자습서: 자동화된 Machine Learning을 사용하여 Python에서 모델 학습(사용되지 않음)
Azure Machine Learning은 기계 학습 모델을 학습, 배포, 자동화, 관리 및 추적할 수 있는 클라우드 기반 환경입니다.
이 자습서에서는 Azure Machine Learning의 자동화된 Machine Learning을 사용하여 택시 요금 가격을 예측하는 회귀 모델을 만듭니다. 이 프로세스는 학습 데이터 및 구성 설정을 수락하고 다양한 방법, 모델 및 하이퍼 매개 변수 설정을 조합하여 자동으로 반복함으로써 최상의 모델에 도달합니다.
이 자습서에서는 다음을 하는 방법을 알아볼 수 있습니다.
- Apache Spark 및 Azure Open Datasets를 사용하여 데이터를 다운로드합니다.
- Apache Spark DataFrames를 사용하여 데이터를 변환하고 정리합니다.
- 자동화된 기계 확습에서 회귀 모델을 학습합니다.
- 모델 정확도를 계산합니다.
시작하기 전에
- 서버리스 Apache Spark 2.4 풀 만들기 빠른 시작에 따라 서버리스 Apache Spark 풀을 만듭니다.
- 기존 Azure Machine Learning 작업 영역이 없는 경우 Azure Machine Learning 작업 영역 설정 자습서를 완료합니다.
Warning
- 2023년 9월 29일부터 Azure Synapse는 Spark 2.4 런타임에 대한 공식 지원을 중단합니다. 2023년 9월 29일 이후 Spark 2.4와 관련된 지원 티켓은 다루지 않습니다. Spark 2.4에 대한 버그 또는 보안 수정을 위한 릴리스 파이프라인은 없습니다. Spark 2.4를 활용하면 지원 중단 날짜가 자체 위험으로 수행됩니다. 잠재적인 보안 및 기능 문제로 인해 지속적인 사용을 강력히 권장하지 않습니다.
- Apache Spark 2.4에 대한 사용 중단 프로세스의 일환으로 Azure Synapse Analytics의 AutoML도 더 이상 사용되지 않음을 알려 드립니다. 여기에는 코드를 통해 AutoML 평가판을 만드는 데 사용되는 낮은 코드 인터페이스와 API가 모두 포함됩니다.
- AutoML 기능은 Spark 2.4 런타임을 통해서만 사용할 수 있습니다.
- AutoML 기능을 계속 활용하려는 고객의 경우 데이터를 ADLSg2(Azure Data Lake Storage Gen2) 계정에 저장하는 것이 좋습니다. 여기에서 AzureML(Azure Machine Learning)을 통해 AutoML 환경에 원활하게 액세스할 수 있습니다. 이 해결 방법에 대한 자세한 내용은 여기에서 사용할 수 있습니다.
회귀 모델 이해
회귀 모델은 독립 예측 변수를 기반으로 하여 숫자 출력 값을 예측합니다. 회귀 분석은 한 변수가 다른 변수에 미치는 영향을 추정하여 이러한 독립 예측 변수 간의 관계를 설정하는 데 도움을 주기 위한 것입니다.
뉴욕시 택시 데이터를 기반으로 하는 예제
이 예제에서는 Spark를 사용하여 NYC(뉴욕시)의 택시 주행 팁 데이터에 대한 일부 분석을 수행합니다. 데이터는 Azure 공개 데이터 세트를 통해 사용할 수 있습니다. 데이터 세트의 이 하위 집합에는 각 주행, 시작/종료 시간, 위치 및 비용을 포함하여 노랑 택시 주행에 대한 정보가 포함되어 있습니다.
Important
스토리지 위치에서 이 데이터를 끌어오는 데 추가 요금이 있을 수 있습니다. 다음 단계에서는 NYC 택시 요금 가격을 예측하는 모델을 개발합니다.
데이터 다운로드 및 준비
이 경우 가능한 방법은 다음과 같습니다.
