Azure Stream Analytics 작업의 호환성 수준
이 문서에서는 Azure Stream Analytics의 호환성 수준 옵션을 설명합니다.
Stream Analytics는 정기적인 기능 업데이트와 지속적인 성능 개선을 통해 관리되는 서비스입니다. 대부분의 서비스 런타임 업데이트는 호환성 수준과 별개로 최종 사용자가 자동으로 사용할 수 있습니다. 하지만 새 기능에서 기존 작업의 동작을 변경하거나 실행 중인 작업에서 데이터를 사용하는 방식이 변경되는 경우 이 변경 내용은 새로운 호환성 수준에서 도입되었습니다. 호환성 수준 설정을 낮게 유지하여 기존 Stream Analytics 작업을 중요 변경 없이 계속 실행할 수 있습니다. 최신 런타임 동작을 수행할 준비가 되면 호환성 수준을 높여 옵트인할 수 있습니다.
호환성 수준 선택
호환성 수준은 스트림 분석 작업의 런타임 동작을 제어합니다.
Azure Stream Analytics는 현재 다음과 같은 두 가지 호환성 수준을 지원합니다.
- 1.2 - 최근 향상된 최신 동작
- 1.1 - 이전 동작
- 1.0 - 수년 전 Azure Stream Analytics의 일반 공급 때 도입된 원래 호환성 수준.
새로운 Stream Analytics 작업을 만들 때 가장 최신 호환성 수준을 사용하여 만드는 것이 좋습니다. 나중에 변경 사항 및 복잡성이 추가되지 않도록 최신 동작에 의존하는 작업 설계를 시작합니다.
호환성 수준 설정
Azure Portal에서 또는 작업 REST API 호출 만들기를 사용하여 Stream Analytics 작업의 호환성 수준을 설정할 수 있습니다.
Azure Portal에서 작업의 호환성 수준을 업데이트하려면 다음을 수행합니다.
- Azure Portal을 사용하여 Stream Analytics 작업으로 이동합니다.
- 호환성 수준을 업데이트하기 전에 작업을 중지합니다. 작업이 실행 중인 상태에서는 호환성 수준을 업데이트할 수 없습니다.
- 구성 제목에서 호환성 수준을 선택합니다.
- 원하는 호환성 수준 값을 선택합니다.
- 페이지 맨 아래에서 저장을 선택합니다.
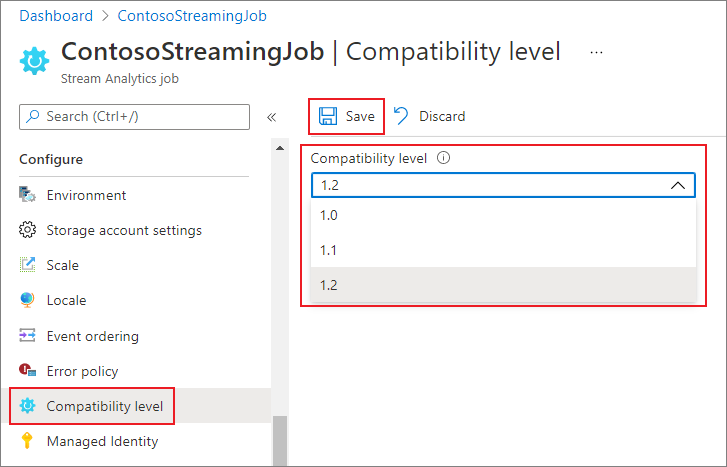
호환성 수준을 업데이트하면 T-컴파일러는 선택된 호환성 수준에 해당하는 구문을 사용하여 작업의 유효성을 검사합니다.
호환성 수준 1.2
호환성 수준 1.2에 다음과 같은 주요 변경 사항이 도입되었습니다.
AMQP 메시징 프로토콜
1.2 수준: Azure Stream Analytics는 AMQP(Advanced Message Queueing Protocol) 메시지 프로토콜을 사용하여 Service Bus Queues 및 토픽에 작성합니다. AMQP를 사용하여 여러 플랫폼 간에 개방형 표준 프로토콜을 사용하는 하이브리드 애플리케이션을 빌드할 수 있습니다.
