자습서: Power BI에 저장된 텍스트에서 핵심 구 추출
Microsoft Power BI Desktop은 데이터에 연결하고, 데이터를 변환 및 시각화할 수 있는 무료 애플리케이션입니다. Azure AI 언어의 기능 중 하나인 핵심 구문 추출은 자연어 처리 기능을 제공합니다. 원시 비구조 텍스트가 주어지면 이 서비스는 가장 중요한 구를 추출하고, 감정을 분석하고, 브랜드와 같은 잘 알려진 엔터티를 식별할 수 있습니다. 이러한 도구를 함께 사용하면 고객이 말하는 제품이 무엇인지, 그 제품에 대해 어떻게 생각하는지 빨리 파악할 수 있습니다.
이 자습서에서는 다음 작업을 수행하는 방법을 알아봅니다.
- Power BI Desktop을 사용하여 데이터 가져오기 및 변환
- Power BI Desktop에서 사용자 지정 함수 만들기
- Azure AI 언어의 핵심 구 추출 기능과 Power BI Desktop 통합
- 핵심 구 추출을 사용하여 고객 피드백에서 가장 중요한 문구 가져오기
- 고객 피드백에서 단어 구름 만들기
필수 조건
- Microsoft Power BI Desktop. 무료로 다운로드할 수 있습니다.
- Microsoft Azure 계정. 체험 계정 만들기 또는 로그인.
- 언어 리소스입니다. 계정이 없으면 만들 수 있습니다.
- 리소스를 만들 때 생성된 언어 리소스 키
- 고객 의견. 데이터 예 또는 사용자 고유 데이터를 사용할 수 있습니다. 이 자습서에서는 예제 데이터를 사용한다고 가정합니다.
고객 데이터 로드
시작하려면 Power BI Desktop을 열고 필수 구성 요소의 일부로 다운로드한 CSV(쉼표로 구분된 값) 파일을 로드합니다. 이 파일은 작은 가상 회사의 지원 포럼에서 하루 동안 벌어지는 가상의 작업을 보여줍니다.
참고 항목
Power BI는 SQL 데이터베이스 같은 다양한 웹 기반 소스의 데이터를 사용할 수 있습니다. 자세한 내용은 파워 쿼리 설명서를 참조하세요.
기본 Power BI Desktop 창에서 홈 리본을 선택합니다. 리본의 외부 데이터 그룹에서 데이터 가져오기 드롭다운 메뉴를 열고 Text/CSV를 선택합니다.
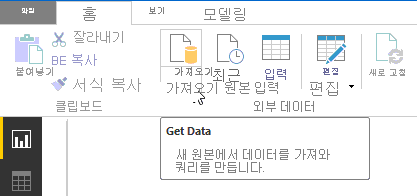
[열기] 대화 상자가 나타납니다. 다운로드 폴더 또는 CSV 파일을 다운로드한 폴더로 이동합니다. 파일 이름을 선택한 다음 열기 버튼을 선택합니다. [CSV 가져오기] 대화 상자가 나타납니다.
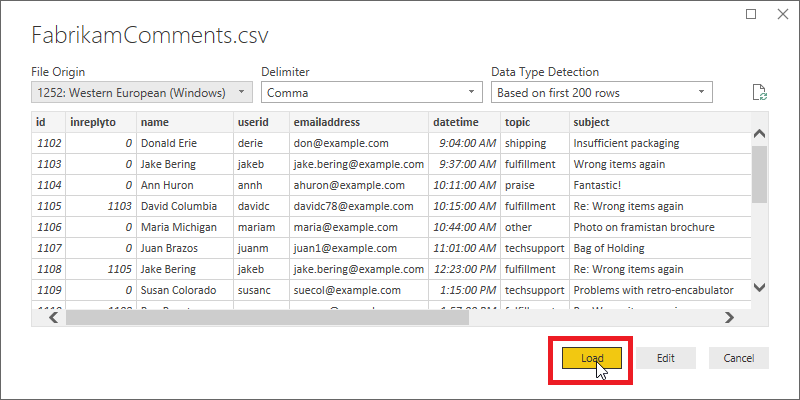
[CSV 가져오기] 대화 상자를 통해 Power BI Desktop이 문자 집합, 구분 기호, 헤더 행 및 열 형식을 올바르게 검색하는지 확인할 수 있습니다. 이 정보는 모두 정확하므로 로드를 선택하세요.
