Azure AI Foundry를 사용하여 생성 AI 모델 및 애플리케이션을 평가하는 방법
상당한 데이터 세트에 적용될 때 생성 AI 모델 및 애플리케이션의 성능을 철저히 평가하려면 평가 프로세스를 시작할 수 있습니다. 이 평가 중에는 모델 또는 애플리케이션이 지정된 데이터 세트로 테스트되고, 해당 성능은 수학 기반 메트릭과 AI 지원 메트릭으로 양적으로 측정됩니다. 이 평가 실행은 애플리케이션의 기능 및 제한 사항에 대한 포괄적인 인사이트를 제공합니다.
이 평가를 수행하기 위해 생성 AI 모델의 성능과 안전을 평가하기 위한 도구와 기능을 제공하는 포괄적인 플랫폼인 Azure AI Foundry 포털에서 평가 기능을 활용할 수 있습니다. AI Foundry 포털에서는 자세한 평가 메트릭을 기록, 보기 및 분석할 수 있습니다.
이 문서에서는 Azure AI Foundry UI의 기본 제공 평가 메트릭이 있는 모델, 테스트 데이터 세트 또는 흐름에 대해 평가 실행을 만드는 방법을 알아봅니다. 유연성을 높이기 위해 사용자 지정 평가 흐름을 설정하고 사용자 지정 평가 기능을 사용할 수 있습니다. 또는 평가 없이 일괄 처리 실행만 수행하는 것이 목표인 경우 사용자 지정 평가 기능을 활용할 수도 있습니다.
필수 조건
AI 지원 메트릭을 사용하여 평가를 실행하려면 다음을 준비해야 합니다.
csv또는jsonl형식 중 하나인 테스트 데이터 세트입니다.- Azure OpenAI 연결입니다. GPT 3.5 모델, GPT 4 모델 또는 Davinci 모델 중 하나를 배포합니다. AI 지원 품질 평가를 실행할 때만 필요합니다.
기본 제공 평가 메트릭을 사용하여 평가 만들기
평가 실행을 통해 테스트 데이터 세트의 각 데이터 행에 대한 메트릭 출력을 생성할 수 있습니다. 하나 이상의 평가 메트릭을 선택하여 다양한 측면에서 출력을 평가할 수 있습니다. AI Foundry 포털의 평가, 모델 카탈로그 또는 프롬프트 흐름 페이지에서 평가 실행을 만들 수 있습니다. 그런 다음, 평가 실행 설정 프로세스를 안내하는 평가 만들기 마법사가 나타납니다.
평가 페이지에서
축소 가능한 왼쪽 메뉴에서 Evaluation>+ 새 평가 만들기를 선택합니다.

모델 카탈로그 페이지에서
축소 가능한 왼쪽 메뉴에서 모델 카탈로그>를 선택하여 특정 모델로 > 이동하여 벤치마크 탭 > 으로 이동하여 사용자 고유의 데이터를 사용해 보세요. 그러면 선택한 모델에 대해 평가 실행을 만들 수 있는 모델 평가 패널이 열립니다.

흐름 페이지에서
축소 가능한 왼쪽 메뉴에서 프롬프트 흐름>평가>자동화된 평가를 선택합니다.

평가 대상
평가 페이지에서 평가를 시작할 경우, 먼저 평가 대상이 무엇인지 결정해야 합니다. 적절한 평가 대상을 지정하면 사용자의 애플리케이션의 구체적인 특성에 맞춰 평가를 조정하여 정확하고 관련성 있는 메트릭을 보장할 수 있습니다. 세 가지 유형의 평가 대상을 지원합니다.
- 모델 및 프롬프트: 선택한 모델 및 사용자 정의 프롬프트에서 생성된 출력을 평가하려고 합니다.
- 데이터 세트: 테스트 데이터 세트에 모델에서 생성된 출력이 이미 있습니다.
- 프롬프트 흐름: 흐름을 만들었고 흐름의 출력을 평가하려고 합니다.