지리 공간적 함수
이전 수준: 지리 계산을 사용한 Azure Stream Analytics.
1.2 수준: Azure Stream Analytics를 사용하면 기하학적 예상 지역 좌표를 계산할 수 있습니다. 지리 공간적 함수의 서명에는 변경 사항이 없습니다. 하지만 해당 의미 체계가 약간 다르므로 이전보다 더 정확한 계산을 수행할 수 있습니다.
Azure Stream Analytics는 지리 공간적 참조 데이터 인덱싱을 지원합니다. 더 빠른 조인 계산을 위해 지리 공간적 요소를 포함하는 참조 데이터를 인덱싱할 수 있습니다.
업데이트된 지리 공간적 함수는 WKT(Well Known Text) 지리 공간적 형식의 전체 표현을 가져옵니다. GeoJson에서 이전에 지원되지 않는 다른 지리 공간적 구성 요소를 지정할 수 있습니다.
자세한 내용은 Azure Stream Analytics – 클라우드 및 IoT Edge의 지리 공간적 기능 업데이트를 참조하세요.
여러 파티션이 있는 입력 원본에 대한 병렬 쿼리 실행
이전 수준: Azure Stream Analytics 쿼리에는 입력 원본 파티션 간에 쿼리 처리를 병렬화하기 위해 PARTITION BY 절을 사용해야 했습니다.
1.2 수준: 쿼리 논리를 입력 원본 파티션 간에 병렬화할 수 있는 경우 Azure Stream Analytics는 별도의 쿼리 인스턴스를 만들고 계산을 병렬로 실행합니다.
Azure Cosmos DB 출력과 네이티브 대량 API 통합
이전 수준: upsert 동작이 insert 또는 merge였습니다.
1.2 수준: Azure Cosmos DB 출력과 네이티브 대량 API 통합은 처리량을 최대화하고 제한 요청을 효율적으로 처리합니다. 자세한 내용은 Azure Cosmos DB 페이지에 Azure Stream Analytics 출력을 참조하세요.
upsert 동작은 insert 또는 replace입니다.
SQL 출력에 작성 시 DateTimeOffset
이전 수준: DateTimeOffset 형식이 UTC로 조정되었습니다.
1.2 수준: DateTimeOffset이 더 이상 조정되지 않습니다.
SQL 출력에 작성 시 Long
이전 수준: 대상 유형에 따라 값이 잘렸습니다.
1.2 수준: 대상 형식에 맞지 않는 값은 출력 오류 정책에 따라 처리됩니다.
SQL 출력에 작성 시 레코드 및 배열 serialization
이전 수준: 레코드는 "Record"로 작성되었으며 배열은 "Array"로 작성되었습니다.
1.2 수준: 레코드와 배열은 JSON 형식으로 직렬화됩니다.
함수 접두사의 엄격한 유효성 검사
이전 수준: 함수 접두사의 엄격한 유효성 검사는 없었습니다.
1.2 수준: Azure Stream Analytics는 함수 접두사의 엄격한 유효성 검사를 수행합니다. 기본 제공 함수에 접두사를 추가하면 오류가 발생합니다. 예를 들어, myprefix.ABS(…)은 지원되지 않습니다.
기본 제공 집계에 접두사를 추가해도 오류가 발생합니다. 예를 들어, myprefix.SUM(…)은 지원되지 않습니다.
사용자 정의 함수에 "system" 접두사를 사용하면 오류가 발생합니다.
배열 및 개체를 Azure Cosmos DB 출력 어댑터의 주요 속성으로 허용하지 않음
이전 수준: 배열 및 개체 형식이 키 속성으로 지원되었습니다.
1.2 수준: 배열 및 개체 형식이 더 이상 키 속성으로 지원되지 않습니다.
