SQLServer: Populating Table With Kafka Topic Data
Introduction
This article is second in the series on how RDBMS data can be synchronized at close to real time using a streaming platform like Apache Kafka.
The first part of this series can be found here which explains on how data from SQL Server source can be streamed using Apache Kafka
This article explains on the similar scenario from another perspective which includes populating a SQL Server table close to real time using data published through a Kafka topic
Scenario
The scenario on hand includes an already created Kafka topic. The requirement is to get the data streamed by the topic close to real time and create/populate a RDBMS table using the streamed data.
Similar to the earlier scenario, we will be using a SQL Server instance running on the docker to create the table and populate it with the data from Kafka topic ingested from a MySQL table data.
Illustration
For illustrating the above scenario, the below setup would be used
- A MySQL instance with sample table to be used as the source for Kafka
- SQL Server 2017 instance hosted on Ubuntu Linux server to act as the sink for Kafka topic data.
- An Apache Kafka instance for creating a streaming topic
- An Apache Kafka connect instance for connecting to MySQL database instance as source and SQL Server instance as the sink to create the table and populate it with data
The flow diagram for the setup would look like the below
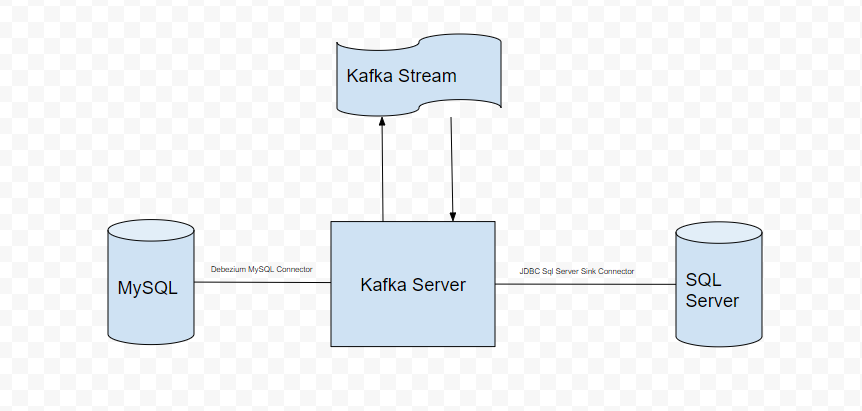