데이터 세트 또는 프롬프트 흐름 평가
평가 만들기 마법사를 입력하면 평가 실행에 대한 선택적 이름을 제공할 수 있습니다. 현재 사용자 쿼리에 응답하고 컨텍스트 정보 유무에 관계없이 응답을 제공하는 애플리케이션을 위해 설계된 쿼리 및 응답 시나리오에 대한 지원을 제공합니다.
필요에 따라 향상된 조직, 컨텍스트 및 검색 용이성을 위해 평가 실행에 설명 및 태그를 추가할 수 있습니다.
도움말 패널을 사용하여 FAQ를 확인하고 마법사를 직접 안내할 수도 있습니다.

프롬프트 흐름을 평가하는 경우 평가할 흐름을 선택할 수 있습니다. 흐름 페이지에서 평가를 시작하면 평가할 흐름이 자동으로 선택됩니다. 다른 흐름을 평가하려는 경우 다른 흐름을 선택할 수 있습니다. 흐름 내에는 여러 노드가 있을 수 있으며 각 노드에는 고유한 변형 세트가 있을 수 있다는 점에 유의해야 합니다. 이러한 경우 평가 프로세스 중에 평가하려는 노드와 변형을 지정해야 합니다.

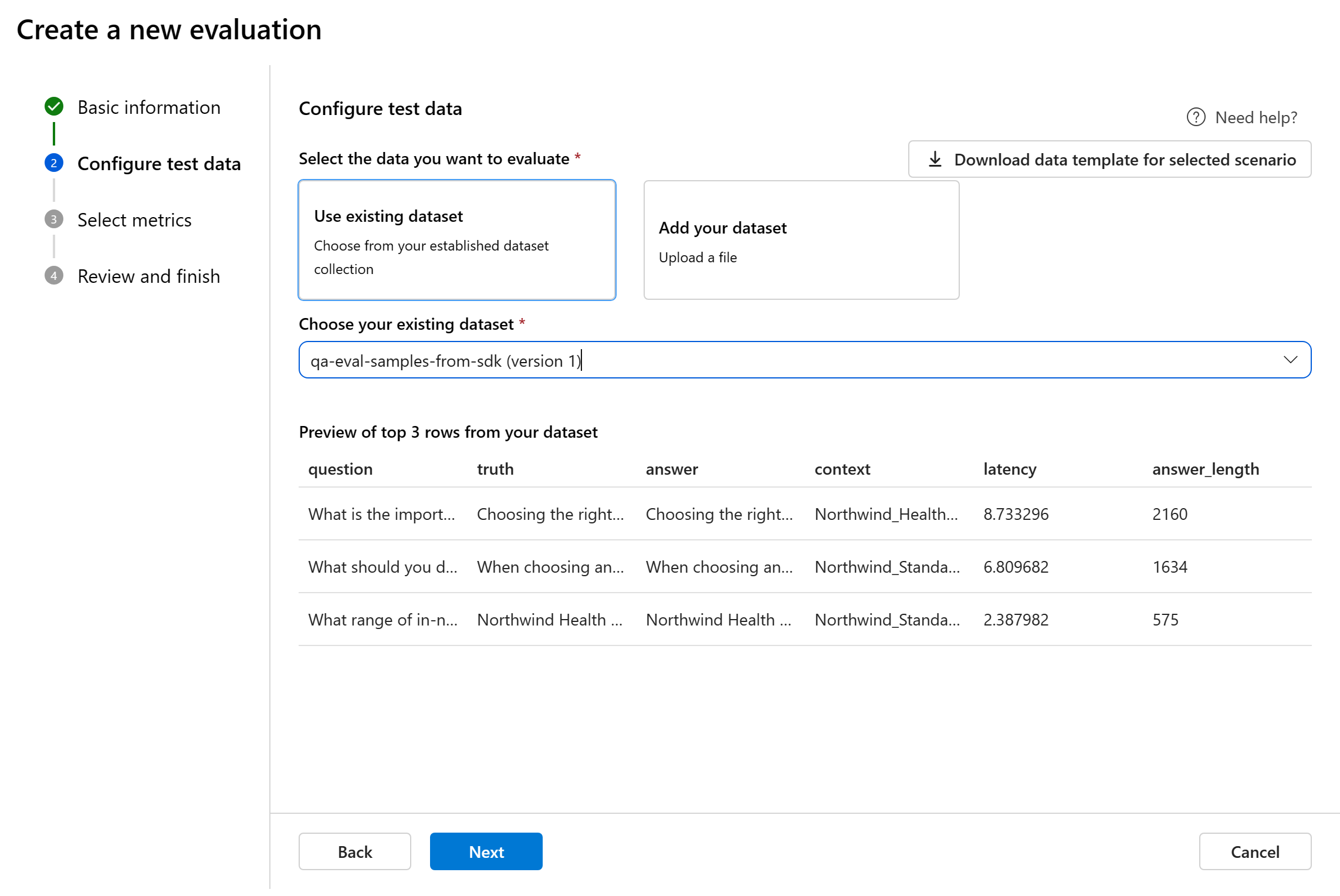
테스트 데이터 구성
기존 데이터 세트 중에서 선택하거나 특별히 평가할 새 데이터 세트를 업로드할 수 있습니다. 테스트 데이터 세트에는 이전 단계에서 선택한 흐름이 없는 경우 평가에 사용할 모델 생성 출력이 있어야 합니다.
기존 데이터 세트 선택: 설정된 데이터 세트 컬렉션에서 테스트 데이터 세트를 선택할 수 있습니다.
