성능 및 대기 시간
이 문서에서는 Azure OpenAI에서 대기 시간 및 처리량이 작동하는 방식과 성능을 향상시키기 위해 환경을 최적화하는 방법에 대한 배경 정보를 제공합니다.
처리량 및 대기 시간 이해
애플리케이션 크기를 조정하는 경우 고려해야 할 두 가지 주요 개념이 있습니다. (1) TPM(분당 토큰)으로 측정된 시스템 수준 처리량과 (2) 호출당 응답 시간(대기 시간이라고도 함).
시스템 수준 처리량
여기서는 배포의 전체 용량, 즉 분당 요청 수와 처리할 수 있는 총 토큰 수가 표시됩니다.
표준 배포의 경우 배포에 할당된 할당량이 달성 가능한 처리량 크기에 어느 정도 영향을 미칩니다. 그러나 할당량은 배포 호출에 대한 허용 논리에만 영향을 주며 처리량에 직접 작용하지는 않습니다. 호출당 대기 시간 변화로 인해 할당량만큼 높은 처리량을 달성하지 못할 수 있습니다. 할당량 관리에 대해 자세히 알아봅니다.
프로비전된 배포에서 모델 처리 용량의 집합 양이 엔드포인트에 할당됩니다. 엔드포인트에서 달성할 수 있는 처리량은 입력 토큰 양, 출력 양, 호출 속도 및 캐시 일치 속도를 포함한 워크로드 셰이프의 요소입니다. 동시 호출 수와 처리된 총 토큰 수는 이러한 값에 따라 달라질 수 있습니다.
모든 배포 유형에서 시스템 수준 처리량 이해는 성능 최적화의 핵심 구성 요소입니다. 처리량이 이러한 요인에 따라 달라지므로 지정된 모델, 버전 및 워크로드 조합에 대한 시스템 수준 처리량을 고려하는 것이 중요합니다.
시스템 수준 처리량 예측
Azure Monitor 메트릭을 사용하여 TPM 예측
지정된 워크로드의 시스템 수준 처리량을 예측하는 한 가지 방법은 기록 토큰 사용량 현황 데이터를 사용하는 것입니다. Azure OpenAI 워크로드의 경우 Azure OpenAI 내에서 제공되는 네이티브 모니터링 기능을 사용하여 모든 기록 사용량 현황 데이터에 액세스하고 시각화할 수 있습니다. Azure OpenAI 워크로드에 대한 시스템 수준 처리량을 예측하려면 (1) 처리된 프롬프트 토큰과 (2) 생성된 완료 토큰이라는 두 가지 메트릭이 필요합니다.
결합 된 경우 처리된 프롬프트 토큰 (입력 TPM) 및 생성된 완료 토큰 (출력 TPM) 메트릭은 실제 워크로드 트래픽에 따라 시스템 수준 처리량의 예상 보기를 제공합니다. 이 방법은 프롬프트 캐싱의 이점을 고려하지 않으므로 보수적인 시스템 처리량 추정치가 됩니다. 이러한 메트릭은 여러 주 기간 동안 1분 동안 최소, 평균 및 최대 집계를 사용하여 분석할 수 있습니다. 평가하기에 충분한 데이터 요소가 있는지 확인하기 위해 몇 주 동안 이 데이터를 분석하는 것이 좋습니다. 다음 스크린샷은 Azure Portal을 통해 직접 사용할 수 있는 Azure Monitor에서 시각화된 처리된 프롬프트 토큰 메트릭의 예를 보여 줍니다.