For the ease of setting up the above environment, dockerized containers are used.
The first article includes step by step explanation for setting up the sample project containing dockerized containers for the above components
Assuming the dockerized environments were setup as per the article, the status can be checked using the docker ps command.
The result should reflect the below
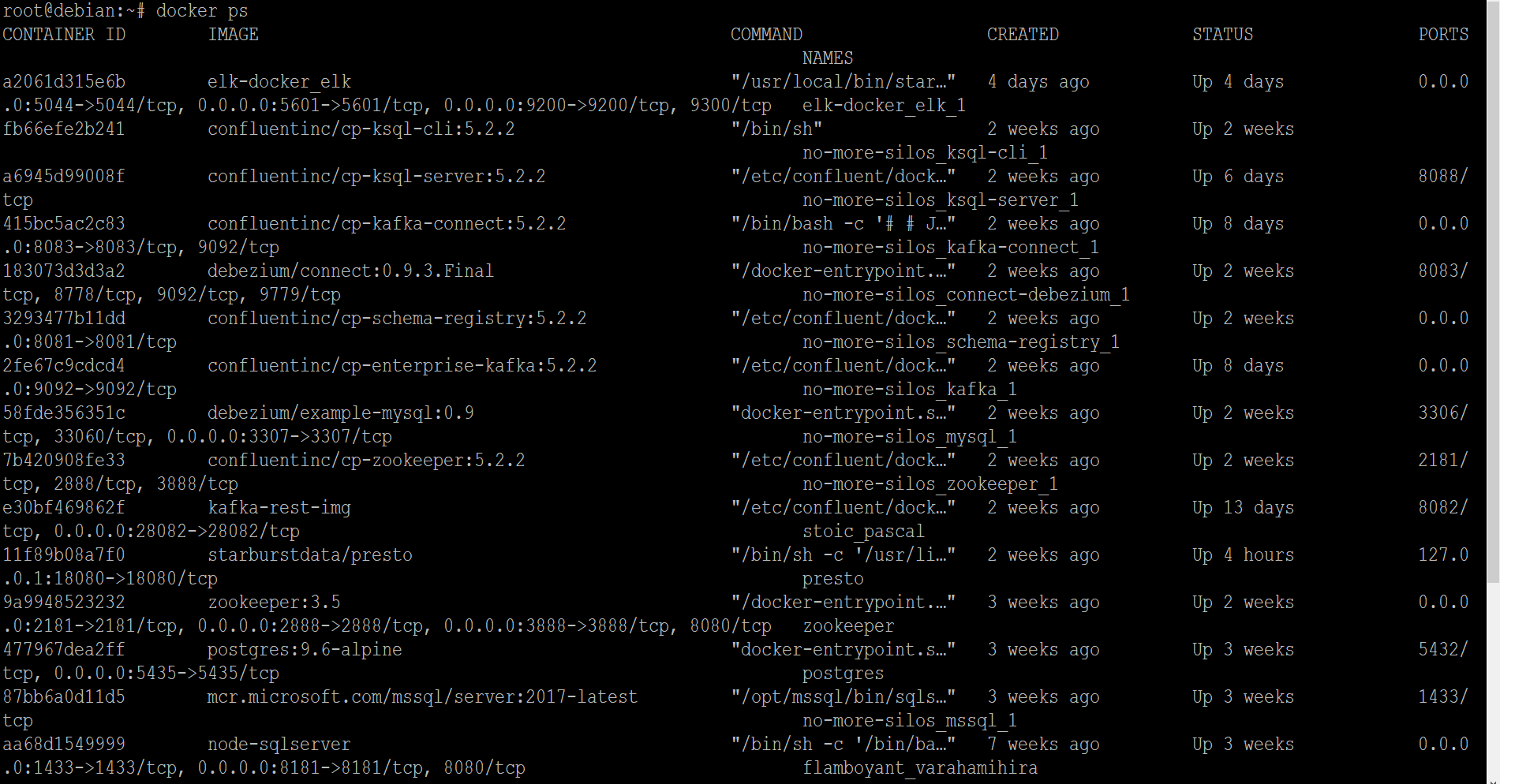
The illustration would be using a sample table within the included MySQL instance to stream data to the Kafka topic following which a sink connection would be configured to the SQLServer instance to create a table dynamically based on the topic data and populate it.
Now that the status is confirmed, next stage is to check the MySQL instance and make sure it contains the sample table with data for Kafka topic to ingest.
The command given below can be used for this purpose
docker exec -it no-more-silos_mysql_1 bash -c 'mysql -u connect_user -pasgard demo'
The result will be as shown in the screenshot below
Indicating that MySQL utility is launched
To check the available tables in the db, SHOW TABLES command can be used

For the sake of this illustration, the accounts table would be used
To start off, the sample data can be checked using a simple SELECT * FROM accounts SQL statement
And the result would be as per below
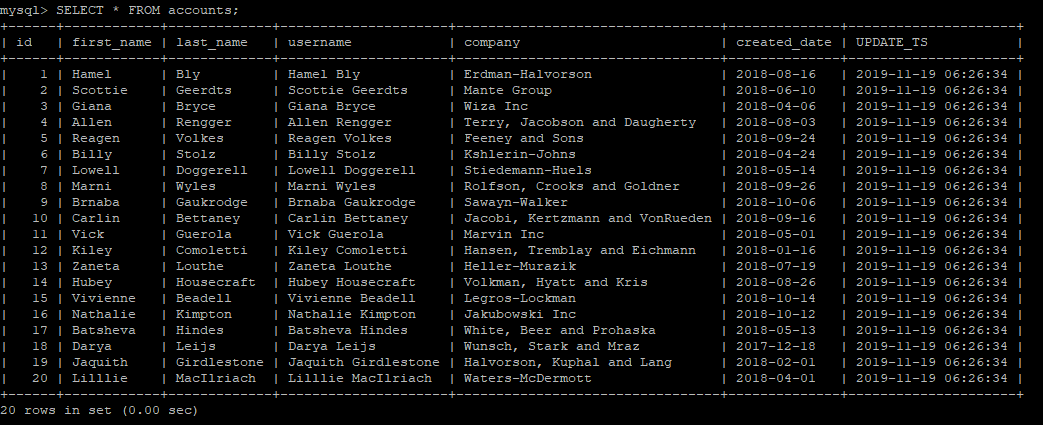
The attempt is to get the data from this table streamed through a Kafka topic and then use it to create a table in SQL Server and populate it with some data.
