A Hitchhikers Guide to Search
Editor’s note: The following post was written by Windows Development MVP Matias Quaranta as part of our Technical Tuesday series.
" The answer to the ultimate question of life, the universe, and everything is... 42"
The Hitchhiker’s Guide to the Galaxy
Or, translating it to Web-Applications Terms, the answer to the ultimate question of content discoverability, performance and everything is... a great Search Service.
The goal of this Guide is to provide quick access to the most relevant pieces of information regarding the key aspects of Azure Search, I won't provide exact code examples but I'll point you in the best direction to find them hopefully making your journey to knowledge faster.
A look back in time
To understand what is Azure Search, let's first go back in time to Lucene, a text search engine (originally created on Java and later ported to .Net as Lucene.net) that creates indexes on our documents based on their data and characteristics, allowing fast searches including tokenization and root word analysis. It also lets us create custom logic to ponder and score documents, so our results will match more closely what the user is trying to find.
Then came Solr, a wrapper around Lucene that provided index access through XML/HTTP services, caching and replication. We could install Solr on our servers or a virtual machine and consume it from our applications.
ElasticSearch was born as an implementation over Lucene that added a REST interface, replication, faceting, filtering, JSON (schema-free) document storage, geo-localization and suggestions (among its main features). But we still needed to rely on maintaining and managing our own infrastructure.
Enter Azure Search

Azure Search can be understood as a fully managed Search-as-a-service solution working in the Cloud, this means that we don't need to worry or invest our time in maintaining the infrastructure behind the search engine, we can focus 100% on creating our product and offer increased value to our customers by adding a robust search experience in our applications. Azure Search adds scalability, fault-tolerance and replication, all working behind a public REST API (that uses OData syntax and Lucene Query syntax for Queries) that allows our applications to use the engine directly from our on-premises servers, from Azure, other cloud provider or any other hosting solution.
It's important to highlight the flexibility of Azure Search, with a couple of clicks on the Azure Portal (or by the Azure Search Management REST API) we can enlarge or shrink our engine capacity (either size by adjusting partitions or throughput/availability by adjusting replicas) according to our needs and budget, effectively adjusting to the demand curve in a quick and effort-less way.
The main capabilities (some of which we will discuss in this article) of Azure Search are:
- Full-Text Search: We can create any amount of indexes without extra cost to index our documents manually (using the API) or automatically (using Indexers) and perform blazing fast searches no matter the size of the documents.
- Multi-Language support: Right now, Azure Search supports 56 languages to use on the text Analyzers that work the indexing magic, allowing word stemming on each and every one of those languages.
- Custom scoring: By default, Azure Search applies the TF-IDF algorithm on our index's Searchable fields to calculate a score and provide results ordered by higher to lower, but we can customize this behavior by assigning weights to different fields or applying functions (boosting new content for example) that alter the resulting score.
- Hit-highlighting: Allows you to show where, in the documents, were the search words found.
- Suggestions: Suggesting possible values for an auto-complete search text input.
- Faceting: A facet is the quantitative categorization of a document on a given area, used mostly on Product Listings or Navigation that include possible filtering values with their quantities.
- Filtering: Allows for result narrowing given certain field values.
- Advanced querying: Azure Search supports keywords, phrase and prefix search (including the use of "+", "-" or "*") and recently Lucene query syntax (we’ll discuss this in detail on following sections).
- Geo-spatial support: Geo-spatial data can be stored and used to provide custom scoring, filtering and sorting.
Creating indexes
An index is defined as an abstraction above your document data. It contains all the necessary information for users to search and find your content. It can contain your whole document or just key attributes, for example, for a news article, the title, body and main image, but not all the other images associated with it, because that's not relevant to the search function. You can then point to the whole document using the search result if you need to.
An index contains fields, Azure Search supports several types of fields within an index:
- Edm.String: Text that can optionally be tokenized for full-text search (word-breaking, stemming, etc.).
- Edm.Boolean: True/false.
- Edm.Int32: 32-bit integer values.
- Edm.Int64: 64-bit integer values.
- Edm.Double: Double-precision numeric data.
