Azure AI 문서 인텔리전스를 사용한 검색 증강 생성
이 콘텐츠는 ![]() v4.0(GA)에 적용됩니다.
v4.0(GA)에 적용됩니다.
소개
RAG(검색 증강 생성)는 ChatGPT와 같은 미리 학습된 LLM(대규모 언어 모델)을 외부 데이터 검색 시스템과 결합하여 원래 학습 데이터 외부의 새 데이터를 통합하는 향상된 응답을 생성하는 디자인 패턴입니다. 애플리케이션에 정보 검색 시스템을 추가하면 문서와 채팅하고, 매력적인 콘텐츠를 생성하고, Azure OpenAI 모델의 강력한 데이터 성능에 액세스할 수 있습니다. 또한 응답을 작성할 때 LLM에서 사용하는 데이터의 제어가 향상됩니다.
문서 인텔리전스 레이아웃 모델은 고급 기계 학습 기반 문서 분석 API입니다. 레이아웃 모델은 고급 콘텐츠 추출 및 문서 구조 분석 기능을 위한 포괄적인 솔루션을 제공합니다. 레이아웃 모델을 사용하면 텍스트 및 구조 요소를 쉽게 추출하여 텍스트의 큰 본문을 임의의 분할이 아닌 의미 체계 콘텐츠에 따른 더 작고 의미 있는 청크로 나눌 수 있습니다. 추출된 정보를 Markdown 형식으로 편리하게 출력할 수 있으므로 제공된 구성 요소를 기반으로 의미 체계 청킹 전략을 정의할 수 있습니다.
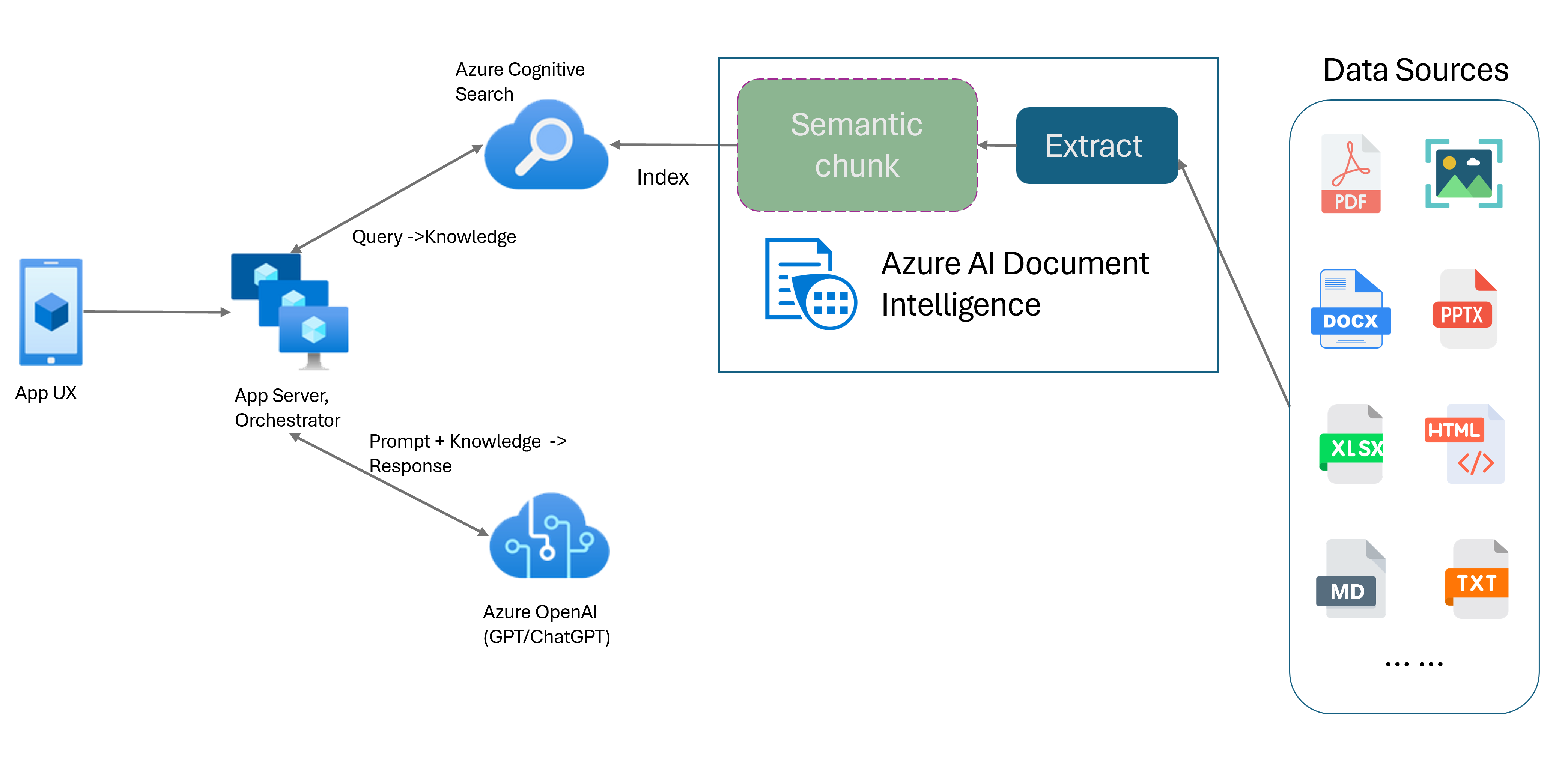
의미 체계 청킹