The Kafka topic can be created using Kafka Connect by creating a connector using Debezium or JDBC connector.
For the connector to work correctly, the table has to be given below privileges
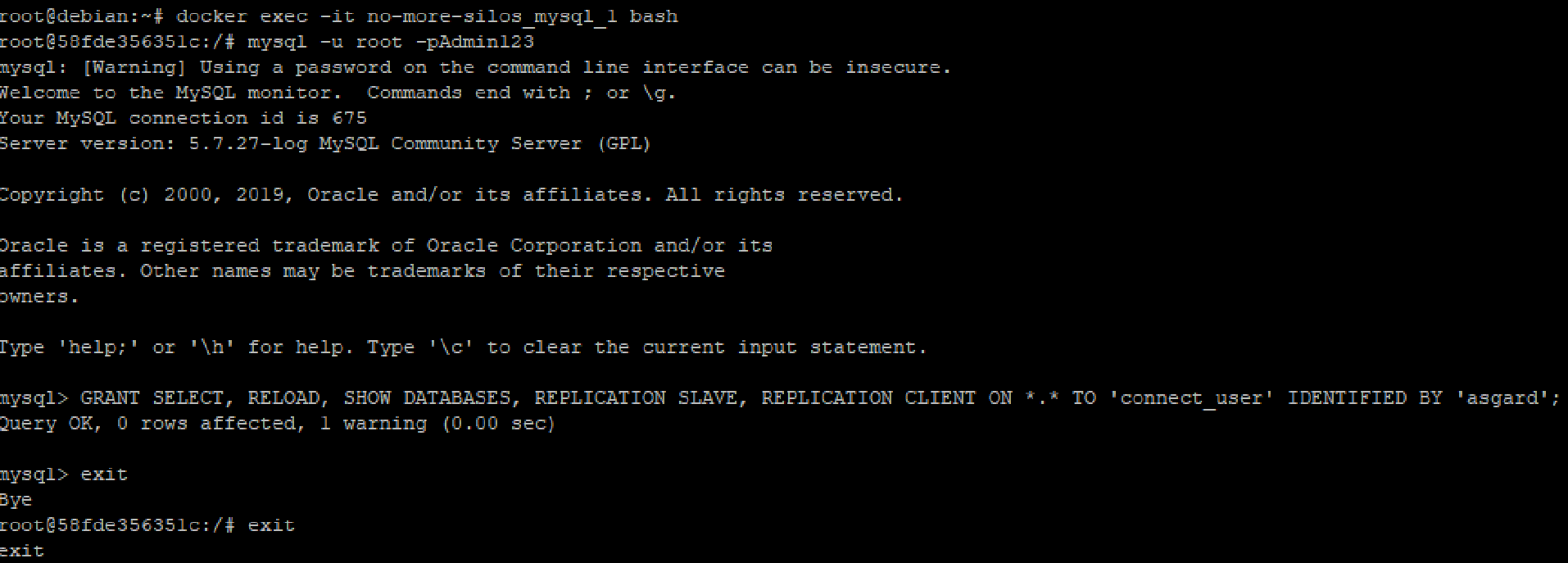
For this illustration, a Debezium based connector shall be used which makes use of the log file information to stream data changes from MySQL table.
