Service Fabric을 사용하여 일반적인 시나리오 진단
이 문서에서는 Service Fabric을 사용하여 모니터링 및 진단 영역에서 사용자에게 발생한 일반적인 시나리오에 대해 설명합니다. 여기서 제시되는 시나리오에서는 애플리케이션, 클러스터 및 인프라의 Service Fabric 3개 계층을 모두 다룹니다. 각 솔루션에서 Application Insights, Azure Monitor 로그 및 Azure 모니터링 도구를 사용하여 각각의 시나리오를 완료합니다. 각 솔루션의 단계를 통해 Service Fabric의 컨텍스트에서 Application Insights 및 Azure Monitor 로그를 사용하는 방법을 사용자에게 소개할 수 있습니다.
필수 조건 및 권장 사항
이 문서의 솔루션에서는 다음 도구를 사용합니다. 다음과 같이 설정하고 구성하는 것이 좋습니다.
- Service Fabric이 있는 Application Insights
- 클러스터에서 Azure Diagnostics 사용
- Log Analytics 작업 영역 설정
- 성능 카운터를 추적하는 Log Analytics 에이전트
내 애플리케이션에서 처리되지 않은 예외를 확인하려면 어떻게 해야 할까요?
애플리케이션이 구성된 Application Insight 리소스로 이동합니다.
왼쪽 상단에서 검색을 선택합니다. 그리고 다음 패널에서 필터를 선택합니다.
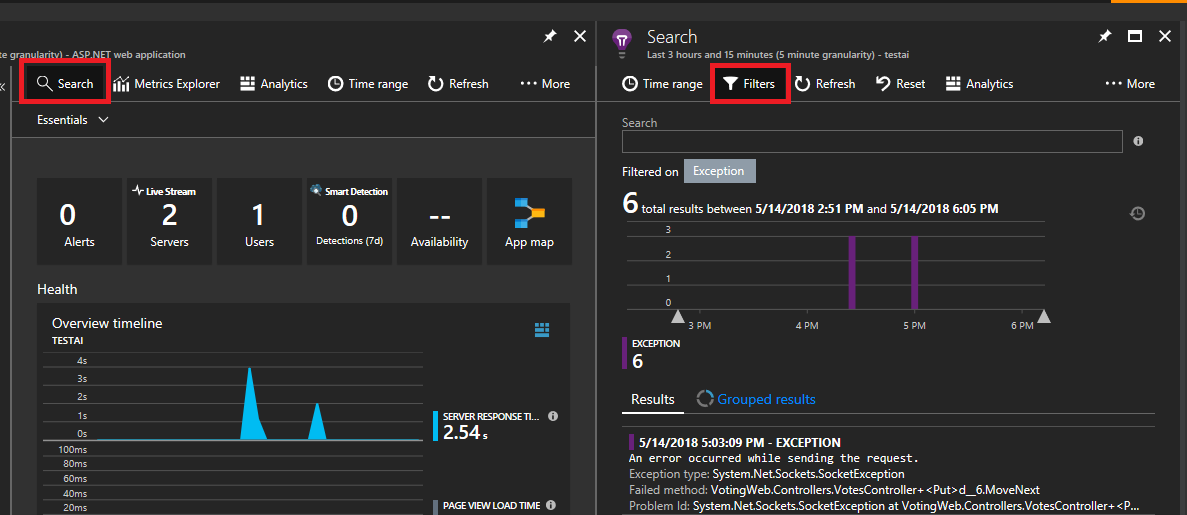
다양한 유형의 이벤트(추적, 요청, 사용자 지정 이벤트)가 표시됩니다. 필터로 "예외"를 선택합니다.