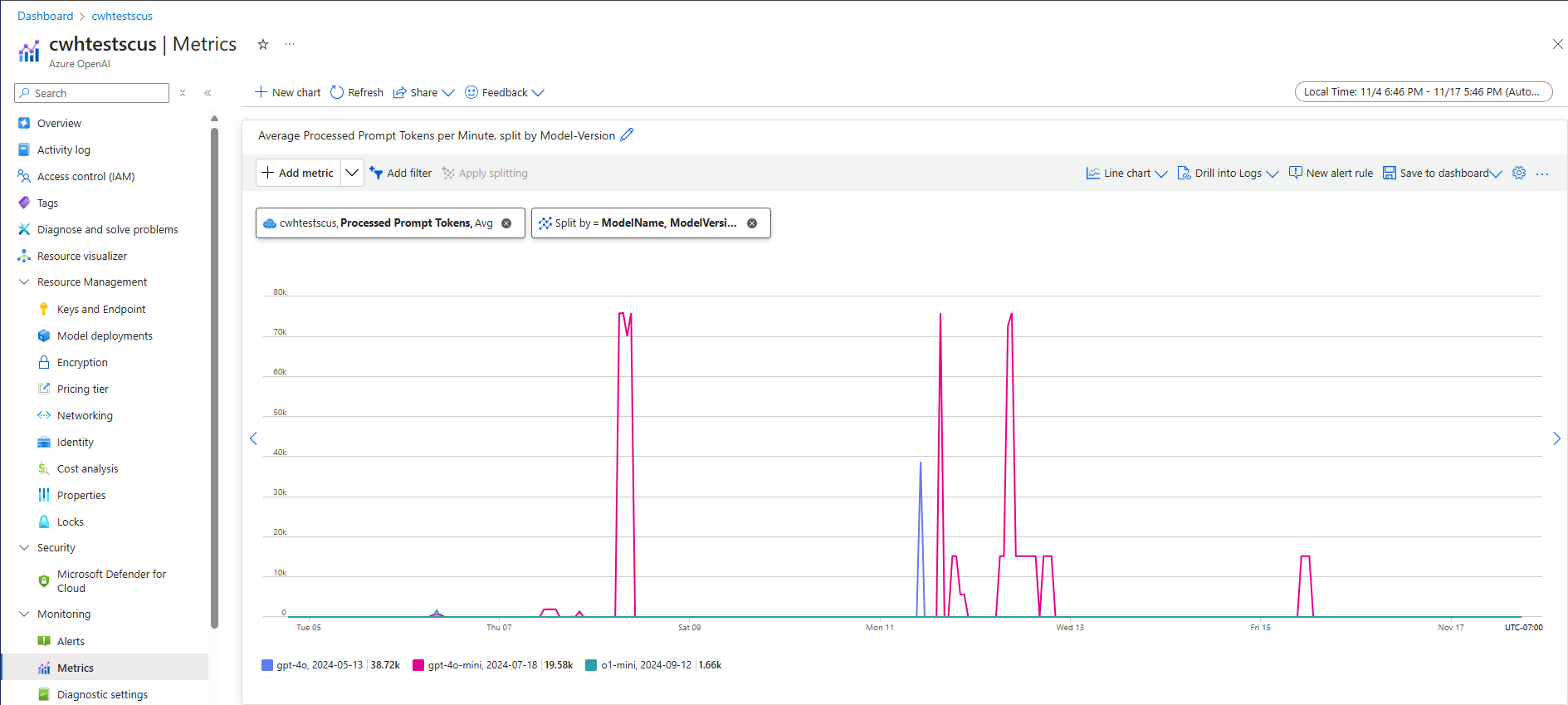
요청 데이터에서 TPM 예측
예상 시스템 수준 처리량에 대한 두 번째 방법은 API 요청 데이터에서 토큰 사용량 정보를 수집하는 것입니다. 이 메서드는 요청당 워크로드 모양을 이해하는 보다 세분화된 접근 방식을 제공합니다. 요청별 토큰 사용량 정보를 RPM(분당 요청 단위)으로 측정된 요청 볼륨과 결합하면 시스템 수준 처리량에 대한 추정치가 제공됩니다. 요청 및 요청 볼륨에서 토큰 사용량 정보의 일관성을 위해 만들어진 모든 가정은 시스템 처리량 예측에 영향을 줍니다. 토큰 사용량 출력 데이터는 지정된 Azure OpenAI Service 채팅 완료 요청에 대한 API 응답 세부 정보에서 찾을 수 있습니다.
{
"body": {
"id": "chatcmpl-7R1nGnsXO8n4oi9UPz2f3UHdgAYMn",
"created": 1686676106,
"choices": [...],
"usage": {
"completion_tokens": 557,
"prompt_tokens": 33,
"total_tokens": 590
}
}
}
지정된 워크로드에 대한 모든 요청이 균일하다고 가정하면 API 응답 데이터의 프롬프트 토큰 및 완료 토큰을 각각 예상 RPM에 곱하여 지정된 워크로드에 대한 입력 및 출력 TPM을 식별할 수 있습니다.