긴 문장은 NLP(자연어 처리) 애플리케이션이 처리하기 어렵습니다. 문장이 여러 절, 복합 명사 또는 동사구, 관계절, 괄호 그룹화로 구성된 경우 특히 그렇습니다. 인간 관찰자와 마찬가지로 NLP 시스템도 제시된 모든 종속성을 성공적으로 추적해야 합니다. 의미 체계 청킹의 목표는 문장 표현의 의미상 일관된 조각을 찾는 것입니다. 그런 다음 이러한 조각을 독립적으로 처리하고, 정보, 해석 또는 의미 체계 관련성의 손실 없이 의미 체계 표현으로 다시 결합할 수 있습니다. 텍스트의 내재된 의미는 청킹 프로세스의 지침으로 사용됩니다.
텍스트 데이터 청킹 전략은 RAG 응답 및 성능을 최적화하는 데 중요한 역할을 합니다. 고정 크기와 의미 체계는 두 가지 고유한 청킹 방법입니다.
고정 크기 청킹. 오늘날 RAG에서 사용되는 대부분의 청킹 전략은 청크라고 하는 고정 크기의 텍스트 세그먼트를 기반으로 합니다. 고정 크기 청킹은 로그와 데이터처럼 강력한 의미 체계 구조가 없는 텍스트에서 빠르고 쉽고 효과적입니다. 하지만 의미 체계 이해와 정확한 컨텍스트가 필요한 텍스트에는 권장되지 않습니다. 창의 고정 크기 특성으로 인해 단어, 문장 또는 단락이 끊어져 이해가 방해되고 정보와 이해의 흐름이 중단될 수 있습니다.
의미 체계 청킹. 이 방법은 의미 체계 이해를 기반으로 텍스트를 청크로 나눕니다. 나누기 경계는 문장 주어에 초점을 맞추고 계산 알고리즘적으로 복잡한 리소스를 많이 사용합니다. 하지만 각 청크 내에서 의미 체계 일관성을 유지한다는 고유한 이점이 있습니다. 텍스트 요약, 감정 분석, 문서 분류 작업에 유용합니다.
