Service Fabric 클러스터 분산
Service Fabric 클러스터 리소스 관리자는 노드나 서비스의 추가 또는 제거에 대응하는 동적 로드 변경을 지원합니다. 또한 제약 조건 위반을 자동으로 수정하고 사전에 로드를 분산하도록 클러스터를 조정합니다. 그러나 이러한 작업은 얼마나 자주 수행될까요? 그리고 이러한 작업을 트리거하는 것은 무엇일까요?
클러스터 리소스 관리자에서 수행하는 세 가지 작업 범주가 있습니다.
- 배치 – 이 단계는 상태 저장 복제본 또는 누락된 상태 비저장 인스턴스 배치를 처리합니다. 배치에는 새로운 서비스와 실패한 상태 저장 복제본 또는 상태 비저장 인스턴스 모두가 포함됩니다. 복제본 또는 인스턴스 삭제와 제거도 여기에서 다룹니다.
- 제약 조건 검사 - 이 단계에서는 시스템 내에서 여러 배치 제약 조건(규칙)을 검사하고 위반을 수정합니다. 규칙의 예로는 노드 용량을 초과하지 않고 서비스 배치 제약 조건을 충족하도록 하는 것을 들 수 있습니다.
- 분산 - 이 단계에서는 다양한 메트릭에 대해 구성된 원하는 수준의 균형에 따라 다시 조정이 필요한지 확인합니다. 필요한 경우 더 균형이 맞는 클러스터에서 배치를 찾습니다.
클러스터 리소스 관리자 타이머 구성
균형 조정과 관련된 첫 번째 컨트롤 세트는 타이머 세트입니다. 이러한 타이머는 클러스터 리소스 관리자에서 클러스터를 검사하고 수정 작업을 수행하는 빈도를 제어합니다.
Cluster Resource Manager에서 수행할 수 있는 이러한 각 형식의 수정 작업은 해당 빈도를 제어하는 다른 타이머에 의해 제어됩니다. 각 타이머가 실행되면 작업이 예약됩니다. 기본적으로 Resource Manager는
- 1/10초마다 상태를 검색하고 업데이트를 적용합니다(예: 노드가 다운된 기록).
- 배치 검사 플래그를 1초마다 설정합니다.
- 제약 조건 검사 플래그를 매 초마다 설정합니다.
- 분산 플래그를 5초마다 설정합니다.
이러한 타이머를 관리하는 구성의 예제는 다음과 같습니다.
ClusterManifest.xml:
<Section Name="PlacementAndLoadBalancing">
<Parameter Name="PLBRefreshGap" Value="0.1" />
<Parameter Name="MinPlacementInterval" Value="1.0" />
<Parameter Name="MinConstraintCheckInterval" Value="1.0" />
<Parameter Name="MinLoadBalancingInterval" Value="5.0" />
</Section>
독립 실행형 배포의 경우 ClusterConfig.json 또는 Azure 호스티드 클러스터의 경우 Template.json를 통해 수행됩니다.
"fabricSettings": [
{
"name": "PlacementAndLoadBalancing",
"parameters": [
{
"name": "PLBRefreshGap",
"value": "0.10"
},
{
"name": "MinPlacementInterval",
"value": "1.0"
},
{
"name": "MinConstraintCheckInterval",
"value": "1.0"
},
{
"name": "MinLoadBalancingInterval",
"value": "5.0"
}
]
}
]
현재 클러스터 리소스 관리자에서는 이러한 작업 중 하나를 한 번에 하나씩 순차적으로 수행합니다. 이는 이러한 타이머를 "최소 간격"이라고 하며, 타이머가 "설정 플래그"가 되면 수행되도록 하는 동작을 참조하는 이유입니다. 예를 들어 클러스터 분산에 앞서 서비스를 만들기 위해 Cluster Resource Manager가 보류 중인 요청을 처리합니다. 지정된 기본 시간 간격에서 알 수 있듯이 클러스터 리소스 관리자에서는 자주 수행해야 하는 작업을 검색합니다. 일반적으로 이는 각 단계에서 수행된 변경 집합이 작음을 의미합니다. 작은 변경을 자주 수행하면 클러스터에서 상황이 발생할 때 클러스터 리소스 관리자에서 즉각적으로 반응할 수 있습니다. 여러 동일한 형식의 이벤트는 동시에 발생하는 경향이 있으므로 기본 타이머가 일부 일괄 처리를 제공합니다.