- Edm.DateTimeOffSet: Date time values represented in the OData V4 format: yyyy-MM-ddTHH:mm:ss.fffZ or yyyy-MM-ddTHH:mm:ss.fff[+|-]HH:mm. Precision of DateTime fields is limited to milliseconds. If you upload datetime values with sub-millisecond precision, the value returned will be rounded up to milliseconds (for example, 2015-04-15T10:30:09.7552052Z will be returned as 2015-04-15T10:30:09.7550000Z).
- Collection (Edm.String): A list of strings that can optionally be tokenized for full-text search.
- Edm.GeographyPoint: A point representing a geographic location on the globe. For request and response bodies the representation of values of this type follows the GeoJSON "Point" type format. For URLs OData uses a literal form based on the WKT standard.
And each field can have one or more of these attributes:
- Retrievable: Can be retrieved among the search results.
- Searchable: The field is indexed and analyzed and can be used for full-text search.
- Filterable: The field can be used to apply filters or be used on Scoring Functions (next section)
- Sortable: The field can be used to sort results. Sorting results overrides the scoring order that Azure Search provides.
- Facetable: The field values can be used to calculate Facets and possibly afterwards used for Filtering.
- Key: It's the primary unique key of the document.
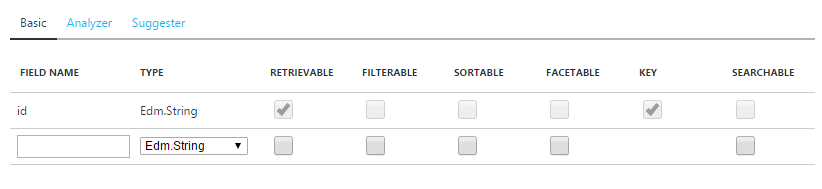
With this in mind, creating an index in the Azure Portal or through the API is quite easy.
Exploring and searching
Searching is achieved through the API using OData syntax or Lucene Query syntax, but there’s a Search explorer available on the Azure Portal too:
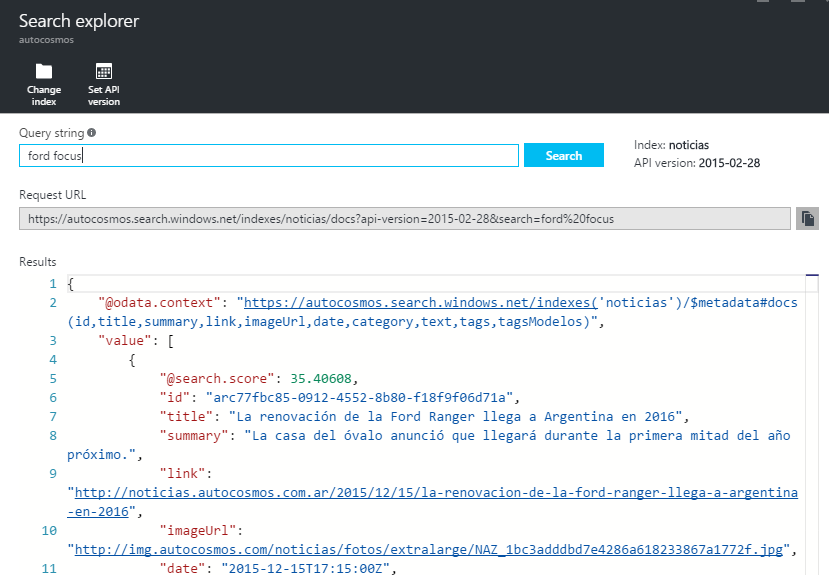
Queries are done using the Simple Query syntax (we’ll view it in more detail later on), we issue a Search Text and Azure Search calculates the score of each document, results are then returned to us on a Score-descending order. Score customization will be explained in the next section.
Results will contain the fields marked as Retrievable in a Json format along with the calculated Score.
Scoring
We talked about indexes and how searches are, by default, treated with the TF-IDF algorithm to calculate the result score on Searchable fields.
What if we don't want the default behavior? What if our documents have attributes that are more relevant than others, or if we want to provide our users with geo-spatial support?
Luckily, we can do this with Custom Scoring Profiles. A Scoring Profile is defined by:
- A Name (following Naming Rules).