로드된 데이터를 보려면 Power BI 작업 영역의 왼쪽 가장자리에 있는 데이터 보기 단추를 클릭합니다. Microsoft Excel처럼 데이터가 들어 있는 테이블이 열립니다.
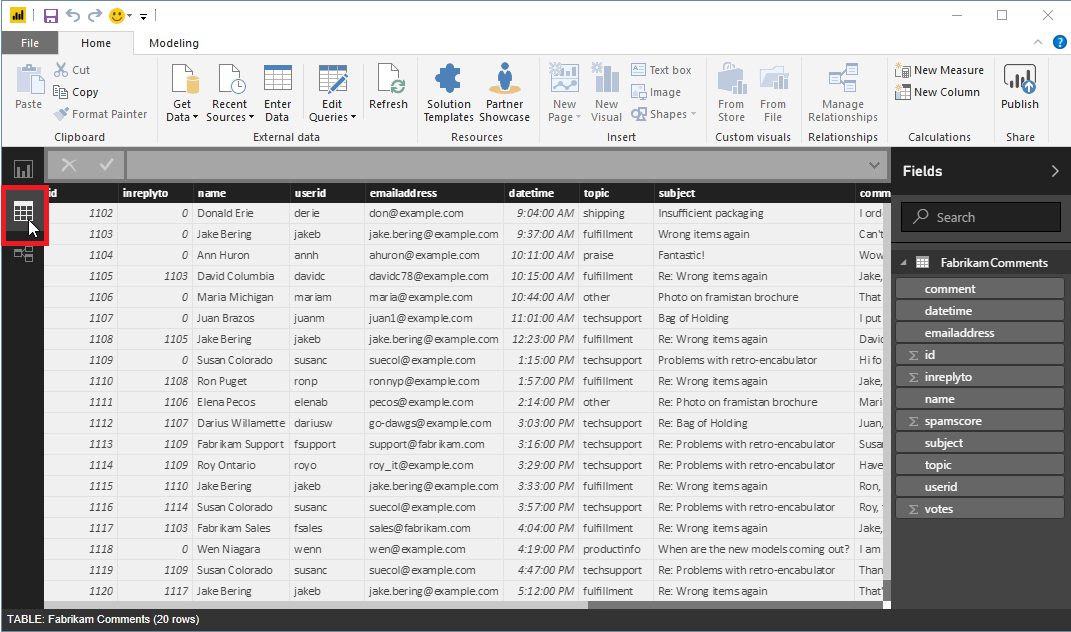
데이터 준비
핵심 구 추출을 통해 처리할 준비가 되기 전에 Power BI Desktop에서 데이터를 변환해야 할 수 있습니다.
샘플 데이터에는 subject 열 및 comment 열이 포함됩니다. Power BI Desktop의 열 병합 함수를 사용하면 comment 열만이 아니라 이러한 두 열의 데이터에서 핵심 구를 추출할 수 있습니다.
Power BI Desktop에서 홈 리본을 선택합니다. 외부 데이터 그룹에서 쿼리 편집을 선택합니다.

아직 선택하지 않은 경우 창의 왼쪽에 있는 쿼리 목록에서 FabrikamComments를 선택합니다.
이제 테이블에서 subject 및 comment 열을 모두 선택합니다. 이러한 열을 보려면 가로로 스크롤해야 할 수 있습니다. 먼저 subject 열 헤더를 클릭한 다음, Control 키를 누른 상태로 comment 열 헤더를 클릭합니다.
