온-프레미스에서 요약 Docker 컨테이너 사용
컨테이너를 사용하면 자체 인프라에서 요약 API를 호스트할 수 있습니다. 원격으로 요약을 호출하여 충족할 수 없는 보안 또는 데이터 거버넌스 요구 사항이 있는 경우 컨테이너가 좋은 옵션이 될 수 있습니다.
필수 조건
- Azure 구독이 없는 경우 무료 계정을 만드세요.
- 호스트 컴퓨터에 설치된 Docker. Docker는 컨테이너에서 Azure에 연결하여 청구 데이터를 보낼 수 있도록 구성해야 합니다.
- Windows에서 Docker는 Linux 컨테이너를 지원하도록 구성해야 합니다.
- Docker 개념에 대한 기본적으로 이해하고 있어야 합니다.
- 무료(F0) 또는 표준(S) 가격 책정 계층이 있는 언어 리소스. 연결이 끊긴 컨테이너의 경우 DC0 계층이 필요합니다.
필수 매개 변수 수집
모든 Azure AI 컨테이너에는 세 가지 기본 매개 변수가 필요합니다. Microsoft Software 사용 조건에는 동의 값이 있어야 합니다. 엔드포인트 URI 및 API 키도 필요합니다.
엔드포인트 URI
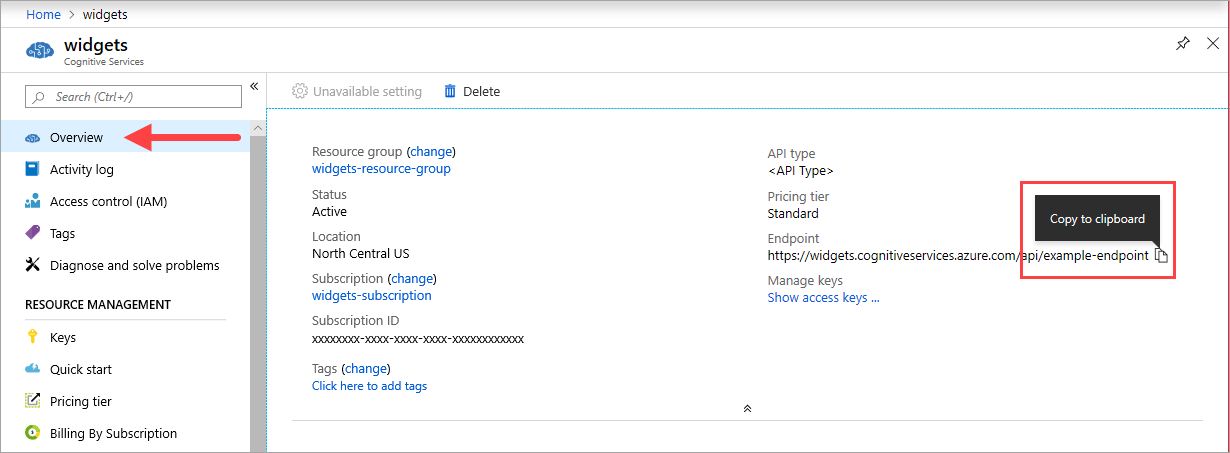
{ENDPOINT_URI} 값은 해당 Azure AI 서비스 리소스의 Azure Portal 개요 페이지에서 확인할 수 있습니다.
개요 페이지로 이동하여 엔드포인트를 마우스로 가리키고 클립보드에 복사 아이콘이 나타납니다. 필요한 경우 엔드포인트를 복사하여 사용합니다.