문서 인텔리전스 레이아웃 모델을 사용한 의미 체계 청킹
Markdown은 구조화되고 형식이 지정된 마크업 언어이며 RAG(검색 증강 생성)에서 의미 체계 청킹이 가능하도록 하는 인기 있는 입력입니다. 레이아웃 모델에서 Markdown 콘텐츠를 사용하여 단락 경계를 기반으로 문서를 분할하고, 테이블의 특정 청크를 만들고, 청킹 전략을 미세 조정하여 생성된 응답의 품질을 향상시킬 수 있습니다.
레이아웃 모델 사용의 이점
간소화된 처리. 단일 API 호출로 디지털 및 스캔된 PDF, 이미지, Office 파일(docx, xlsx, pptx), HTML과 같은 다양한 문서 형식을 구문 분석할 수 있습니다.
확장성 및 AI 품질 레이아웃 모델은 OCR(광학 인식), 테이블 추출, 문서 구조 분석에서 확장성이 높습니다. 이 모델은 309개의 인쇄 언어와 12개의 필기 언어를 지원하여 AI 기능에 기반한 고품질 결과를 보장합니다.
LLM(대규모 언어 모델) 호환성. 레이아웃 모델 Markdown 형식 출력은 LLM 친화적이며, 워크플로에 원활하게 통합할 수 있습니다. 문서의 테이블을 Markdown 형식으로 전환하고 문서를 구문 분석하는 데 드는 광범위한 노력을 방지하여 LLM 이해를 높일 수 있습니다.
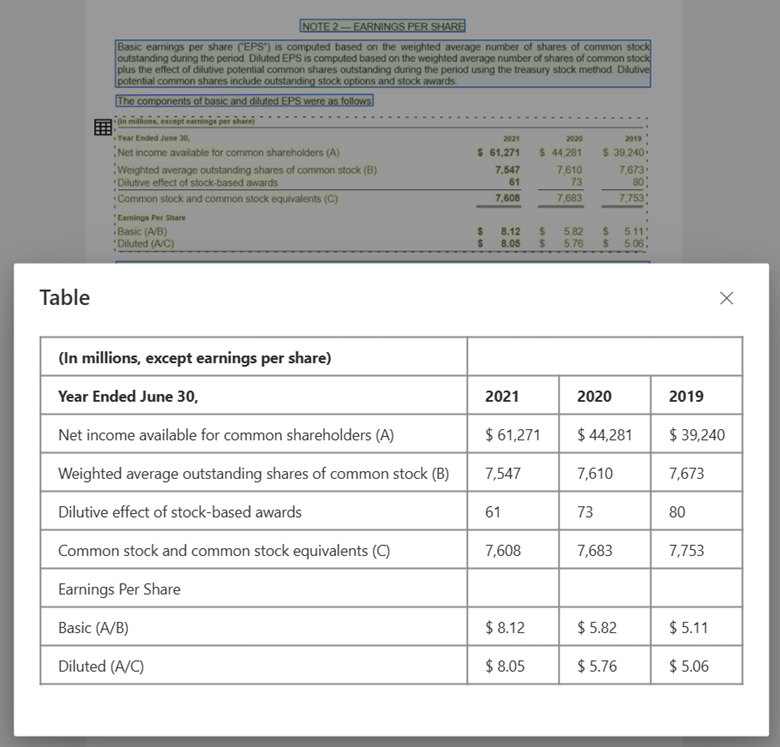
문서 인텔리전스 스튜디오를 사용하여 처리되고 레이아웃 모델을 사용하여 MarkDown으로 출력된 텍스트 이미지

레이아웃 모델을 사용하여 문서 인텔리전스 스튜디오로 처리된 텍스트 이미지
시작하기
문서 인텔리전스 레이아웃 모델 2024-11-30(GA) 은 다음 개발 옵션을 지원합니다.
시작할 준비가 되셨나요?