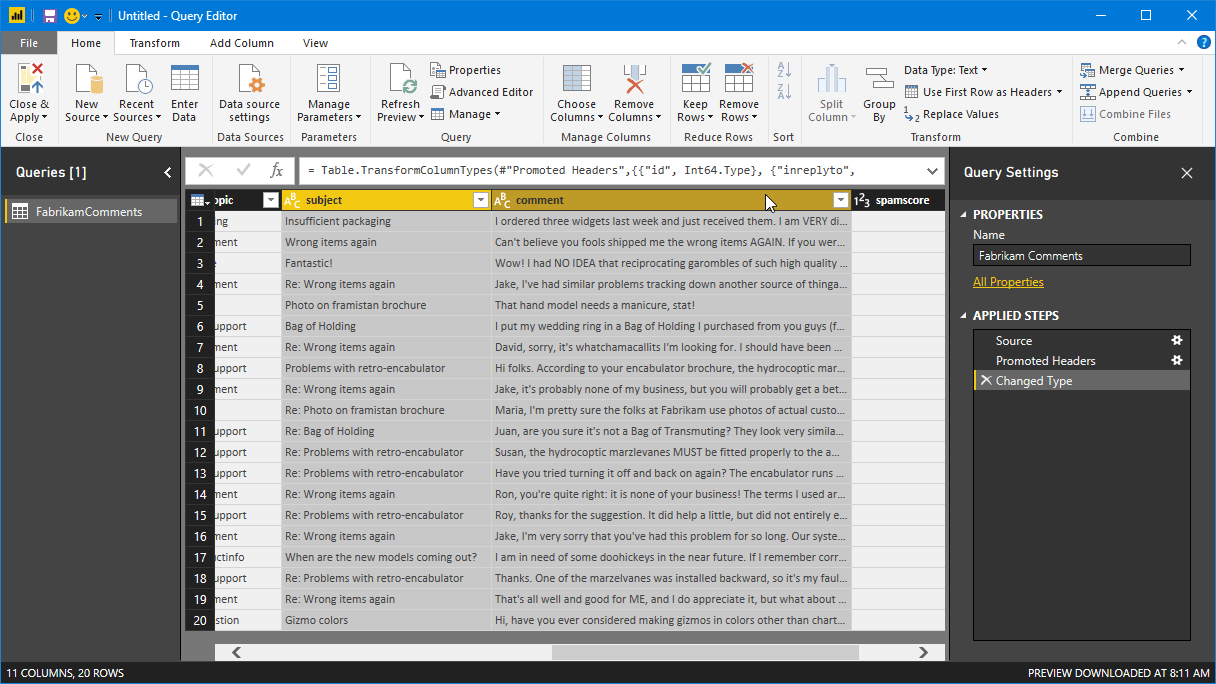
변환 리본을 선택합니다. 리본의 텍스트 열 그룹에서 열 병합을 선택합니다. [열 병합] 대화 상자가 나타납니다.
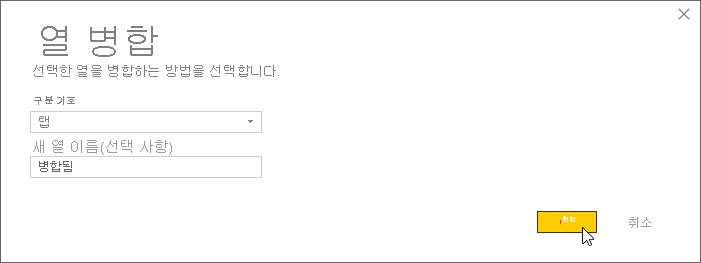
열 병합 대화상자에서 구분 기호로 Tab을 선택한 다음 확인을 선택합니다.
또한 빈 항목 제거 필터를 사용하여 빈 메시지를 필터링하거나 정리 변환을 사용하여 인쇄할 수 없는 문자를 제거하는 방안을 고려해 볼 수 있습니다. 데이터에 샘플 파일의 spamscore 열과 비슷한 열이 포함된 경우 번호 필터를 사용하여 “스팸” 주석을 건너뛸 수 있습니다.