예를 들어 노드가 실패할 경우 전체 장애 도메인 작업을 한 번에 수행할 수 있습니다. 이러한 모든 실패는 PLBRefreshGap 이후의 다음 상태 업데이트에서 캡처됩니다. 수정은 다음 배치, 제약 조건 검사 및 분산 실행 중에 결정됩니다. 기본적으로 클러스터 리소스 관리자는 클러스터에서 변경 시간 내내 검색하는 것이 아니라 모든 변경을 한꺼번에 처리합니다. 이렇게 하면 갑작스러운 이탈이 발생하게 됩니다.
Cluster Resource Manager는 클러스터의 분산 여부를 판단하기 위해 추가적인 정보도 필요로 합니다. 이를 위해 BalancingThresholds(분산 임계값)과 ActivityThresholds(활동 임계값)의 다른 두 가지 구성 요소가 있습니다.
분산 임계값
분산 임계값은 로드 다시 분산을 트리거하기 위한 주요 컨트롤입니다. 메트릭에 대한 분산 임계값은 비율입니다. 가장 로드가 많은 노드의 메트릭에 대한 로드를 가장 로드가 적은 노드의 로드 양으로 나눈 값이 해당 메트릭의 BalancingThreshold를 초과하는 경우 클러스터의 불균형이 발생합니다. 결과적으로 Cluster Resource Manager가 다음 번에 확인할 때 분산이 트리거됩니다. MinLoadBalancingInterval 타이머는 클러스터 리소스 관리자에서 로드 다시 분산이 필요한지 확인해야 하는 빈도를 정의합니다. 확인은 아무 것도 발생하지 않는다는 의미입니다.
분산 임계값은 클러스터 정의의 일부로서 메트릭 단위로 정의됩니다. 메트릭에 대한 자세한 내용은 메트릭 문서를 확인하세요.
ClusterManifest.xml
<Section Name="MetricBalancingThresholds">
<Parameter Name="MetricName1" Value="2"/>
<Parameter Name="MetricName2" Value="3.5"/>
</Section>
독립 실행형 배포의 경우 ClusterConfig.json 또는 Azure 호스티드 클러스터의 경우 Template.json를 통해 수행됩니다.
"fabricSettings": [
{
"name": "MetricBalancingThresholds",
"parameters": [
{
"name": "MetricName1",
"value": "2"
},
{
"name": "MetricName2",
"value": "3.5"
}
]
}
]
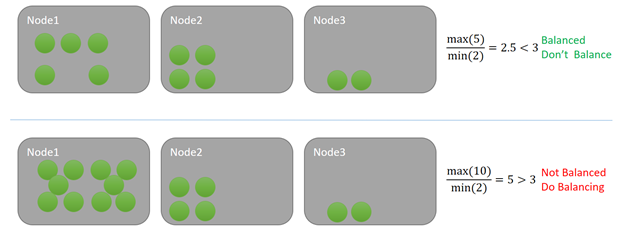
이 예제에서는 각 서비스에서 한 단위의 메트릭을 사용합니다. 위 예제에서 노드의 최대 부하는 5이고 최소 부하는 2입니다. 이 메트릭에 대한 분산 임계값이 3이라고 가정해 봅니다. 클러스터의 비율이 5/2 = 2.5이며 지정된 분산 임계값인 3보다 낮으므로 클러스터는 균형이 맞습니다. Cluster Resource Manager가 확인할 때 분산이 트리거되지 않습니다.
아래 예에서 노드의 최대 로드는 10이지만 최소 로드는 2이므로 비율은 5입니다. 5는 해당 메트릭에 지정된 분산 임계값인 3보다 큽니다. 결과적으로 다음번에 분산 타이머가 실행될 때 분산 변경 실행이 예약됩니다. 이와 같은 상황에서 일부 로드는 일반적으로 노드 3에 분산됩니다. Service Fabric 클러스터 리소스 관리자에서 greedy 방식을 사용하지 않으므로 일부 로드가 노드 2에도 분산됩니다.