The command will look like below
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{"name": "debezium-mysql-source-accounts","config": {"connector.class": "io.debezium.connector.mysql.MySqlConnector","database.hostname": "IPAddress","database.port": "3306","database.user": "connect_user","database.password": "asgard","database.server.id": "42","database.server.name": "asgard","table.whitelist": "demo.accounts","database.history.kafka.bootstrap.servers": "kafka:29092", "database.history.kafka.topic": "demo.accounts" , "include.schema.changes": "true","transforms":"unwrap,route","transforms.route.type":"org.apache.kafka.connect.transforms.RegexRouter","transforms.route.regex":"([^.]+)\\.([^.]+)\\.([^.]+)","decimal.handling.mode":"string","transforms.unwrap.drop.tombstones":"false","transforms.unwrap.type":"io.debezium.transforms.UnwrapFromEnvelope","transforms.route.replacement":"mysql_demo_$3","snapshot.mode":"initial"}}'
Once created the status can be checked as follows
curl -s "http://localhost:8083/connectors"| jq '.[]'| xargs -I{connector_name} curl -s "http://localhost:8083/connectors/"{connector_name}"/status"| jq -c -M '[.name,.connector.state,.tasks[].state]|join(":|:")'| column -s : -t| sed 's/\"//g'| sort
Result would be as below

Check and ensure the topic is created as defined
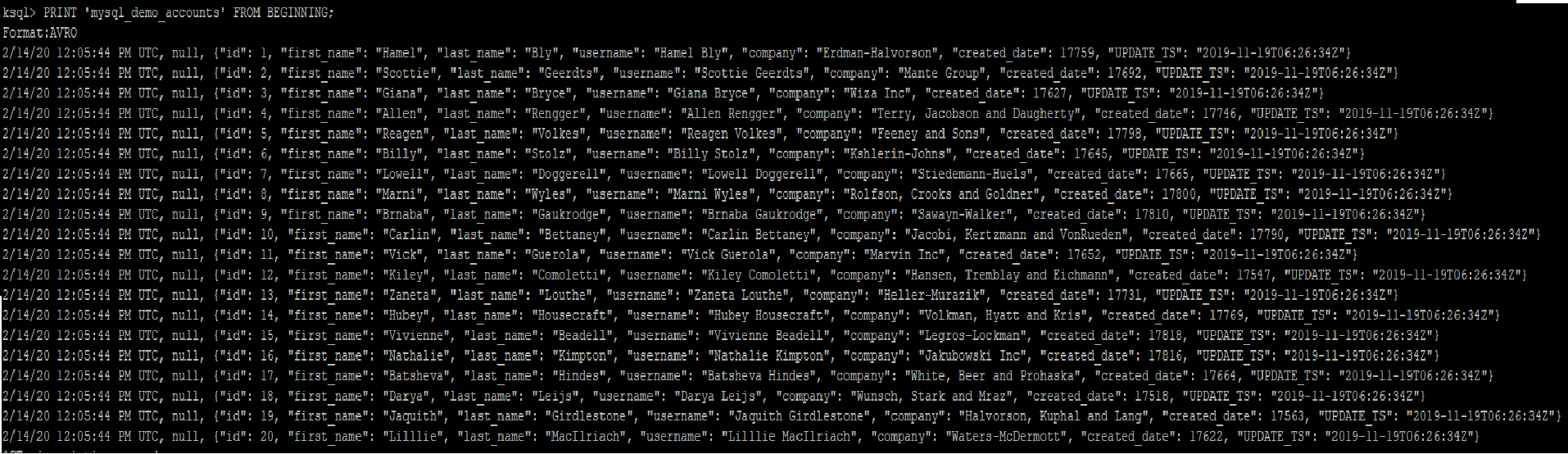
The topic starts emitting the data changes from accounts table
Next stage is to create the table in SQL Server and populate it from the Kafka topic data
For this purpose, a sink connector needs to be used.
The JDBC sink connector can be used for this purpose
The package includes SQL Server sink connector which can be used to create and populate the table in the SQL Server instance. For the connector to work fine, Kafka Connect should have the correct JDBC driver based on JRE version installed as a JAR file. For the Github project that is used for this illustration the JAR has to be copied to /u01/jdbc-drivers/ folder in the host Linux machine.