API 이해
핵심 구 추출은 HTTP 요청당 최대 1,000개의 텍스트 문서를 처리할 수 있습니다. Power BI는 레코드를 한 번에 하나씩 처리하는 것을 선호하므로 이 자습서에서 API 호출에는 각각 단일 문서만 포함됩니다. 핵심 구 API는 처리할 각 문서에 대한 다음 필드가 필요합니다.
| 필드 | 설명 |
|---|---|
id |
요청 내에서 이 문서의 고유 식별자. 응답에도 이 필드가 포함됩니다. 이런 방식으로 두 개 이상의 문서를 처리하는 경우 추출된 핵심 문구를 원본 문서와 쉽게 연결할 수 있습니다. 이 자습서에서는 요청당 하나의 문서만 처리하므로 id 값을 각 요청에 동일하게 하드 코드할 수 있습니다. |
text |
처리할 텍스트입니다. 이 필드의 값은 이전 섹션에서 만든 Merged 열에서 가져오며, 결합된 제목 줄과 주석 텍스트를 포함합니다. 핵심 구 API에서는 이 데이터가 약 5,120자 이하여야 합니다. |
language |
문서가 작성되는 자연어에 대한 코드입니다. 샘플 데이터의 모든 메시지는 영어로 작성되므로 이 필드의 en 값을 하드 코드할 수 있습니다. |
사용자 지정 함수 만들기
이제 Power BI와 핵심 구 추출을 통합할 사용자 지정 함수를 만들 준비가 되었습니다. 이 함수는 매개 변수로 처리할 텍스트를 받습니다. 데이터를 필요한 JSON 형식으로 또는 그 반대로 변환하고 핵심 구 API에 대한 HTTP 요청을 만듭니다. 그런 다음, 함수는 API의 응답을 구문 분석하고 추출된 핵심 구의 쉼표로 구분된 목록을 포함하는 문자열을 반환합니다.
참고 항목
Power BI Desktop 사용자 지정 함수는 파워 쿼리 M 수식 언어 또는 줄여서 "M"으로 작성됩니다. M은 F# 기반의 함수 프로그래밍 언어입니다. 하지만 프로그래머가 아니어도 이 자습서를 완료할 수 있도록 아래에 코드가 포함되어 있습니다.
Power BI Desktop에서 아직 쿼리 편집기 창에 있는지 확인합니다. 그렇지 않은 경우 홈 리본을 선택하고 외부 데이터 그룹에서 쿼리 편집을 선택합니다.
이제 홈 리본의 새 쿼리 그룹에서 새 원본 드롭다운 메뉴를 열고 빈 쿼리를 선택합니다.
[쿼리] 목록에 새 쿼리가 나타나며, 처음에는 이름이 Query1로 지정됩니다. 이 항목을 두 번 클릭하고 이름을 KeyPhrases로 변경합니다.
이제 홈 리본의 쿼리 그룹에서 고급 편집기를 선택하여 고급 편집기 창을 엽니다. 창에 있는 기존 코드를 삭제하고 다음 코드를 붙여넣습니다.
참고 항목
아래 예시 엔드포인트(<your-custom-subdomain> 포함)를 언어 리소스에 대해 생성된 엔드포인트로 바꿉니다. Azure Portal에 로그인하고 리소스로 이동한 다음 키 및 엔드포인트를 선택하여 이 엔드포인트를 찾을 수 있습니다.
// Returns key phrases from the text in a comma-separated list
(text) => let
apikey = "YOUR_API_KEY_HERE",
endpoint = "https://<your-custom-subdomain>.cognitiveservices.azure.com/text/analytics" & "/v3.0/keyPhrases",
jsontext = Text.FromBinary(Json.FromValue(Text.Start(Text.Trim(text), 5000))),
jsonbody = "{ documents: [ { language: ""en"", id: ""0"", text: " & jsontext & " } ] }",
bytesbody = Text.ToBinary(jsonbody),
headers = [#"Ocp-Apim-Subscription-Key" = apikey],
bytesresp = Web.Contents(endpoint, [Headers=headers, Content=bytesbody]),
jsonresp = Json.Document(bytesresp),
keyphrases = Text.Lower(Text.Combine(jsonresp[documents]{0}[keyPhrases], ", "))
in keyphrases
YOUR_API_KEY_HERE을 언어 리소스 키로 바꿉니다. Azure Portal에 로그인하고 언어 리소스로 이동한 다음 키 및 엔드포인트 페이지를 선택하여 이 키를 찾을 수도 있습니다. 키 앞뒤에 있는 따옴표를 그대로 두어야 합니다. 그런 다음 완료를 선택합니다.
