문서 인텔리전스 레이아웃 모델
이 콘텐츠는 ![]() v4.0(GA) | 이전 버전:
v4.0(GA) | 이전 버전: ![]() v3.1(GA)
v3.1(GA) ![]() v3.0(GA)
v3.0(GA)![]() v2.1(GA)
v2.1(GA)
문서 인텔리전스 레이아웃 모델은 문서 인텔리전스 클라우드에서 사용할 수 있는 고급 기계 학습 기반 문서 분석 API입니다. 이를 통해 사용자는 다양한 형식으로 문서를 가져와 문서의 정형 데이터 표현을 반환할 수 있습니다. 이 버전은 강력한 OCR(광학 문자 인식) 기능을 딥 러닝 모델과 결합하여 텍스트, 테이블, 선택 표시 및 문서 구조를 추출합니다.
문서 레이아웃 분석(v4)
문서 구조 레이아웃 분석은 문서를 분석하여 관심 영역과 해당 상호 관계를 추출하는 프로세스입니다. 목표는 페이지에서 텍스트 및 구조 요소를 추출하여 더 나은 의미 체계 이해 모델을 빌드하는 것입니다. 문서 레이아웃에는 두 가지 유형의 역할이 있습니다.
- 기하학적 역할: 텍스트, 테이블, 그림 및 선택 표시는 기하학적 역할의 예입니다.
- 논리적 역할: 제목, 머리글 및 바닥글은 텍스트의 논리적 역할의 예입니다.
다음 그림에서는 샘플 페이지의 이미지에 있는 일반적인 구성 요소를 보여 줍니다.

개발 옵션(v4)
문서 인텔리전스 v4.0: 2024-11-30 (GA)은 다음 도구, 애플리케이션 및 라이브러리를 지원합니다.
| 기능 | 리소스 | Model ID |
|---|---|---|
| 레이아웃 모델 | • 문서 인텔리전스 스튜디오 • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-layout |
입력 요구 사항(v4)
지원 파일 형식:
모델 PDF 이미지: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word(DOCX), Excel(XLSX), PowerPoint(PPTX), HTML읽기 ✔ ✔ ✔ 레이아웃 ✔ ✔ ✔ 일반 문서 ✔ ✔ 사전 제작 ✔ ✔ 사용자 지정 추출 ✔ ✔ 사용자 지정 분류 ✔ ✔ ✔ 최상의 결과를 위해 문서당 하나의 명확한 사진 또는 고품질 스캔을 제공합니다.
PDF 및 TIFF의 경우 최대 2,000페이지를 처리할 수 있습니다(무료 계층 구독의 경우 처음 2페이지만 처리됨).
문서를 분석하기 위한 파일 크기는 유료(S0) 계층의 경우 500MB이고 무료(F0) 계층의 경우
4MB입니다.이미지 크기는 50픽셀 x 50픽셀에서 10,000픽셀 x 10,000픽셀 사이여야 합니다.
PDF가 암호로 잠긴 경우에는 제출하기 전에 잠금을 해제해야 합니다.
추출할 텍스트의 최소 높이는 1024 x 768 픽셀 이미지의 경우 12픽셀입니다. 이 차원은 150DPI(인치당 도트 수)에서 약
8점 텍스트에 해당합니다.사용자 지정 모델 학습의 경우 학습 데이터의 최대 페이지 수는 사용자 지정 템플릿 모델의 경우 500개, 사용자 지정 인공신경망 모델의 경우 50,000개입니다.
사용자 지정 추출 모델 학습의 경우 학습 데이터의 총 크기는 템플릿 모델의 경우 50MB이고 인공신경망 모델의 경우
1GB입니다.사용자 지정 분류 모델 학습의 경우 학습 데이터의 총 크기는
1GB이고 최대 10,000페이지입니다. 2024-11-30(GA)의 경우 학습 데이터의 총 크기는 최대 10,000페이지의 GB입니다2.
레이아웃 모델 시작
문서 인텔리전스를 사용하여 텍스트, 테이블, 표 머리글, 선택 표시 및 구조 정보를 포함한 데이터를 문서에서 추출하는 방법을 알아보세요. 다음 리소스가 필요합니다.
Azure 구독은 무료로 만들 수 있습니다.
Azure Portal의 Document Intelligence 인스턴스입니다. 무료 가격 책정 계층(
F0)을 사용하여 서비스를 시도할 수 있습니다. 리소스가 배포된 후 리소스로 이동을 선택하여 키 및 엔드포인트를 가져옵니다.
참고 항목
문서 인텔리전스 스튜디오는 v3.0 API 이상 버전에서 사용할 수 있습니다.
문서 인텔리전스 스튜디오에서 처리된 샘플 문서
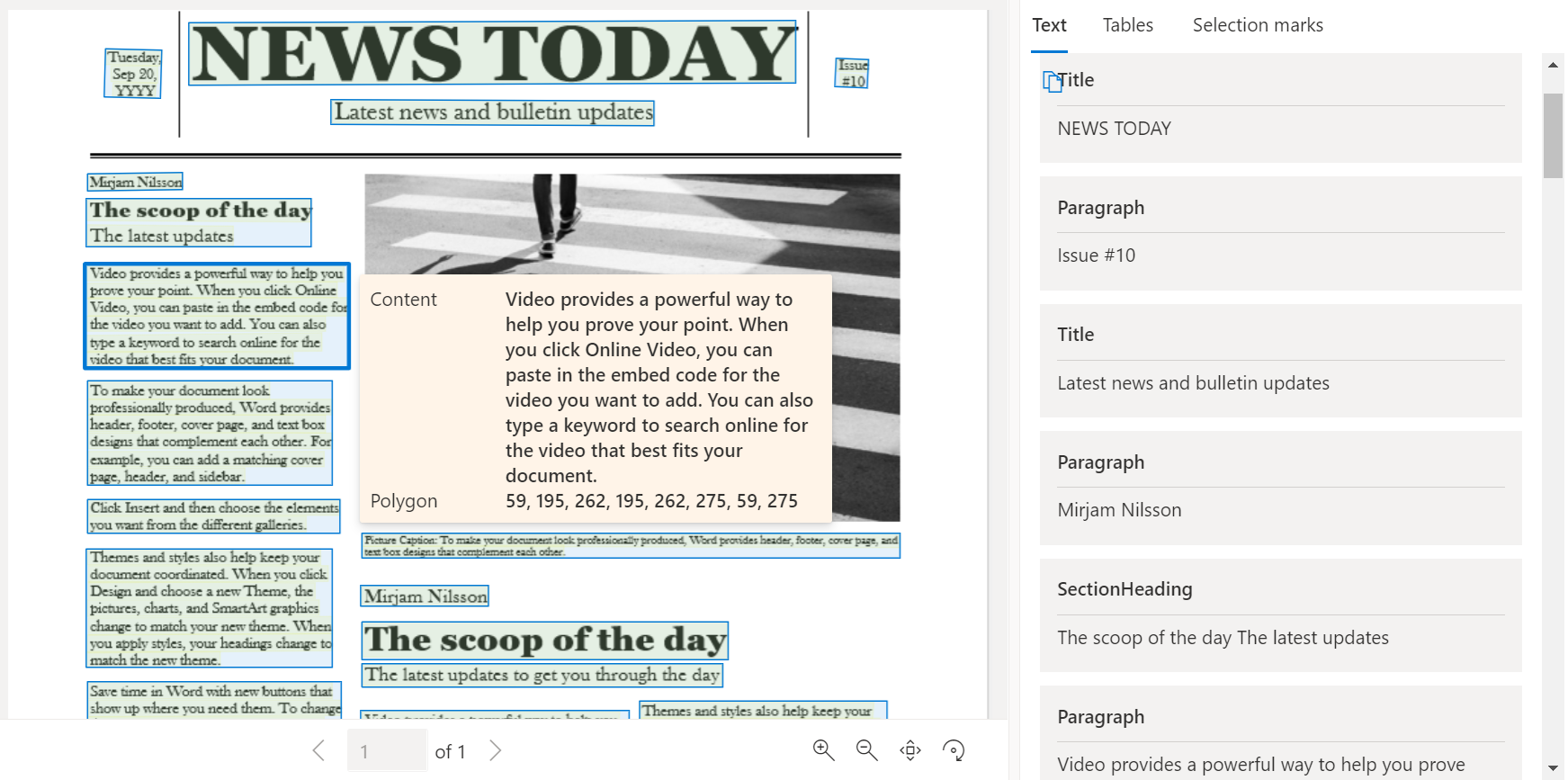
문서 인텔리전스 스튜디오 홈페이지에서 레이아웃을 선택합니다.