구성
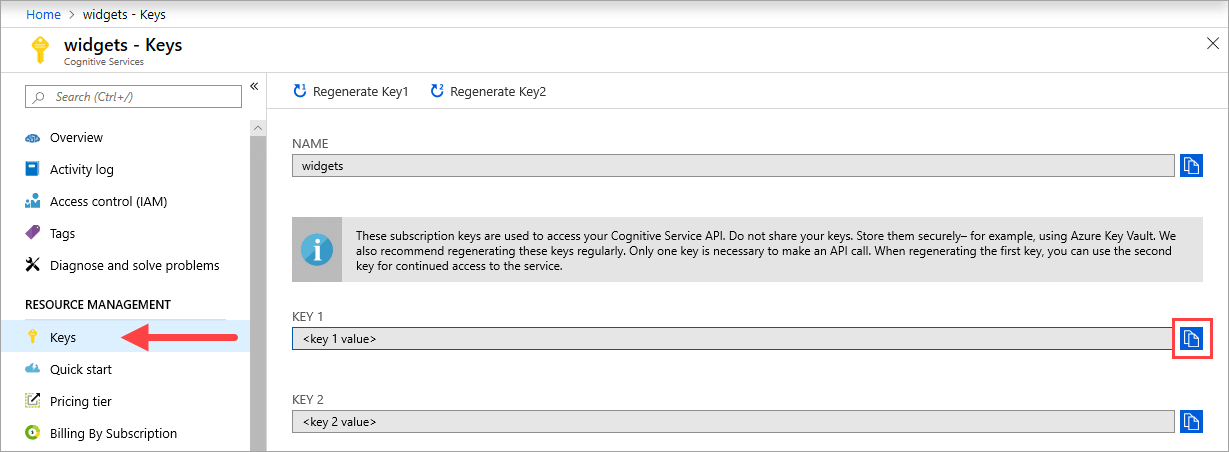
{API_KEY} 값은 컨테이너를 시작하는 데 사용되며 해당 Azure AI 서비스 리소스에 대한 Azure portal의 키 페이지에서 사용할 수 있습니다.
키 페이지로 이동하여 클립보드에 복사 아이콘을 선택합니다.
Important
이러한 구독 키는 Azure AI 서비스 API에 액세스하는 데 사용됩니다. 키를 공유하지 마세요. 안전하게 저장하세요. 예를 들어 Azure Key Vault를 사용합니다. 또한 이러한 키를 정기적으로 다시 생성하는 것이 좋습니다. API 호출을 수행하는 데는 키가 하나만 필요합니다. 첫 번째 키를 다시 생성하는 경우 두 번째 키를 사용하여 서비스에 계속 액세스할 수 있습니다.
호스트 컴퓨터 요구 사항 및 권장 사항
호스트는 Docker 컨테이너를 실행하는 x64 기반 컴퓨터입니다. 다음과 같이 Azure에서 컴퓨터 온-프레미스 또는 Docker 호스팅 서비스일 수 있습니다.
- Azure Kubernetes Service.
- Azure Container Instances.
- Kubernetes 클러스터는 Azure Stack에 배포됩니다. 자세한 내용은 Azure Stack에 Kubernetes 배포를 참조하세요.
다음 표에서는 요약 컨테이너 기술에 대한 최소 및 권장 사양을 설명합니다. 나열된 CPU/메모리 조합은 4,000개의 토큰 입력을 위한 것입니다(대화 사용은 동일한 요청의 모든 측면에 대해 사용됨).
| 컨테이너 유형 | 권장되는 CPU 코어 수 | 권장 메모리 | 주의 |
|---|---|---|---|
| 요약 CPU 컨테이너 | 16 | 48GB | |
| 요약 GPU 컨테이너 | 2 | 24GB | 16GB VRAM으로 Cuda 11.8을 지원하는 NVIDIA GPU가 필요합니다. |
docker run 명령의 일부로 사용되는 --cpus 및 --memory 설정에 해당하는 CPU 코어 및 메모리.
docker pull을 사용하여 컨테이너 이미지 가져오기
요약 컨테이너 이미지는 mcr.microsoft.com 컨테이너 레지스트리 신디케이트에서 찾을 수 있습니다.
azure-cognitive-services/textanalytics/ 리포지토리 내에 있으며 이름은 summarization입니다. 전체 컨테이너 이미지 이름은 mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization입니다.
최신 버전의 컨테이너를 사용하려면 latest 태그를 사용할 수 있습니다.
MCR에서 태그의 전체 목록을 찾을 수도 있습니다.
docker pull 명령을 사용하여 Microsoft Container Registry에서 컨테이너 이미지를 다운로드합니다.
docker pull mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:cpu
CPU 컨테이너의 경우
docker pull mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:gpu
GPU 컨테이너의 경우
팁
docker images 명령을 사용하여 다운로드한 컨테이너 이미지를 나열할 수 있습니다. 예를 들어 다음 명령은 다운로드한 각 컨테이너 이미지의 ID, 리포지토리 및 태그를 테이블 형식으로 나열합니다.