The command to create the Sql Server Sink connector would look like below
curl -X POST http://localhost:8083/connectors -H ``"Content-Type: application/json" -d ``'{"name": "jdbc-sqlserver-sink-mysql-accounts","config": { "connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector", "tasks.max": "1", "key.converter": "org.apache.kafka.connect.storage.StringConverter", "key.converter.schema.registry.url": "http://schema-registry:8081", "value.converter": "io.confluent.connect.avro.AvroConverter", "value.converter.schema.registry.url": "http://schema-registry:8081", "header.converter": "org.apache.kafka.connect.storage.SimpleHeaderConverter", "config.action.reload": "restart", "errors.retry.timeout": "0", "errors.tolerance": "none", "errors.log.enable": "true", "errors.log.include.messages": "true", "topics": "mysql_demo_accounts", "errors.deadletterqueue.topic.name": "DLQ_MySQLDemoAccounts", "errors.deadletterqueue.context.headers.enable": "true", "connection.url": "jdbc:``sqlserver://192.168.95.5``:1433;databaseName=from_MySQL;", "connection.user": "sa", "connection.password": "Yukon900", "insert.mode": "upsert", "table.name.format": "mysql_Accounts", "pk.mode": "record_value", "pk.fields": "id", "auto.create": "true", "auto.evolve": "false", "max.retries": "1", "retry.backoff.ms": "3000"}}'
Once created, check the status and ensure tasks are running

From the screenshot its evident the connector is running
This implies behind the scene the connector has created the required sink table in the SQL Server instance and populate the table with data from the Kafka topic.
This is because auto.create is set to true in the connector configuration above.
To confirm this, connect to the Sql Server instance using SSMS and ensure the table is created within the specified database (from_MySQL in the above case).
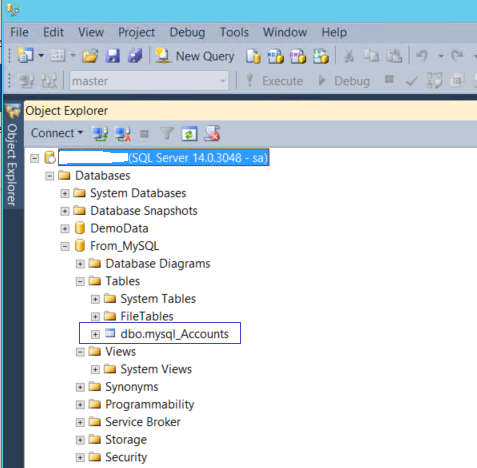
The screenshot shows the table mysql_Accounts is created inside SqlServer instance as specified.