새 데이터 세트 추가: 로컬 스토리지에서 파일을 업로드할 수 있습니다.
.csv및.jsonl파일 형식만 지원합니다.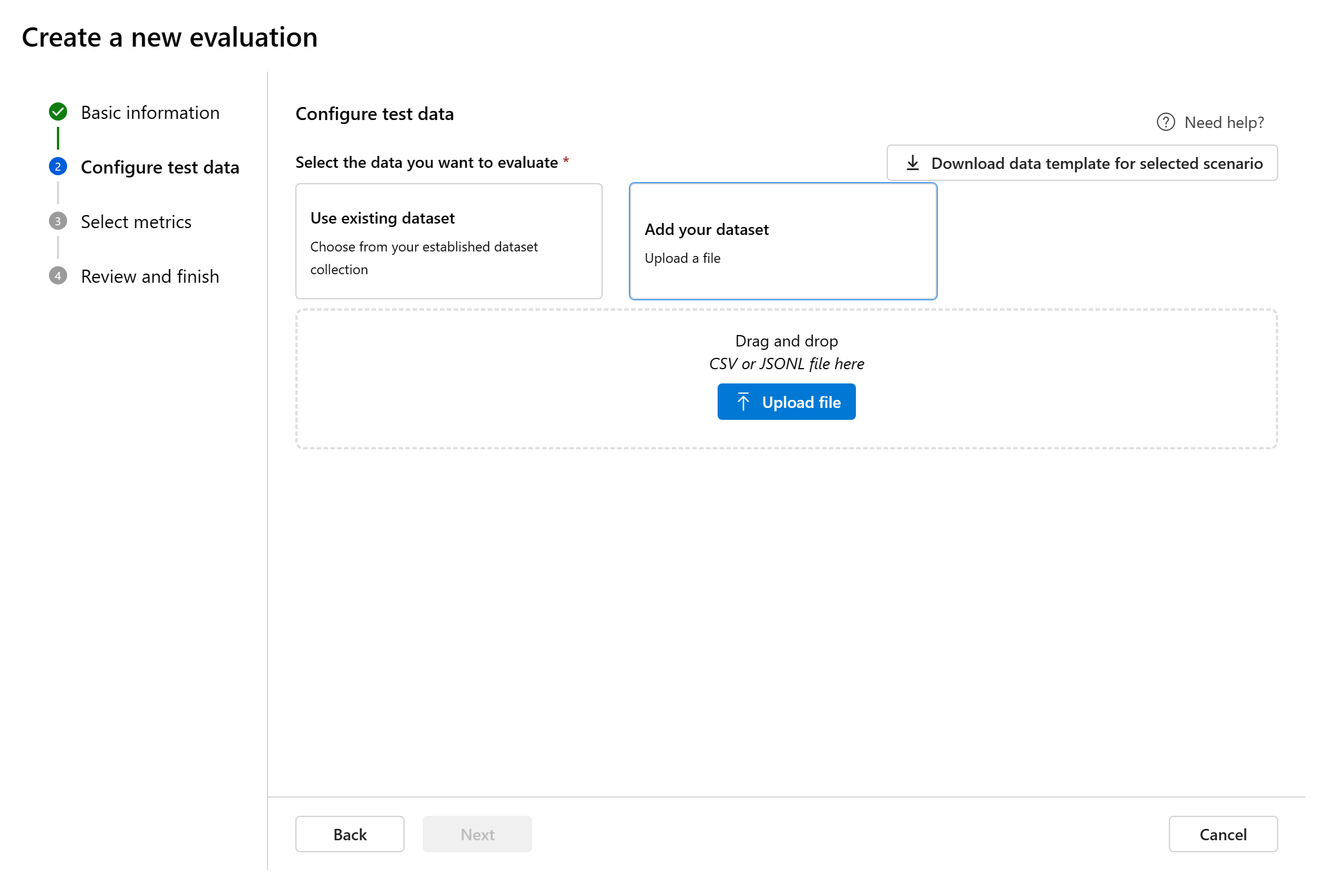
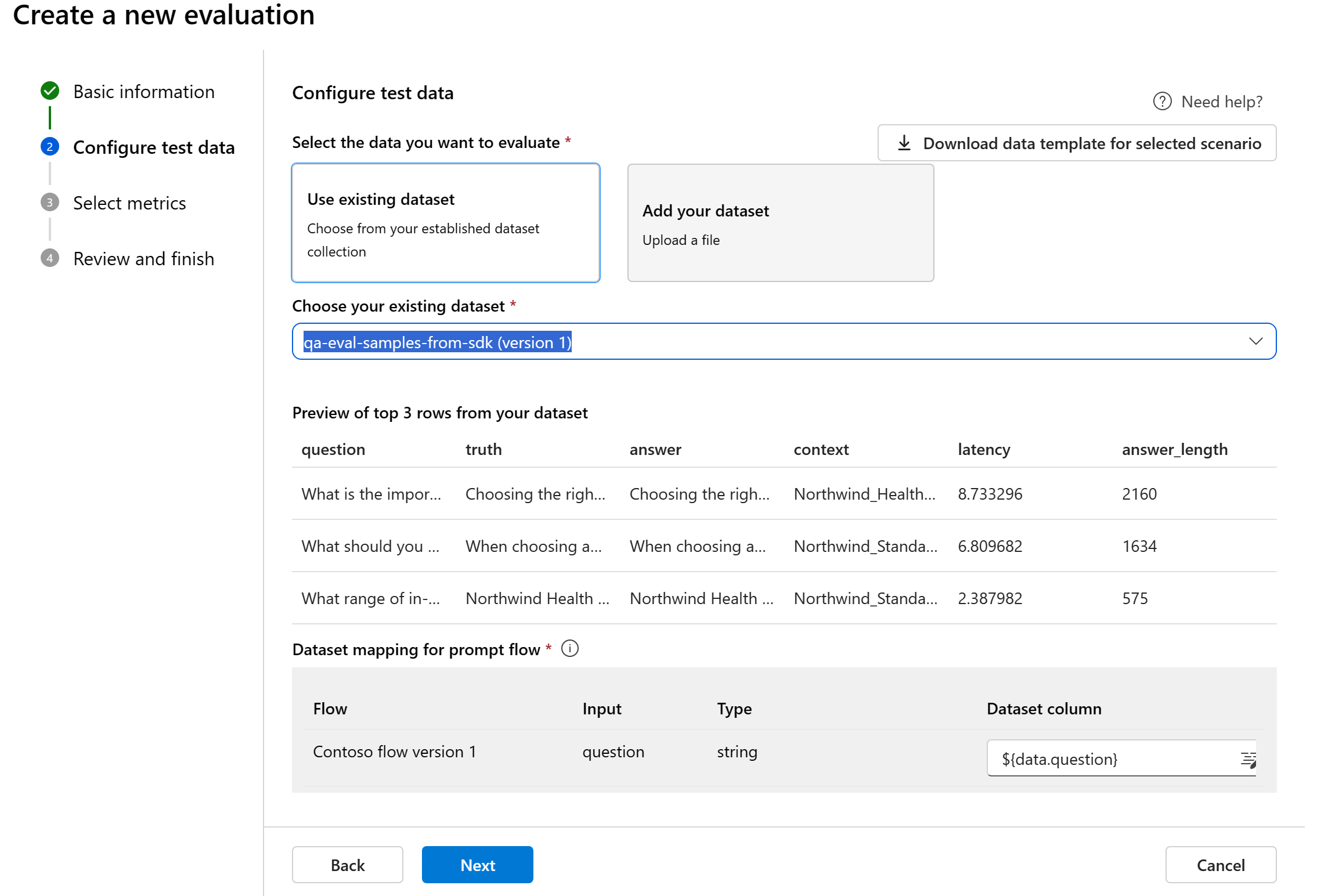
흐름을 위한 데이터 매핑: 평가할 흐름을 선택하는 경우 흐름에서 일괄 처리 실행을 실행하여 평가용 출력을 생성하는 데 필요한 입력과 일치하도록 데이터 열이 구성되어 있는지 확인합니다. 그런 다음 흐름의 출력을 사용하여 평가가 수행됩니다. 그런 다음, 다음 단계에서 평가 입력에 대한 데이터 매핑을 구성합니다.