샘플 문서를 분석하거나 자체 파일을 업로드할 수 있습니다.
분석 실행 버튼을 선택하고 필요한 경우 분석 옵션을 구성합니다.

지원되는 언어
지원되는 언어의 전체 목록은 언어 지원 - 문서 분석 모델 페이지를 참조하세요.
데이터 추출(v4)
레이아웃 모델은 문서에서 텍스트, 선택 표시, 표, 단락 및 단락 형식(roles)을 추출합니다.
참고 항목
Document Intelligence v4.0(2024-11-30(GA)) 이상에서는 Microsoft Office(DOCX, XLSX, PPTX) 및 HTML 파일을 지원합니다. 다음 기능은 지원되지 않습니다.
- 각 페이지 개체에는 각도, 너비/높이 및 단위가 없습니다.
- 검색된 각 개체에 대해 경계 다각형 또는 경계 영역이 없습니다.
- 페이지 범위(
pages)는 매개 변수로 지원되지 않습니다. lines개체가 없습니다.
페이지
페이지 컬렉션은 문서 내의 페이지 목록입니다. 각 페이지는 문서 및 .내에서 순차적으로 표시됩니다. /에는 페이지가 회전되는지와 너비와 높이(픽셀 단위)를 나타내는 방향 각도가 포함됩니다. 모델 출력의 페이지 단위는 다음과 같이 계산됩니다.
| 파일 형식 | 컴퓨팅된 페이지 단위 | 전체 페이지 수 |
|---|---|---|
| 이미지(JPEG/JPG, PNG, BMP, HEIF) | 각 이미지 = 1페이지 단위 | 총 이미지 |
| PDF의 각 페이지 = 1페이지 단위 | PDF의 총 페이지 수 | |
| TIFF | TIFF의 각 이미지 = 1페이지 단위 | TIFF의 총 이미지 |
| Word(DOCX) | 최대 3,000자 = 1페이지 단위, 포함되거나 연결된 이미지가 지원되지 않음 | 각각 최대 3,000자의 총 페이지 |
| Excel(XLSX) | 개별 워크시트 = 1페이지 단위, 포함되거나 연결된 이미지가 지원되지 않음 | 전체 워크시트 |
| PowerPoint(PPTX) | 개별 슬라이드 = 1페이지 단위, 포함되거나 연결된 이미지가 지원되지 않음 | 전체 슬라이드 |
| HTML | 최대 3,000자 = 1페이지 단위, 포함되거나 연결된 이미지가 지원되지 않음 | 각각 최대 3,000자의 총 페이지 |
# Analyze pages.
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
문서에서 선택한 페이지를 추출합니다.
대규모의 다중 페이지 문서의 경우 pages 쿼리 매개 변수를 사용하여 텍스트 추출을 위한 특정 페이지 번호 또는 페이지 범위를 지정합니다.
단락
레이아웃 모델은 paragraphs 컬렉션에서 식별된 모든 텍스트 블록을 analyzeResults 아래의 최상위 개체로 추출합니다. 이 컬렉션의 각 항목은 텍스트 블록과 .를 나타냅니다. /에는 추출된 텍스트content와 경계 polygon 좌표가 포함됩니다. span 정보는 문서의 전체 텍스트가 포함된 최상위 content 속성 내의 텍스트 조각을 가리킵니다.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
단락 역할
새로운 기계 학습 기반 페이지 개체 검색은 제목, 섹션 머리글, 페이지 머리글, 페이지 바닥글 등과 같은 논리적 역할을 추출합니다. 문서 인텔리전스 레이아웃 모델은 모델이 예측하는 특수 역할 또는 형식을 사용하여 paragraphs 컬렉션의 특정 텍스트 블록을 할당합니다. 보다 풍부한 의미 체계 분석을 위해 추출된 콘텐츠의 레이아웃을 이해하는 데 도움이 되도록 구조화되지 않은 문서에 단락 역할을 사용하는 것이 가장 좋습니다. 지원되는 단락 역할은 다음과 같습니다.
| 예측된 역할 | 설명 | 지원되는 파일 형식 |
|---|---|---|
title |
페이지의 기본 제목 | pdf, 이미지, docx, pptx, xlsx, html |
sectionHeading |
페이지의 하나 이상의 부제목 | pdf, 이미지, docx, xlsx, html |
footnote |
페이지 아래쪽에 있는 텍스트 | pdf, 이미지 |
pageHeader |
페이지 위쪽 에지에 있는 텍스트 | pdf, 이미지, docx |
pageFooter |
페이지 아래쪽 에지에 있는 텍스트 | pdf, 이미지, docx, pptx, html |
pageNumber |
페이지 번호 | pdf, 이미지 |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
텍스트 줄 및 단어
문서 인텔리전스의 문서 레이아웃 모델은 인쇄 및 필기 스타일 텍스트를 lines과(와) words(으)로 추출합니다. 컬렉션입니다 styles . /에는 연결된 텍스트를 가리키는 범위와 함께 검색되는 경우 줄에 대한 필기 스타일이 포함됩니다. 이 기능은 지원되는 필기 언어에 적용됩니다.
Microsoft Word, Excel, PowerPoint 및 HTML의 경우 Document Intelligence v4.0 2024-11-30(GA) 레이아웃 모델은 포함된 모든 텍스트를 있는 그대로 추출합니다. 텍스트는 단어와 단락으로 추출됩니다. 포함된 이미지는 지원되지 않습니다.
# Analyze lines.
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{line.polygon}'"
)
# Analyze words.
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
텍스트 줄에 대한 필기 스타일
응답 .. /includes 각 텍스트 줄이 필기 스타일인지 여부와 신뢰도 점수의 분류를 포함합니다. 자세한 정보. 필기 언어 지원을 참조하세요. 다음 예제에서는 JSON 코드 조각 예제를 보여줍니다.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
글꼴/스타일 추가 기능을 사용하도록 설정하면 글꼴/스타일 결과도 styles 개체의 일부로 가져옵니다.
선택 표시
또한 레이아웃 모델은 문서에서 선택 표시를 추출합니다. 추출된 선택 표시는 각 페이지의 pages 컬렉션 내에 표시됩니다. 여기에는 경계 polygon, confidence 및 선택 영역 state(selected/unselected)가 포함됩니다. 텍스트 표현(즉, :selected: 및 :unselected)은 문서의 전체 텍스트가 포함된 최상위 content 속성을 참조하는 시작 인덱스(offset) 및 length로도 포함됩니다.