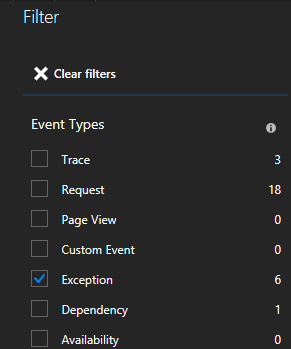
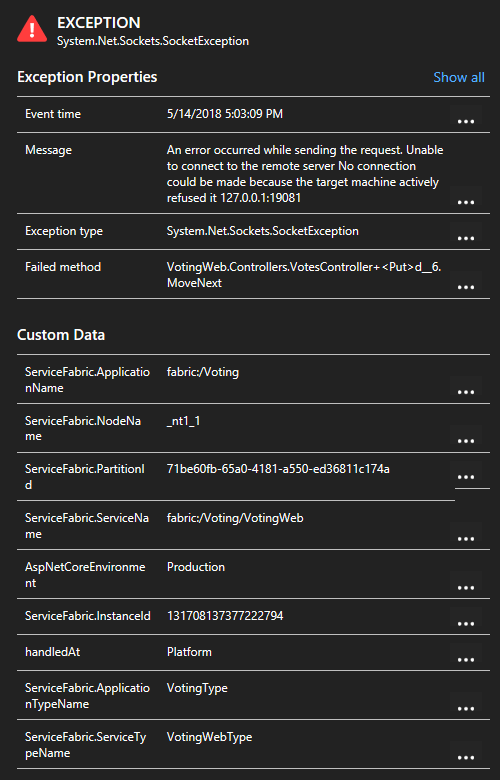
Service Fabric Application Insights SDK를 사용하는 경우 목록에서 예외를 클릭하면 서비스 컨텍스트가 포함된 자세한 내용을 살펴볼 수 있습니다.
내 서비스에서 사용되는 HTTP 호출을 확인하려면 어떻게 할까요?
동일한 Application Insight 리소스에서 예외 대신 "요청"을 필터링하여 모든 요청을 볼 수 있습니다
Service Fabric Application Insights SDK를 사용하는 경우 서로 연결된 서비스의 시각적 표현과 성공하거나 실패한 요청 수를 볼 수 있습니다. 왼쪽에서 "애플리케이션 맵" 선택
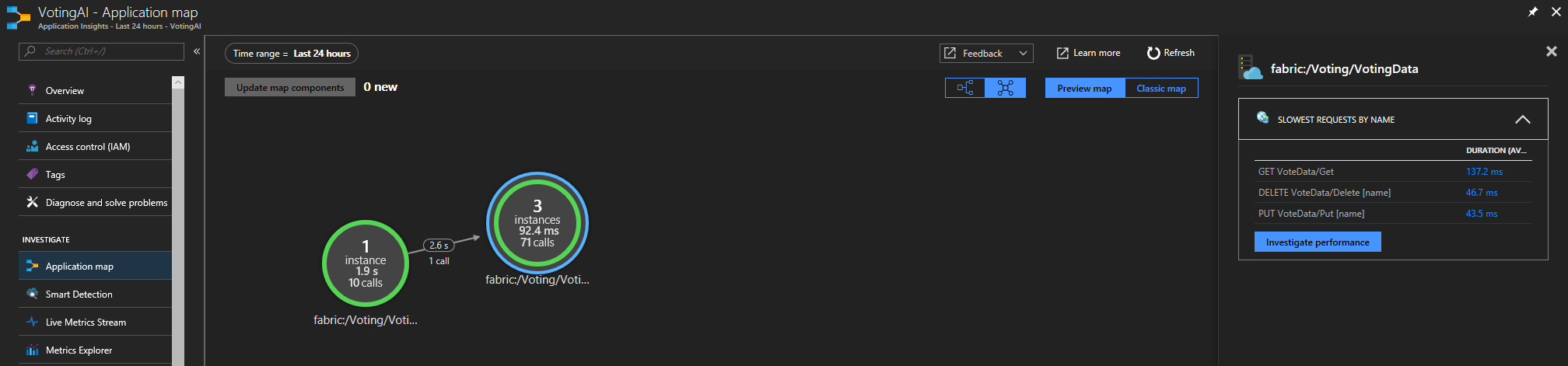
애플리케이션 맵에 대한 자세한 내용은 애플리케이션 맵 설명서를 참조하세요.
노드가 중단될 때 경고를 만들려면 어떻게 할까요?
노드 이벤트는 Service Fabric 클러스터에서 추적합니다. ServiceFabric(NameofResourceGroup)이라는 Service Fabric 분석 솔루션 리소스로 이동합니다.