메트릭 선택
Microsoft는 애플리케이션을 포괄적으로 평가하기 위해 Microsoft에서 큐레이팅한 세 가지 유형의 메트릭을 지원합니다.
- AI 품질(AI 지원): 이러한 메트릭은 생성된 콘텐츠의 전반적인 품질과 일관성을 평가합니다. 이러한 메트릭을 실행하려면 모델 배포가 판사로 필요합니다.
- NLP(AI 품질): 이러한 NLP 메트릭은 수학 기반이며 생성된 콘텐츠의 전반적인 품질도 평가합니다. 그들은 종종 지상 진실 데이터를 필요로하지만, 그들은 판사로 모델 배포를 필요로하지 않습니다.
- 위험 및 안전 메트릭: 이 메트릭은 잠재적인 콘텐츠 위험을 식별하고 생성된 콘텐츠의 안전을 보장하는 데 중점을 둡니다.

각 시나리오에서 지원을 제공하는 메트릭의 전체 목록을 보려면 표를 참조하세요. 각 메트릭 정의 및 계산 방법에 대한 자세한 내용은 메트릭 평가 및 모니터링을 참조하세요.
| AI 품질(AI 지원) | AI 품질(NLP) | 위험 및 안전 메트릭 |
|---|---|---|
| 접지, 관련성, 일관성, 유창성, GPT 유사성 | F1 점수, 루즈, 점수, BLEU 점수, GLEU 점수, 유성 점수 | 자해 관련 콘텐츠, 증오 및 불공정 콘텐츠, 폭력 콘텐츠, 성적 콘텐츠, 보호 자료, 간접 공격 |
AI 지원 품질 평가를 실행할 때는 계산 프로세스에 대한 GPT 모델을 지정해야 합니다. 계산을 위해 Azure OpenAI 연결과 GPT-3.5, GPT-4 또는 Davinci 모델을 사용한 배포를 선택합니다.