# Analyze selection marks.
if page.selection_marks:
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{selection_mark.polygon}' and has a confidence of {selection_mark.confidence}"
)
테이블
테이블 추출은 일반적으로 테이블 형식이 지정된 대량의 데이터를 포함하는 문서를 처리하기 위한 주요 요구 사항입니다. 레이아웃 모델은 JSON 출력의 pageResults 섹션에서 테이블을 추출합니다. 추출된 테이블 정보입니다. /에는 열 및 행 수, 행 범위 및 열 범위가 포함됩니다. 경계 다각형이 있는 각 셀은 영역이 columnHeader로 인식되는지 여부에 관계없이 정보와 함께 출력됩니다. 모델은 순환되는 테이블 추출을 지원합니다. 각 테이블 셀에는 행 및 열 인덱스와 경계 다각형 좌표가 포함됩니다. 셀 텍스트의 경우 모델은 시작 인덱스(offset)가 포함된 span 정보를 출력합니다. 또한 모델은 문서의 전체 텍스트를 포함하는 최상위 수준 콘텐츠 내에서 length를 출력합니다.
문서 인텔리전스 베일 추출 기능을 사용할 때 고려해야 할 몇 가지 요소는 다음과 같습니다.
추출하려는 데이터가 테이블로 존재하고 테이블 구조가 의미 있나요?
데이터가 테이블 형식이 아닌 경우 데이터가 2차원 그리드에 잘 맞나요?
테이블이 여러 페이지에 걸쳐 있나요? 그렇다면 모든 페이지에 레이블을 지정할 필요가 없도록 PDF를 문서 인텔리전스로 보내기 전에 여러 페이지로 분할합니다. 분석 후 페이지를 단일 테이블로 후처리합니다.
사용자 지정 모델을 만드는 경우 테이블 형식 필드를 참조하세요. 각 열에 대한 동적 테이블의 행 수는 가변적입니다. 각 열에 대한 고정 테이블의 행 수는 일관적입니다.
참고 항목
- 입력 파일이 XLSX인 경우 테이블 분석은 지원되지 않습니다.
- 2024-11-30(GA)의 경우 그림과 테이블의 경계 영역은 핵심 콘텐츠만 포함하며 관련 캡션 및 각주를 제외합니다.
if result.tables:
for table_idx, table in enumerate(result.tables):
print(f"Table # {table_idx} has {table.row_count} rows and " f"{table.column_count} columns")
if table.bounding_regions:
for region in table.bounding_regions:
print(f"Table # {table_idx} location on page: {region.page_number} is {region.polygon}")
# Analyze cells.
for cell in table.cells:
print(f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'")
if cell.bounding_regions:
for region in cell.bounding_regions:
print(f"...content on page {region.page_number} is within bounding polygon '{region.polygon}'")
markdown 형식으로 출력
레이아웃 API는 추출된 텍스트를 markdown 형식으로 출력할 수 있습니다. outputContentFormat=markdown을 사용하여 markdown에서 출력 형식을 지정합니다. markdown 콘텐츠는 content 섹션의 일부로 출력됩니다.
참고 항목
v4.0 2024-11-30(GA)의 경우 테이블의 표현이 HTML 테이블로 변경되어 병합된 셀, 다중 행 머리글 등을 렌더링할 수 있습니다. 또 다른 관련 변경 내용은 유니코드 확인란 문자☒와 ☐ 선택 표시에 :selected: 및 :unselected:를 사용하는 것입니다. 이는 최상위 수준의 범위에서 선택 표시 필드의 범위가 유니코드 문자를 참조하더라도 선택 표시 필드의 내용은 :selected:를 포함한다는 것을 의미합니다.
document_intelligence_client = DocumentIntelligenceClient(endpoint=endpoint, credential=AzureKeyCredential(key))
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=url),
output_content_format=ContentFormat.MARKDOWN,
)
그림
문서의 그림(차트, 이미지)은 텍스트 콘텐츠를 보완하고 향상시키는 데 중요한 역할을 하며 복잡한 정보를 이해하는 데 도움이 되는 시각적 표현을 제공합니다. 레이아웃 모델에서 검색된 그림 개체에는 boundingRegions(페이지 번호와 그림 경계를 윤곽선으로 표시하는 다각형 좌표를 포함하여 문서 페이지에 있는 그림의 공간 위치), spans(그림과 관련된 텍스트 범위를 자세히 설명하고 문서 텍스트 내의 오프셋과 길이 지정. 이 연결은 그림을 관련 텍스트 컨텍스트와 연결하는 데 도움이 됨), elements(그림과 관련되거나 그림을 설명하는 문서 내의 텍스트 요소 또는 단락의 식별자) 및 caption(있는 경우)과 같은 주요 속성이 있습니다.
초기 분석 작업 중에 output=figures가 지정되면 서비스는 /analyeResults/{resultId}/figures/{figureId}을(를) 통해 액세스할 수 있는 검색된 모든 그림에 대해 잘린 이미지를 생성합니다.
figureIndex이(가) 페이지당 하나로 다시 설정되는 문서화되지 않은 {pageNumber}.{figureIndex} 규칙에 따라 각 그림 개체에 FigureId이(가) 포함됩니다.
참고 항목
v4.0 2024-11-30(GA)의 경우 그림과 테이블의 경계 영역은 핵심 콘텐츠만 포함하며 관련 캡션 및 각주를 제외합니다.
# Analyze figures.
if result.figures:
for figures_idx,figures in enumerate(result.figures):
print(f"Figure # {figures_idx} has the following spans:{figures.spans}")
for region in figures.bounding_regions:
print(f"Figure # {figures_idx} location on page:{region.page_number} is within bounding polygon '{region.polygon}'")

섹션
계층적 문서 구조 분석은 광범위한 문서를 구성, 이해 및 처리하는 데 중요한 역할을 합니다. 이 접근 방식은 이해력을 높이고, 탐색을 용이하게 하며, 정보 검색을 개선하기 위해 긴 문서를 의미상 분할하는 데 매우 중요합니다. 문서 생성형 AI에서 RAG(검색 증강 세대)의 등장은 계층적 문서 구조 분석의 중요성을 강조합니다. 레이아웃 모델은 각 섹션 내의 섹션과 개체의 관계를 식별하는 출력의 섹션 및 하위 섹션을 지원합니다. 계층 구조는 각 섹션의 elements에서 유지 관리됩니다. 출력 markdown 형식을 사용하여 markdown에서 섹션 및 하위 섹션을 쉽게 가져올 수 있습니다.
document_intelligence_client = DocumentIntelligenceClient(endpoint=endpoint, credential=AzureKeyCredential(key))
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=url),
output_content_format=ContentFormat.MARKDOWN,
)

이 콘텐츠는 ![]() v3.1(GA) | 최신 버전:
v3.1(GA) | 최신 버전:![]() v4.0(GA) | 이전 버전:
v4.0(GA) | 이전 버전: ![]() v3.0
v3.0![]() v2.1에 적용됩니다.
v2.1에 적용됩니다.
이 콘텐츠는 ![]() v3.0(GA) | 최신 버전:
v3.0(GA) | 최신 버전: ![]() v4.0(GA)
v4.0(GA) ![]() v3.1 | 이전 버전:
v3.1 | 이전 버전: ![]() v2.1에 적용됩니다.
v2.1에 적용됩니다.
이 콘텐츠는 ![]() v2.1 | 최신 버전:
v2.1 | 최신 버전: ![]() v4.0(GA)에 적용됩니다.
v4.0(GA)에 적용됩니다.
