빠른 시작: 사용자 지정 키워드 만들기
참조 설명서 | 패키지(NuGet) | GitHub의 추가 샘플
이 빠른 시작에서는 사용자 지정 키워드 작업의 기본 사항을 알아봅니다. 키워드는 제품을 음성으로 활성화할 수 있는 단어 또는 짧은 구입니다. Speech Studio에서 키워드 모델을 만듭니다. 그런 다음 애플리케이션에서 Speech SDK와 함께 사용하는 모델 파일을 내보냅니다.
필수 구성 요소
- Azure 구독 무료로 하나를 만들 수 있습니다.
- Azure Portal에서 음성 리소스를 만듭니다.
- 음성 리소스 키 및 지역을 가져옵니다. 음성 리소스가 배포된 후, 리소스로 이동을 선택하여 키를 보고 관리합니다.
Speech Studio에서 키워드 만들기
사용자 지정 키워드를 사용하려면 Speech Studio에서 사용자 지정 키워드 페이지를 사용하여 키워드를 만들어야 합니다. 키워드를 제공한 후에는 Speech SDK에서 사용할 수 있는 .table 파일을 생성합니다.
Important
사용자 지정 키워드 모델 및 결과 .table 파일은 Speech Studio에서만 만들 수 있습니다.
SDK 또는 REST 호출을 사용하여 사용자 지정 키워드를 만들 수는 없습니다.
Speech Studio로 이동하여 로그인합니다. 음성 구독이 없으면 Speech Services 만들기로 이동합니다.
사용자 지정 키워드 페이지에서 새 프로젝트 만들기를 선택합니다.
사용자 지정 키워드 프로젝트의 이름, 설명 및 언어를 입력합니다. 프로젝트당 하나의 언어만 선택할 수 있으며 현재 지원은 영어(미국) 및 중국어(북경어, 간체)로 제한됩니다.

목록에서 프로젝트 이름을 선택합니다.
가상 도우미에 대한 사용자 지정 키워드를 만들려면 새 모델 만들기를 선택합니다.
