Case-insensitive Search Operations
Many applications have a functional requirement for the underlying database to have a case-sensitive sort-order, implying that all character data related operations are case-sensitive. With SQL Server, such databases are created with either the ‘binary’ or any of the case-sensitive (CS) sort orders (collations). Often times these applications also need to perform case-insensitive searches for character data. This can be challenging and, if not implemented correctly, lead to sub-optimal performance, given that the database was created to be case-sensitive. Let’s take a look at this using a simple example.
Assume you have a sample database ‘TestDB’ created with the Latin1_General_CS_AS collation. This database has a table ‘Customer’ inserted with a few hundred rows of data values and having the indexes shown below:
CREATE TABLE Customer
(
Id INT,
FirstName VARCHAR(32),
LastName VARCHAR (32)
)
GO
INSERT Customer VALUES (1, 'MaryAnne', 'McNight')
INSERT Customer VALUES (2, 'McCarthy', 'Mendosa')
INSERT Customer VALUES (3, 'Burzin', 'Patel')
INSERT Customer VALUES (4, 'Jill', 'Jumper')
INSERT Customer VALUES (5, 'Douglas', 'adams') ...
...
...
GO
CREATE ClUSTERED INDEX idx1 ON Customer(Id)
GO
CREATE INDEX idx2 ON Customer (FirstName)
GO
Now let’s say there’s a need for an application to perform a case insensitive search on the FirstName column. This can easily be done using the T-SQL statement below.
SELECT Id, FirstName, LastName FROM Customer
WHERE UPPER (FirstName) = 'BURZIN'
GO
While functionally correct, this query is not optimal because the database engine has to read every row value of FirstName, convert it to upper-case, and then compare it to the literal value ‘BURZIN’ This results in an index scan operation on the table as shown in the query plan below.
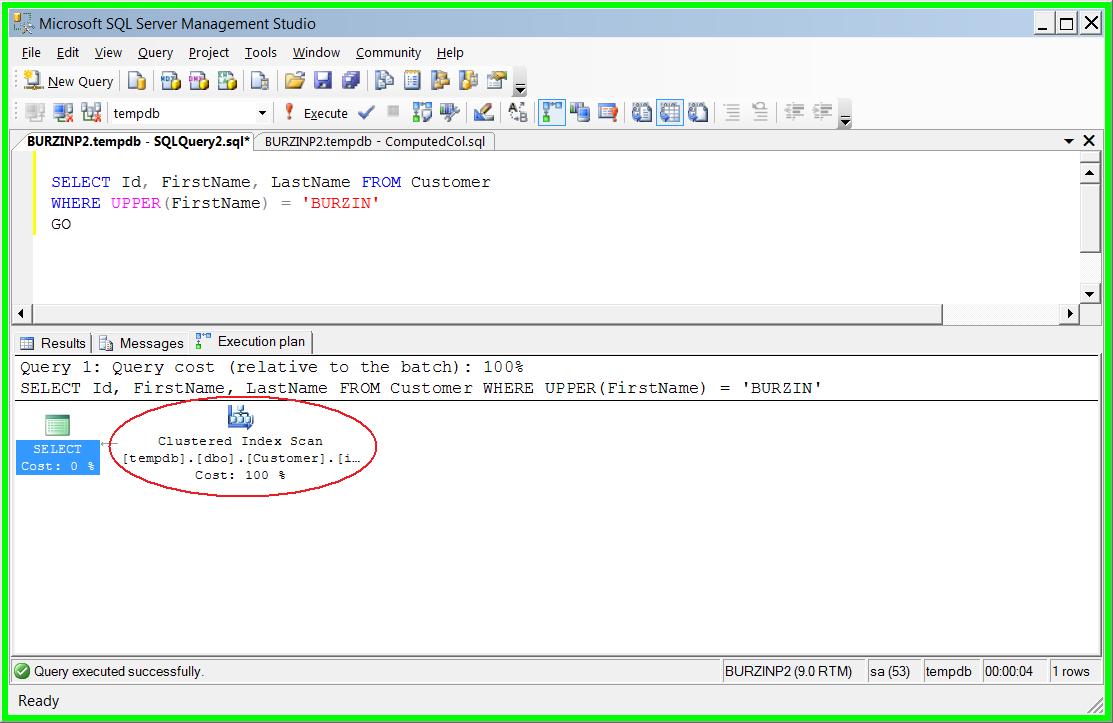
Moreover the performance of this query is almost linearly dependent on the number of rows in the ‘Customer’ table, implying that when the size of the table grows the perforamnce declines because more rows need to be read to locate the qualifying row. This is not good for the performance and scalabilty of the solution and in certain cases can also result in blocking issues.