문서 인텔리전스 레이아웃 모델은 문서 인텔리전스 클라우드에서 사용할 수 있는 고급 기계 학습 기반 문서 분석 API입니다. 이를 통해 사용자는 다양한 형식으로 문서를 가져와 문서의 정형 데이터 표현을 반환할 수 있습니다. 이 버전은 강력한 OCR(광학 문자 인식) 기능을 딥 러닝 모델과 결합하여 텍스트, 테이블, 선택 표시 및 문서 구조를 추출합니다.
문서 레이아웃 분석
문서 구조 레이아웃 분석은 문서를 분석하여 관심 영역과 해당 상호 관계를 추출하는 프로세스입니다. 목표는 페이지에서 텍스트 및 구조 요소를 추출하여 더 나은 의미 체계 이해 모델을 빌드하는 것입니다. 문서 레이아웃에는 두 가지 유형의 역할이 있습니다.
- 기하학적 역할: 텍스트, 테이블, 그림 및 선택 표시는 기하학적 역할의 예입니다.
- 논리적 역할: 제목, 머리글 및 바닥글은 텍스트의 논리적 역할의 예입니다.
다음 그림에서는 샘플 페이지의 이미지에 있는 일반적인 구성 요소를 보여 줍니다.
개발 옵션
문서 인텔리전스 v3.1은 다음 도구, 애플리케이션, 라이브러리를 지원합니다.
| 기능 | 리소스 | Model ID |
|---|---|---|
| 레이아웃 모델 | • 문서 인텔리전스 스튜디오 • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-layout |
문서 인텔리전스 v3.0은 다음 도구, 애플리케이션, 라이브러리를 지원합니다.
| 기능 | 리소스 | Model ID |
|---|---|---|
| 레이아웃 모델 | • 문서 인텔리전스 스튜디오 • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-layout |
문서 인텔리전스 v2.1은 다음 도구, 애플리케이션, 라이브러리를 지원합니다.
| 기능 | 리소스 |
|---|---|
| 레이아웃 모델 | • 문서 인텔리전스 레이블 지정 도구 • REST API • 클라이언트-라이브러리 SDK • 문서 인텔리전스 Docker 컨테이너 |
입력 요구 사항
지원 파일 형식:
모델 PDF 이미지: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word(DOCX), Excel(XLSX), PowerPoint(PPTX), HTML읽기 ✔ ✔ ✔ 레이아웃 ✔ ✔ ✔ 일반 문서 ✔ ✔ 사전 제작 ✔ ✔ 사용자 지정 추출 ✔ ✔ 사용자 지정 분류 ✔ ✔ ✔ 최상의 결과를 위해 문서당 하나의 명확한 사진 또는 고품질 스캔을 제공합니다.
PDF 및 TIFF의 경우 최대 2,000페이지를 처리할 수 있습니다(무료 계층 구독의 경우 처음 2페이지만 처리됨).
문서를 분석하기 위한 파일 크기는 유료(S0) 계층의 경우 500MB이고 무료(F0) 계층의 경우
4MB입니다.이미지 크기는 50픽셀 x 50픽셀에서 10,000픽셀 x 10,000픽셀 사이여야 합니다.
PDF가 암호로 잠긴 경우에는 제출하기 전에 잠금을 해제해야 합니다.
추출할 텍스트의 최소 높이는 1024 x 768 픽셀 이미지의 경우 12픽셀입니다. 이 차원은 150DPI(인치당 도트 수)에서 약
8점 텍스트에 해당합니다.사용자 지정 모델 학습의 경우 학습 데이터의 최대 페이지 수는 사용자 지정 템플릿 모델의 경우 500개, 사용자 지정 인공신경망 모델의 경우 50,000개입니다.
사용자 지정 추출 모델 학습의 경우 학습 데이터의 총 크기는 템플릿 모델의 경우 50MB이고 인공신경망 모델의 경우
1GB입니다.사용자 지정 분류 모델 학습의 경우 학습 데이터의 총 크기는
1GB이고 최대 10,000페이지입니다. 2024-11-30(GA)의 경우 학습 데이터의 총 크기는 최대 10,000페이지의 GB입니다2.
- 지원되는 파일 형식: JPEG, PNG, PDF 및 TIFF.
- 지원되는 페이지 수: PDF 및 TIFF의 경우 최대 2,000페이지가 처리됩니다. 체험 계층 구독자의 경우 처음 두 페이지만 처리됩니다.
- 지원되는 파일 크기: 파일 크기는 50MB 미만이어야 하며 크기는 50 x 50픽셀 이상, 최대 10,000 x 10,000픽셀이어야 합니다.
레이아웃 모델 시작
문서 인텔리전스를 사용하여 텍스트, 테이블, 표 머리글, 선택 표시 및 구조 정보를 포함한 데이터를 문서에서 추출하는 방법을 알아보세요. 다음 리소스가 필요합니다.
Azure 구독은 무료로 만들 수 있습니다.
Azure Portal의 Document Intelligence 인스턴스입니다. 무료 가격 책정 계층(
F0)을 사용하여 서비스를 시도할 수 있습니다. 리소스가 배포된 후 리소스로 이동을 선택하여 키 및 엔드포인트를 가져옵니다.
참고 항목
문서 인텔리전스 스튜디오는 v3.0 API 이상 버전에서 사용할 수 있습니다.
문서 인텔리전스 스튜디오에서 처리된 샘플 문서
문서 인텔리전스 스튜디오 홈페이지에서 레이아웃을 선택합니다.
샘플 문서를 분석하거나 자체 파일을 업로드할 수 있습니다.
분석 실행 버튼을 선택하고 필요한 경우 분석 옵션을 구성합니다.
문서 인텔리전스 샘플 레이블 지정 도구
문서 인텔리전스 샘플 도구로 이동합니다.
샘플 도구 홈페이지에서 레이아웃을 사용하여 텍스트, 테이블 및 선택 표시 가져오기를 선택합니다.
문서 인텔리전스 서비스 엔드포인트 필드에 문서 인텔리전스 구독으로 가져온 엔드포인트를 붙여넣습니다.
키 필드에 문서 인텔리전스 리소스에서 가져오는 키를 붙여넣습니다.
원본 필드의 드롭다운 메뉴에서 URL을 선택합니다. 다음 샘플 문서를 사용할 수 있습니다.
페치 단추를 선택합니다.
레이아웃 실행을 선택합니다. 문서 인텔리전스 샘플 레이블 지정 도구는
Analyze LayoutAPI를 호출하여 문서를 분석합니다.
결과 보기 - 강조 표시된 추출된 텍스트, 검색된 선택 표시 및 검색된 테이블을 참조하세요.