모델의 이름, 설명 및 원하는 키워드를 입력하고 다음을 선택합니다. 효과적인 키워드 선택에 대한 지침을 참조하세요.
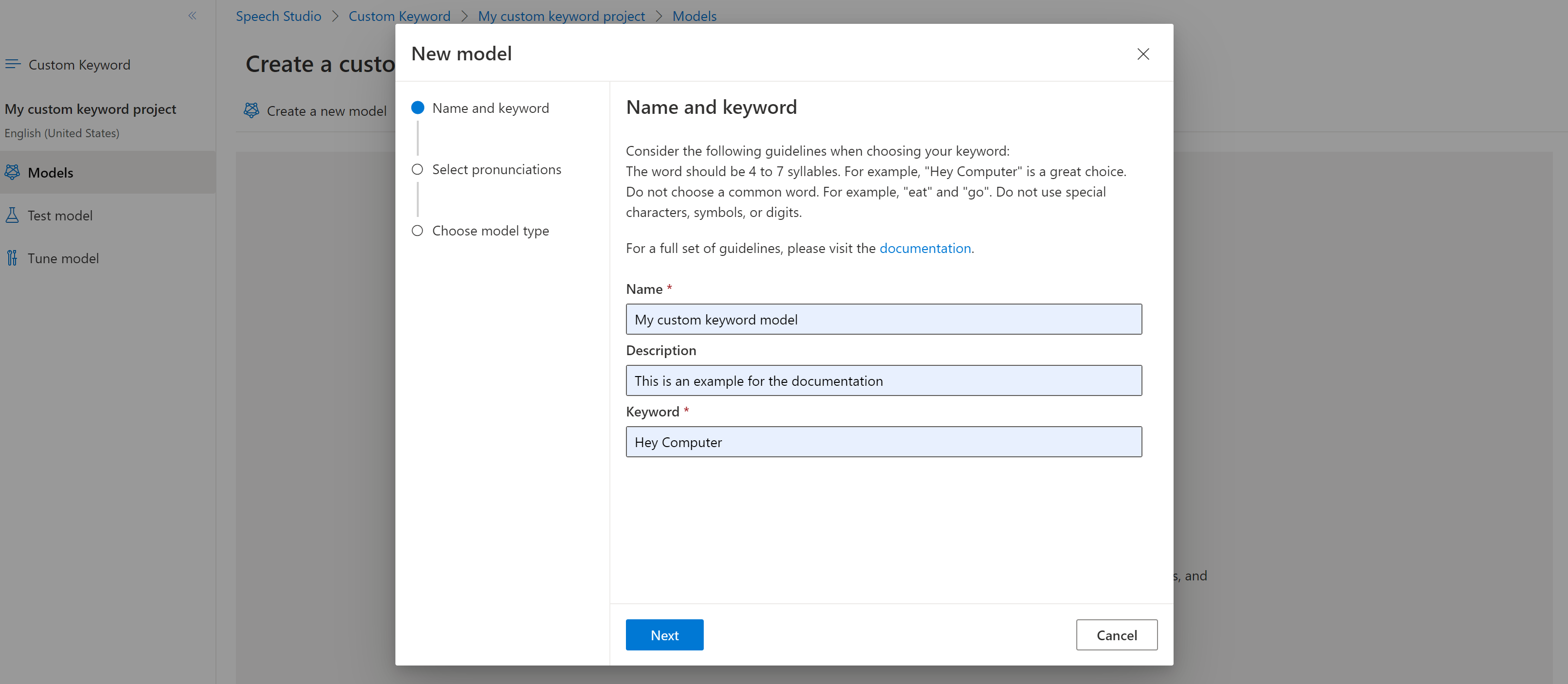
포털에서는 키워드에 대한 후보 발음을 만듭니다. 재생 단추를 선택하여 각 후보를 듣고 잘못된 발음 옆에 있는 확인 표시를 제거합니다. 사용자가 키워드를 말하는 방식에 해당하는 모든 발음을 선택한 후 다음을 선택하여 키워드 모델 생성을 시작합니다.

모델 유형을 선택한 다음 만들기를 선택합니다. 키워드 인식 영역 지원 문서에서 고급 모델 유형을 지원하는 지역 목록을 볼 수 있습니다.
모델이 생성되는 데 최대 30분이 소요될 수 있습니다. 모델이 완료되면 키워드 목록이 처리 중에서 성공으로 변경됩니다.

왼쪽의 축소 가능한 메뉴에서 모델을 조정하고 다운로드하는 조정 옵션을 선택합니다. 다운로드한 파일은
.zip압축 파일입니다. 압축 파일을 추출하면 확장명이.table인 파일이 표시됩니다. SDK와 함께.table파일을 사용하므로 해당 경로를 기록해 두세요.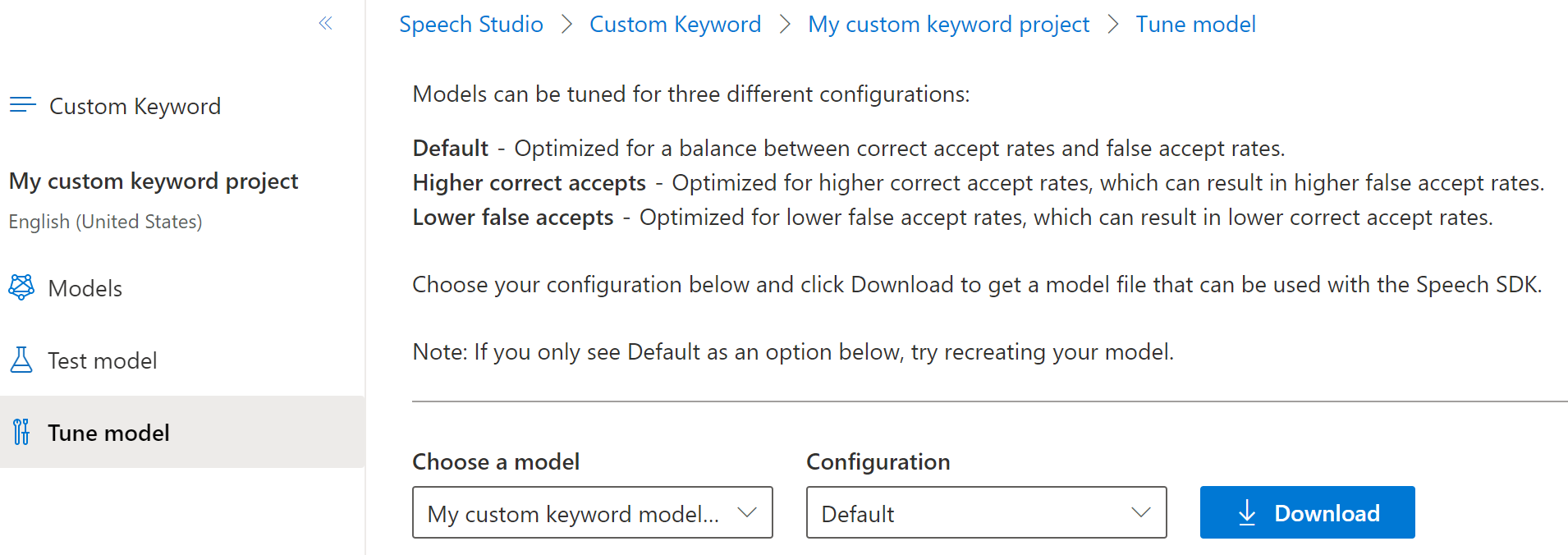
Speech SDK와 함께 키워드 모델 사용
먼저 KeywordRecognitionModel을 반환하는 FromFile() 정적 함수를 사용하여 키워드 모델 파일을 로드합니다. Speech Studio에서 다운로드한 .table 파일의 경로를 사용합니다. 또한 기본 마이크를 사용하여 AudioConfig를 만든 다음, 오디오 구성을 사용하여 새 KeywordRecognizer를 인스턴스화합니다.
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Audio;
var keywordModel = KeywordRecognitionModel.FromFile("your/path/to/Activate_device.table");