블레이드 하단에서 "요약"이라는 제목의 그래프 선택
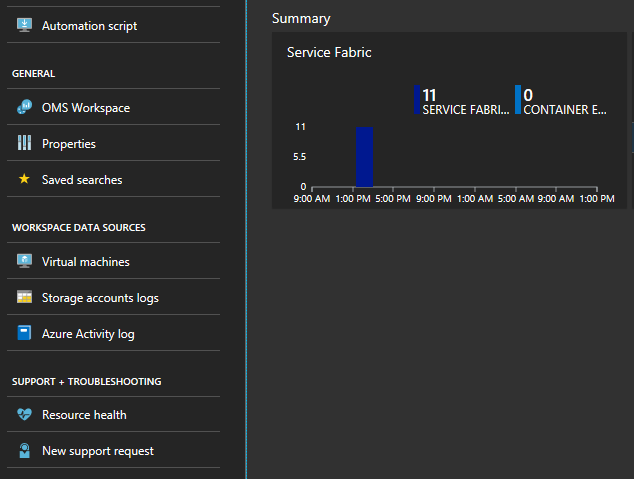
여기에는 다양한 메트릭을 표시하는 많은 그래프와 타일이 있습니다. 그래프 중 하나를 선택하면 로그 검색으로 이동됩니다. 여기서는 모든 클러스터 이벤트 또는 성능 카운터를 쿼리할 수 있습니다.
다음 쿼리를 입력합니다. 이러한 이벤트 ID는 노드 이벤트 참조에 있습니다.
ServiceFabricOperationalEvent | where EventID >= 25622 and EventID <= 25626위쪽에서 "새 경고 규칙"을 선택하면, 이제 이 쿼리에 따라 이벤트가 도착할 때마다 선택한 통신 방법으로 경고 메시지를 받게 됩니다.
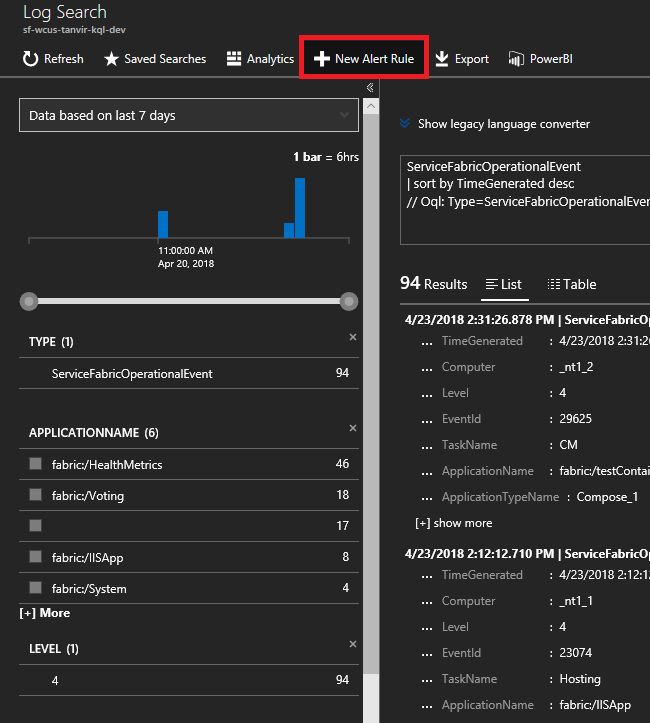
애플리케이션 업그레이드 롤백에 대한 경고를 받으려면 어떻게 해야 할까요?
앞서와 동일한 [로그 검색] 창에서 업그레이드 롤백에 대한 다음 쿼리를 입력합니다. 이러한 이벤트 ID는 애플리케이션 이벤트 참조에 있습니다.
ServiceFabricOperationalEvent | where EventID == 29623 or EventID == 29624상단에서 "새 경고 규칙"을 선택하면 이제 이 쿼리를 기반으로 이벤트가 도착할 때마다 경고를 받게 됩니다.
컨테이너 메트릭을 보려면 어떻게 할까요?
모든 그래프가 있는 동일한 보기에서 컨테이너 성능에 대한 일부 타일을 볼 수 있습니다. 이러한 타일을 채우려면 Log Analytics 에이전트와 컨테이너 모니터링 솔루션이 필요합니다.