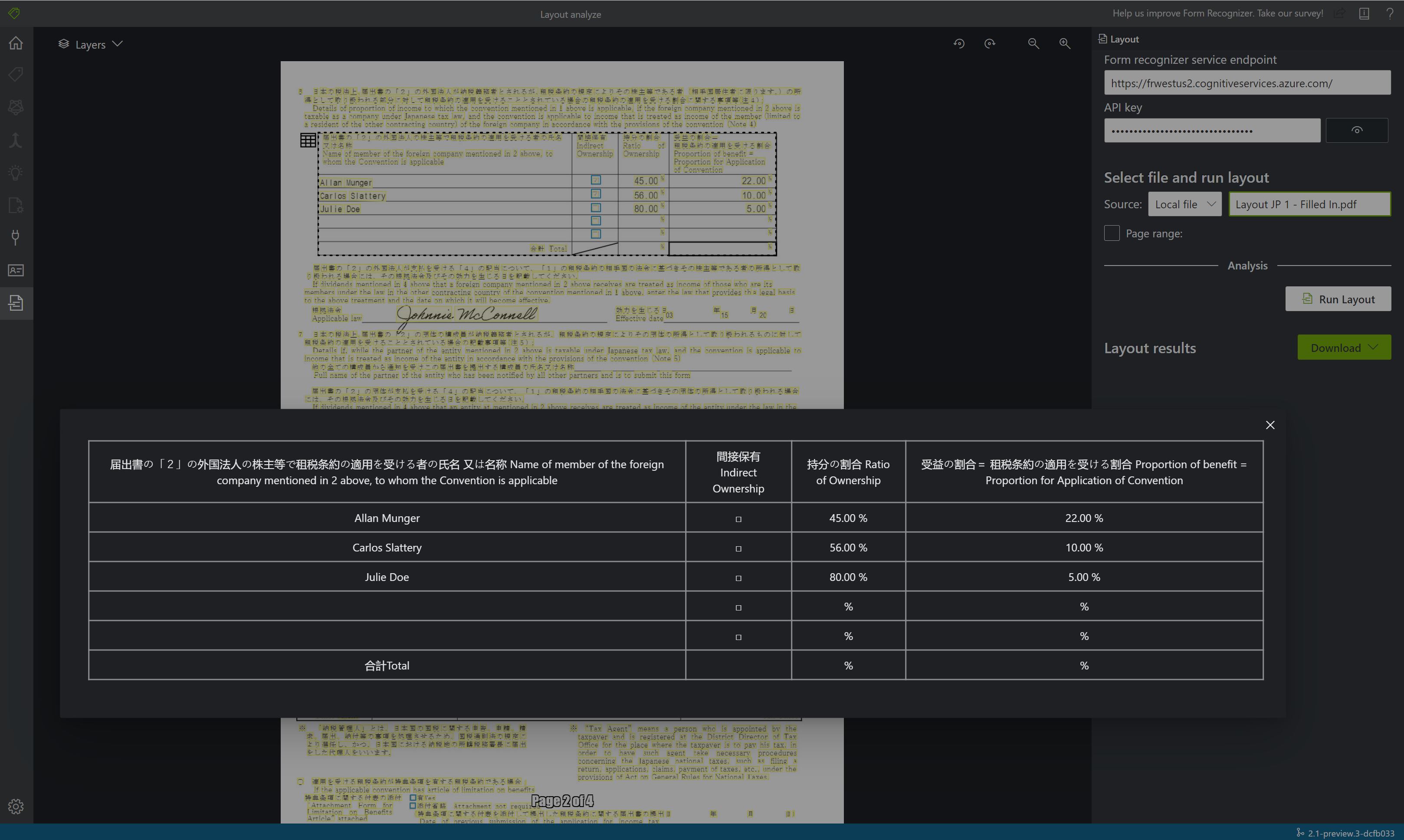
{kind=link}
지원되는 언어 및 로캘
지원되는 언어의 전체 목록은 언어 지원 - 문서 분석 모델 페이지를 참조하세요.
문서 인텔리전스 v2.1은 다음 도구, 애플리케이션, 라이브러리를 지원합니다.
| 기능 | 리소스 |
|---|---|
| 레이아웃 API | • 문서 인텔리전스 레이블 지정 도구 • REST API • 클라이언트-라이브러리 SDK • 문서 인텔리전스 Docker 컨테이너 |
데이터 추출
레이아웃 모델은 문서에서 텍스트, 선택 표시, 표, 단락 및 단락 형식(roles)을 추출합니다.
참고 항목
Document Intelligence v4.0 2024-11-30(GA) 은 Microsoft Office(DOCX, XLSX, PPTX) 및 HTML 파일을 지원합니다. 다음 기능은 지원되지 않습니다.
- 각 페이지 개체에는 각도, 너비/높이 및 단위가 없습니다.
- 검색된 각 개체에 대해 경계 다각형 또는 경계 영역이 없습니다.
- 페이지 범위(
pages)는 매개 변수로 지원되지 않습니다. lines개체가 없습니다.
페이지
페이지 컬렉션은 문서 내의 페이지 목록입니다. 각 페이지는 문서 및 .내에서 순차적으로 표시됩니다. /에는 페이지가 회전되는지와 너비와 높이(픽셀 단위)를 나타내는 방향 각도가 포함됩니다. 모델 출력의 페이지 단위는 다음과 같이 계산됩니다.
| 파일 형식 | 컴퓨팅된 페이지 단위 | 전체 페이지 수 |
|---|---|---|
| 이미지(JPEG/JPG, PNG, BMP, HEIF) | 각 이미지 = 1페이지 단위 | 총 이미지 |
| PDF의 각 페이지 = 1페이지 단위 | PDF의 총 페이지 수 | |
| TIFF | TIFF의 각 이미지 = 1페이지 단위 | TIFF의 총 이미지 |
| Word(DOCX) | 최대 3,000자 = 1페이지 단위, 포함되거나 연결된 이미지가 지원되지 않음 | 각각 최대 3,000자의 총 페이지 |
| Excel(XLSX) | 개별 워크시트 = 1페이지 단위, 포함되거나 연결된 이미지가 지원되지 않음 | 전체 워크시트 |
| PowerPoint(PPTX) | 개별 슬라이드 = 1페이지 단위, 포함되거나 연결된 이미지가 지원되지 않음 | 전체 슬라이드 |
| HTML | 최대 3,000자 = 1페이지 단위, 포함되거나 연결된 이미지가 지원되지 않음 | 각각 최대 3,000자의 총 페이지 |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
문서에서 선택한 페이지를 추출합니다.
대규모의 다중 페이지 문서의 경우 pages 쿼리 매개 변수를 사용하여 텍스트 추출을 위한 특정 페이지 번호 또는 페이지 범위를 지정합니다.
단락
레이아웃 모델은 paragraphs 컬렉션에서 식별된 모든 텍스트 블록을 analyzeResults 아래의 최상위 개체로 추출합니다. 이 컬렉션의 각 항목은 텍스트 블록과 .를 나타냅니다. /에는 추출된 텍스트content와 경계 polygon 좌표가 포함됩니다. span 정보는 문서의 전체 텍스트가 포함된 최상위 content 속성 내의 텍스트 조각을 가리킵니다.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
단락 역할
새로운 기계 학습 기반 페이지 개체 검색은 제목, 섹션 머리글, 페이지 머리글, 페이지 바닥글 등과 같은 논리적 역할을 추출합니다. 문서 인텔리전스 레이아웃 모델은 모델이 예측하는 특수 역할 또는 형식을 사용하여 paragraphs 컬렉션의 특정 텍스트 블록을 할당합니다. 보다 풍부한 의미 체계 분석을 위해 추출된 콘텐츠의 레이아웃을 이해하는 데 도움이 되도록 구조화되지 않은 문서에 단락 역할을 사용하는 것이 가장 좋습니다. 지원되는 단락 역할은 다음과 같습니다.
| 예측된 역할 | 설명 | 지원되는 파일 형식 |
|---|---|---|
title |
페이지의 기본 제목 | pdf, 이미지, docx, pptx, xlsx, html |
sectionHeading |
페이지의 하나 이상의 부제목 | pdf, 이미지, docx, xlsx, html |
footnote |
페이지 아래쪽에 있는 텍스트 | pdf, 이미지 |
pageHeader |
페이지 위쪽 에지에 있는 텍스트 | pdf, 이미지, docx |
pageFooter |
페이지 아래쪽 에지에 있는 텍스트 | pdf, 이미지, docx, pptx, html |
pageNumber |
페이지 번호 | pdf, 이미지 |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
텍스트 줄 및 단어
문서 인텔리전스의 문서 레이아웃 모델은 인쇄 및 필기 스타일 텍스트를 lines과(와) words(으)로 추출합니다. 컬렉션입니다 styles . /에는 연결된 텍스트를 가리키는 범위와 함께 검색되는 경우 줄에 대한 필기 스타일이 포함됩니다. 이 기능은 지원되는 필기 언어에 적용됩니다.