docker images --format "table {{.ID}}\t{{.Repository}}\t{{.Tag}}"
IMAGE ID REPOSITORY TAG
<image-id> <repository-path/name> <tag-name>
요약 컨테이너 모델 다운로드
요약 컨테이너를 실행하기 위한 필수 조건은 모델을 먼저 다운로드하는 것입니다. 예를 들어 CPU 컨테이너 이미지를 사용하여 다음 명령 중 하나를 실행하여 이 작업을 수행할 수 있습니다.
docker run -v {HOST_MODELS_PATH}:/models mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:cpu downloadModels=ExtractiveSummarization billing={ENDPOINT_URI} apikey={API_KEY}
docker run -v {HOST_MODELS_PATH}:/models mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:cpu downloadModels=AbstractiveSummarization billing={ENDPOINT_URI} apikey={API_KEY}
docker run -v {HOST_MODELS_PATH}:/models mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:cpu downloadModels=ConversationSummarization billing={ENDPOINT_URI} apikey={API_KEY}
컨테이너가 HOST_MODELS_PATH 내의 모든 모델을 로드하므로 동일한 HOST_MODELS_PATH 내의 모든 기술에 대한 모델을 다운로드하는 것은 권장되지 않습니다. 이렇게 하면 많은 양의 메모리가 사용됩니다. 특정 HOST_MODELS_PATH에 필요한 기술에 대한 모델만 다운로드하는 것이 좋습니다.
모델과 컨테이너 간의 호환성을 보장하기 위해 새 이미지 버전을 사용하여 컨테이너를 만들 때마다 활용된 모델을 다시 다운로드합니다. 연결이 끊긴 컨테이너를 사용하는 경우 모델을 다운로드한 후 라이선스를 다시 다운로드해야 합니다.
docker run을 사용하여 컨테이너 실행
호스트 컴퓨터에 요약 컨테이너가 있으면 다음 docker run 명령을 사용하여 컨테이너를 실행합니다. 컨테이너는 중지할 때까지 계속 실행됩니다. 다음 자리 표시자를 고유한 값으로 바꿉니다.
| 자리 표시자 | 값 | 형식 또는 예 |
|---|---|---|
| {HOST_MODELS_PATH} | Docker에서 모델을 유지하는 데 사용하는 호스트 컴퓨터 볼륨 탑재입니다. | 예를 들면 c:\SummarizationModel입니다. 여기서 c:\ 드라이브는 호스트 컴퓨터에 있습니다. |
| {ENDPOINT_URI} | 요약 API에 액세스하기 위한 엔드포인트입니다. Azure Portal의 리소스 키 및 엔드포인트 페이지에서 이 값을 찾을 수 있습니다. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
| {API_KEY} | 언어 리소스의 키입니다. Azure Portal의 리소스 키 및 엔드포인트 페이지에서 이 값을 찾을 수 있습니다. | xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx |
docker run -p 5000:5000 -v {HOST_MODELS_PATH}:/models mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:cpu eula=accept rai_terms=accept billing={ENDPOINT_URI} apikey={API_KEY}
또는 GPU 컨테이너를 실행하는 경우 대신 이 명령을 사용합니다.
docker run -p 5000:5000 --gpus all -v {HOST_MODELS_PATH}:/models mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:gpu eula=accept rai_terms=accept billing={ENDPOINT_URI} apikey={API_KEY}
컴퓨터에 둘 이상의 GPU가 있는 경우 --gpus all을 --gpus device={DEVICE_ID}로 바꿉니다.
Important
- 다음 섹션에서 Docker 명령은 줄 연속 문자 같은 백 슬래시,
\을 사용합니다. 호스트 운영 체제의 요구 사항에서 이 기준을 바꾸거나 제거합니다. - 컨테이너를 실행하려면
Eula,Billing,rai_terms및ApiKey옵션을 지정해야 합니다. 그렇지 않으면 컨테이너가 시작되지 않습니다. 자세한 내용은 Billing을 참조하세요.
이 명령은 다음을 수행합니다.
- 컨테이너 이미지에서 요약 컨테이너를 실행합니다.
- 1개 CPU 코어 및 4GB 메모리 할당
- 5000 TCP 포트 표시 및 컨테이너에 의사-TTY 할당
- 종료 후 자동으로 컨테이너를 제거합니다. 컨테이너 이미지는 호스트 컴퓨터에서 계속 사용할 수 있습니다.
동일한 호스트에서 여러 컨테이너 실행
노출된 포트로 여러 컨테이너를 실행하려는 경우, 각 컨테이너를 다른 노출된 포트로 실행해야 합니다. 예를 들어 첫 번째 컨테이너는 포트 5000에서 실행하고 두 번째 컨테이너는 포트 5001에서 실행합니다.