사용자 지정 함수 사용
이제 사용자 지정 함수를 사용하여 각 고객 의견에서 핵심 구를 추출하고 테이블의 새 열에 저장할 수 있습니다.
Power BI Desktop의 [쿼리 편집기] 창에서 FabrikamComments 쿼리로 다시 전환합니다. 열 추가 리본을 선택합니다. 일반 그룹에서 사용자 지정 함수 호출을 선택합니다.
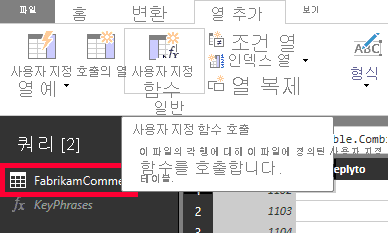
[사용자 지정 함수 호출] 대화 상자가 표시됩니다. 새 열 이름에 keyphrases를 입력합니다. 함수 쿼리에서 직접 만든 사용자 지정 함수(KeyPhrases)를 선택합니다.
대화 상자에 새 필드 텍스트(선택 사항)가 표시됩니다. 이 필드에는 핵심 구 API의 text 매개 변수 값을 제공하는 데 사용할 열을 입력해야 합니다. (language 및 id 매개 변수의 값은 이미 하드 코드했습니다.) 드롭다운 메뉴에서 Merged(이전에 제목 및 메시지 필드를 병합하여 만든 열)를 선택합니다.
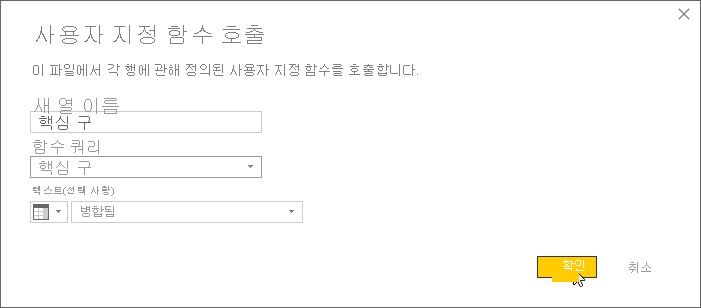
마지막으로 확인을 선택합니다.
모든 것이 준비되면 Power BI에서 테이블의 각 행에 한 번씩 사용자 지정 함수를 호출합니다. 이렇게 하면 쿼리가 핵심 구 API에 전송되고 결과를 저장할 새 열이 테이블에 추가됩니다. 그러나 이러한 일이 발생하기 전에 인증 및 개인 정보 설정을 지정해야 할 수 있습니다.
인증 및 개인 정보
[사용자 지정 함수 호출] 대화 상자를 닫으면 핵심 구 API에 연결할 방법을 지정하라는 배너가 나타날 수 있습니다.

자격 증명 편집을 선택하고 대화 상자에서 Anonymous이 선택되었는지 확인한 다음 연결을 선택합니다.
참고 항목
핵심 구 추출이 액세스 키를 사용하여 요청을 인증하므로 Power BI가 HTTP 요청 자체에 대한 자격 증명을 제공할 필요가 없으므로 Anonymous를 선택합니다.
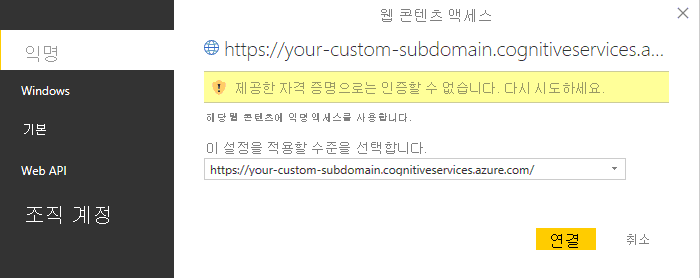
익명 액세스를 선택한 후에도 자격 증명 편집 배너가 표시되는 경우 사용자 지정 함수의 코드에 언어 리소스 키를 붙여넣는 것을 잊어버렸을 KeyPhrases 수 있습니다.
다음으로, 데이터 원본의 개인 정보 취급에 대한 정보를 입력하라는 배너가 나타날 수 있습니다.