문서 인텔리전스 스튜디오
문서 인텔리전스 스튜디오 빠른 시작에 따라 시작할 수 있습니다. 다음으로 제공된 샘플 코드를 사용하여 문서 인텔리전스 기능을 자체 애플리케이션에 통합할 수 있습니다.
레이아웃 모델로 시작하세요. 스튜디오에서 RAG를 사용하려면 다음 분석 옵션을 선택해야 합니다.
**Required**- 분석 실행 범위 → 현재 문서.
- 페이지 범위 → 모든 페이지.
- 출력 형식 스타일 → Markdown.
**Optional**- 관련 선택적 감지 매개 변수를 선택할 수도 있습니다.
저장을 선택합니다.
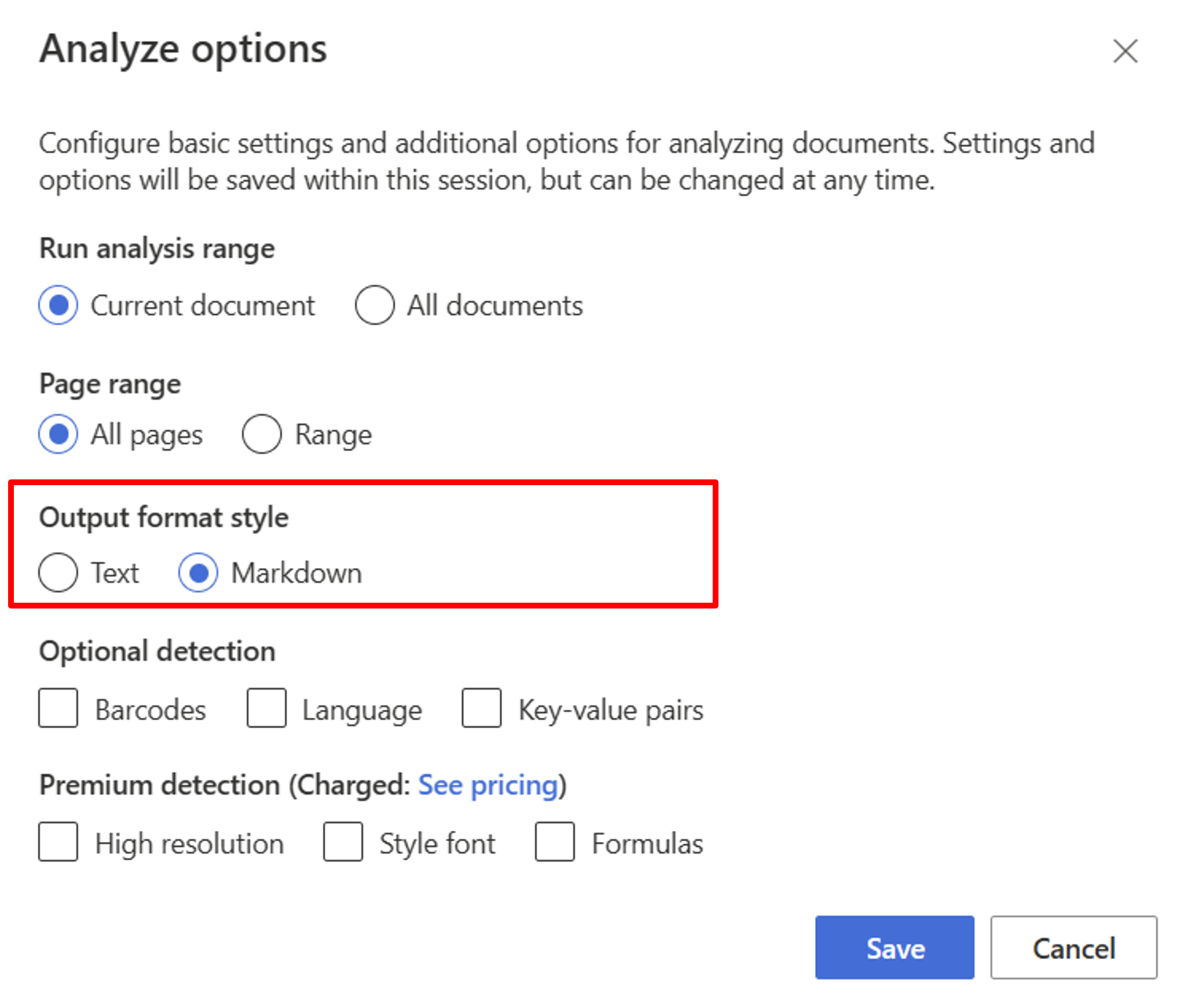
출력을 보려면 분석 실행 단추를 선택합니다.