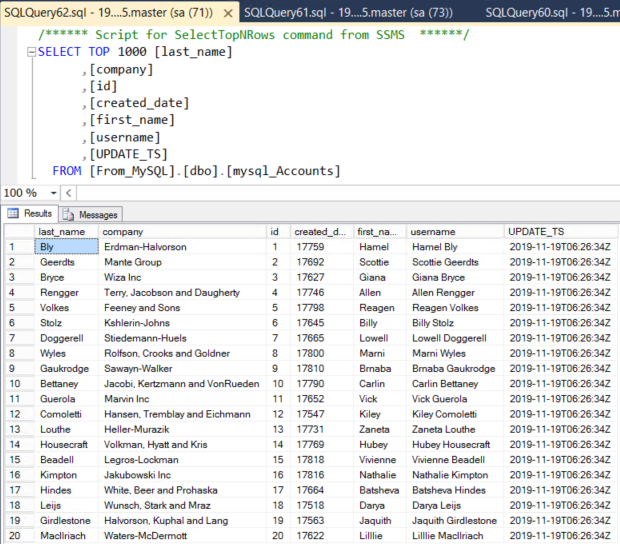
The data can be checked to ensure it includes the entire topic data
Propagating DML Changes
The next step is to do some DML changes and ensure the topic is picking up and transmitting the changes to the sink table close to real time
New Insert
Insert a new row into MySQL and check the topic and the sink table
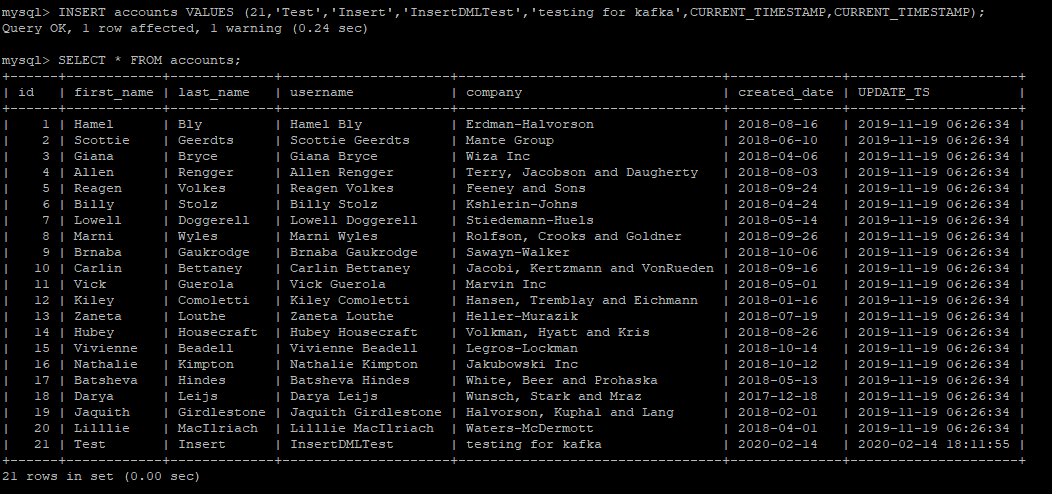
Checking the topic shows the new row included as a message
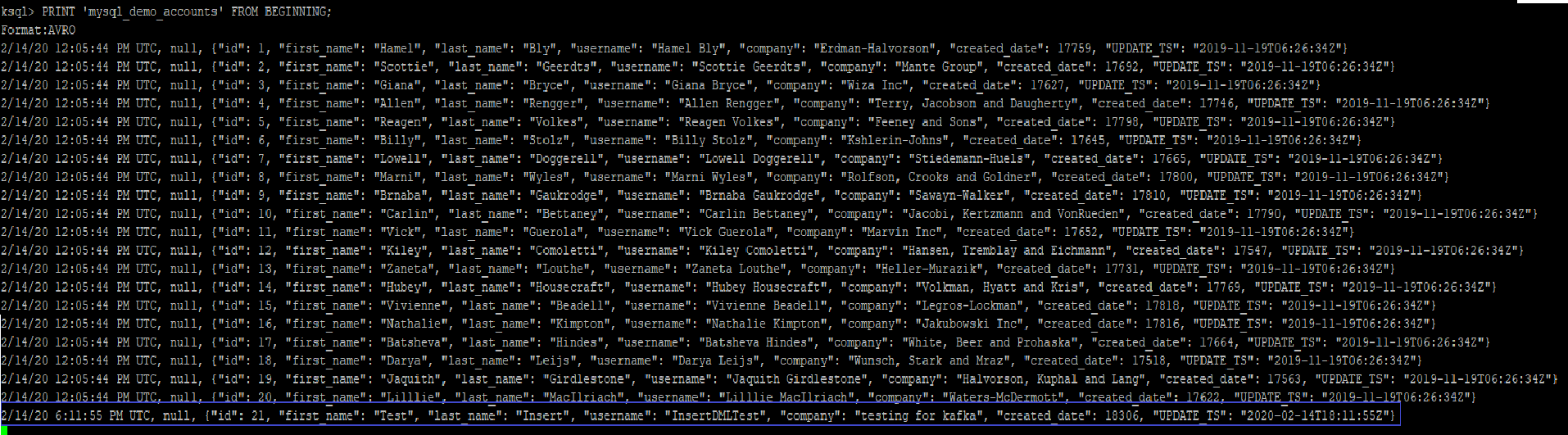
Indicating that new insert has been picked up by Kafka topic
Check the sink table to ensure that the new row has been populated
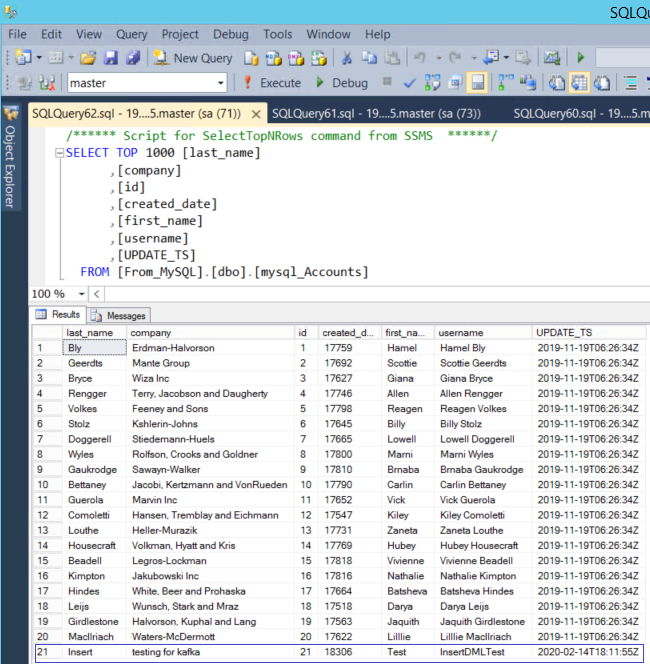
Existing Row Modify
This time update is performed on the newly added row in the last stage and let’s see how Kafka topic and sink table picks it up
Kafka topic picks up the modification almost instantaneously.