참고 항목
"분산"은 클러스터에서 로드를 관리하기 위한 두 가지 전략을 처리합니다. 클러스터 리소스 관리자에서 사용하는 기본 전략은 클러스터의 노드 간에 로드를 분산하는 것입니다. 다른 전략은 조각 모음입니다. 조각 모음은 동일한 분산을 실행하는 동안에 수행됩니다. 분산 및 조각 모음 전략은 동일한 클러스터 내의 여러 메트릭에 사용할 수 있습니다. 서비스에서는 분산 및 조각 모음 메트릭을 모두 사용할 수 있습니다. 조각 모음 메트릭의 경우 분산 임곗값보다 작은 경우 클러스터의 로드 비율에서 다시 분산을 트리거합니다.
분산 임곗값 이하를 달성하는 것이 명시적 목표는 아닙니다. 분산 임계값은 트리거입니다. 분산이 실행될 때 클러스터 리소스 관리자는 자체적으로 수행할 수 있는 향상된 기능(있는 경우)을 결정합니다. 분산 검색이 시작되었기 때문에 어떤 항목도 이동하지 않는다는 의미는 아닙니다. 때로는 클러스터에서 분산되지 않지만 너무 제한되어 수정하지 못할 수 있습니다. 또는 향상된 기능이 이동해야 하지만 비용이 많이 들 수도 있습니다.
활동 임계값
경우에 따라 노드가 상대적으로 불균형하기도 하지만 클러스터의 총 부하량은 낮습니다. 이러한 현상은 일시적인 감소이거나, 새 클러스터가 막 부트스트랩되었기 때문에 발생합니다. 어느 경우든 얻을 수 있는 이득이 거의 없기 때문에 클러스터 분산에 시간을 투자하지 않으려 할 수 있습니다. 클러스터가 분산을 거쳤다면 절대적인 큰 차이를 만들지 않고 네트워크와 컴퓨팅 리소스를 사용하여 항목을 이동한 것입니다. 이처럼 불필요한 이동을 방지하기 위해 활동 임계값이라고 하는 다른 컨트롤이 있습니다. 활동 임계값을 사용하면 활동에 대해 일부 절대 하한값을 지정할 수 있습니다. 이 임계값을 초과하는 노드가 없으면 분산 임계값에 도달해도 분산이 트리거되지 않습니다.
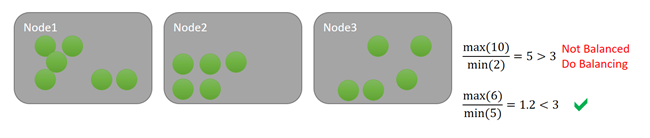
이 메트릭에 대해 세 개의 분산 임계값을 유지한다고 가정해 보겠습니다. 활동 임계값도 1,536이라고 가정해 보겠습니다. 첫 번째 경우에서 분산 임계값에 따르면 클러스터는 불균형 상태이지만 활동 임계값을 충족하는 노드가 없으므로 아무 일도 발생하지 않습니다. 아래 예에서 노드 1은 작업 임곗값을 초과했습니다. 메트릭에 대한 분산 임계값과 활동 임계값이 모두 초과되었으므로 분산이 예약됩니다. 예를 들어 다음 다이어그램을 살펴보겠습니다.

분산 임계값과 마찬가지로 활동 임계값은 클러스터 정의를 통한 메트릭을 기준으로 정의됩니다.
ClusterManifest.xml
<Section Name="MetricActivityThresholds">
<Parameter Name="Memory" Value="1536"/>
</Section>
독립 실행형 배포의 경우 ClusterConfig.json 또는 Azure 호스티드 클러스터의 경우 Template.json를 통해 수행됩니다.
"fabricSettings": [
{
"name": "MetricActivityThresholds",
"parameters": [
{
"name": "Memory",
"value": "1536"
}
]
}
]
분산 및 활동 임계값은 모두 특정 메트릭에 연결됩니다. 분산은 동일한 메트릭에 대해 분산 임계값과 활동 임계값을 모두 초과한 경우에만 트리거됩니다.
참고 항목
지정되지 않은 경우 메트릭에 대한 균형 조정 임계값은 1이고 활동 임계값은 0입니다. 즉, 클러스터 Resource Manager는 지정된 부하에 해당 메트릭이 완벽하게 분산되도록 유지하려고 합니다. 사용자 지정 메트릭을 사용하는 경우 메트릭에 대한 고유한 분산 및 작업 임곗값을 명시적으로 정의하는 것이 좋습니다.