SDK 또는 REST API
선호하는 프로그래밍 언어 SDK 또는 REST API의 문서 인텔리전스 빠른 시작을 따를 수 있습니다. 레이아웃 모델을 사용하여 문서에서 콘텐츠와 구조를 추출합니다.
Markdown 출력 형식의 문서를 분석하기 위해 GitHub 리포지토리에서 코드 샘플과 팁을 확인할 수도 있습니다.
의미 체계 청킹을 사용하여 문서 채팅 빌드
Azure OpenAI on Your Data를 사용하면 문서에서 지원되는 채팅을 실행할 수 있습니다. Azure OpenAI on Your Data는 문서 인텔리전스 레이아웃 모델을 적용하여 테이블과 단락을 기반으로 긴 텍스트를 청킹함으로써 문서를 추출하고 구문 분석합니다. GitHub 리포지토리에 있는 Azure OpenAI 샘플 스크립트를 사용하여 청킹 전략을 사용자 지정할 수도 있습니다.
Azure AI 문서 인텔리전스는 이제 문서 로더 중 하나로 LangChain과 통합되었습니다. 이를 사용하여 쉽게 데이터를 로드하고 Markdown 형식으로 출력할 수 있습니다. 자세한 내용은 LangChain에서 Azure AI 문서 인텔리전스를 문서 로더로, Azure Search를 검색기로 사용하는 RAG 패턴의 간단한 데모를 보여 주는 샘플 코드 를 참조하세요.
데이터 솔루션 가속기 코드 샘플과의 채팅은 엔드 투 엔드 기준선 RAG 패턴 샘플을 보여 줍니다. 이 샘플은 Azure AI Search를 검색기로 사용하고 Azure AI 문서 인텔리전스를 문서 로딩과 의미 체계 청킹에 사용합니다.
사용 사례
문서에서 특정 섹션을 찾는 경우 의미 체계 청킹을 사용하여 섹션 머리글을 기반으로 문서를 더 작은 청크로 나누면 원하는 섹션을 빠르고 쉽게 찾는 데 도움이 됩니다.
# Using SDK targeting 2024-11-30 (GA), make sure your resource is in one of these regions: East US, West US2, West Europe
# pip install azure-ai-documentintelligence==1.0.0b1
# pip install langchain langchain-community azure-ai-documentintelligence
from azure.ai.documentintelligence import DocumentIntelligenceClient
endpoint = "https://<my-custom-subdomain>.cognitiveservices.azure.com/"
key = "<api_key>"
from langchain_community.document_loaders import AzureAIDocumentIntelligenceLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter
# Initiate Azure AI Document Intelligence to load the document. You can either specify file_path or url_path to load the document.
loader = AzureAIDocumentIntelligenceLoader(file_path="<path to your file>", api_key = key, api_endpoint = endpoint, api_model="prebuilt-layout")
docs = loader.load()
# Split the document into chunks base on markdown headers.
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
docs_string = docs[0].page_content
splits = text_splitter.split_text(docs_string)
splits
다음 단계
Azure AI 문서 인텔리전스에 대해 자세히 알아봅니다.
Document Intelligence 빠른 시작을 완료하고 원하는 개발 언어로 문서 처리 앱 만들기를 시작해 보세요.