NLP(AI Quality) 메트릭은 애플리케이션의 성능을 평가하는 수학 기반 측정값입니다. 종종 계산을 위해 지상 진리 데이터가 필요합니다. ROUGE는 메트릭 제품군입니다. ROUGE 유형을 선택하여 점수를 계산할 수 있습니다. 다양한 유형의 ROUGE 메트릭은 텍스트 생성의 품질을 평가하는 방법을 제공합니다. ROUGE-N은 후보 텍스트와 참조 텍스트 간의 n-gram 겹침을 측정합니다.

위험 및 안전 메트릭의 경우 연결 및 배포를 제공할 필요가 없습니다. Azure AI Foundry 포털 안전 평가 백 엔드 서비스는 콘텐츠 위험 심각도 점수 및 추론을 생성하여 콘텐츠 피해에 대한 애플리케이션을 평가할 수 있는 GPT-4 모델을 프로비전합니다.
콘텐츠 피해 메트릭(자해 관련 콘텐츠, 증오 및 불공정 콘텐츠, 폭력 콘텐츠, 성적 콘텐츠)에 대한 결함률을 계산하기 위한 임계값을 설정할 수 있습니다. 결함률은 심각도 수준(매우 낮음, 낮음, 중간, 높음)이 임계값을 초과하는 인스턴스의 비율을 취하여 계산됩니다. 기본값으로 임계값은 “중간”으로 설정됩니다.
보호 자료 및 간접 공격의 경우 결함률은 출력이 'true'인 인스턴스의 백분율을 사용하여 계산됩니다(결함률 = (#trues/#instances) × 100).

참고 항목
AI 지원 위험 및 안전 메트릭은 Azure AI Foundry 안전 평가 백 엔드 서비스에서 호스팅되며 미국 동부 2, 프랑스 중부, 영국 남부, 스웨덴 중부 지역에서만 사용할 수 있습니다.
평가를 위한 데이터 매핑: 데이터 세트의 어떤 데이터 열이 평가에 필요한 입력과 일치하는지 지정해야 합니다. 다양한 평가 메트릭은 정확한 계산을 위해 고유한 형식의 데이터 입력이 필요합니다.

참고 항목
데이터에서 평가하는 경우 "응답"은 데이터 세트 ${data$response}의 응답 열에 매핑되어야 합니다. 흐름에서 평가하는 경우 흐름 출력 ${run.outputs.response}에서 "응답"이 와야 합니다.
각 메트릭에 대한 특정 데이터 매핑 요구 사항에 대한 지침은 표에 제공된 정보를 참조하세요.
쿼리 및 응답 메트릭 요구 사항
| 메트릭 | 쿼리 | 응답 | Context | 참값(Ground truth) |
|---|---|---|---|---|
| 접지 | 필수: Str | 필수: Str | 필수: Str | 해당 없음 |
| 일관성 | 필수: Str | 필수: Str | 해당 없음 | 해당 없음 |
| 유창성 | 필수: Str | 필수: Str | 해당 없음 | 해당 없음 |
| 정확도 | 필수: Str | 필수: Str | 필수: Str | 해당 없음 |
| GPT 유사성 | 필수: Str | 필수: Str | 해당 없음 | 필수: Str |
| F1 점수 | 해당 없음 | 필수: Str | 해당 없음 | 필수: Str |
| BLEU 점수 | 해당 없음 | 필수: Str | 해당 없음 | 필수: Str |
| GLEU 점수 | 해당 없음 | 필수: Str | 해당 없음 | 필수: Str |
| METEOR 점수 | 해당 없음 | 필수: Str | 해당 없음 | 필수: Str |
| ROUGE 점수 | 해당 없음 | 필수: Str | 해당 없음 | 필수: Str |
| 자해 관련 콘텐츠 | 필수: Str | 필수: Str | 해당 없음 | 해당 없음 |
| 증오스럽고 불공정한 콘텐츠 | 필수: Str | 필수: Str | 해당 없음 | 해당 없음 |
| 폭력적인 콘텐츠 | 필수: Str | 필수: Str | 해당 없음 | 해당 없음 |
| 성적인 콘텐츠 | 필수: Str | 필수: Str | 해당 없음 | 해당 없음 |
| 보호 재질 | 필수: Str | 필수: Str | 해당 없음 | 해당 없음 |
| 간접 공격 | 필수: Str | 필수: Str | 해당 없음 | 해당 없음 |
- 쿼리: 특정 정보를 찾는 쿼리입니다.
- 응답: 모델에서 생성된 쿼리에 대한 응답입니다.
- 컨텍스트: 응답이 생성되는 원본(즉, 접지 문서)...
- 기본 진실: 사용자/사람이 실제 답변으로 생성한 쿼리에 대한 응답입니다.
검토 및 완료
필요한 모든 구성을 완료한 후 검토하고 '제출'을 선택하여 평가 실행을 제출할 수 있습니다.

