Azure Stream Analytics 작업에 대한 지역 중복성 얻기
Azure Stream Analytics는 자동 지역 장애 조치를 제공하지 않지만, 여러 Azure 지역에서 동일한 Stream Analytics 작업을 배포하여 지역 중복성을 얻을 수 있습니다. 각 작업은 로컬 입력 및 로컬 출력 원본에 연결됩니다. 애플리케이션은 두 개의 지역 입력으로 입력 데이터를 보내고 두 개의 지역 출력 간에 조정을 진행해야 합니다. Stream Analytics 작업은 별도의 두 엔터티입니다.
다음 다이어그램에서는 이벤트 허브 입력 및 Azure 데이터베이스 출력을 사용하는 샘플 지역 중복 Stream Analytics 작업 배포를 보여 줍니다.
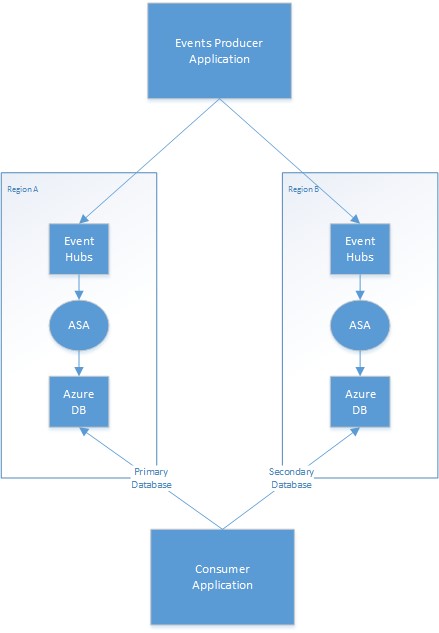
기본/보조 전략
애플리케이션은 주 데이터베이스로 간주되는 지역 출력 데이터베이스와 보조 데이터베이스로 간주되는 지역 출력 데이터베이스를 관리해야 합니다. 주 지역 장애 시 애플리케이션은 보조 데이터베이스로 전환되고 해당 데이터베이스에서 업데이트를 읽기 시작합니다. 중복 읽기를 최소화할 수 있는 실제 메커니즘은 애플리케이션에 따라 달라집니다. 출력에 추가 정보를 기록하여 이 프로세스를 간소화할 수 있습니다. 예를 들어, 각 출력에 타임스탬프 또는 시퀀스 ID를 추가하여 중복 행을 건너뛰는 귀찮은 작업을 간편하게 수행할 수 있습니다. 주 지역이 복원되면 유사한 메커니즘을 사용하여 보조 데이터베이스를 처리합니다.
지역 복제 옵션마다 다른 입력 및 출력 유형을 사용할 수 있지만 이 문서에 설명된 패턴을 사용하여 지역 중복을 구현하면 이벤트 생산자와 이벤트 소비자 둘 다에 대해 유연성 및 제어가 달성되므로 권장됩니다.