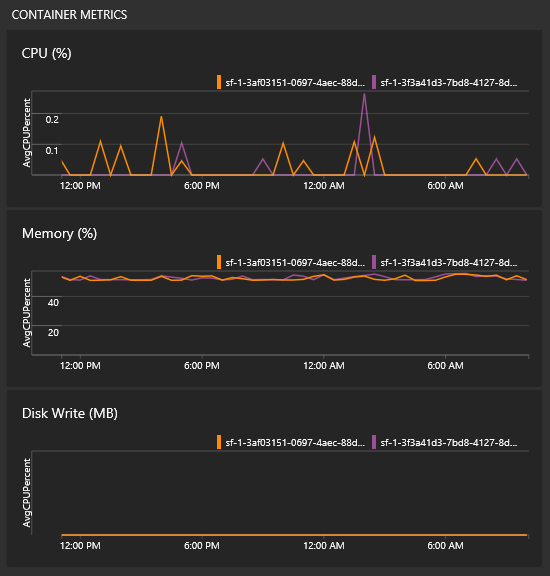
참고 항목
컨테이너 내에서 원격 분석을 계측하려면 컨테이너에 대한 Application Insights nuget 패키지를 추가해야 합니다.
성능 카운터를 모니터링하려면 어떻게 해야 할까요?
클러스터에 Log Analytics 에이전트를 추가한 후에는 추적하려는 특정 성능 카운터를 추가해야 합니다. 포털의 Log Analytics 작업 영역 페이지로 이동합니다. 솔루션의 페이지에서 작업 영역 탭은 왼쪽 메뉴에 있습니다.
작업 영역 페이지에 있으면 동일한 왼쪽 메뉴에서 "고급 설정"을 선택합니다.
데이터 > Windows 성능 카운터(Linux 머신의 경우 데이터 > Linux 성능 카운터)를 차례로 선택하여 Log Analytics 에이전트를 통해 노드에서 특정 카운터를 수집하기 시작합니다. 추가할 카운터에 대한 형식 예제는 다음과 같습니다.
.NET CLR Memory(<ProcessNameHere>)\\# Total committed BytesProcessor(_Total)\\% Processor Time빠른 시작에서 VotingData 및 VotingWeb은 사용한 프로세스 이름이므로 이러한 카운터의 추적은 다음과 같습니다.
.NET CLR Memory(VotingData)\\# Total committed Bytes.NET CLR Memory(VotingWeb)\\# Total committed Bytes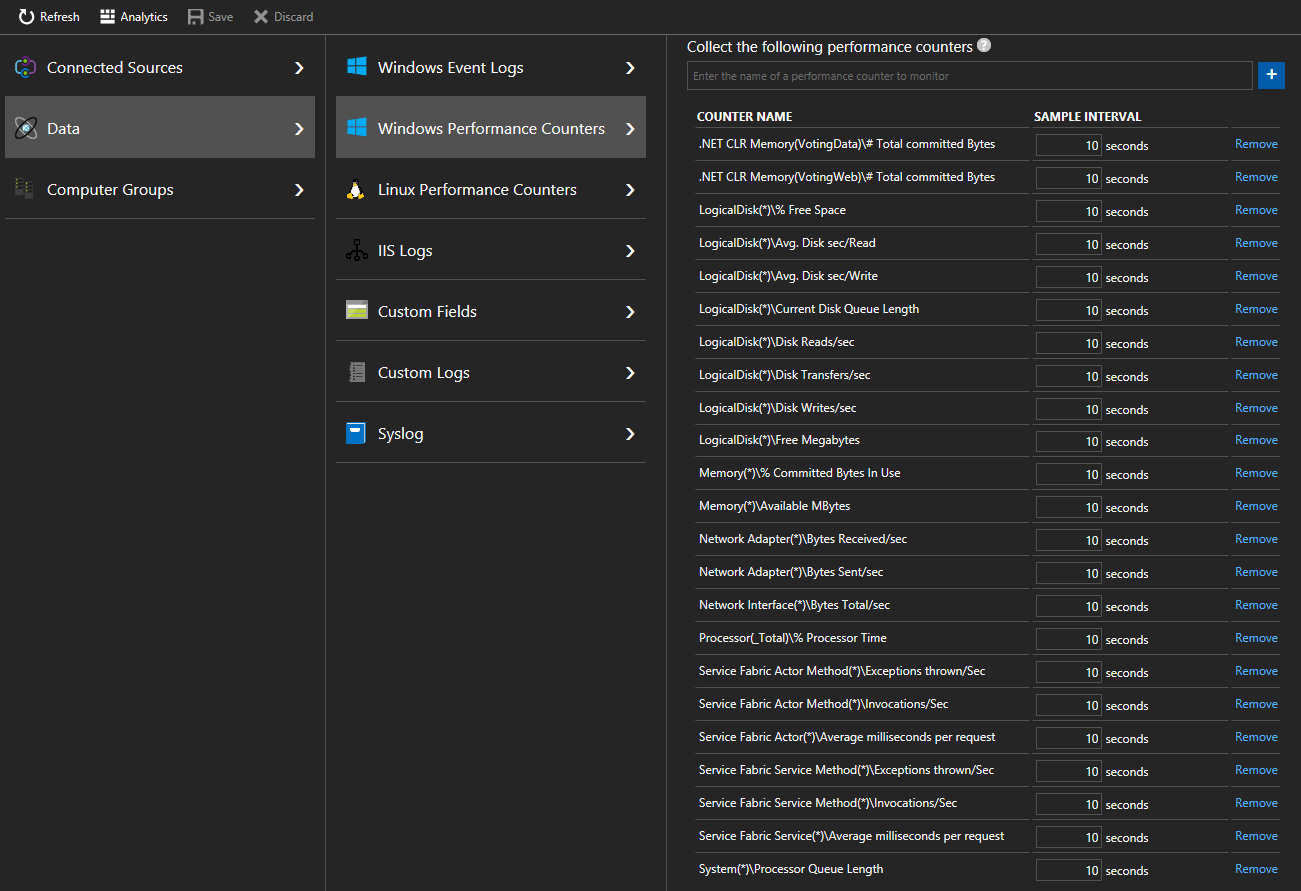
이를 통해 인프라가 워크로드를 처리하는 방법을 확인하고 리소스 사용률에 따라 관련 경고를 설정할 수 있습니다. 예를 들어 총 프로세서 사용률이 90%를 초과하거나 5% 미만인 경우 경고를 설정하는 것이 좋습니다. 이 경우 사용할 카운터 이름은 "% 프로세서 시간"입니다. 이 작업은 다음 쿼리에 대한 경고 규칙을 만들어 수행할 수 있습니다.
Perf | where CounterName == "% Processor Time" and InstanceName == "_Total" | where CounterValue >= 90 or CounterValue <= 5.