분산 서비스 함께 사용
클러스터가 분산되지 않는지 여부는 클러스터 전체의 결정입니다. 그러나 개별 서비스 복제본과 인스턴스를 움직여 문제를 해결합니다. 참 합리적이지 않은가요? 메모리가 한 노드에 쌓여 있다면 여러 복제본이나 인스턴스가 여기에 참여할 수 있습니다. 불균형을 해결하려면 불균형 상태인 메트릭을 사용하는 상태 저장 복제본이나 상태 비저장 인스턴스를 움직여야 합니다.
그러나 때때로 자체적으로 분산되지 않는 서비스가 이동됩니다(이전의 로컬 및 전역 가중치에 대한 논의를 상기함). 모든 서비스의 메트릭이 분산되었을 때 서비스가 이동하는 이유는 무엇인가요? 예를 들어 살펴보겠습니다.
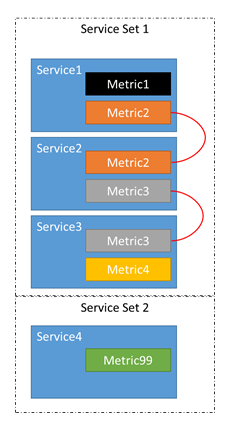
- 서비스 1, 서비스 2, 서비스 3 및 서비스 4의 네 가지 서비스가 있다고 가정해 보겠습니다.
- 서비스 1은 메트릭 메트릭 1 및 메트릭 2를 보고합니다.
- 서비스 2는 메트릭 메트릭 2 및 메트릭 3를 보고합니다.
- 서비스 3은 메트릭 메트릭 3 및 메트릭 4를 보고합니다.
- 서비스 4는 메트릭 메트릭 99를 보고합니다.
실제로 4개의 독립된 서비스가 있는 것이 아니라, 3개의 서비스가 관련되어 있고 하나는 자체적으로 꺼져 있습니다.
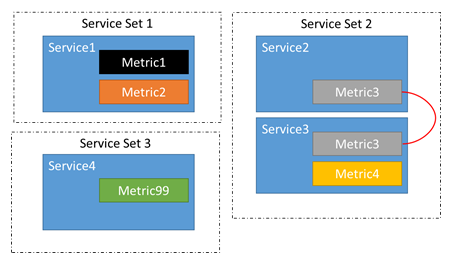
이 체인으로 인해 메트릭 1-4가 분산되지 않으므로 서비스 1-3에 속한 복제본 또는 인스턴스가 이동할 수 있습니다. 메트릭 1, 2 또는 3이 분산되지 않으므로 서비스 4에서 이동이 발생하지 않음을 알 수 있습니다. 서비스 4에 속한 복제본 또는 인스턴스를 이동해도 메트릭 1-3의 분산에 아무런 영향을 주지 않기 때문에 전혀 의미가 없습니다.
클러스터 리소스 관리자는 관련된 서비스를 자동으로 파악합니다. 서비스에 대한 메트릭을 추가, 제거 또는 변경하면 이러한 관계에 영향을 미칠 수 있습니다. 예를 들어 분산이 두 번 실행되는 동안 서비스 2에서 메트릭 2를 제거하도록 업데이트되었을 수 있습니다. 이를 통해 Service 1과 Service 2 사이의 체인이 끊깁니다. 이제는 관련된 두 개의 서비스 그룹 대신 세 개 그룹이 있습니다.
노드 유형별 클러스터 분산
이전 섹션에서 설명한 것처럼 리밸런싱 트리거의 기본 컨트롤은 작업 임곗값, 분산 임곗값 및 타이머입니다. Service Fabric 클러스터 리소스 관리자 노드 유형당 매개 변수를 지정하고 불균형 노드 형식에서만 이동을 허용하여 다시 분산 트리거를 보다 세부적으로 제어할 수 있습니다. 노드 유형당 분산의 기본 이점은 다른 노드 형식의 성능 저하 없이 더 엄격한 분산 규칙이 필요한 노드 형식에서 성능을 개선할 수 있다는 것입니다. 이 기능에는 두 개의 주요 부분이 포함되어 있습니다.