이 컨테이너와 다른 Azure AI 서비스 컨테이너를 HOST에서 함께 실행할 수 있습니다. 동일한 Azure AI 서비스 컨테이너의 여러 컨테이너를 실행할 수도 있습니다.
컨테이너의 예측 엔드포인트 쿼리
컨테이너는 REST 기반 쿼리 예측 엔드포인트 API를 제공합니다.
컨테이너 API에 대한 호스트 http://localhost:5000을 사용합니다.
컨테이너가 실행 중인지 확인
컨테이너가 실행되고 있는지 확인하는 방법은 여러 가지가 있습니다. 확인 대상인 컨테이너의 외부 IP 주소 및 노출된 포트를 찾고 즐겨 찾는 웹 브라우저를 엽니다. 아래의 다양한 요청 URL을 사용하여 컨테이너가 실행되는지 확인합니다. 여기에 나열된 예제 요청 URL은 http://localhost:5000이지만, 특정 컨테이너는 다를 수 있습니다. 컨테이너의 외부 IP 주소 및 공개된 포트를 사용해야 합니다.
| 요청 URL | 용도 |
|---|---|
http://localhost:5000/ |
컨테이너는 홈페이지를 제공합니다. |
http://localhost:5000/ready |
GET을 사용하여 요청된 이 URL에서 컨테이너가 모델에 대한 쿼리를 수락할 준비가 되었음을 확인합니다. 이 요청은 Kubernetes 활동성 및 준비 상태 프로브에 사용될 수 있습니다. |
http://localhost:5000/status |
또한 GET을 사용하여 요청된 이 URL은 컨테이너를 시작하는 데 사용된 API 키가 엔드포인트 쿼리를 수행하지 않고 유효한지 확인합니다. 이 요청은 Kubernetes 활동성 및 준비 상태 프로브에 사용될 수 있습니다. |
http://localhost:5000/swagger |
컨테이너는 엔드포인트에 대한 전체 설명서 세트와 사용해 보기 기능을 제공합니다. 이 기능을 사용하면 웹 기반 HTML 양식으로 설정을 입력할 수 있고 코드 작성 없이 쿼리를 만들 수 있습니다. 쿼리가 반환되면 필요한 HTTP 헤더 및 본문 형식을 보여주기 위해 예제 CURL 명령이 제공됩니다. |
인터넷 연결이 끊어진 컨테이너 실행
인터넷에서 연결이 끊긴 이 컨테이너를 사용하려면 먼저 신청서를 작성하고 약정 플랜을 구매하여 액세스를 요청해야 합니다. 자세한 내용은 연결되지 않은 환경에서 Docker 컨테이너 사용을 참조하세요.
인터넷 연결이 끊어진 컨테이너를 실행하도록 승인된 경우 자리 표시자 값과 함께 사용할 docker run 명령의 형식을 보여주는 다음 예를 사용하세요. 이러한 자리 표시자 값을 고유한 값으로 바꿉니다.
docker run 명령의 DownloadLicense=True 매개 변수는 Docker 컨테이너가 인터넷에 연결되어 있지 않을 때 실행할 수 있도록 하는 라이선스 파일을 다운로드합니다. 또한 만료 날짜가 포함되어 있으며 이후에는 라이선스 파일이 컨테이너를 실행할 수 없게 됩니다. 승인된 적절한 컨테이너에만 라이선스 파일을 사용할 수 있습니다. 예를 들어, 언어 서비스 컨테이너가 있는 음성 텍스트 변환 컨테이너용 라이선스 파일을 사용할 수 없습니다.
연결이 끊긴 요약 컨테이너 모델 다운로드
요약 컨테이너를 실행하기 위한 필수 조건은 모델을 먼저 다운로드하는 것입니다. 예를 들어 CPU 컨테이너 이미지를 사용하여 다음 명령 중 하나를 실행하여 이 작업을 수행할 수 있습니다.
docker run -v {HOST_MODELS_PATH}:/models mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:cpu downloadModels=ExtractiveSummarization billing={ENDPOINT_URI} apikey={API_KEY}
docker run -v {HOST_MODELS_PATH}:/models mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:cpu downloadModels=AbstractiveSummarization billing={ENDPOINT_URI} apikey={API_KEY}
docker run -v {HOST_MODELS_PATH}:/models mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:cpu downloadModels=ConversationSummarization billing={ENDPOINT_URI} apikey={API_KEY}
컨테이너가 HOST_MODELS_PATH 내의 모든 모델을 로드하므로 동일한 HOST_MODELS_PATH 내의 모든 기술에 대한 모델을 다운로드하는 것은 권장되지 않습니다. 이렇게 하면 많은 양의 메모리가 사용됩니다. 특정 HOST_MODELS_PATH에 필요한 기술에 대한 모델만 다운로드하는 것이 좋습니다.