using var audioConfig = AudioConfig.FromDefaultMicrophoneInput();
using var keywordRecognizer = new KeywordRecognizer(audioConfig);
Important
AudioConfig.fromStreamInput() 메서드를 통해 오디오 샘플로 키워드 모델을 직접 테스트하려는 경우 첫 번째 키워드 앞에 최소 1.5초 동안 음소거되는 샘플을 사용해야 합니다. 이는 키워드 인식 엔진이 초기화되고 첫 번째 키워드를 검색하기 전에 수신 대기 상태로 돌아갈 수 있는 적절한 시간을 제공하기 위한 것입니다.
다음으로, 모델 개체를 전달하여 RecognizeOnceAsync()를 한 번 호출하면 키워드 인식이 실행됩니다. 이 메서드를 사용하면 키워드가 인식될 때까지 지속되는 키워드 인식 세션이 시작됩니다. 따라서 일반적으로 이 디자인 패턴은 다중 스레드 애플리케이션에서 사용하거나 절전 모드 해제 단어를 무기한 기다릴 수 있는 사용 사례에서 사용합니다.
KeywordRecognitionResult result = await keywordRecognizer.RecognizeOnceAsync(keywordModel);
참고 항목
여기에 표시된 예제에서는 인증 컨텍스트에 SpeechConfig 개체가 필요하지 않으며 백 엔드에 연결하지 않기 때문에 로컬 키워드 인식을 사용합니다. 그러나 직접 백 엔드 연결을 이용하여 키워드 인식 및 확인을 둘 다 실행할 수 있습니다.
연속 인식
Speech SDK의 다른 클래스는 키워드 인식을 통해 음성 및 의도 인식을 위한 연속 인식을 지원합니다. 이 SDK를 사용하면 키워드 모델의 .table 파일을 참조하는 기능을 통해 일반적으로 연속 인식에 사용하는 것과 동일한 코드를 사용할 수 있습니다.