- 불균형 검색은 노드 유형별로 수행됩니다. 이전에는 각 노드 유형에 대해 불균형의 전역 계산이 계산되었습니다. 모든 노드 형식의 균형이 조정된 경우 CRM은 분산 단계를 트리거하지 않습니다. 그렇지 않으면 하나 이상의 노드 유형이 불균형한 경우 분산 단계가 필요합니다.
- 분산은 불균형한 노드 형식에서만 복제본을 이동하며, 다른 노드 형식은 분산 단계의 영향을 받지 않습니다.
노드 유형당 분산이 클러스터에 미치는 영향
노드 유형별로 클러스터의 균형을 조정하는 동안 Service Fabric 클러스터 리소스 관리자는 각 노드 유형의 불균형 상태를 계산합니다. 하나 이상의 노드 유형이 불균형하면 분산 단계가 트리거됩니다. 분산 단계는 이러한 노드 형식에서 분산이 일시적으로 일시 중지된 경우(예: 이전 분산 단계 이후 최소 분산 간격이 통과되지 않은 경우) 불균형한 노드 형식의 복제본을 이동하지 않습니다. 불균형 상태의 탐지는 기존 클러스터 분산에 이미 사용할 수 있는 공통 메커니즘을 사용하지만 구성 세분성과 유연성을 개선합니다. 불균형을 감지하기 위해 노드 유형별로 균형을 조정하는 데 사용되는 메커니즘은 아래 목록에 제공됩니다.
- 노드 유형당 메트릭 분산 임곗값은 클래식 분산에 사용되는 전역적으로 정의된 분산 임곗값과 유사한 역할을 갖는 값입니다. 최소 및 최대 메트릭 로드의 비율은 각 노드 유형에 대해 계산됩니다. 노드 형식의 비율이 노드 형식의 정의된 분산 임곗값보다 높은 경우 노드 형식은 불균형으로 표시됩니다. 노드 유형별 메트릭 작업 임곗값 구성에 대한 자세한 내용은 노드 유형별 분산 임곗값 섹션을 확인하세요.
- 노드 유형당 메트릭 작업 임곗값은 클래식 분산에 사용되는 전역적으로 정의된 작업 임곗값과 유사한 역할을 갖는 값입니다. 최대 메트릭 로드는 각 노드 유형에 대해 계산됩니다. 노드 형식의 최대 로드가 해당 노드 형식에 대해 정의된 작업 임곗값보다 높은 경우 노드 형식은 불균형으로 표시됩니다. 노드 유형별 메트릭 작업 임곗값 구성에 대한 자세한 내용은 노드 유형별 작업 임곗값 섹션을 확인하세요.
- 노드 유형당 최소 분산 간격에는 전역적으로 정의된 최소 분산 간격과 유사한 역할이 있습니다. 각 노드 유형에 대해 클러스터 리소스 관리자는 마지막 분산의 타임스탬프를 유지합니다. 정의된 최소 분산 간격 내의 노드 형식에서 두 번의 연속 분산 단계를 실행할 수 없습니다. 노드 유형당 최소 분산 간격 구성에 대한 자세한 내용은 노드 유형별 최소 분산 간격 섹션을 확인하세요.
노드 유형별 분산 설명
노드 유형별로 분산을 사용하도록 설정하려면 클러스터 매니페스트에서 SeparateBalancingStrategyPerNodeType 매개 변수를 사용하도록 설정해야 합니다. 또한 하위 클러스터링 기능도 사용하도록 설정해야 합니다. 기능을 사용하도록 설정하기 위한 클러스터 매니페스트 PlacementAndLoadBalancing 섹션의 예:
<Section Name="PlacementAndLoadBalancing">
<Parameter Name="SeparateBalancingStrategyPerNodeType" Value="true" />
<Parameter Name="SubclusteringEnabled" Value="true" />
<Parameter Name="SubclusteringReportingPolicy" Value="1" />
</Section>
독립 실행형 배포의 경우 ClusterConfig.json 또는 Azure 호스팅 클러스터의 경우 Template.json:
"fabricSettings": [
{
"name": "PlacementAndLoadBalancing",
"parameters": [
{
"name": "SeparateBalancingStrategyPerNodeType",
"value": "true"
},
{
"name": "SubclusteringEnabled",
"value": "true"
},
{
"name": "SubclusteringReportingPolicy",
"value": "1"
},
]
}
]
이전 섹션에서 설명한 대로 노드 유형별로 임곗값 및 간격을 지정할 수 있습니다. 특정 매개 변수 업데이트에 대한 자세한 내용은 다음 섹션을 확인하세요.