모델 및 프롬프트 평가
선택한 모델 배포 및 정의된 프롬프트에 대한 새 평가를 만들려면 간소화된 모델 평가 패널을 사용합니다. 이 간소화된 인터페이스를 사용하면 통합된 단일 패널 내에서 평가를 구성하고 시작할 수 있습니다.
기본 정보
시작하려면 평가 실행의 이름을 설정할 수 있습니다. 그런 다음 평가하려는 모델 배포를 선택합니다. Azure OpenAI 모델 및 MaaS(Model-as-a-Service)와 호환되는 기타 오픈 모델(예: Meta Llama 및 Phi-3 제품군 모델)을 모두 지원합니다. 필요에 따라 최대 응답, 온도 및 상위 P와 같은 모델 매개 변수를 조정할 수 있습니다.
시스템 메시지 텍스트 상자에서 시나리오에 대한 프롬프트를 제공합니다. 프롬프트를 만드는 방법에 대한 자세한 내용은 프롬프트 카탈로그를 참조하세요. 예제를 추가하여 채팅에 원하는 응답을 표시하도록 선택할 수 있습니다. 여기에 추가한 응답을 모방하여 시스템 메시지에 배치한 규칙과 일치하는지 확인합니다.

테스트 데이터 구성
모델 및 프롬프트를 구성한 후 평가에 사용할 테스트 데이터 세트를 설정합니다. 이 데이터 세트는 평가에 대한 응답을 생성하기 위해 모델로 전송됩니다. 테스트 데이터를 구성하는 세 가지 옵션이 있습니다.
- 샘플 데이터 생성
- 기존 데이터 세트 사용
- 데이터 세트 추가
데이터 세트를 쉽게 사용할 수 없고 작은 샘플로 평가를 실행하려는 경우 GPT 모델을 사용하여 선택한 항목에 따라 샘플 질문을 생성하는 옵션을 선택할 수 있습니다. 이 항목은 생성된 콘텐츠를 관심 분야에 맞게 조정하는 데 도움이 됩니다. 쿼리 및 응답은 실시간으로 생성되며 필요에 따라 다시 생성할 수 있습니다.
참고 항목
생성된 데이터 세트는 평가 실행이 만들어지면 프로젝트의 Blob Storage에 저장됩니다.

데이터 매핑
기존 데이터 세트를 사용하거나 새 데이터 세트를 업로드하도록 선택하는 경우 평가에 필요한 필드에 데이터 세트의 열을 매핑해야 합니다. 평가 중에 모델의 응답은 다음과 같은 주요 입력에 대해 평가됩니다.
- 쿼리: 모든 메트릭에 필요
- 컨텍스트: 선택 사항
- 접지 진실: 선택 사항, NLP(AI 품질) 메트릭에 필요
이러한 매핑은 데이터와 평가 조건 간의 정확한 맞춤을 보장합니다.