Microsoft Word, Excel, PowerPoint 및 HTML의 경우 Document Intelligence v4.0 2024-11-30(GA) 레이아웃 모델은 포함된 모든 텍스트를 있는 그대로 추출합니다. 텍스트는 단어와 단락으로 추출됩니다. 포함된 이미지는 지원되지 않습니다.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
텍스트 줄에 대한 필기 스타일
응답 .. /includes 각 텍스트 줄이 필기 스타일인지 여부와 신뢰도 점수의 분류를 포함합니다. 자세한 정보. 필기 언어 지원을 참조하세요. 다음 예제에서는 JSON 코드 조각 예제를 보여줍니다.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
글꼴/스타일 추가 기능을 사용하도록 설정하면 글꼴/스타일 결과도 styles 개체의 일부로 가져옵니다.
선택 표시
또한 레이아웃 모델은 문서에서 선택 표시를 추출합니다. 추출된 선택 표시는 각 페이지의 pages 컬렉션 내에 표시됩니다. 여기에는 경계 polygon, confidence 및 선택 영역 state(selected/unselected)가 포함됩니다. 텍스트 표현(즉, :selected: 및 :unselected)은 문서의 전체 텍스트가 포함된 최상위 content 속성을 참조하는 시작 인덱스(offset) 및 length로도 포함됩니다.
{
"selectionMarks": [
{
"state": "unselected",
"polygon": [],
"confidence": 0.995,
"span": {
"offset": 1421,
"length": 12
}
}
]
}
# Analyze selection marks.
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{format_polygon(selection_mark.polygon)}' and has a confidence of {selection_mark.confidence}"
)
테이블
테이블 추출은 일반적으로 테이블 형식이 지정된 대량의 데이터를 포함하는 문서를 처리하기 위한 주요 요구 사항입니다. 레이아웃 모델은 JSON 출력의 pageResults 섹션에서 테이블을 추출합니다. 추출된 테이블 정보입니다. /에는 열 및 행 수, 행 범위 및 열 범위가 포함됩니다. 경계 다각형이 있는 각 셀은 영역이 columnHeader로 인식되는지 여부에 관계없이 정보와 함께 출력됩니다. 모델은 순환되는 테이블 추출을 지원합니다. 각 테이블 셀에는 행 및 열 인덱스와 경계 다각형 좌표가 포함됩니다. 셀 텍스트의 경우 모델은 시작 인덱스(offset)가 포함된 span 정보를 출력합니다. 또한 모델은 문서의 전체 텍스트를 포함하는 최상위 수준 콘텐츠 내에서 length를 출력합니다.
문서 인텔리전스 베일 추출 기능을 사용할 때 고려해야 할 몇 가지 요소는 다음과 같습니다.
추출하려는 데이터가 테이블로 존재하고 테이블 구조가 의미 있나요?
데이터가 테이블 형식이 아닌 경우 데이터가 2차원 그리드에 잘 맞나요?
테이블이 여러 페이지에 걸쳐 있나요? 그렇다면 모든 페이지에 레이블을 지정할 필요가 없도록 PDF를 문서 인텔리전스로 보내기 전에 여러 페이지로 분할합니다. 분석 후 페이지를 단일 테이블로 후처리합니다.
사용자 지정 모델을 만드는 경우 테이블 형식 필드를 참조하세요. 각 열에 대한 동적 테이블의 행 수는 가변적입니다. 각 열에 대한 고정 테이블의 행 수는 일관적입니다.
참고 항목
- 입력 파일이 XLSX인 경우 테이블 분석은 지원되지 않습니다.
- Document Intelligence v4.0 2024-11-30(GA)은 핵심 콘텐츠만 포함하며 관련 캡션 및 각주를 제외하는 그림 및 테이블에 대한 경계 영역을 지원합니다.
{
"tables": [
{
"rowCount": 9,
"columnCount": 4,
"cells": [
{
"kind": "columnHeader",
"rowIndex": 0,
"columnIndex": 0,
"columnSpan": 4,
"content": "(In millions, except earnings per share)",
"boundingRegions": [],
"spans": []
},
]
}
]
}
# Analyze tables.
for table_idx, table in enumerate(result.tables):
print(
f"Table # {table_idx} has {table.row_count} rows and "
f"{table.column_count} columns"
)
for region in table.bounding_regions:
print(
f"Table # {table_idx} location on page: {region.page_number} is {format_polygon(region.polygon)}"
)
for cell in table.cells:
print(
f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'"
)
for region in cell.bounding_regions:
print(
f"...content on page {region.page_number} is within bounding polygon '{format_polygon(region.polygon)}'"
)
주석(2023-02-28-preview API에서만 사용 가능)
레이아웃 모델은 선택 표시 및 십자와 같은 주석을 문서에서 추출합니다. 응답 .. /에는 신뢰도 점수 및 경계 다각형과 함께 주석 종류가 포함됩니다.
{
"pages": [
{
"annotations": [
{
"kind": "cross",
"polygon": [...],
"confidence": 1
}
]
}
]
}
자연스러운 읽기 순서 출력(라틴어만 해당)
readingOrder 쿼리 매개 변수를 사용하여 텍스트 줄이 출력되는 순서를 지정할 수 있습니다. 다음 예제와 같이 인간 친화적인 읽기 순서 출력을 위해 natural을 사용합니다. 이 기능은 라틴어에 대해서만 지원됩니다.

텍스트 추출을 위한 페이지 번호 또는 범위 선택
대규모의 다중 페이지 문서의 경우 pages 쿼리 매개 변수를 사용하여 텍스트 추출을 위한 특정 페이지 번호 또는 페이지 범위를 지정합니다. 다음 예제에서는 모든 페이지(1-10) 및 선택한 페이지(3-6) 모두에 대한 텍스트를 포함하는 10개의 페이지가 있는 문서를 보여 줍니다.

레이아웃 분석 결과 가져오기 작업
두 번째 단계는 레이아웃 분석 결과 가져오기 작업을 호출하는 것입니다. 이 작업은 Analyze Layout 작업이 만든 결과 ID를 입력으로 사용합니다. 다음과 같은 가능한 값을 가진 상태 필드가 포함된 JSON 응답을 반환합니다.
| 필드 | Type | 사용 가능한 값: |
|---|---|---|
| status | string | notStarted: 분석 작업이 시작되지 않았습니다.running: 분석 작업이 진행 중입니다.failed: 분석 작업이 실패했습니다.succeeded: 분석 작업이 성공했습니다. |
succeeded 값이 반환될 때까지 이 작업을 반복적으로 호출합니다. RPS(초당 요청 수) 속도를 초과하지 않도록 하려면 3~5초 간격을 사용합니다.
상태 필드에 값이 있으면 succeeded JSON 응답입니다. /에는 추출된 레이아웃, 텍스트, 표 및 선택 표시가 포함됩니다. 추출된 데이터입니다. /에는 추출된 텍스트 줄과 단어, 경계 상자, 필기 표시가 있는 텍스트 모양, 표 및 선택/선택되지 않은 표시가 표시된 선택 표시가 포함됩니다.