노드 유형당 분산 임곗값
분산 구성에서 세분성을 높이기 위해 노드 유형별로 메트릭 분산 임곗값을 정의할 수 있습니다. 분산 임곗값은 특정 노드 형식 내에서 최대 및 최소 로드 값의 비율에 대한 임곗값을 나타내기 때문에 부동 소수점 형식을 갖습니다. 분산 임곗값은 각 노드 유형에 대한 PlacementAndLoadBalancingOverrides 섹션에 정의되어 있습니다.
<NodeTypes>
<NodeType Name="NodeType1">
<PlacementAndLoadBalancingOverrides>
<MetricBalancingThresholdsPerNodeType>
<BalancingThreshold Name="Metric1" Value="2.5">
<BalancingThreshold Name="Metric2" Value="4">
<BalancingThreshold Name="Metric3" Value="3.25">
</MetricBalancingThresholdsPerNodeType>
</PlacementAndLoadBalancingOverrides>
</NodeType>
</NodeTypes>
메트릭에 대한 분산 임곗값이 노드 유형에 대해 정의되지 않은 경우 임곗값은 PlacementAndLoadBalancing 섹션에서 전역적으로 정의된 메트릭 분산 임곗값 값을 상속합니다. 그렇지 않고 메트릭에 대한 분산 임곗값이 노드 형식에 대해 정의되지 않았거나 PlacementAndLoadBalancing 섹션에서 전역적으로 정의되지 않은 경우 임곗값은 기본값 0이 됩니다.
노드 유형당 작업 임곗값
분산 구성의 세분성을 높이기 위해 노드 유형별로 메트릭 작업 임곗값을 정의할 수 있습니다. 작업 임곗값은 특정 노드 형식 내의 최대 로드 값에 대한 임곗값을 나타내기 때문에 정수 형식을 갖습니다. 작업 임곗값은 각 노드 유형에 대한 PlacementAndLoadBalancingOverrides 섹션에 정의되어 있습니다.
<NodeTypes>
<NodeType Name="NodeType1">
<PlacementAndLoadBalancingOverrides>
<MetricActivityThresholdsPerNodeType>
<ActivityThreshold Name="Metric1" Value="500">
<ActivityThreshold Name="Metric2" Value="40">
<ActivityThreshold Name="Metric3" Value="1000">
</MetricActivityThresholdsPerNodeType>
</PlacementAndLoadBalancingOverrides>
</NodeType>
</NodeTypes>
메트릭에 대한 작업 임곗값이 노드 유형에 대해 정의되지 않은 경우 임곗값은 PlacementAndLoadBalancing 섹션에서 전역적으로 정의된 메트릭 작업 임곗값의 값을 상속합니다. 그렇지 않고 메트릭에 대한 작업 임곗값이 노드 형식에 대해 정의되지 않았거나 PlacementAndLoadBalancing 섹션에서 전역적으로 정의되지 않은 경우 임곗값은 기본값 0이 됩니다.
노드 유형당 최소 분산 간격
분산 구성의 세분성을 높이기 위해 노드 유형별로 최소 분산 간격을 정의할 수 있습니다. 최소 분산 간격은 동일한 노드 형식에서 두 개의 연속 분산 라운드 전에 통과해야 하는 최소 시간을 나타내기 때문에 정수 형식입니다. 최소 분산 간격은 각 노드 유형에 대한 PlacementAndLoadBalancingOverrides 섹션에 정의되어 있습니다.
<NodeTypes>
<NodeType Name="NodeType1">
<PlacementAndLoadBalancingOverrides>
<MinLoadBalancingIntervalPerNodeType>100</MinLoadBalancingIntervalPerNodeType>
</PlacementAndLoadBalancingOverrides>
</NodeType>
</NodeTypes>
노드 형식에 대해 최소 분산 간격이 정의되지 않은 경우 간격은 PlacementAndLoadBalancing 섹션에 전역적으로 정의된 최소 분산 간격에서 값을 상속합니다. 그렇지 않고 노드 형식에 대해 또는 PlacementAndLoadBalancing 섹션에서 전역적으로 최소 간격이 정의되지 않은 경우 최소 간격의 기본값은 0이며 이는 연속 분산 라운드 간의 일시 중지가 필요하지 않음을 나타냅니다.