JSON, AVRO 및 PARQUET에서 부울 형식 역직렬화
이전 수준: Azure Stream Analytics는 부울 값을 BIGINT 형식으로 역직렬화합니다. false는 0으로 매핑되고 true는 1로 매핑됩니다. 출력은 이벤트를 BIT로 명시적으로 변환하는 경우에만 JSON, AVRO 및 PARQUET에서 부울 값을 만듭니다.
예를 들어 input1에서 JSON { "value": true }를 읽는 SELECT value INTO output1 FROM input1과 같은 통과 쿼리는 output1에 JSON 값 { "value": 1 }을 씁니다.
1.2 수준: Azure Stream Analytics는 부울 값을 BIT 형식으로 역직렬화합니다. False는 0에 매핑되고 true는 1에 매핑됩니다. input1에서 JSON { "value": true }를 읽는 SELECT value INTO output1 FROM input1과 같은 통과 쿼리는 output1에 JSON 값 { "value": true }를 씁니다. 값을 쿼리에 BIT를 입력하도록 캐스팅하여 부울 형식을 지원하는 형식의 출력에서 true 및 false로 표시되도록 할 수 있습니다.
호환성 수준 1.1
호환성 수준 1.1의 주요 변경 내용은 다음과 같습니다.
Service Bus XML 형식
1.0 수준: Azure Stream Analytics에서 DataContractSerializer를 사용했기 때문에 메시지 콘텐츠에 XML 태그가 포함되었습니다. 예시:
@\u0006string\b3http://schemas.microsoft.com/2003/10/Serialization/\u0001{ "SensorId":"1", "Temperature":64\}\u0001
1.1 수준: 추가 태그 없이 메시지 콘텐츠에 스트림이 직접 포함됩니다. 예: { "SensorId":"1", "Temperature":64}
필드 이름의 대/소문자 구분 유지
1.0 수준: Azure Stream Analytics 엔진에서 필드 이름을 처리할 때 소문자로 변경되었습니다.
1.1 수준: Azure Stream Analytics 엔진에서 필드 이름을 처리할 때 대소문자 구분이 유지됩니다.
참고 항목
지속적인 대/소문자 구분은 에지 환경을 사용하여 호스팅되는 Stream Analytic 작업에 아직 사용할 수 없습니다. 결과적으로, 작업이 에지에서 호스팅되는 경우 모든 필드 이름은 소문자로 변환됩니다.
FloatNaNDeserializationDisabled
1.0 수준: CREATE TABLE 명령은 FLOAT 열 유형에서 NaN(Not-a-Number. 예를 들어 Infinity, -Infinity)이 있는 이벤트를 필터링하지 않았습니다. 이는 이러한 숫자에 대해 문서화된 범위를 벗어났기 때문입니다.
1.1 수준: CREATE TABLE을 사용하면 강력한 스키마를 지정할 수 있습니다. Stream Analytics 엔진은 데이터가 이 스키마를 준수하는지 확인합니다. 이 모델을 사용하면 이 명령으로 NaN 값을 사용하는 이벤트를 필터링할 수 있습니다.
JSON에 대한 수신 시 날짜/시간 문자열을 DateTime 형식으로 자동 변환하지 않음
1.0 수준: JSON 파서는 날짜/시간/영역 정보를 포함하는 문자열 값을 수신 시 DATETIME 형식으로 자동 변환하므로 값이 원래 형식 및 표준 시간대 정보를 즉시 잃게 됩니다. 수신 중에 처리되기 때문에 해당 필드를 쿼리에서 사용하지 않더라도 UTC 날짜/시간으로 변환됩니다.
1.1 수준: 날짜/시간/영역 정보를 포함하는 문자열 값이 DATETIME 형식으로 자동 변환되지 않습니다. 따라서 표준 시간대 정보 및 원래 형식이 유지됩니다. 하지만 쿼리에서 NVARCHAR(MAX) 필드를 DATETIME 식의 일부로 사용하는 경우(예: DATEADD 함수), 계산을 수행하기 위해 DATETIME 형식으로 변환되고 원래 형식이 유실됩니다.