텍스트 줄에 대한 필기 분류(라틴어에만 해당)
응답 .. /includes 각 텍스트 줄이 필기 스타일인지 여부와 신뢰도 점수의 분류를 포함합니다. 이 기능은 라틴어에 대해서만 지원됩니다. 다음 예제에서는 이미지의 텍스트에 대한 필기 분류를 보여 줍니다.

샘플 JSON 출력
레이아웃 분석 결과 가져오기 작업에 대한 응답은 모든 정보가 추출된 문서를 구조화된 방식으로 표현한 것입니다. 샘플 문서 파일 및 해당 구조화된 출력 샘플 레이아웃 출력은 여기를 참조하세요.
JSON 출력에는 다음 두 부분이 있습니다.
readResults노드에는 인식된 모든 텍스트와 선택 표시가 포함됩니다. 텍스트 프레젠테이션 계층 구조는 페이지, 줄, 개별 단어입니다.pageResults노드에는 ‘readResults’ 필드의 줄과 단어에 대한 참조, 경계 상자, 신뢰도와 함께 추출된 테이블과 셀이 포함됩니다.
예제 출력
Text
레이아웃 API는 문서 및 이미지에서 여러 텍스트 각도 및 색이 지정된 텍스트를 추출합니다. 문서, 팩스, 인쇄 및/또는 필기(영어 전용) 텍스트 및 혼합 모드의 사진을 허용합니다. 텍스트는 줄, 단어, 경계 상자, 신뢰도 점수 및 스타일(필기 또는 기타)에 대해 제공된 정보와 함께 추출됩니다. 모든 텍스트 정보는 JSON 출력의 readResults 섹션에 포함됩니다.
머리글이 있는 테이블