Kafka being a streaming platform streams the change as a new row with the same id value as shown below. The timestamp value will denote the modification time of the row
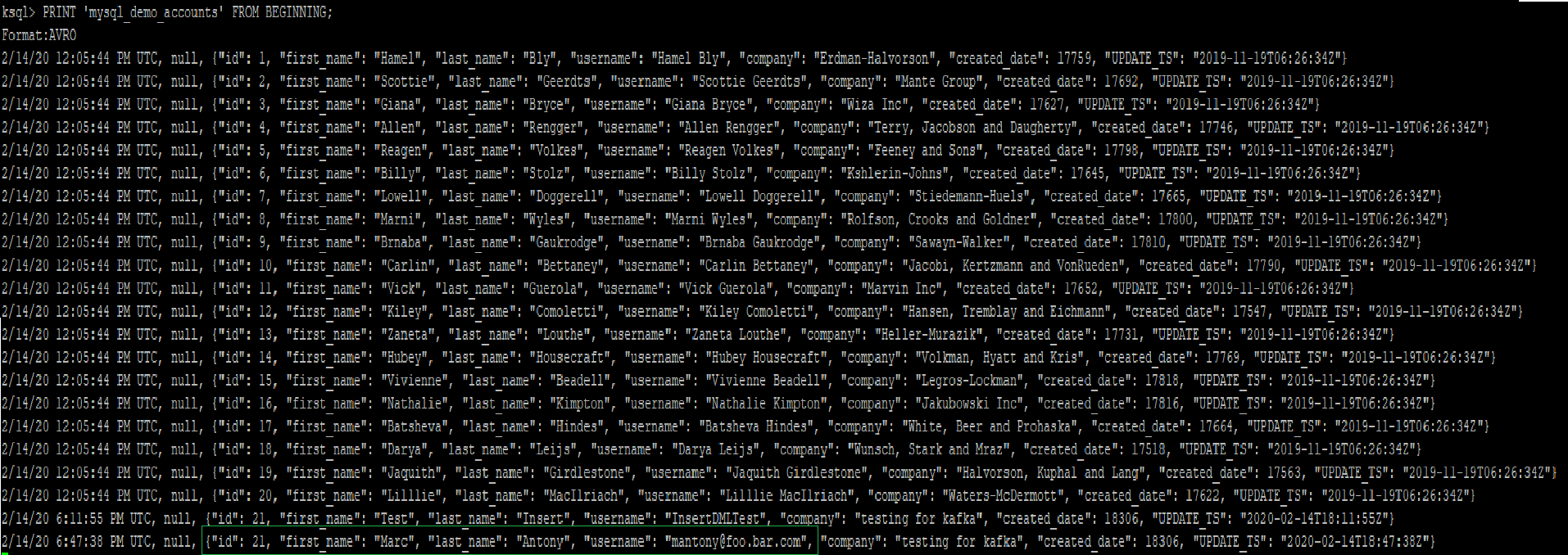
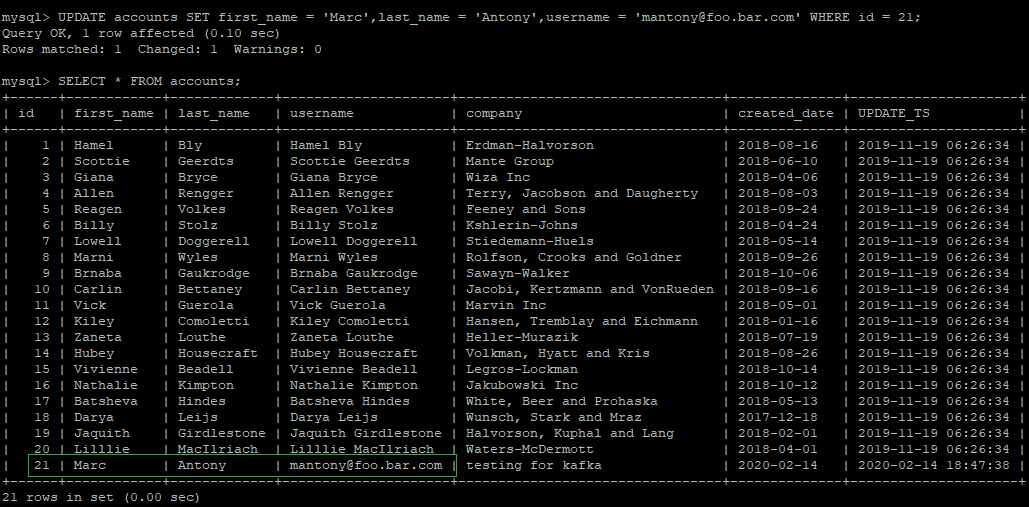
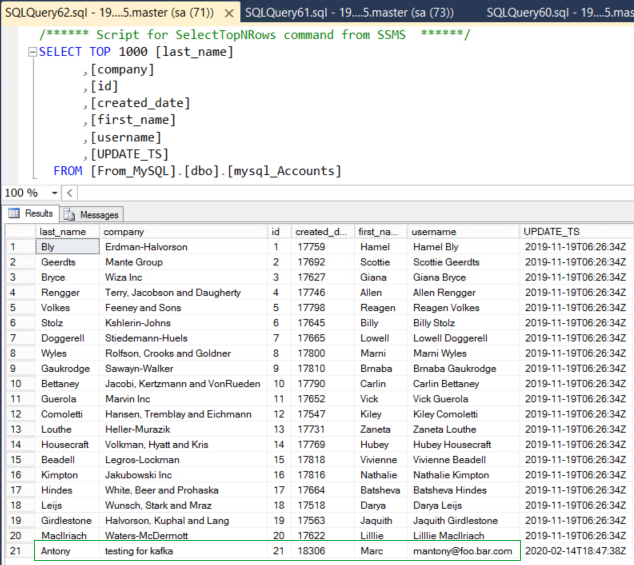
Check the sink table. The Kafka connector would pick up the change and update the row inside Sql Server table based on the key column (id) value within the topic which can be confirmed from the screenshot below
Delete Existing Row
As of now, only soft deletes are handled by Debezium connector. Actual delete DML events are transmitted as a series of two events a row with _deleted as true followed by a tombstone event.
The sink connector does not currently pick up the delete operation from this tombstone event.
Conclusion
The above illustration shows how data from a Kafka topic can be used to create and populate a table. As shown in the illustration, this approach can be used to synchronize data between source and sink systems.
See Also