시스템 수준 처리량 예상치를 사용하는 방법
지정된 워크로드에 대해 시스템 수준 처리량이 예측되면 이러한 예상을 사용하여 표준 및 프로비전된 배포의 크기를 지정할 수 있습니다. 표준 배포의 경우 입력 및 출력 TPM 값을 결합하여 지정된 배포에 할당할 총 TPM을 예측할 수 있습니다. 프로비전된 배포의 경우 요청 토큰 사용량 데이터 또는 입력 및 출력 TPM 값을 사용하여 배포 용량 계산기 환경에서 지정된 워크로드를 지원하는 데 필요한PTU 수를 예측할 수 있습니다.
GPT-4o 미니 모델에 대한 몇 가지 예는 다음과 같습니다.
| 프롬프트 크기(토큰) | 생성 크기(토큰) | 분당 요청 수 | 입력 TPM | 출력 TPM | 총 TPM | 필요한 PTU |
|---|---|---|---|---|---|---|
| 800 | 150 | 30 | 24,000 | 4,500 | 28,500 | 15 |
| 5,000 | 50 | 1,000 | 5,000,000 | 50,000 | 5,050,000 | 140 |
| 1,000 | 300 | 500 | 500,000 | 150,000 | 650,000 | 30 |
워크로드 배포가 일정하게 유지되는 경우 PTU 수는 호출 속도로 대략 선형적으로 확장됩니다.
대기 시간: 호출당 응답 시간
이 컨텍스트에서 대기 시간을 대략적으로 정의하면 모델에서 응답을 다시 가져오는 데 걸리는 시간으로 나타낼 수 있습니다. 완료 및 채팅 완료 요청의 경우 대기 시간은 주로 모델 유형, 프롬프트의 토큰 수 및 생성된 토큰 수에 따라 달라집니다. 일반적으로 각 프롬프트 토큰은 생성된 각 증분 토큰에 비해 약간의 시간을 추가합니다.
이러한 모델에서는 호출당 예상 대기 시간을 예측하는 것이 어려울 수 있습니다. 완료 요청의 대기 시간은 네 가지 주요 요인인 (1) 모델, (2) 프롬프트의 토큰 수, (3) 생성된 토큰 수 및 (4) 배포 및 시스템의 전체 부하에 따라 달라질 수 있습니다. 1과 3이 총 시간이 주로 기여합니다. 다음 섹션에서는 큰 언어 모델 유추 호출의 구조에 대해 좀 더 자세히 알아봅니다.
성능 향상
애플리케이션의 호출당 대기 시간을 개선하기 위해 제어할 수 있는 몇 가지 요소가 있습니다.
모델 선택
대기 시간은 사용 중인 모델에 따라 달라집니다. 동일한 요청의 경우 서로 다른 모델에서 채팅 완료 호출에 대한 대기 시간이 다를 것으로 예상합니다. 사용 사례에 가장 빠른 응답 시간과 가장 짧은 대기 시간 모델이 필요한 경우 최신 GPT-4o mini 모델을 사용하는 것이 좋습니다.
생성 크기 및 최대 토큰
Azure OpenAI 엔드포인트에 완료 요청을 보내면 입력 텍스트가 배포된 모델로 전송되는 토큰으로 변환됩니다. 모델은 입력 토큰을 받은 다음, 응답 생성을 시작합니다. 반복적인 순차 프로세스이며 한 번에 하나의 토큰이 있습니다. 이것을 n tokens = n iterations의 for 루프처럼 생각할 수 있습니다. 대부분의 모델에서 응답 생성은 프로세스에서 가장 느린 단계입니다.
요청 시 요청된 생성 크기(max_tokens 매개 변수)가 생성 크기의 초기 예측값으로 사용됩니다. 전체 크기를 생성하는 컴퓨팅 시간은 요청이 처리될 때 모델에 의해 예약됩니다. 생성이 완료되면 나머지 할당량이 해제됩니다. 토큰 수를 줄이는 방법은 다음과 같습니다.