평가 메트릭 선택
마지막 단계는 평가할 항목을 선택하는 것입니다. 개별 메트릭을 선택하고 사용 가능한 모든 옵션을 숙지해야 하는 대신 요구 사항에 가장 적합한 메트릭 범주를 선택할 수 있도록 하여 프로세스를 간소화합니다. 범주를 선택하면 이전 단계에서 제공한 데이터 열을 기반으로 해당 범주 내의 모든 관련 메트릭이 계산됩니다. 메트릭 범주를 선택하면 "만들기"를 선택하여 평가 실행을 제출하고 평가 페이지로 이동하여 결과를 볼 수 있습니다.
다음 세 가지 범주를 지원합니다.
- AI 품질(AI 지원): AI 지원 메트릭을 계산하려면 Azure OpenAI 모델 배포를 판사로 제공해야 합니다.
- AI 품질(NLP)
- 안전
| AI 품질(AI 지원) | AI 품질(NLP) | 안전 |
|---|---|---|
| 근거(컨텍스트 필요), 관련성(컨텍스트 필요), 일관성, 유창성 | F1 점수, 루즈, 점수, BLEU 점수, GLEU 점수, 유성 점수 | 자해 관련 콘텐츠, 증오 및 불공정 콘텐츠, 폭력 콘텐츠, 성적 콘텐츠, 보호 자료, 간접 공격 |
사용자 지정 평가 흐름을 사용하여 평가 만들기
자체 평가 방법을 개발할 수 있습니다.
흐름 페이지에서: 축소 가능한 왼쪽 메뉴에서 프롬프트 흐름>평가>사용자 지정 평가를 선택합니다.

평가기 라이브러리에서 평가기 보기 및 관리
평가기 라이브러리는 평가기의 세부 정보와 상태를 볼 수 있는 중앙 집중식 위치입니다. Microsoft에서 큐레이팅한 평가기를 보고 관리할 수 있습니다.
팁
프롬프트 흐름 SDK를 통해 사용자 지정 평가기를 사용할 수 있습니다. 자세한 내용은 프롬프트 흐름 SDK 사용하여 평가를 참조하세요.
평가기 라이브러리를 사용하여 버전 관리도 가능합니다. 다른 버전의 작업과 비교하고, 필요한 경우 이전 버전을 복원하고, 다른 사용자와 더 쉽게 공동 작업할 수 있습니다.
AI Foundry 포털에서 평가기 라이브러리를 사용하려면 프로젝트의 평가 페이지로 이동하여 평가기 라이브러리 탭을 선택합니다.

평가기 이름을 선택하여 자세한 내용을 볼 수 있습니다. 이름, 설명, 매개 변수를 확인하고 평가기와 연결된 파일을 확인할 수 있습니다. 다음은 Microsoft에서 큐레이팅한 평가기의 몇 가지 예입니다.
- Microsoft에서 큐레이팅한 성능 및 품질 평가기의 경우 세부 정보 페이지에서 주석 프롬프트를 볼 수 있습니다. 데이터 및 목표에 따라 매개 변수 또는 조건을 변경하여 이러한 프롬프트를 사용자 고유의 사용 사례에 맞게 조정할 수 있습니다. 예를 들어 Groundedness-Evaluator를 선택하고 메트릭을 계산하는 방법을 보여 주는 프롬프트 파일을 확인할 수 있습니다.
- Microsoft에서 큐레이팅한 위험 및 안전 평가기의 경우 메트릭의 정의를 볼 수 있습니다. 예를 들어 자해 관련 콘텐츠 평가기를 선택하고 이 안전 메트릭의 의미와 Microsoft가 다양한 심각도 수준을 결정하는 방법을 알아볼 수 있습니다.
다음 단계
생성 AI 애플리케이션을 평가하는 방법에 대해 자세히 알아봅니다.