PySpark 커널을 사용하여 Notebook을 만듭니다. 자세한 지침은 Notebook 만들기를 참조하세요.
참고 항목
PySpark 커널로 인해 컨텍스트를 명시적으로 만들 필요가 없습니다. 첫 번째 코드 셀을 실행하면 Spark 컨텍스트가 자동으로 만들어집니다.
원시 데이터는 Parquet 형식이므로 Spark 컨텍스트를 사용하여 파일을 DataFrame으로 메모리에 직접 끌어올 수 있습니다. Open Datasets API를 통해 데이터를 검색하여 Spark DataFrame을 만듭니다. 여기서는 Spark DataFrame
schema on read속성을 사용하여 데이터 형식 및 스키마를 유추합니다.blob_account_name = "azureopendatastorage" blob_container_name = "nyctlc" blob_relative_path = "yellow" blob_sas_token = r"" # Allow Spark to read from the blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name),blob_sas_token) # Spark read parquet; note that it won't load any data yet df = spark.read.parquet(wasbs_path)Spark 풀의 크기에 따라 원시 데이터가 너무 크거나 작업하는 데 너무 많은 시간이 걸릴 수 있습니다.
start_date및end_date필터를 사용하여 이 데이터를 한 달 분량의 데이터처럼 더 작은 데이터로 필터링할 수 있습니다. DataFrame을 필터링한 후 새 DataFrame에서describe()함수를 실행하여 각 필드에 대한 요약 통계도 확인합니다.요약 통계를 기반으로 하여 데이터에 몇 가지 불규칙성이 있음을 알 수 있습니다. 예를 들어 통계에 따르면 최소 주행 거리가 0보다 작습니다. 이러한 불규칙한 데이터 요소를 필터링해야 합니다.
# Create an ingestion filter start_date = '2015-01-01 00:00:00' end_date = '2015-12-31 00:00:00' filtered_df = df.filter('tpepPickupDateTime > "' + start_date + '" and tpepPickupDateTime< "' + end_date + '"') filtered_df.describe().show()열 세트를 선택하고 픽업
datetime필드에서 다양한 시간 기반 기능을 만들어 데이터 세트에서 기능을 생성합니다. 이전 단계에서 식별된 이상값은 학습하는 데 필요하지 않으므로 이러한 값을 필터링한 다음, 마지막 몇 개의 열을 제거합니다.from datetime import datetime from pyspark.sql.functions import * # To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) taxi_df = sampled_taxi_df.select('vendorID', 'passengerCount', 'tripDistance', 'startLon', 'startLat', 'endLon' \ , 'endLat', 'paymentType', 'fareAmount', 'tipAmount'\ , column('puMonth').alias('month_num') \ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , date_format('tpepPickupDateTime', 'EEEE').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month') ,(unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('trip_time'))\ .filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\ & (sampled_taxi_df.tipAmount >= 0)\ & (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\ & (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\ & (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 200)\ & (sampled_taxi_df.rateCodeId <= 5)\ & (sampled_taxi_df.paymentType.isin({"1", "2"}))) taxi_df.show(10)여기서 볼 수 있듯이 월의 날짜, 픽업 시간, 평일 및 총 이동 시간에 대한 추가 열이 포함된 새 DataFrame이 생성됩니다.

테스트 및 유효성 검사 데이터 세트 생성
최종 데이터 세트가 있으면 Spark에서 random_ split 함수를 사용하여 데이터를 학습 세트 및 테스트 세트로 분할할 수 있습니다. 이 함수는 제공된 가중치를 사용하여 모델 학습을 위한 학습 데이터 세트 및 테스트를 위한 유효성 검사 데이터 세트로 데이터를 임의로 분할합니다.
# Random split dataset using Spark; convert Spark to pandas
training_data, validation_data = taxi_df.randomSplit([0.8,0.2], 223)
이 단계에서는 완성된 모델을 테스트하기 위한 데이터 요소가 모델을 학습시키는 데 사용되지 않도록 합니다.
