Best Practice: Get your HEAD in order
To ensure optimal performance and reliability when rendering pages, you should order the elements within the HEAD element carefully. First, I’ll explain the optimal order, and then explain the reasoning for this structure.
Optimal Head Ordering
<doctype>
<html>
<head>
<meta http-equiv content-type charset><meta http-equiv x-ua-compatible> <base>
<title, favicon, comments, script blocks, etc>
Why Order Matters
In order to understand why the ordering of the elements in the HEAD matters, it’s important to understand how the browser parses webpages, and what impact each element has on the parsing of the page.
When the browser begins parsing a page, it begins reading the bytes of the HTTP response body. If the response’s Content-Type header specifies a charset attribute, those body bytes can immediately be interpreted as text using the specified character encoding. However, if a charset declaration is not present, the browser must begin scanning the bytes of the response body, checking for a Unicode Byte-Order-Marker at the top or scanning for a META HTTP-EQUIV element that specifies the charset. When such a declaration is reached, the parser may need to restart in order to ensure that the bytes previously read were interpreted properly. When a restart occurs, the F12 Developer Tools will show the following note in the console:

This restart can impact performance, as we’ll discuss momentarily.
If a character set declaration is not found, the browser is forced to “Autodetect” the content-encoding based on the nature of the bytes read or other factors, potentially resulting in a mismatch between the web developer’s intent and the browser’s guess. That mismatch can result in a broken page, or a page which contains gibberish in some places. Therefore, for functionality and performance reasons, it is a best-practice to specify the encoding[1] using HTTP response headers. If you must specify the character set using a META tag for some reason, it is critical that the META tag is the first element in the HEAD.
Internet Explorer 8 and later versions allow page authors to specify which document mode should be used for the rendering of the page, in order to enable a site to suggest that later versions of IE should render a given page in a legacy mode for compatibility reasons. Because the document mode can impact how the browser parses a page, Internet Explorer will need to restart the parsing process if a META element is found that specifies an X-UA-Compatible value different than was originally used to start parsing. The F12 Developer tools will note when a restart was needed:

For that reason, it is a best-practice to specify any X-UA-Compatible value as a HTTP response header. If you must specify the X-UA-Compatible value using a META tag for some reason, this element MUST appear before any script blocks and SHOULD appear as early in the HEAD element as possible. In some cases, a specified X-UA-Compatible META tag can be ignored (e.g. because the document mode was already finalized due to earlier markup[2]). When this happens, the F12 Developer Tools’ console will show the following message:

The BASE element controls how any relative URLs in your page are made absolute in order to retrieve the specified resources from the network. Ordinarily, a relative URL is combined with the URL of a page in order to make it absolute. However, when a BASE tag is present, the specified HREF is used for URL-combination, and the page’s URL is not used. Because the BASE element impacts the combination of all relative URLs in a page, it MUST appear before any relative URLs in your page. As of IE7, the BASE element MUST appear within the HEAD element and will be ignored if it appears in the body. While it is technically possible to use JavaScript (e.g. via document.write) to specify a BASE element, doing so is strongly discouraged.
After you’ve specified any of the charset, X-UA-Compatible, and BASE declarations you need, finish out your HEAD tag with a TITLE element and any other markup.
Understanding the Lookahead Pre-parser
To reduce the delay inherent in downloading script, stylesheets, images, and other resources referenced in an HTML page, Internet Explorer needs to request the download of those resources as early as possible in the loading of the page. The key problem is that the browser’s parser must pause when it encounters a non-async/non-defer script element, in order to run the script in order, as required by the standards. In the absence of mitigations, this pause would result in a significant delay in the parsing of the rest of the page, and thus result in resources being requested from the network much later.
To mitigate this issue when loading a page, Internet Explorer runs a second instance of a parser whose job is to hunt for resources to download while the main parser is paused. This mode is called the lookahead pre-parser[3] because it looks ahead of the main parser for resources referenced in later markup. The download requests triggered by the lookahead are called “speculative” because it is possible (not likely, but possible) that the script run by the main parser will change the meaning of the subsequent markup (for instance, it might adjust the BASE against which relative URLs are combined) and result in the speculative request being wasted.
Critically, when the parser is forced to incur a document mode or charset restart, IE aborts all of that page’s in-flight requests and begins parsing of the page anew, again looking for resources to speculatively download. Beyond the CPU cost of these restarts, there can be a network cost as well.
For instance, consider a page that restarts from IE9 Standards mode to Quirks Mode. The F12 console shows the restart:

…and you can see the aborted speculative requests listed in the Network tab of the F12 Developer Tools:

Because the restart occurs very early on in page load, only the first speculative request actually made it through URLMon and WinINET and was requested from the network.
In Fiddler, you can see the aborted request for /1.js. The Reason column shows that the first request was from the original html lookahead tokenizer while the subsequent (successful) downloads were triggered by the restarted html lookahead tokenizer:
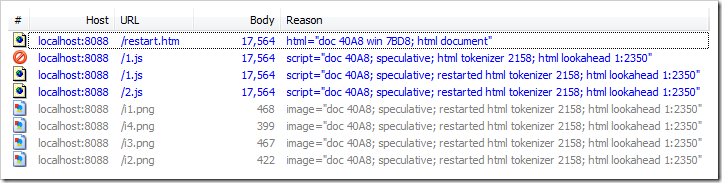
Because the browser aborted the first request for the script file, it didn’t read the entire response from the network; instead it issued a TCP RST on the request’s connection, immediately closing it. When the restarted lookahead identified the same resource to download, it required the establishment of a new TCP/IP connection.
For best performance, specify your page’s character set and X-UA-Compatible (if desired) using HTTP response headers, helping the browser avoid expensive restarts.
-Eric
[1] In case you’re wondering, UTF-8 encoding is the best choice. For web content, UTF-8 is almost always more efficient than UTF-16, and there are some peculiarities with UTF-16 support that make it inadvisable for use in web content.
[2] Internet Explorer 10 PPB2 introduced a new architecture where a versioning pre-scan occurs before the parsers begin their work; the X-UA-Compatible META tag must appear in the first 4kb of the markup or it will be ignored.
[3] Regular readers may recall that I’ve written about Internet Explorer’s Lookahead downloading feature previously.
Comments
Anonymous
July 18, 2011
The comment has been removedAnonymous
July 18, 2011
The comment has been removedAnonymous
July 18, 2011
@EricLaw: See html5.org/.../web-apps-tracker. github.com/.../69 may also be of interest, along with mathiasbynens.be/.../base.Anonymous
July 18, 2011
The comment has been removedAnonymous
July 18, 2011
The comment has been removedAnonymous
July 19, 2011
> particularly when its failure to do so could result in a security vulnerability. Could you file a bug on the spec, or email public-html with some details? Obviously the spec shouldn't mandate insecure behaviour.Anonymous
July 19, 2011
Yeah, please do report the security problem. You can mail me directly if you'd rather not make it public: ian@hixie.chAnonymous
July 19, 2011
The comment has been removedAnonymous
July 21, 2011
The comment has been removedAnonymous
July 21, 2011
The comment has been removedAnonymous
July 21, 2011
Eric, is CHARSET needed in the HTTP Response headers of JS and CSS files? Will the browser do the same thing like looking for the meta tag information in the response body? The reason I am asking is that JS & CSS will not have meta tag in the response body so it is no use scanning through looking for charset.Anonymous
July 21, 2011
@Senthil: Correct, setting the charset in the HTTP Response headers is a best-practice for JS and CSS files. You're right to note that JavaScript files don't have a way to specify their character set internally to the script content itself. You may be surprised to learn that CSS files actually do have such a method, using the @charset declaration.Anonymous
July 25, 2011
Thanks Eric. I am trying to reach out to our Edge Caching Service folks to include "charset: utf-8" in the HTTP headers for JS & CSS static resources. Do you have any rough performance measurements (like millisecond improvements) of including charset in headers?Anonymous
July 25, 2011
@Senthil: I don't have any hard numbers, but I'd expect the improvement to be under a millisecond. The primary advantage in specifying charset for CSS/JS is to ensure proper functionality (e.g. that they aren't misinterpreted as being in a different charset). I believe we've seen some cases where charset misinterpretation in such files could be abused by an attacker.Anonymous
August 05, 2011
@Eric you might want to the Expression Web Developer team to remove the the Content-Type meta tag from the default template. It is there when you create a new HTML file, at least on Web Dev 3.0!Anonymous
August 06, 2011
@George: There's nothing inherently wrong with including a Content-Type META containing a CharSet, so long as it merely reiterates the charset specified in the Content-Type in the HTTP response headers. The fact that they're currently using "windows-1252" as the default character set here is sub-optimal. I'll ask them about that. Thanks!Anonymous
August 08, 2011
@George: The Expression team notes that UTF-8 is the default for new web pages in new web sites. If you open an existing site, it may have a Default Page Encoding set. Check the option in Site | Site Settings...Anonymous
August 19, 2011
WebKit has issues with BASE injection: bugs.webkit.org/show_bug.cgiAnonymous
February 02, 2013
The reason HTML5 decided to change the BASE element handling: lists.w3.org/.../0062.html