음성 텍스트 변환의 경우 음성 인식 가이드에 표시된 것과 동일한 디자인 패턴을 따라 연속 인식을 설정합니다. 그런 다음, recognizer.StartContinuousRecognitionAsync() 호출을 recognizer.StartKeywordRecognitionAsync(KeywordRecognitionModel)로 바꾸고 KeywordRecognitionModel 개체를 전달합니다. 키워드 인식으로 연속 인식을 중지하려면 recognizer.StopContinuousRecognitionAsync() 대신 recognizer.StopKeywordRecognitionAsync()를 사용합니다.
의도 인식은 StartKeywordRecognitionAsync 및 StopKeywordRecognitionAsync 함수와 함께 동일한 패턴을 사용합니다.
참조 설명서 | 패키지(NuGet) | GitHub의 추가 샘플
C++용 Speech SDK는 키워드 인식을 지원하지만 아직 가이드가 여기에 포함되지 않았습니다. 다른 프로그래밍 언어를 선택해서 작업을 시작하고 개념을 알아보거나 이 문서의 앞 부분에 링크된 C++ 참조 및 샘플을 참조하세요.
작성자: eric-urban ms.service: azure-ai-speech ms.topic: include ms.date: 9/12/2024 ms.author: eur
- Azure 구독 무료로 하나를 만들 수 있습니다.
- Azure Portal에서 음성 리소스를 만듭니다.
- 음성 리소스 키 및 지역을 가져옵니다. 음성 리소스가 배포된 후, 리소스로 이동을 선택하여 키를 보고 관리합니다.
Speech Studio에서 키워드 만들기
사용자 지정 키워드를 사용하려면 Speech Studio에서 사용자 지정 키워드 페이지를 사용하여 키워드를 만들어야 합니다. 키워드를 제공한 후에는 Speech SDK에서 사용할 수 있는 .table 파일을 생성합니다.
Important
사용자 지정 키워드 모델 및 결과 .table 파일은 Speech Studio에서만 만들 수 있습니다.
SDK 또는 REST 호출을 사용하여 사용자 지정 키워드를 만들 수는 없습니다.
Speech Studio로 이동하여 로그인합니다. 음성 구독이 없으면 Speech Services 만들기로 이동합니다.
사용자 지정 키워드 페이지에서 새 프로젝트 만들기를 선택합니다.
사용자 지정 키워드 프로젝트의 이름, 설명 및 언어를 입력합니다. 프로젝트당 하나의 언어만 선택할 수 있으며 현재 지원은 영어(미국) 및 중국어(북경어, 간체)로 제한됩니다.
목록에서 프로젝트 이름을 선택합니다.
가상 도우미에 대한 사용자 지정 키워드를 만들려면 새 모델 만들기를 선택합니다.
모델의 이름, 설명 및 원하는 키워드를 입력하고 다음을 선택합니다. 효과적인 키워드 선택에 대한 지침을 참조하세요.
포털에서는 키워드에 대한 후보 발음을 만듭니다. 재생 단추를 선택하여 각 후보를 듣고 잘못된 발음 옆에 있는 확인 표시를 제거합니다. 사용자가 키워드를 말하는 방식에 해당하는 모든 발음을 선택한 후 다음을 선택하여 키워드 모델 생성을 시작합니다.
모델 유형을 선택한 다음 만들기를 선택합니다. 키워드 인식 영역 지원 문서에서 고급 모델 유형을 지원하는 지역 목록을 볼 수 있습니다.
모델이 생성되는 데 최대 30분이 소요될 수 있습니다. 모델이 완료되면 키워드 목록이 처리 중에서 성공으로 변경됩니다.
왼쪽의 축소 가능한 메뉴에서 모델을 조정하고 다운로드하는 조정 옵션을 선택합니다. 다운로드한 파일은
.zip압축 파일입니다. 압축 파일을 추출하면 확장명이.table인 파일이 표시됩니다. SDK와 함께.table파일을 사용하므로 해당 경로를 기록해 두세요.