Azure Machine Learning 작업 영역에 연결
Azure Machine Learning에서 작업 영역은 Azure 구독 및 리소스 정보를 수락하는 클래스입니다. 또한 클라우드 리소스를 만들어서 모델 실행을 모니터링하고 추적합니다. 이 단계에서는 기존 Azure Machine Learning 작업 영역에서 작업 영역 개체를 만듭니다.
from azureml.core import Workspace
# Enter your subscription id, resource group, and workspace name.
subscription_id = "<enter your subscription ID>" #you should be owner or contributor
resource_group = "<enter your resource group>" #you should be owner or contributor
workspace_name = "<enter your workspace name>" #your workspace name
ws = Workspace(workspace_name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group)
DataFrame을 Azure Machine Learning 데이터 세트로 변환
원격 실험을 제출하려면 데이터 세트를 Azure Machine Learning TabularDatset 인스턴스로 변환합니다. TabularDataset는 제공된 파일을 구문 분석하여 데이터를 테이블 형식으로 나타냅니다.
다음 코드는 기존 작업 영역과 기본 Azure Machine Learning 데이터 저장소를 가져옵니다. 그런 다음, 데이터 저장소 및 파일 위치를 경로 매개 변수에 전달하여 새 TabularDataset 인스턴스를 만듭니다.
import pandas
from azureml.core import Dataset
# Get the Azure Machine Learning default datastore
datastore = ws.get_default_datastore()
training_pd = training_data.toPandas().to_csv('training_pd.csv', index=False)
# Convert into an Azure Machine Learning tabular dataset
datastore.upload_files(files = ['training_pd.csv'],
target_path = 'train-dataset/tabular/',
overwrite = True,
show_progress = True)
dataset_training = Dataset.Tabular.from_delimited_files(path = [(datastore, 'train-dataset/tabular/training_pd.csv')])

자동화된 실험 제출
다음 섹션에서는 자동화된 Machine Learning 실험을 제출하는 과정을 안내합니다.
학습 설정 정의
실험을 제출하려면 학습에 대한 실험 매개 변수와 모델 설정을 정의해야 합니다. 전체 설정 목록은 Python에서 자동화된 Machine Learning 실험 구성을 참조하세요.
import logging automl_settings = { "iteration_timeout_minutes": 10, "experiment_timeout_minutes": 30, "enable_early_stopping": True, "primary_metric": 'r2_score', "featurization": 'auto', "verbosity": logging.INFO, "n_cross_validations": 2}정의된 학습 설정을
kwargs매개 변수로AutoMLConfig개체에 전달합니다. Spark를 사용하고 있으므로sc변수에서 자동으로 액세스할 수 있는 Spark 컨텍스트도 전달해야 합니다. 또한 학습 데이터와 모델 유형(이 경우 회귀)을 지정합니다.from azureml.train.automl import AutoMLConfig automl_config = AutoMLConfig(task='regression', debug_log='automated_ml_errors.log', training_data = dataset_training, spark_context = sc, model_explainability = False, label_column_name ="fareAmount",**automl_settings)
참고 항목
자동화된 Machine Learning 전처리 단계는 기본 모델의 일부가 됩니다. 이러한 단계에는 기능 정규화, 누락된 데이터 처리 및 텍스트에서 숫자로의 변환이 포함됩니다. 모델을 예측에 사용하는 경우 학습 중에 적용되는 동일한 전처리 단계가 입력 데이터에 자동으로 적용됩니다.
자동 회귀 모델 학습
다음으로, Azure Machine Learning 작업 영역에서 실험 개체를 만듭니다. 실험은 개별 실행에 대한 컨테이너 역할을 합니다.
from azureml.core.experiment import Experiment
# Start an experiment in Azure Machine Learning
experiment = Experiment(ws, "aml-synapse-regression")
tags = {"Synapse": "regression"}
local_run = experiment.submit(automl_config, show_output=True, tags = tags)
# Use the get_details function to retrieve the detailed output for the run.
run_details = local_run.get_details()
실험이 완료되면 출력에서 완료된 반복에 대한 세부 정보를 반환합니다. 각 반복의 경우 모델 유형, 실행 지속 및 학습 정확도가 표시됩니다. BEST 필드는 메트릭 유형에 따라 최적의 실행 학습 점수를 추적합니다.