계속을 선택하고 대화 상자의 각 데이터 원본에 대해 Public을 선택합니다. 그런 다음 저장을 선택합니다.

Word Cloud 만들기
표시되는 배너를 모두 처리한 후 홈 리본에서 닫기 및 적용을 선택하여 쿼리 편집기를 닫습니다.
Power BI Desktop이 필요한 HTTP 요청을 만들 때까지 잠시 시간이 걸립니다. 테이블의 각 행에서, 새 keyphrases 열에는 Key Phrases API가 텍스트에서 검색한 핵심 문구가 포함됩니다.
이제 이 열을 사용하여 Word Cloud를 생성하겠습니다. 시작하려면 작업 영역 왼쪽에 있는 기본 Power BI Desktop 창에서 보고서 단추를 클릭합니다.
참고 항목
모든 의견의 전체 텍스트 대신 추출된 핵심 문구를 사용하여 Word Cloud를 생성하는 이유는 무엇일까요? 핵심 문구는 가장 일반적인 단어뿐 아니라 고객 의견에서 중요한 단어를 제공합니다. 또한 상대적으로 수가 적은 의견에서 특정 단어를 자주 사용하더라도 결과 클라우드의 단어 크기 조정이 왜곡되지 않습니다.
아직 Word Cloud 사용자 지정 시각적 개체가 없으면 지금 설치합니다. 작업 영역 오른쪽의 [시각화] 패널에서 세 점(...)을 클릭하고 시장에서 가져오기를 선택합니다. 목록에 표시된 시각화 도구에 "클라우드"라는 단어가 없으면 "클라우드"를 검색하고 Word Cloud 시각적 개체 옆에 있는 추가 단추를 클릭합니다. Power BI는 Word Cloud 시각적 개체를 설치하고 성공적으로 설치되었음을 사용자에게 알려줍니다.

먼저, [시각화] 패널에서 Word Cloud 아이콘을 클릭합니다.

작업 영역에 새 보고서가 나타납니다. [시각화] 패널의 [필드] 패널에서 keyphrases 필드를 [범주] 필드로 끌어 놓습니다. 보고서 안에 Word Cloud가 나타납니다.
이제 [시각화] 패널의 [형식] 페이지로 전환합니다. 클라우드에서 "of" 같은 짧고 일반적인 단어를 제거하도록, [중지 단어] 범주에서 기본 중지 단어를 켭니다. 그러나 주요 문구를 시각화하기 때문에 해당 구문에 중지 단어가 포함되어 있지 않을 수 있습니다.
이 패널에서 좀 더 아래로 내려가서 텍스트 회전 및 제목을 끕니다.
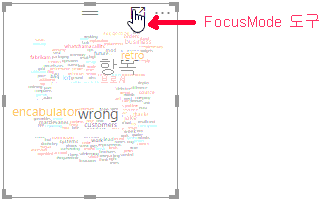
단어 클라우드를 더 자세히 보려면 보고서에서 초점 모드 도구를 선택하세요. 이 도구는 아래와 같이 작업 영역 전체를 채우도록 Word Cloud를 확장합니다.

다른 기능 사용
Azure AI 언어는 감정 분석 및 언어 탐지도 제공합니다. 언어 감지는 고객 피드백의 일부가 영어가 아닌 경우에 특히 유용합니다.
이러한 두 API는 핵심 구 API와 비슷합니다. 즉, 이 자습서에서 만든 것과 거의 같은 사용자 지정 함수를 사용하여 두 API를 Power BI Desktop과 통합할 수 있습니다. 앞에서 했던 것처럼 빈 쿼리를 만들고 아래에서 적절한 코드를 [고급 편집기]에 붙여넣으면 됩니다. (액세스 키를 잊지 마세요!) 그런 다음, 앞에서 했던 것처럼 함수를 사용하여 테이블에 새 열을 추가합니다.
아래의 감정 분석 함수는 텍스트에 표현된 감정이 얼마나 긍정적인지를 나타내는 레이블을 반환합니다.
// Returns the sentiment label of the text, for example, positive, negative or mixed.