Speech SDK와 함께 키워드 모델 사용
Go SDK에서 사용자 지정 키워드 모델을 사용하는 방법에 대해서는 참조 설명서를 참조하세요.
Java용 Speech SDK는 키워드 인식을 지원하지만 아직 가이드가 여기에 포함되지 않았습니다. 다른 프로그래밍 언어를 선택해서 작업을 시작하고 개념을 알아보거나 이 문서의 앞 부분에 링크된 Java 참조 및 샘플을 참조하세요.
참조 설명서 | 패키지(npm) | GitHub의 추가 샘플 | 라이브러리 소스 코드
JavaScript용 Speech SDK는 키워드 인식을 지원하지 않습니다. 다른 프로그래밍 언어를 선택하거나 이 문서의 앞 부분에서 링크된 JavaScript 참조 및 샘플을 참조하세요.
참조 설명서 | 패키지(다운로드) | GitHub의 추가 샘플
이 빠른 시작에서는 사용자 지정 키워드 작업의 기본 사항을 알아봅니다. 키워드는 제품을 음성으로 활성화할 수 있는 단어 또는 짧은 구입니다. Speech Studio에서 키워드 모델을 만듭니다. 그런 다음 애플리케이션에서 Speech SDK와 함께 사용하는 모델 파일을 내보냅니다.
필수 구성 요소
- Azure 구독 무료로 하나를 만들 수 있습니다.
- Azure Portal에서 음성 리소스를 만듭니다.
- 음성 리소스 키 및 지역을 가져옵니다. 음성 리소스가 배포된 후, 리소스로 이동을 선택하여 키를 보고 관리합니다.
Speech Studio에서 키워드 만들기
사용자 지정 키워드를 사용하려면 Speech Studio에서 사용자 지정 키워드 페이지를 사용하여 키워드를 만들어야 합니다. 키워드를 제공한 후에는 Speech SDK에서 사용할 수 있는 .table 파일을 생성합니다.
Important
사용자 지정 키워드 모델 및 결과 .table 파일은 Speech Studio에서만 만들 수 있습니다.
SDK 또는 REST 호출을 사용하여 사용자 지정 키워드를 만들 수는 없습니다.
Speech Studio로 이동하여 로그인합니다. 음성 구독이 없으면 Speech Services 만들기로 이동합니다.
사용자 지정 키워드 페이지에서 새 프로젝트 만들기를 선택합니다.
사용자 지정 키워드 프로젝트의 이름, 설명 및 언어를 입력합니다. 프로젝트당 하나의 언어만 선택할 수 있으며 현재 지원은 영어(미국) 및 중국어(북경어, 간체)로 제한됩니다.
목록에서 프로젝트 이름을 선택합니다.
가상 도우미에 대한 사용자 지정 키워드를 만들려면 새 모델 만들기를 선택합니다.
모델의 이름, 설명 및 원하는 키워드를 입력하고 다음을 선택합니다. 효과적인 키워드 선택에 대한 지침을 참조하세요.
포털에서는 키워드에 대한 후보 발음을 만듭니다. 재생 단추를 선택하여 각 후보를 듣고 잘못된 발음 옆에 있는 확인 표시를 제거합니다. 사용자가 키워드를 말하는 방식에 해당하는 모든 발음을 선택한 후 다음을 선택하여 키워드 모델 생성을 시작합니다.
모델 유형을 선택한 다음 만들기를 선택합니다. 키워드 인식 영역 지원 문서에서 고급 모델 유형을 지원하는 지역 목록을 볼 수 있습니다.
모델이 생성되는 데 최대 30분이 소요될 수 있습니다. 모델이 완료되면 키워드 목록이 처리 중에서 성공으로 변경됩니다.
왼쪽의 축소 가능한 메뉴에서 모델을 조정하고 다운로드하는 조정 옵션을 선택합니다. 다운로드한 파일은
.zip압축 파일입니다. 압축 파일을 추출하면 확장명이.table인 파일이 표시됩니다. SDK와 함께.table파일을 사용하므로 해당 경로를 기록해 두세요.