참고 항목
자동화된 Machine Learning 실험이 제출되면 다양한 반복 및 모델 유형을 실행합니다. 이 실행에는 일반적으로 60~90분이 걸립니다.
최적 모델 검색
반복에서 최상의 모델을 선택하려면 get_output 함수를 사용하여 최상의 실행 및 적합 모델을 반환합니다. 다음 코드에서는 기록된 메트릭 또는 특정 반복에 대한 최상의 실행 및 적합 모델을 검색합니다.
# Get best model
best_run, fitted_model = local_run.get_output()
모델 정확도 테스트
모델 정확도를 테스트하려면 테스트 데이터 세트에서 택시 요금 예측을 실행하는 최상의 모델을 사용합니다.
predict함수는 최적의 모델을 사용하고 유효성 검사 데이터 세트에서y값(운임 금액)을 예측합니다.# Test best model accuracy validation_data_pd = validation_data.toPandas() y_test = validation_data_pd.pop("fareAmount").to_frame() y_predict = fitted_model.predict(validation_data_pd)제곱 평균 오차는 모델에서 예측한 샘플 값과 관찰 값 간의 차이를 측정하는 데 자주 사용됩니다.
y_testDataFrame을 모델에서 예측한 값과 비교하여 결과의 제곱 평균 오차를 계산합니다.mean_squared_error함수는 두 개의 배열을 가져와서 두 배열 간의 평균 제곱 오차를 계산합니다. 그런 다음, 결과의 제곱근을 가져옵니다. 이 메트릭은 택시 요금 예측과 실제 요금 값의 차이를 대략적으로 나타냅니다.from sklearn.metrics import mean_squared_error from math import sqrt # Calculate root-mean-square error y_actual = y_test.values.flatten().tolist() rmse = sqrt(mean_squared_error(y_actual, y_predict)) print("Root Mean Square Error:") print(rmse)Root Mean Square Error: 2.309997102577151제곱 평균 오차는 모델에서 예측하는 응답에 대한 정확도를 보여주는 좋은 척도입니다. 결과에 따르면 모델이 데이터 세트의 기능에서 택시 요금(일반적으로 $2.00 이내)을 예측하는 데 매우 적합하다는 것을 알 수 있습니다.
다음 코드를 실행하여 절대 백분율 평균 오차를 계산합니다. 이 메트릭은 정확도를 오류에 대한 백분율로 나타냅니다. 이 작업은 각 예측 값과 실제 값 간의 절대 차이를 계산한 다음, 모든 차이의 합계를 계산하여 수행됩니다. 그런 다음, 해당 합계를 실제 값의 합계에 대한 백분율로 나타냅니다.
# Calculate mean-absolute-percent error and model accuracy sum_actuals = sum_errors = 0 for actual_val, predict_val in zip(y_actual, y_predict): abs_error = actual_val - predict_val if abs_error < 0: abs_error = abs_error * -1 sum_errors = sum_errors + abs_error sum_actuals = sum_actuals + actual_val mean_abs_percent_error = sum_errors / sum_actuals print("Model MAPE:") print(mean_abs_percent_error) print() print("Model Accuracy:") print(1 - mean_abs_percent_error)Model MAPE: 0.03655071038487368 Model Accuracy: 0.9634492896151263두 가지 예측 정확도 메트릭에 따르면 모델이 데이터 세트의 기능에서 택시 요금을 예측하는 데 매우 적합하다는 것을 알 수 있습니다.