모델과 컨테이너 간의 호환성을 보장하기 위해 새 이미지 버전을 사용하여 컨테이너를 만들 때마다 활용된 모델을 다시 다운로드합니다. 연결이 끊긴 컨테이너를 사용하는 경우 모델을 다운로드한 후 라이선스를 다시 다운로드해야 합니다.
docker run을 사용하여 연결이 끊긴 컨테이너 실행
| 자리 표시자 | 값 | 형식 또는 예 |
|---|---|---|
{IMAGE} |
사용하려는 컨테이너 이미지입니다. | mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:cpu |
{LICENSE_MOUNT} |
라이선스가 다운로드되고 탑재될 경로입니다. | /host/license:/path/to/license/directory |
{HOST_MODELS_PATH} |
모델을 다운로드하고 탑재한 경로입니다. | /host/models:/models |
{ENDPOINT_URI} |
서비스 요청을 인증하기 위한 엔드포인트입니다. Azure Portal의 리소스 키 및 엔드포인트 페이지에서 이 값을 찾을 수 있습니다. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API_KEY} |
Text Analytics 리소스의 키입니다. Azure Portal의 리소스 키 및 엔드포인트 페이지에서 이 값을 찾을 수 있습니다. | xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx |
{CONTAINER_LICENSE_DIRECTORY} |
컨테이너의 로컬 파일 시스템에 있는 라이선스 폴더의 위치입니다. | /path/to/license/directory |
docker run --rm -it -p 5000:5000 \
-v {LICENSE_MOUNT} \
-v {HOST_MODELS_PATH} \
{IMAGE} \
eula=accept \
rai_terms=accept \
billing={ENDPOINT_URI} \
apikey={API_KEY} \
DownloadLicense=True \
Mounts:License={CONTAINER_LICENSE_DIRECTORY}
라이선스 파일이 다운로드되면 연결이 끊긴 환경에서 컨테이너를 실행할 수 있습니다. 다음 예는 자리 표시자 값과 함께 사용할 docker run 명령의 형식을 보여 줍니다. 이러한 자리 표시자 값을 고유한 값으로 바꿉니다.
컨테이너가 실행되는 곳마다 라이선스 파일을 컨테이너에 탑재해야 하며 컨테이너의 로컬 파일 시스템에서 라이선스 폴더의 위치를 Mounts:License=로 지정해야 합니다. 청구 사용량 기록을 작성할 수 있도록 출력 탑재도 지정해야 합니다.
| 자리 표시자 | 값 | 형식 또는 예 |
|---|---|---|
{IMAGE} |
사용하려는 컨테이너 이미지입니다. | mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:cpu |
{MEMORY_SIZE} |
컨테이너에 할당할 적절한 메모리 크기입니다. | 4g |
{NUMBER_CPUS} |
컨테이너에 할당할 적절한 CPU 수입니다. | 4 |
{LICENSE_MOUNT} |
라이선스를 찾고 탑재할 경로입니다. | /host/license:/path/to/license/directory |
{HOST_MODELS_PATH} |
모델을 다운로드하고 탑재한 경로입니다. | /host/models:/models |
{OUTPUT_PATH} |
사용량 기록 로깅을 위한 출력 경로입니다. | /host/output:/path/to/output/directory |
{CONTAINER_LICENSE_DIRECTORY} |
컨테이너의 로컬 파일 시스템에 있는 라이선스 폴더의 위치입니다. | /path/to/license/directory |
{CONTAINER_OUTPUT_DIRECTORY} |
컨테이너의 로컬 파일 시스템에 있는 출력 폴더의 위치입니다. | /path/to/output/directory |
docker run --rm -it -p 5000:5000 --memory {MEMORY_SIZE} --cpus {NUMBER_CPUS} \
-v {LICENSE_MOUNT} \
-v {HOST_MODELS_PATH} \
-v {OUTPUT_PATH} \
{IMAGE} \
eula=accept \
rai_terms=accept \
Mounts:License={CONTAINER_LICENSE_DIRECTORY}
Mounts:Output={CONTAINER_OUTPUT_DIRECTORY}
컨테이너 중지
컨테이너를 종료하려면 컨테이너를 실행하는 명령줄 환경에서 Ctrl+C를 선택합니다.