- A group of one or more Searchable Fields and a Weight for each of them. The Weight is just a relative value of relevance among the selected fields. For example, in a document that represents a news article with a Title, Summary and Body, I could assign a Weight of 1 to the Body, a Weight of 2 to the Summary (because it's twice as important) and a Weight of 3.5 to the Title (Weights can have decimals).
- Optionally, Scoring Functions that will alter the result of the document score for certain scenarios.Available scoring functions are:
- "freshness": For boosting documents that are older or newer (on a Edm.DataTimeOffset field). For example, raising the score of the current month's news above the rest.
- "magnitude": For boosting documents based on numeric field (Edm.Int32, Edm.Int64 and Edm.Double) values. Mostly used to boost items given their price (cheaper higher) or count of downloads, but can be applied to any custom logic you can think of.
- "distance": For boosting documents based on their location (Edm.GeographyPoint fields). The most common scenario is the "Show the results closer to me" feature on search apps.
- "tag": Used for Tag Boosting scenarios. If we know our users, we can "tag" them with (for example) the product categories they like more, and when they search, we can boost the results that match those categories, providing a personalized result list for each user.
Custom Scoring Profiles can be created through the API or on the Portal.
Content Indexers
What good is searching if you don't have content? Adding or updating documents is almost as important as finding them, that's why Azure Search provides several methods for importing our data to our indexes.
The most straightforward method is using the Document API, directly as a REST service or using the Azure Search SDK. There are plenty of examples around, including geo-spatial support.
But using the API means that the logic of when, or which documents are added and maintained on the index relies on our code, we decide when to add, when to update and when to remove, we may need this "freedom" because our business logic or our storage may need so.
Another option, more dynamic and faster is to use Indexers. An Indexer is a process that describes how the data flows from your data source into a target search index; a search index can have several Indexers (from different data sources) but an Indexer can have only one associated index.
Supported data sources right now are:
- DocumentDB: You can sync your index with a DocumentDB collection and even customize the queries used to feed the Indexer.
- SQL Server: Indexing content that exists on Azure SQL databases, on other cloud providers, even on-premises databases, can be achieved by creating an Indexer for SQL, that can map a query on a table or a view.
- Blob Storage: Azure Search can index your blobs (HTML, MS Office formats, PDF, XML, ZIP, JSON and plain text) in Azure Storage by mapping blob metadata to index fields and the file contents as a single field.
Indexers can be created using the API or using the Portal. They can be run once or assigned a schedule and they can track changes based on SQL Integrated Change Tracking or a High Watermark Policy (an internal mark that tracks last updated timestamps).
Suggestions
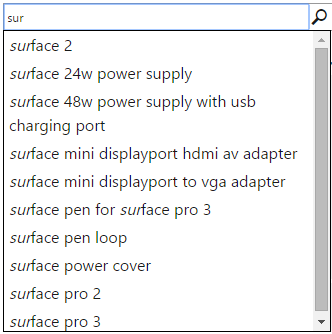
There cannot be a complete search experience without some sort of auto-complete functionality which offers the user possible search terms based on what he or she already typed. With Azure Search you can create your own Suggesters, you will be able to define which fields feed the Suggester based on the fields' values and then consume the Suggester to provide possible search terms to the user via the API.
The fields used by the Suggester can only be of types Edm.String and Collection(Edm.String) and using Default Analyzers. It is advised that these fields should have low cardinality to provide the best performance, but we'll talk about performance shortly.
Azure Search Suggesters support Fuzzy Search too, keep in mind that performance-wise, they are slower because of the extra fuzzy analysis.
The creation of the Suggester can be achieved through the API or through the Portal. Keep in mind that you can only have one per index and you cannot edit it afterwards.
There are full examples available, including one that implements Type-Ahead client functionality.
Advanced querying
Recently, Lucene query syntax support has been announced on Azure Search based on Apache's definition.
Some of you might think, what's the difference between using Azure Search's queries (let's call it Simple query syntax) by default and Lucene syntax? If the latter is more complete, why wouldn't I use it by default?
Azure Search Simple query syntax (based on Lucene's Simple Query Parser) is enough for almost all scenarios, it will match documents containing any or all of the search terms, including any variations found during analysis of the text and calculate the score based on the TF-IDF algorithm (Custom Scoring Profiles help to customize the fields and score result). The internal Lucene queries used are optimized to provide the best possible performance.