적합한 선형 회귀 모델이 준비되면 이제 모델이 데이터에 적합한 정도를 확인해야 합니다. 이렇게 하려면 예측 출력에 대한 실제 요금 값을 도표에 표시합니다. 또한 R 제곱 측정값을 계산하여 데이터가 적합 회귀선에 가까운 정도를 파악합니다.
import matplotlib.pyplot as plt import numpy as np from sklearn.metrics import mean_squared_error, r2_score # Calculate the R2 score by using the predicted and actual fare prices y_test_actual = y_test["fareAmount"] r2 = r2_score(y_test_actual, y_predict) # Plot the actual versus predicted fare amount values plt.style.use('ggplot') plt.figure(figsize=(10, 7)) plt.scatter(y_test_actual,y_predict) plt.plot([np.min(y_test_actual), np.max(y_test_actual)], [np.min(y_test_actual), np.max(y_test_actual)], color='lightblue') plt.xlabel("Actual Fare Amount") plt.ylabel("Predicted Fare Amount") plt.title("Actual vs Predicted Fare Amount R^2={}".format(r2)) plt.show()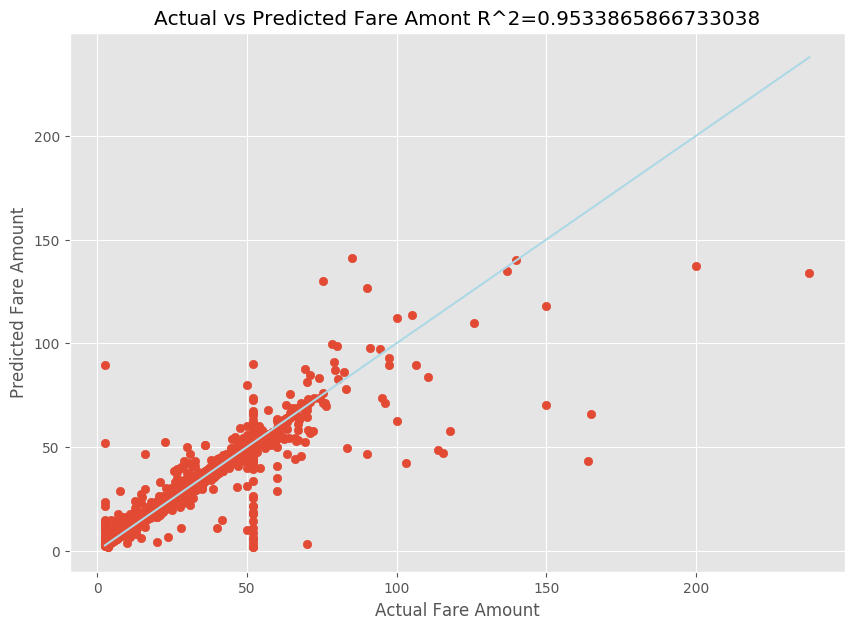
결과에 따르면 R 제곱 측정값이 분산의 95%를 차지한다는 것을 알 수 있습니다. 또한 이를 통해 실제 값 도표 및 관찰 값 도표의 유효성도 검사됩니다. 회귀 모델이 설명하는 분산이 클수록 데이터 요소가 적합 회귀선에 더 가까워집니다.
Azure Machine Learning에 모델 등록
최상의 모델에 대한 유효성이 검사되면 해당 모델을 Azure Machine Learning에 등록할 수 있습니다. 그런 다음, 등록된 모델을 다운로드하거나 배포하고, 등록한 모든 파일을 받을 수 있습니다.