문제 해결
출력 탑재 및 활성화된 로깅을 사용하여 컨테이너를 실행하는 경우 컨테이너는 컨테이너를 시작 또는 실행하는 동안 발생하는 문제를 해결하는 데 도움이 되는 로그 파일을 생성합니다.
팁
자세한 문제 해결 정보 및 지침은 Azure AI 컨테이너 FAQ(자주 묻는 질문)를 참조하세요.
결제
요약 컨테이너는 Azure 계정의 Language 리소스를 사용하여 청구 정보를 Azure로 보냅니다.
컨테이너에 대한 쿼리는 ApiKey 매개 변수에 사용되는 Azure 리소스의 가격 책정 계층으로 청구됩니다.
Azure AI 서비스 컨테이너는 측정 또는 청구 엔드포인트에 연결하지 않고 실행할 수 있는 라이선스가 부여되지 않습니다. 사용자는 컨테이너가 항상 청구 엔드포인트와 청구 정보를 통신할 수 있도록 설정해야 합니다. Azure AI 서비스 컨테이너는 분석 중인 이미지나 텍스트와 같은 고객 데이터를 Microsoft에 보내지 않습니다.
Azure에 연결
컨테이너에는 실행할 청구 인수 값이 필요합니다. 이러한 값을 통해 컨테이너는 청구 엔드포인트에 연결할 수 있습니다. 컨테이너는 약 10 ~ 15분마다 사용량을 보고합니다. 컨테이너가 허용되는 시간 내에서 Azure에 연결되지 않으면 컨테이너는 계속 실행되지만 청구 엔드포인트가 복원될 때까지 쿼리를 처리하지 않습니다. 10 ~ 15분 간격으로 동시에 10회 동안 연결이 시도됩니다. 10회 시도 안에 청구 엔드포인트에 연결할 수 없는 경우 컨테이너는 요청 처리를 중지합니다. 청구를 위해 Microsoft로 전송되는 정보의 예는 Azure AI 서비스 컨테이너 FAQ를 참조하세요.
청구 인수
다음 세 가지 옵션 모두에 유효한 값이 제공되면 컨테이너를 시작합니다. docker run 명령이 컨테이너를 시작합니다.
| 옵션 | 설명 |
|---|---|
ApiKey |
청구 정보를 추적하는 데 사용되는 Azure AI 서비스 리소스의 API 키입니다. 이 옵션의 값은 Billing에 지정된 프로비전된 리소스의 API 키로 설정해야 합니다. |
Billing |
청구 정보를 추적하는 데 사용되는 Azure AI 서비스 리소스의 엔드포인트입니다. 이 옵션의 값은 프로비저닝된 Azure 리소스의 엔드포인트 URI로 설정해야 합니다. |
Eula |
컨테이너에 대한 라이선스에 동의했음을 나타냅니다. 이 옵션의 값은 동의로 설정해야 합니다. |
이러한 옵션에 대한 자세한 내용은 컨테이너 구성을 참조하세요.
요약
이 문서에서는 요약 컨테이너를 다운로드, 설치 및 실행하기 위한 개념과 워크플로를 알아보았습니다. 요약:
- 요약은 Docker용 Linux 컨테이너를 제공합니다.
- 컨테이너 이미지는 Microsoft 컨테이너 레지스트리(MCR)에서 다운로드됩니다.
- 컨테이너 이미지는 Docker에서 실행됩니다.
- 컨테이너를 인스턴스화할 때 청구 정보를 지정해야 합니다.
Important
이 컨테이너는 측정을 위해 Azure에 연결하지 않고 실행할 수 있는 라이선스가 없습니다. 고객은 컨테이너에서 항상 계량 서비스와 청구 정보를 통신할 수 있도록 설정해야 합니다. Azure AI 컨테이너는 고객 데이터(예: 분석 중인 텍스트)를 Microsoft에 보내지 않습니다.
다음 단계
- 구성 설정은 컨테이너 구성을 참조하세요.