- 각 호출의
max_tokens매개 변수를 가능한 한 작게 설정합니다. - 추가 콘텐츠 생성을 방지하기 위한 중지 시퀀스를 포함합니다.
- 더 적은 응답 생성: best_of 및 n 매개 변수는 여러 출력을 생성하기 때문에 대기 시간을 크게 늘릴 수 있습니다. 가장 빠른 응답의 경우 이러한 값을 지정하거나 1로 설정하지 마세요.
요약하면 요청당 생성된 토큰 수를 줄이면 각 요청의 대기 시간이 줄어듭니다.
스트리밍
요청에서 stream: true를 설정하면 서비스는 전체 토큰 시퀀스가 생성될 때까지 기다리지 않고 토큰이 사용 가능해진 즉시 토큰을 반환합니다. 모든 토큰을 가져오는 시간은 달라지지 않지만 첫 번째 응답 시간이 줄어듭니다. 이 방법은 최종 사용자가 생성되는 응답을 읽을 수 있으므로 더 나은 사용자 환경을 제공합니다.
스트리밍은 처리하는 데 시간이 오래 걸리는 큰 호출에서도 유용합니다. 많은 클라이언트 및 중간 계층에는 개별 호출에 대한 시간 제한이 있습니다. 클라이언트 쪽 시간 초과로 인해 장기 생성 호출이 취소될 수 있습니다. 데이터를 다시 스트리밍하면 증분 데이터가 수신되는지 확인할 수 있습니다.
스트리밍을 사용하는 경우의 예
채팅 봇 및 대화형 인터페이스.
스트리밍은 인식된 대기 시간에 영향을 줍니다. 스트리밍을 사용하도록 설정하면 토큰이 사용 가능해지는 즉시 청크로 다시 받습니다. 최종 사용자의 경우 요청을 완료하기 위한 전체 시간은 동일하게 유지되더라도 모델이 더 빠르게 응답하는 것처럼 느껴지는 경우가 많습니다.
스트리밍이 덜 중요한 경우의 예:
감정 분석, 언어 번역, 콘텐츠 생성.
실시간 응답이 아니라 완료된 결과에만 관심이 있는 대량 작업을 수행하는 많은 사용 사례가 있습니다. 스트리밍을 사용하지 않도록 설정하면 모델이 전체 응답을 완료할 때까지 토큰을 받지 않습니다.
콘텐츠 필터링
Azure OpenAI에는 핵심 모델과 함께 작동하는 콘텐츠 필터링 시스템이 포함되어 있습니다. 이 시스템은 유해한 콘텐츠의 출력을 탐지하고 방지하기 위한 분류 모델의 앙상블을 통해 프롬프트와 완료를 모두 실행하여 작동합니다.
콘텐츠 필터링 시스템은 입력 프롬프트와 출력 완료 모두에서 잠재적으로 유해한 콘텐츠의 특정 범주를 탐지하고 조치를 취합니다.
콘텐츠 필터링을 추가하면 안전성뿐만 아니라 대기 시간도 증가합니다. 이러한 성능 절충이 필요한 애플리케이션이 많이 있지만 성능 향상을 위해 콘텐츠 필터를 사용하지 않도록 설정해야 하는 저위험 사용 사례가 있습니다.
기본 콘텐츠 필터링 정책에 대한 수정을 요청하는 방법에 대해 자세히 알아봅니다.
워크로드 분리
동일한 엔드포인트에서 다른 워크로드를 혼합하면 대기 시간에 부정적인 영향을 줄 수 있습니다. 이는 (1) 유추 중에 함께 일괄 처리되고 짧은 호출이 더 긴 완료를 기다릴 수 있고 (2) 호출을 혼합하면 둘 다 동일한 공간을 위해 경쟁하므로 캐시 적중률이 줄어들 수 있기 때문입니다. 가능하면 각 워크로드에 대해 별도의 배포를 사용하는 것이 좋습니다.
프롬프트 크기
프롬프트 크기는 생성 크기보다 대기 시간에 미치는 영향이 적지만, 특히 크기가 커지는 경우 전체 시간에 영향을 줍니다.