description = 'My automated ML model'
model_path='outputs/model.pkl'
model = best_run.register_model(model_name = 'NYCYellowTaxiModel', model_path = model_path, description = description)
print(model.name, model.version)
NYCYellowTaxiModel 1
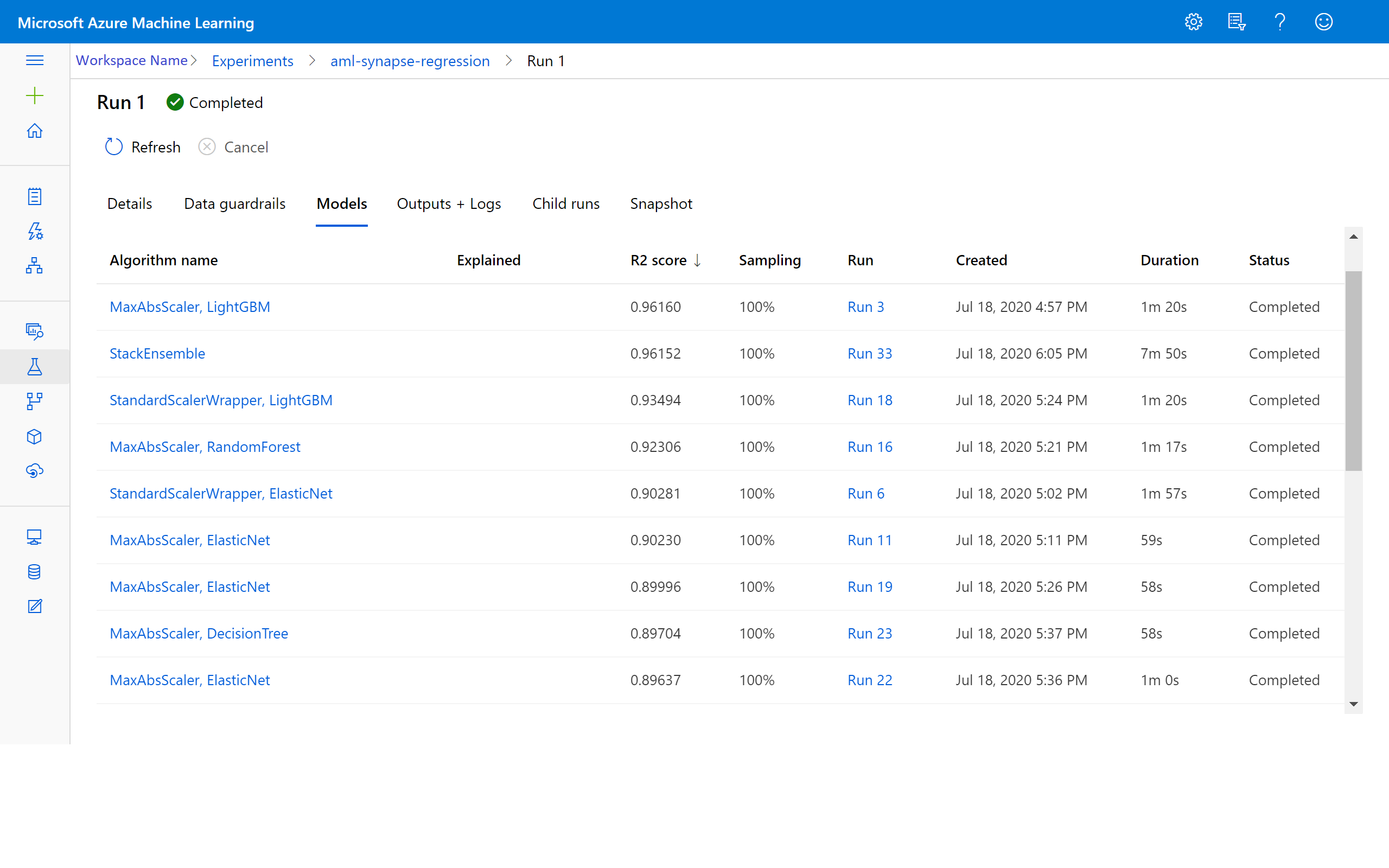
Azure Machine Learning에서 결과 보기
Azure Machine Learning 작업 영역에서 실험으로 이동하여 반복 결과에 액세스할 수도 있습니다. 여기에서 실행 상태, 시도된 모델 및 기타 모델 메트릭에 대한 추가 세부 정보를 가져올 수 있습니다.