내 Reliable Services 및 Actors의 성능을 추적하려면 어떻게 할까요?
애플리케이션에서 Reliable Services 또는 Actors의 성능을 추적하려면 Service Fabric 작업자, 작업자 메서드, 서비스 및 서비스 메서드 카운터도 수집해야 합니다. 수집 가능한 신뢰할 수 있는 서비스 및 작업자 성능 카운터의 예는 다음과 같습니다.
참고 항목
Service Fabric 성능 카운터는 현재 Log Analytics 에이전트에서 수집할 수 없지만 다른 진단 솔루션에서 수집할 수 있습니다.
Service Fabric Service(*)\\Average milliseconds per requestService Fabric Service Method(*)\\Invocations/SecService Fabric Actor(*)\\Average milliseconds per requestService Fabric Actor Method(*)\\Invocations/Sec
Reliable Services 및 Actors의 성능 카운터에 대한 전체 목록은 해당 링크에서 확인하세요.
다음 단계
- 일반 코드 패키지 활성화 오류 조회
- AI에 경고 설정 - 성능 또는 사용 변경에 대한 알림 받기
- Application Insights의 스마트 검색 - 잠재적인 성능 문제를 경고하기 위해 AI에 전송되는 원격 분석에 대한 사전 분석 수행
- 검색 및 진단에 도움이 되도록 Azure Monitor 로그 경고에 대해 자세히 알아보세요.
- 온-프레미스 클러스터의 경우 Azure Monitor 로그는 Azure Monitor 로그로 데이터를 보내는 데 사용할 수 있는 게이트웨이(HTTP 전달 프록시)를 제공합니다. 자세한 내용은 Log Analytics 게이트웨이를 사용하여 인터넷 액세스 없이 Azure Monitor 로그에 컴퓨터 연결을 참조하세요.
- Azure Monitor 로그의 일부로 제공되는 로그 검색 및 쿼리 기능을 알아봅니다.
- Azure Monitor 로그에 대한 자세한 개요와 제공되는 사항을 알아보려면 Azure Monitor 로그란?을 참조하세요.