Speech SDK와 함께 키워드 모델 사용
Objective C SDK에서 사용자 지정 키워드 모델 사용하려면 GitHub의 샘플을 참조하세요.
참조 설명서 | 패키지(다운로드) | GitHub의 추가 샘플
이 빠른 시작에서는 사용자 지정 키워드 작업의 기본 사항을 알아봅니다. 키워드는 제품을 음성으로 활성화할 수 있는 단어 또는 짧은 구입니다. Speech Studio에서 키워드 모델을 만듭니다. 그런 다음 애플리케이션에서 Speech SDK와 함께 사용하는 모델 파일을 내보냅니다.
필수 구성 요소
- Azure 구독 무료로 하나를 만들 수 있습니다.
- Azure Portal에서 음성 리소스를 만듭니다.
- 음성 리소스 키 및 지역을 가져옵니다. 음성 리소스가 배포된 후, 리소스로 이동을 선택하여 키를 보고 관리합니다.
Speech Studio에서 키워드 만들기
사용자 지정 키워드를 사용하려면 Speech Studio에서 사용자 지정 키워드 페이지를 사용하여 키워드를 만들어야 합니다. 키워드를 제공한 후에는 Speech SDK에서 사용할 수 있는 .table 파일을 생성합니다.
Important
사용자 지정 키워드 모델 및 결과 .table 파일은 Speech Studio에서만 만들 수 있습니다.
SDK 또는 REST 호출을 사용하여 사용자 지정 키워드를 만들 수는 없습니다.
Speech Studio로 이동하여 로그인합니다. 음성 구독이 없으면 Speech Services 만들기로 이동합니다.
사용자 지정 키워드 페이지에서 새 프로젝트 만들기를 선택합니다.
사용자 지정 키워드 프로젝트의 이름, 설명 및 언어를 입력합니다. 프로젝트당 하나의 언어만 선택할 수 있으며 현재 지원은 영어(미국) 및 중국어(북경어, 간체)로 제한됩니다.
목록에서 프로젝트 이름을 선택합니다.
가상 도우미에 대한 사용자 지정 키워드를 만들려면 새 모델 만들기를 선택합니다.
모델의 이름, 설명 및 원하는 키워드를 입력하고 다음을 선택합니다. 효과적인 키워드 선택에 대한 지침을 참조하세요.
포털에서는 키워드에 대한 후보 발음을 만듭니다. 재생 단추를 선택하여 각 후보를 듣고 잘못된 발음 옆에 있는 확인 표시를 제거합니다. 사용자가 키워드를 말하는 방식에 해당하는 모든 발음을 선택한 후 다음을 선택하여 키워드 모델 생성을 시작합니다.
모델 유형을 선택한 다음 만들기를 선택합니다. 키워드 인식 영역 지원 문서에서 고급 모델 유형을 지원하는 지역 목록을 볼 수 있습니다.
모델이 생성되는 데 최대 30분이 소요될 수 있습니다. 모델이 완료되면 키워드 목록이 처리 중에서 성공으로 변경됩니다.
왼쪽의 축소 가능한 메뉴에서 모델을 조정하고 다운로드하는 조정 옵션을 선택합니다. 다운로드한 파일은
.zip압축 파일입니다. 압축 파일을 추출하면 확장명이.table인 파일이 표시됩니다. SDK와 함께.table파일을 사용하므로 해당 경로를 기록해 두세요.
Speech SDK와 함께 키워드 모델 사용
Objective C SDK에서 사용자 지정 키워드 모델 사용하려면 GitHub의 샘플을 참조하세요. 현재 패리티에 대한 Swift 샘플이 없지만 개념은 비슷합니다.
참고 항목
iOS의 Swift 애플리케이션에서 키워드 인식을 사용하려는 경우 Speech Studio에서 만든 새 키워드 모델에는 Speech SDK xcframework 번들 https://aka.ms/csspeech/iosbinaryembedded 또는 MicrosoftCognitiveServicesSpeechEmbedded-iOS 프로젝트의 Pod를 사용해야 합니다.