예제
예 1
클러스터에 노드 유형 A 및 노드 유형 B라는 두 개의 노드 형식이 포함된 경우를 살펴보겠습니다. 모든 서비스는 동일한 메트릭을 보고하며 이러한 노드 유형 간에 분할되므로 로드 통계는 서로 다릅니다. 이 예제에서 노드 형식 A 의 최대 로드는 300이고 최소 100개이며 노드 형식 B 의 최대 로드는 700이고 최소 로드는 500입니다.
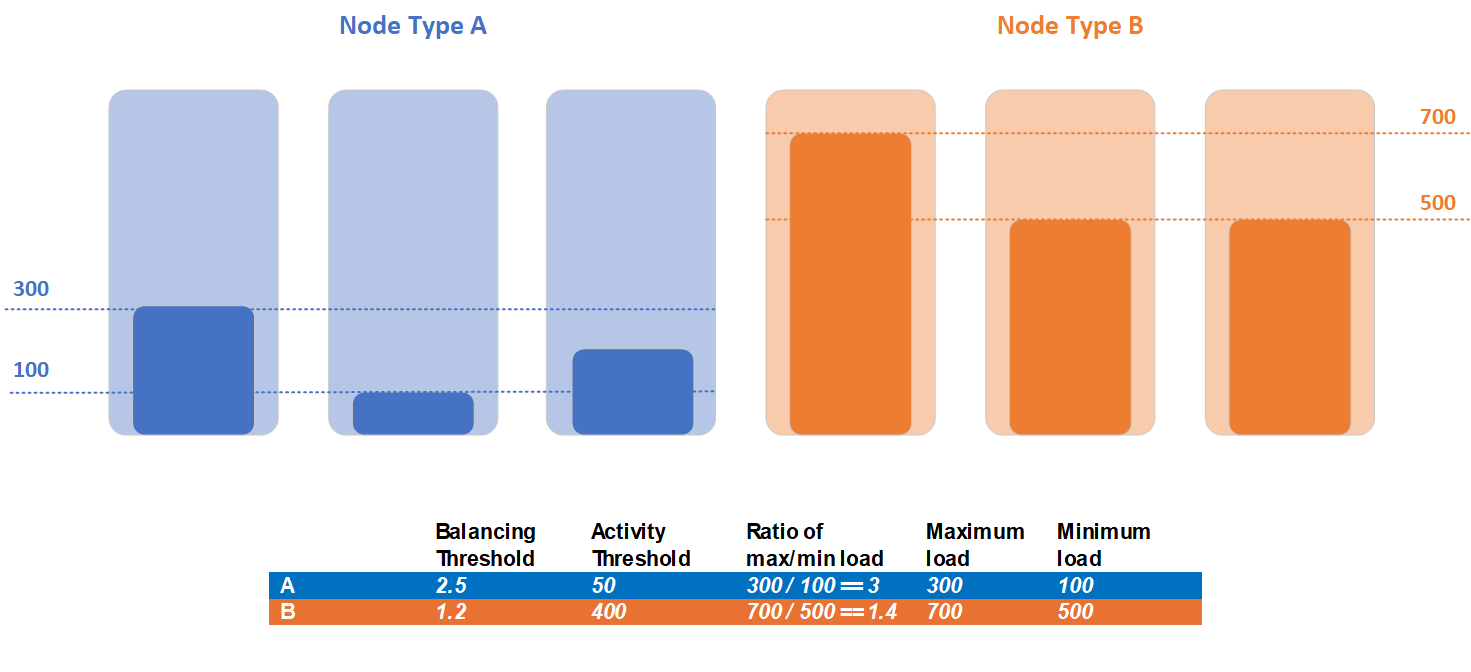
고객은 두 노드 유형의 워크로드에 서로 다른 분산 요구 사항이 있음을 감지하고 노드 유형별로 다른 분산 및 작업 임곗값을 설정하기로 결정했습니다. 노드 유형 A의 분산 임곗값은 2.5이고 작업 임곗값은 50입니다. 노드 유형 B의 경우 고객은 분산 임곗값을 1.2로 설정하고 작업 임곗값을 400으로 설정합니다.