일괄 처리
동일한 엔드포인트에 여러 요청을 보내는 경우 요청을 단일 호출로 일괄 처리할 수 있습니다. 이렇게 하면 수행해야 하는 요청 수가 줄어들고 시나리오에 따라 전반적인 응답 시간이 향상될 수 있습니다. 이 방법을 테스트하여 도움이 되는지 확인하는 것이 좋습니다.
처리량을 측정하는 방법
다음 두 가지 측정값을 사용하여 배포의 전체 처리량을 측정하는 것이 좋습니다.
- 분당 호출 수: 분당 API 유추 호출 수입니다. Azure OpenAI 요청 메트릭을 사용하고 ModelDeploymentName으로 분할하여 Azure-monitor에서 측정할 수 있습니다.
- 분당 총 토큰 수: 배포에서 분당 처리되는 총 토큰 수입니다. 여기에는 프롬프트 및 생성된 토큰이 포함됩니다. 배포 성능을 보다 깊이 있게 이해하기 위해 둘 다를 측정하는 방식으로 추가로 분할하는 경우가 많습니다. 처리된 유추 토큰 메트릭을 사용하여 Azure-Monitor에서 측정할 수 있습니다.
Azure OpenAI 서비스 모니터링에 대해 자세히 알아볼 수 있습니다.
호출당 대기 시간을 측정하는 방법
각 호출에 걸리는 시간은 모델을 읽고, 출력을 생성하고, 콘텐츠 필터를 적용하는 데 걸리는 시간에 따라 달라집니다. 스트리밍을 사용하는지 여부에 따라 시간을 측정하는 방법이 달라집니다. 각 사례에 대해 다른 측정값 집합을 제안합니다.
Azure OpenAI 서비스 모니터링에 대해 자세히 알아볼 수 있습니다.
비스트리밍:
- 엔드투엔드 요청 시간: API 게이트웨이에서 측정한 대로 비스트리밍 요청에 대한 전체 응답을 생성하는 데 걸린 총 시간입니다. 프롬프트 및 생성 크기가 증가함에 따라 이 수치가 증가합니다.
스트리밍:
- 응답 시간: 요청 스트리밍에 권장되는 대기 시간(응답성) 측정값입니다. PTU 및 PTU 관리형 배포에 적용됩니다. API 게이트웨이에서 측정한 대로 사용자가 프롬프트를 보낸 후 첫 번째 응답이 표시되는 데 걸린 시간으로 계산됩니다. 프롬프트 크기가 증가하거나 적중 크기가 감소하면 이 수치가 증가합니다.
- 첫 번째 토큰에서 마지막 토큰까지의 평균 토큰 생성 속도 시간을 API 게이트웨이에서 측정한, 생성된 토큰 수로 나눈 값입니다. 이렇게 하면 응답 생성 속도가 측정되며, 이 값은 시스템 부하가 증가함에 따라 증가합니다. 요청 스트리밍에 권장되는 대기 시간 측정값입니다.
요약
모델 대기 시간: 모델 대기 시간이 중요한 경우 GPT-4o mini 모델을 사용해 보는 것이 좋습니다.
최대 토큰 감소: OpenAI는 생성된 총 토큰 수가 비슷한 경우에도 최대 토큰 매개 변수에 대해 더 높은 값이 설정된 요청의 대기 시간이 더 긴 것으로 나타났습니다.
생성된 총 토큰 감소: 생성된 토큰 수가 적을수록 전체 응답이 더 빨라집니다. 이는
n tokens = n iterations에서 for 루프를 사용하는 것과 같습니다. 생성된 토큰 수를 줄이면 전반적인 응답 시간이 그에 따라 향상됩니다.스트리밍: 스트리밍을 사용하도록 설정하면 마지막 토큰이 준비될 때까지 기다리지 않고도 생성되는 모델 응답을 볼 수 있도록 하여 특정 상황에서 사용자가 더 나은 결과를 예상할 수 있도록 하는 데 유용할 수 있습니다.
콘텐츠 필터링은 안전성을 향상시키지만 대기 시간에도 영향을 줍니다. 워크로드가 수정된 콘텐츠 필터링 정책의 이점을 활용할 수 있는지 평가합니다.