참조 설명서 | 패키지(PyPi) | GitHub의 추가 샘플
이 빠른 시작에서는 사용자 지정 키워드 작업의 기본 사항을 알아봅니다. 키워드는 제품을 음성으로 활성화할 수 있는 단어 또는 짧은 구입니다. Speech Studio에서 키워드 모델을 만듭니다. 그런 다음 애플리케이션에서 Speech SDK와 함께 사용하는 모델 파일을 내보냅니다.
필수 구성 요소
- Azure 구독 무료로 하나를 만들 수 있습니다.
- Azure Portal에서 음성 리소스를 만듭니다.
- 음성 리소스 키 및 지역을 가져옵니다. 음성 리소스가 배포된 후, 리소스로 이동을 선택하여 키를 보고 관리합니다.
Speech Studio에서 키워드 만들기
사용자 지정 키워드를 사용하려면 Speech Studio에서 사용자 지정 키워드 페이지를 사용하여 키워드를 만들어야 합니다. 키워드를 제공한 후에는 Speech SDK에서 사용할 수 있는 .table 파일을 생성합니다.
Important
사용자 지정 키워드 모델 및 결과 .table 파일은 Speech Studio에서만 만들 수 있습니다.
SDK 또는 REST 호출을 사용하여 사용자 지정 키워드를 만들 수는 없습니다.
Speech Studio로 이동하여 로그인합니다. 음성 구독이 없으면 Speech Services 만들기로 이동합니다.
사용자 지정 키워드 페이지에서 새 프로젝트 만들기를 선택합니다.
사용자 지정 키워드 프로젝트의 이름, 설명 및 언어를 입력합니다. 프로젝트당 하나의 언어만 선택할 수 있으며 현재 지원은 영어(미국) 및 중국어(북경어, 간체)로 제한됩니다.
목록에서 프로젝트 이름을 선택합니다.
가상 도우미에 대한 사용자 지정 키워드를 만들려면 새 모델 만들기를 선택합니다.
모델의 이름, 설명 및 원하는 키워드를 입력하고 다음을 선택합니다. 효과적인 키워드 선택에 대한 지침을 참조하세요.
포털에서는 키워드에 대한 후보 발음을 만듭니다. 재생 단추를 선택하여 각 후보를 듣고 잘못된 발음 옆에 있는 확인 표시를 제거합니다. 사용자가 키워드를 말하는 방식에 해당하는 모든 발음을 선택한 후 다음을 선택하여 키워드 모델 생성을 시작합니다.
모델 유형을 선택한 다음 만들기를 선택합니다. 키워드 인식 영역 지원 문서에서 고급 모델 유형을 지원하는 지역 목록을 볼 수 있습니다.
모델이 생성되는 데 최대 30분이 소요될 수 있습니다. 모델이 완료되면 키워드 목록이 처리 중에서 성공으로 변경됩니다.
왼쪽의 축소 가능한 메뉴에서 모델을 조정하고 다운로드하는 조정 옵션을 선택합니다. 다운로드한 파일은
.zip압축 파일입니다. 압축 파일을 추출하면 확장명이.table인 파일이 표시됩니다. SDK와 함께.table파일을 사용하므로 해당 경로를 기록해 두세요.
Speech SDK와 함께 키워드 모델 사용
Python SDK에서 사용자 지정 키워드 모델 사용하려면 GitHub의 샘플을 참조하세요.
음성 텍스트 변환 REST API 참조 | 짧은 오디오 참조를 위한 음성 텍스트 변환 REST API | GitHub의 추가 샘플
음성 텍스트 변환 REST API는 키워드 인식을 지원하지 않습니다. 다른 프로그래밍 언어를 선택하거나 이 문서의 앞 부분에서 링크된 참조 및 샘플을 참조하세요.
Speech CLI는 키워드 인식을 지원하지만 아직 가이드가 여기에 포함되지 않았습니다. 다른 프로그래밍 언어를 선택하여 작업을 시작하고 개념에 대해 알아보세요.