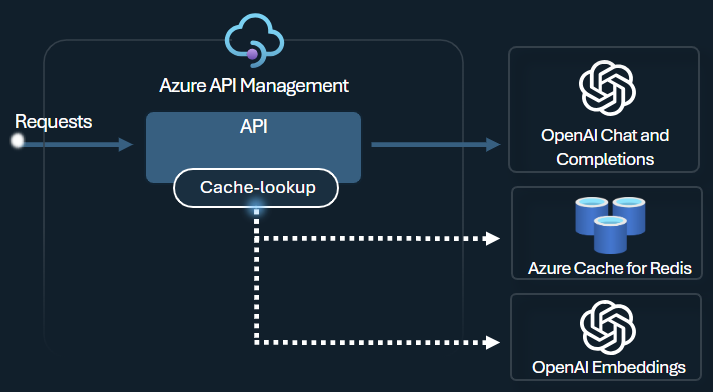
API Management에서 Azure Redis Enterprise 또는 RediSearch와 호환되고 Azure API Management에 온보딩된 다른 외부 캐시 를 사용하여 의미 체계 캐싱을 사용하도록 설정합니다. Azure OpenAI Service Embeddings API 를 사용하여 azure-openai-semantic-cache-store 및 azure-openai-semantic-cache-lookup 정책은 캐시에서 의미상 유사한 프롬프트 완성을 저장하고 검색합니다. 이 방법을 사용하면 완료가 다시 사용되어 토큰 사용량이 줄어들고 응답 성능이 향상됩니다.
팁
Azure AI 모델 유추 API를 통해 사용할 수 있는 LLM API에 대한 의미 체계 캐싱을 사용하도록 설정하기 위해 API Management는 동등한 llm-semantic-cache-store-policy 및 llm-semantic-cache-lookup-policy 정책을 제공합니다.
랩 및 샘플
- Azure API Management의 GenAI 게이트웨이 기능에 대한 랩
- APIM(Azure API Management) - Azure OpenAI 샘플(Node.js)
- API Management에서 Azure OpenAI를 사용하기 위한 Python 샘플 코드
아키텍처 및 디자인 고려 사항
- API Management를 사용하는 GenAI 게이트웨이 참조 아키텍처
- AI 허브 게이트웨이 랜딩 존 가속기
- Azure OpenAI 리소스를 사용하여 게이트웨이 솔루션 디자인 및 구현
- 여러 Azure OpenAI 배포 또는 인스턴스 앞에서 게이트웨이 사용