Lucene query syntax gives you a more granular and powerful control of the query. It's mostly used for these key scenarios:
- Fuzzy search: By adding the tilde "~" after search terms, you can instruct Azure Search to ponder variations of the word or misspellings.
- Proximity Search: By using the tilde "~" plus a number, you can specify what's the word-distance between two search terms. For example, "hotel airport"~5 will find documents that have both words with a maximum of 5 words in between.
- Term boosting: By adding a caret "^" to a search term followed by a number (any positive number including decimal values), we can boost the score of the documents that contain that term in particular. For example, searching for "lucene^2 search" will give increased score for those documents that contain "lucene" along with "search" higher than those that only contain "search". This is different from Scoring Profiles, since Term Boosting points to search terms and Scoring Profiles apply to index fields. By default, any term has a Boosting of 1, using less-than-one values (like 0.2) will effectively decrease the score of that term.
- Regular expressions: Regular expression syntax can be used just by applying the expression between forward slashes "/". Valid expressions can be found on the RegExp class.
As you can see, using Lucene query syntax gives you more flexibility and power in creating your queries but, "a great power comes with a great responsibility", your queries are as optimized as you make them.
Analytics
After creating our service and consuming it for some time, we may be wondering: Can I see how frequently is the service being used? What are the most common queries? Am I reaching my service throughput quota?
The answer is yes. You can enable Traffic Analytics for your Azure Search Service. You just need an Azure Storage Account where your analytics log can be stored on.
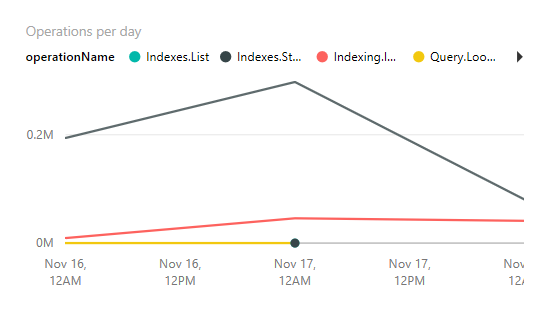
Once the data starts flowing, you can use tools like PowerBI Desktop to obtain a more graphical and comprehensive information about the service.
Not only can you see how often is your service used and it's latency, but you can even find out how often are you hitting HTTP Status 503, which means that you are above your service quota.
Performance guidelines and tips
Even on a service as optimized as Azure Search there's room for good practices and correct use scenarios.
Following Pablo Castro's excellent presentation on AzureCon I'll humbly highlight some of the most common questions and doubts regarding the performance of the service.
Let's start with some common points:
- When you create an index, only mark fields as Searchable, Facetable or filterable if they really need to be. This increases the indexing time and the storage usage of your service.
- Enable Suggesters only if you are going to use them, they will impact on indexing times.
- If your data is in Azure SQL, DocumentDB or Azure Storage Blobs, use Indexers, they have optimized queries to obtain and process the data.
- Facetable fields work best for low density values. High cardinality will slow down your queries so it's best to plan ahead.
- Low selective queries are obviously, slower, since the engine will have to ponder all the indexed documents if we don't apply any kind of Filters. Make queries as explicit and selective as possible.
Keep in mind that all service tiers (especially the Free tier) have usage limitations. To overcome these limitations we can scale our service for more storage (increasing Partitions) and/or for more throughput and parallelism (increasing Replicas).
For High-availability, it is recommended to use two Replicas for read-only queries and three Replicas for read-write workloads.
To understand how many replicas we really need, it's crucial to know what's the Latency we expect from the service according to our own product or service. The best way of defining the Replicas is to test our service with a normal workload and track what's the current Latency. If we need a lower Latency, we can increase the Replicas and repeat the testing operation.
Conclusion
Hopefully this guide will help you find your answers as quickly as Azure Search provides results, well, maybe a little bit slower, but it will save you enough time so you can focus on building your best search application and get it running quickly enough.
Remember that you can try Azure Search for FREE, you don’t need to spend any money to make your proofs of concept or tests.

About the author
Microsoft MVP, Azure & Web Engineer, open source contributor and firm believer in the freedom of knowledge.