이 예제에서 클러스터에 대한 불균형을 검색하는 동안 두 노드 유형 모두 작업 임곗값을 위반합니다. 노드 유형 A의 최대 로드 300은 정의된 작업 임곗값인 50보다 높습니다. 노드 유형 B의 최대 로드 700은 정의된 작업 임곗값인 400보다 높습니다. 노드 유형 A는 최대 및 최소 로드의 현재 비율이 3이고 분산 임곗값이 2.5이므로 분산 임곗값 조건을 위반합니다. 반대로 노드 유형 B는 이 노드 형식에 대한 최대 및 최소 로드의 현재 비율이 1.2이지만 분산 임곗값은 1.4이므로 분산 임곗값 조건을 위반하지 않습니다. 분산은 노드 유형 A의 복제본에만 필요하며, 분산 단계 중에 이동할 수 있는 유일한 복제본 집합은 노드 형식 A에 배치된 복제본입니다.
예제 2
클러스터에 노드 유형 A, B, C라는 세 개의 노드 형식이 포함된 경우를 살펴보겠습니다. 모든 서비스는 동일한 메트릭을 보고하며 이러한 노드 유형 간에 분할되므로 로드 통계는 서로 다릅니다. 이 예제에서 노드 유형 A의 최대 로드는 600이고 최소 로드는 100이며, 노드 형식 B는 최대 로드가 900이고 최소 로드가 100이며, 노드 형식 C 는 최대 로드가 600이고 최소 로드는 300입니다.

고객은 이러한 노드 유형의 워크로드에 서로 다른 분산 요구 사항이 있음을 감지하고 노드 유형별로 다른 분산 및 작업 임곗값을 설정하기로 결정했습니다. 노드 유형 A의 분산 임곗값은 5이고 작업 임곗값은 700입니다. 노드 유형 B의 경우 고객은 분산 임곗값을 10으로 설정하고 작업 임곗값을 200으로 설정합니다. 노드 유형 C의 경우 고객은 분산 임곗값을 2로 설정하고 작업 임곗값을 300으로 설정합니다.
노드 유형 A의 최대 로드 600은 정의된 작업 임곗값 700보다 낮으므로 노드 유형 A의 균형이 조정되지 않습니다. 노드 유형 B의 최대 로드 900은 정의된 작업 임곗값인 200보다 높습니다. 노드 유형 B는 작업 임곗값 조건을 위반합니다. 노드 유형 C의 최대 로드 600은 정의된 작업 임곗값인 300보다 높습니다. 노드 형식 C는 작업 임곗값 조건을 위반합니다. 노드 유형 B는 이 노드 형식에 대한 최대 및 최소 로드의 현재 비율이 9이지만 분산 임곗값은 10이므로 분산 임곗값 조건을 위반하지 않습니다. 노드 유형 C는 최대 및 최소 로드의 현재 비율이 2이고 분산 임곗값이 2이므로 분산 임곗값 조건을 위반합니다. 분산은 노드 유형 C의 복제본에만 필요하며, 분산 단계 중에 이동할 수 있는 유일한 복제본 집합은 노드 형식 C에 배치된 복제본입니다.
다음 단계
- 메트릭은 서비스 패브릭 클러스터 리소스 관리자가 클러스터의 소비와 용량을 관리하는 방법입니다. 메트릭 및 구성 방법에 대한 자세한 내용은 메트릭 문서를 확인하세요.
- 이동 비용은 특정 서비스가 다른 서비스에 비해 이동하는 데 비용이 더 많이 드는 것을 클러스터 리소스 관리자에게 알리는 한 가지 방법입니다. 이동 비용에 대한 자세한 내용은 이동 비용 문서를 참조하세요.
- 클러스터 리소스 관리자에는 클러스터에서 이탈을 늦추도록 구성할 수 있는 몇 가지 제한이 있습니다. 일반적으로 필요하지는 않지만 필요할 경우 고급 제한 문서에서 알아볼 수 있습니다.
- 클러스터 리소스 관리자는 하위 클러스터링을 인식하고 처리할 수 있습니다. 배치 제약 조건 및 분산을 사용할 때 하위 클러스터링이 발생할 수 있습니다. 하위 클러스터링이 분산에 미치는 영향과 처리 방법에 대한 자세한 내용은 하위 클러스팅 문서를 참조하세요.