레이아웃 API는 JSON 출력의 pageResults 섹션에서 테이블을 추출합니다. 문서를 스캔, 사진화 또는 디지털화할 수 있습니다. 테이블은 병합된 셀 또는 열, 테두리가 있거나 없는 상태, 홀수 각도를 사용하여 복잡하게 지정할 수 있습니다. 추출된 테이블 정보입니다. /에는 열 및 행 수, 행 범위 및 열 범위가 포함됩니다. 경계 상자가 있는 각 셀은 영역이 머리글의 일부로 인식되는지 여부에 관계없이 정보와 함께 출력됩니다. 모델 예측 머리글 셀은 여러 행에 걸쳐 있으며 테이블의 첫 번째 행이 아닐 수도 있습니다. 회전된 테이블에서도 작동합니다. 각 표 셀도 .. /에는 섹션의 개별 단어에 대한 참조가 포함된 전체 텍스트가 readResults 포함됩니다.
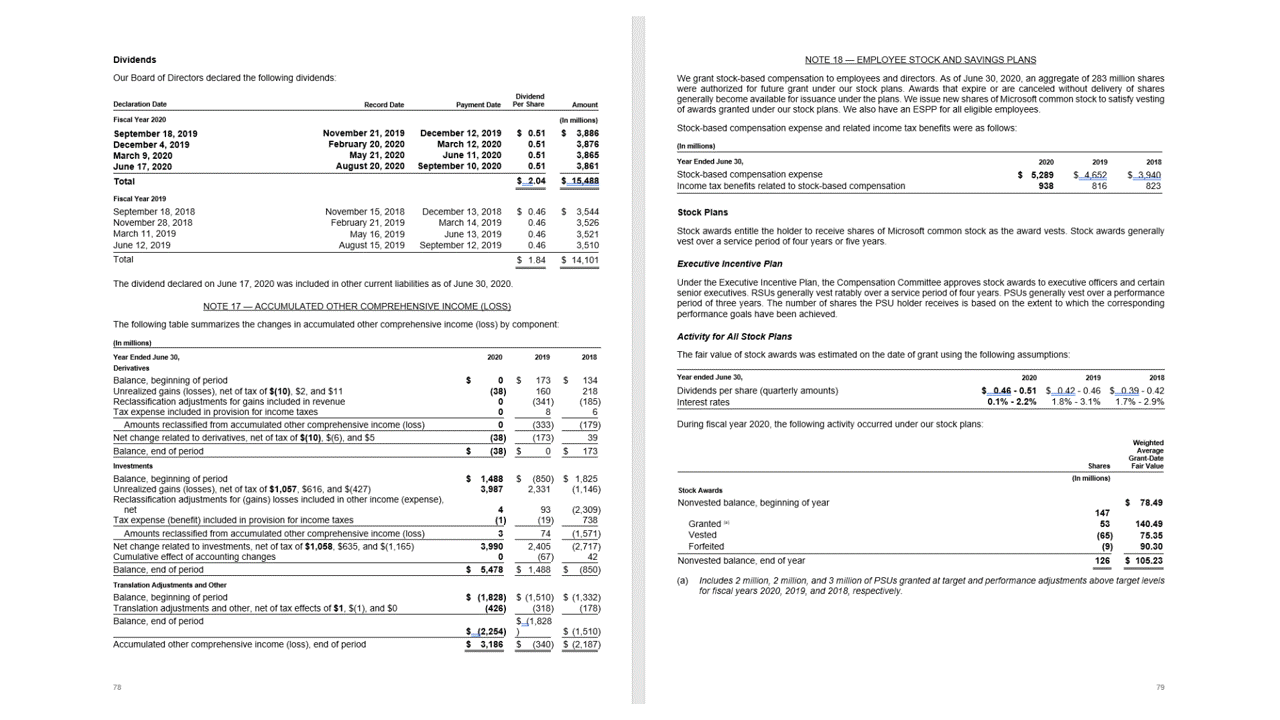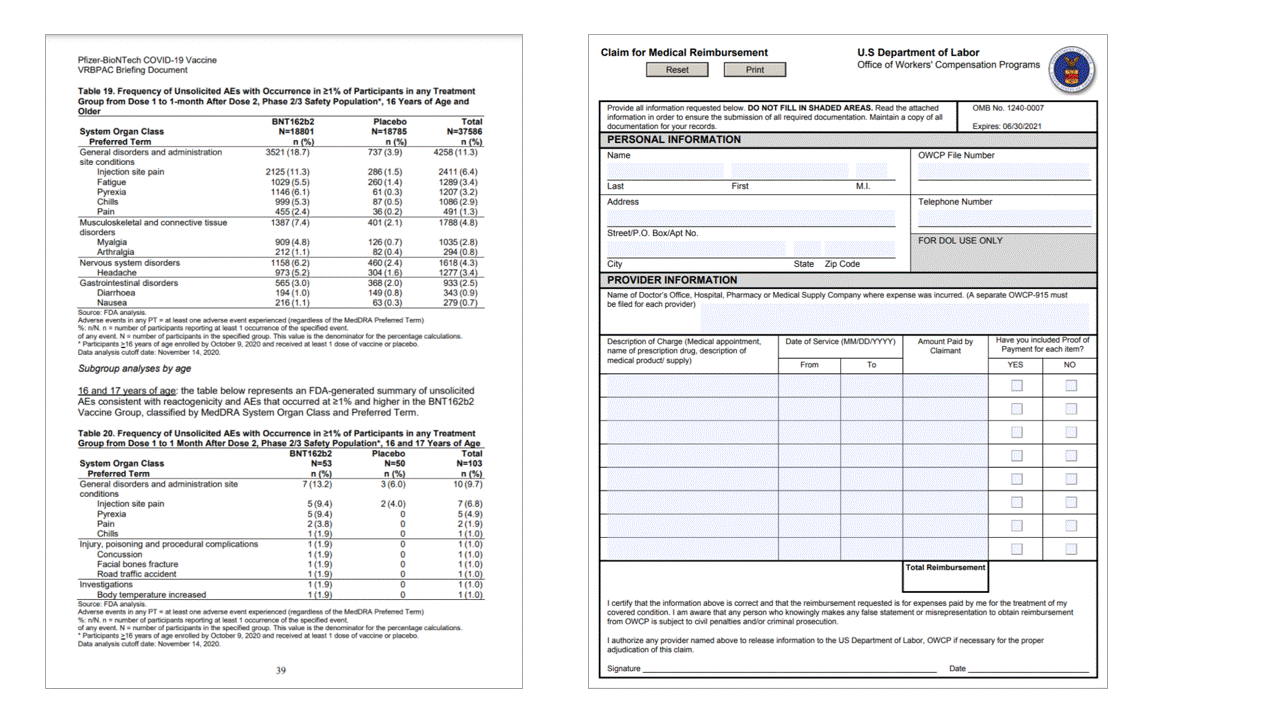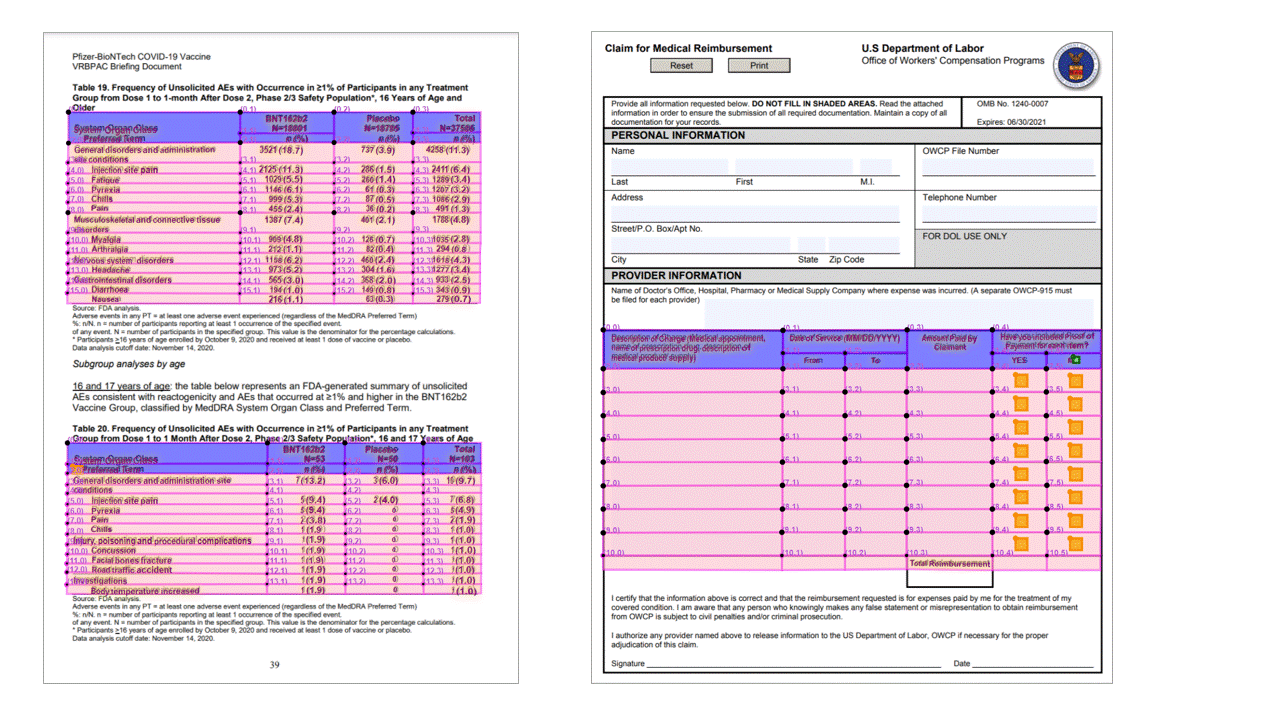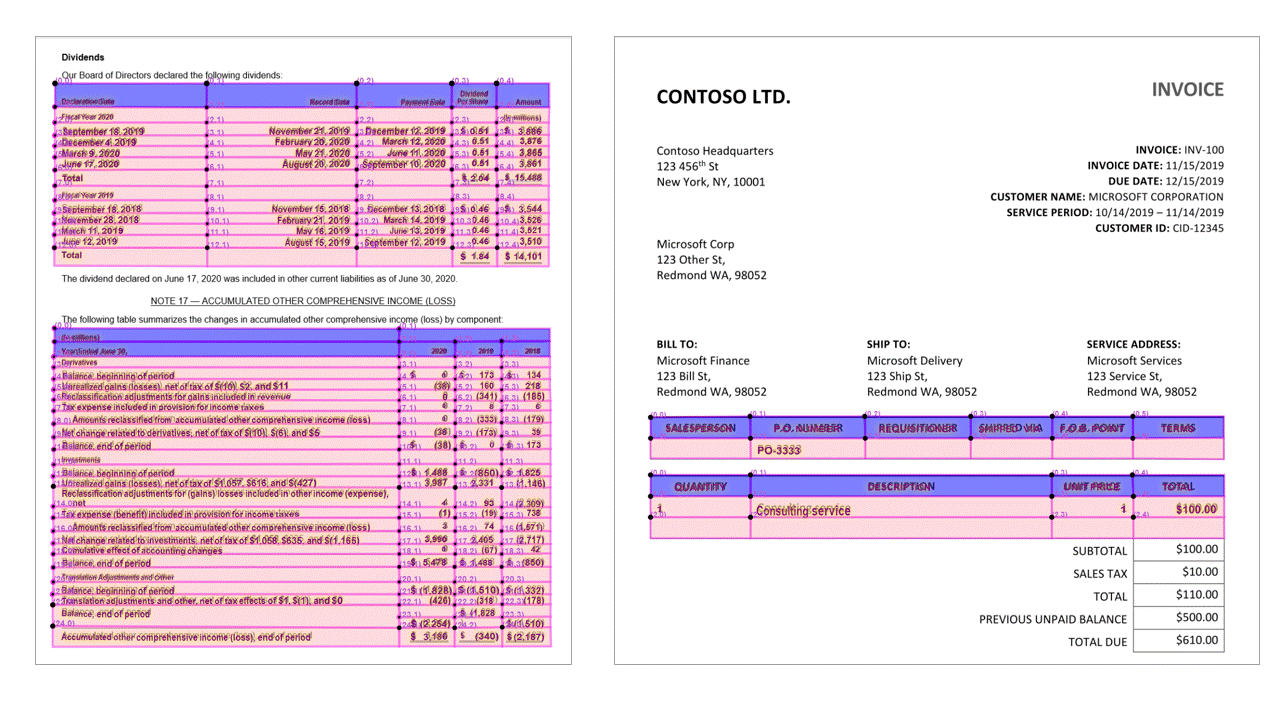
선택 표시
또한 레이아웃 API는 문서에서 선택 표시를 추출합니다. 추출된 선택 표시에는 경계 상자, 신뢰도 및 상태(선택/선택 취소)가 포함됩니다. 선택 표시 정보는 JSON 출력의 readResults 섹션에서 추출됩니다.
마이그레이션 가이드
- 애플리케이션 및 워크플로에서 v3.1 버전을 사용하는 방법을 알아보려면 문서 인텔리전스 v3.1 마이그레이션 가이드를 따르세요.
다음 단계
Document Intelligence 빠른 시작을 완료하고 원하는 개발 언어로 문서 처리 앱 만들기를 시작해 보세요.
Document Intelligence 빠른 시작을 완료하고 원하는 개발 언어로 문서 처리 앱 만들기를 시작해 보세요.