(text) => let
apikey = "YOUR_API_KEY_HERE",
endpoint = "<your-custom-subdomain>.cognitiveservices.azure.com" & "/text/analytics/v3.1/sentiment",
jsontext = Text.FromBinary(Json.FromValue(Text.Start(Text.Trim(text), 5000))),
jsonbody = "{ documents: [ { language: ""en"", id: ""0"", text: " & jsontext & " } ] }",
bytesbody = Text.ToBinary(jsonbody),
headers = [#"Ocp-Apim-Subscription-Key" = apikey],
bytesresp = Web.Contents(endpoint, [Headers=headers, Content=bytesbody]),
jsonresp = Json.Document(bytesresp),
sentiment = jsonresp[documents]{0}[sentiment]
in sentiment
두 가지 버전의 언어 검색 함수가 있습니다. 첫 번째는 ISO 언어 코드(예: 영어를 나타내는 en)를 반환하고, 두 번째는 “친숙한” 이름(예: English)을 반환합니다. 두 버전에서 본문의 마지막 줄만 다른 것을 확인할 수 있습니다.
// Returns the two-letter language code (for example, 'en' for English) of the text
(text) => let
apikey = "YOUR_API_KEY_HERE",
endpoint = "https://<your-custom-subdomain>.cognitiveservices.azure.com" & "/text/analytics/v3.1/languages",
jsontext = Text.FromBinary(Json.FromValue(Text.Start(Text.Trim(text), 5000))),
jsonbody = "{ documents: [ { id: ""0"", text: " & jsontext & " } ] }",
bytesbody = Text.ToBinary(jsonbody),
headers = [#"Ocp-Apim-Subscription-Key" = apikey],
bytesresp = Web.Contents(endpoint, [Headers=headers, Content=bytesbody]),
jsonresp = Json.Document(bytesresp),
language = jsonresp [documents]{0}[detectedLanguage] [name] in language
// Returns the name (for example, 'English') of the language in which the text is written
(text) => let
apikey = "YOUR_API_KEY_HERE",
endpoint = "https://<your-custom-subdomain>.cognitiveservices.azure.com" & "/text/analytics/v3.1/languages",
jsontext = Text.FromBinary(Json.FromValue(Text.Start(Text.Trim(text), 5000))),
jsonbody = "{ documents: [ { id: ""0"", text: " & jsontext & " } ] }",
bytesbody = Text.ToBinary(jsonbody),
headers = [#"Ocp-Apim-Subscription-Key" = apikey],
bytesresp = Web.Contents(endpoint, [Headers=headers, Content=bytesbody]),
jsonresp = Json.Document(bytesresp),
language =jsonresp [documents]{0}[detectedLanguage] [name] in language
마지막으로, 다음은 이미 제공된 핵심 문구 함수의 변형으로, 문구를 쉼표로 구분된 문구의 단일 문자열이 아닌 목록 개체로 반환합니다.
참고 항목
단일 문자열을 반환하여 워드 클라우드 예제를 간소화했습니다. 반면, 목록은 Power BI에서 반환된 문구에 사용할 수 있도록 좀 더 유연한 형식입니다. [쿼리 편집기]의 [변환] 리본에서 [구조적 열] 리본 그룹을 사용하여 Power BI Desktop에서 목록 개체를 조작할 수 있습니다.
// Returns key phrases from the text as a list object
(text) => let
apikey = "YOUR_API_KEY_HERE",
endpoint = "https://<your-custom-subdomain>.cognitiveservices.azure.com" & "/text/analytics/v3.1/keyPhrases",
jsontext = Text.FromBinary(Json.FromValue(Text.Start(Text.Trim(text), 5000))),
jsonbody = "{ documents: [ { language: ""en"", id: ""0"", text: " & jsontext & " } ] }",
bytesbody = Text.ToBinary(jsonbody),
headers = [#"Ocp-Apim-Subscription-Key" = apikey],
bytesresp = Web.Contents(endpoint, [Headers=headers, Content=bytesbody]),
jsonresp = Json.Document(bytesresp),
keyphrases = jsonresp[documents]{0}[keyPhrases]
in keyphrases
다음 단계
Azure AI 언어, Power Query M 수식 언어 또는 Power BI에 대해 자세히 알아보세요.