Ideally the query would have used the existing non-clustered index (idx2) and performed an index seek operation instead of the index scan. SQL Server 2005 offers a solution to this problem requiring a relatively minor change to the table schema and index but no change required to the query itself. In SQL Server 2005 you can resolve this by creating a computed column using thee UPPER function and the corresponding clusutered index on the newly created columns as shown below.
CREATE TABLE Customer
(
Id INT,
FirstName VARCHAR (32),
LastName VARCHAR (32),
UPPERFirstName AS UPPER (FirstName)
)
GO
CREATE ClUSTERED INDEX idx1 ON Customer(Id)
GO
CREATE INDEX idx2 ON Customer (UPPERFirstName)
GO
As you may know, computed columns are automatically maintained by the SQL Server database engine and do not require any explicit user actions when performing inserts, updates or deletes. This means that none of the core application functionality needs to be changed to accommodate the new column.
NOTE: additional information about computed columns, including the SET options required, can be found in the SQL Server Books Online (ms- help://MS.SQLCC.v9/MS.SQLSVR.v9.en/udb9/html/f1a29423-7fe9-454c-b9d9- 5afeea6e3fb4.htm and ms- help://MS.SQLCC.v9/MS.SQLSVR.v9.en/tsqlref9/html/d2297805-412b-47b5-aeeb- 53388349a5b9.htm).
Now when the original query is rerun, the SQL Server 2005 database engine automatically determines that the table has a computed column with the same exact function as the query and an index on that column. Using this information it automatically choses to use the index on the computed column to perform a seek operation as shown in the query plan below.
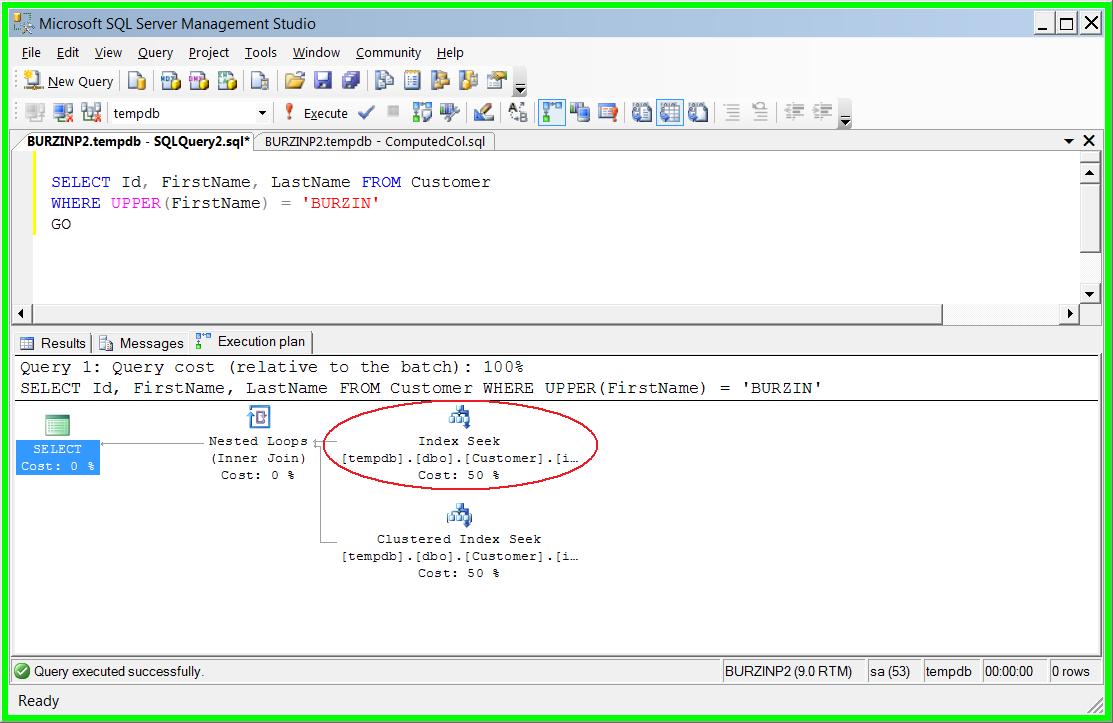
NOTE: In order to balance the cost vs. benefits of optimizing a query, the SQL Server optimizer does not extensively optimize trivial queries operating against small tables. Because of this, the index on the computed column as shown above is only selected for use when the ‘Customer’ table has more than 140 rows.
As can be seen, there is some overhead associated with creating and maintaining the additional (computed) column, however in my experience the benefits of having this solution far outweigh the cost and therefore justify its use.
While this example presents a solution for a case insensitive search using the UPPER function, the solution can be easily be extended for use with other functions as well.
Comments
- Anonymous
June 01, 2009
PingBack from http://paidsurveyshub.info/story.php?id=74110