Azure Traffic Manager의 안정성
이 문서에는 Azure Traffic Manager에 대한 지역 간 재해 복구 및 비즈니스 연속성 지원이 포함되어 있습니다.
지역 간 재해 복구 및 비즈니스 연속성
DR(재해 복구)은 가동 중지 시간 및 데이터 손실을 초래하는 자연 재해 또는 실패한 배포와 같은 영향이 큰 이벤트로부터 복구하는 것입니다. 원인에 관계없이 최상의 재해 해결책은 잘 정의되고 테스트된 DR 계획과 DR을 적극적으로 지원하는 애플리케이션 디자인입니다. 재해 복구 계획을 만들기 전에 재해 복구 전략을 디자인하기 위한 권장 사항을 참조하세요.
DR과 관련하여 Microsoft는 공유 책임 모델을 사용합니다. 공유 책임 모델에서 Microsoft는 기준 인프라 및 플랫폼 서비스를 사용할 수 있도록 보장합니다. 동시에 많은 Azure 서비스는 데이터를 자동으로 복제하거나 실패한 지역에서 대체하여 사용하도록 설정된 다른 지역으로 교차 복제하지 않습니다. 이러한 서비스의 경우 워크로드에 적합한 재해 복구 계획을 설정할 책임이 있습니다. Azure PaaS(Platform as a Service) 제품에서 실행되는 대부분의 서비스는 DR을 지원하는 기능과 지침을 제공하며, 서비스별 기능을 사용하여 빠른 복구를 지원하여 DR 계획을 개발하는 데 도움이 될 수 있습니다.
Azure Traffic Manager는 전역 Azure 지역의 공용 애플리케이션에 트래픽을 분산할 수 있는 DNS 기반 트래픽 부하 분산 장치입니다. 또한 Traffic Manager는 고가용성과 빠른 응답성을 갖춘 퍼블릭 엔드포인트를 제공합니다.
Traffic Manager는 DNS를 사용하여 트래픽 라우팅 방법에 따라 클라이언트 요청을 적절한 서비스 엔드포인트로 보냅니다. 또한 Traffic Manager는 모든 엔드포인트에 대한 상태 모니터링을 제공합니다. 엔드포인트는 Azure의 내부 또는 외부에서 호스팅되는 인터넷 연결 서비스일 수 있습니다. Traffic Manager는 다양한 애플리케이션 요구와 자동 장애 조치(failover)에 맞는 트래픽 라우팅 방법 및 엔드포인트 모니터링 옵션을 제공합니다. Traffic Manager는 전체 Azure 지역의 오류를 포함한, 오류에 대해 복원력을 갖습니다.
다중 지역 지리의 재해 복구
DNS는 네트워크 트래픽을 전환하는 가장 효율적인 메커니즘 중 하나입니다. DNS는 종종 전역적이고 데이터 센터 외부에 있기 때문에 효율적입니다. DNS는 또한 모든 지역 또는 AZ(가용성 영역) 수준 오류로부터 보호됩니다.
재해 복구 아키텍처 설정에는 두 가지 기술적인 측면이 있습니다.
배포 메커니즘을 사용하여 주 및 대기 환경 간에 인스턴스, 데이터 및 구성 복제. 이러한 형식의 재해 복구는 기본적으로 Azure Site Recovery를 통해 수행할 수 있습니다. Veritas 또는 NetApp과 같은 Microsoft Azure 파트너 어플라이언스/서비스를 통해 Azure Site Recovery 설명서를 참조하세요.
주 사이트에서 대기 사이트로 네트워크/웹 트래픽을 전환하는 솔루션 개발. 이 유형의 재해 복구는 Azure DNS, Azure Traffic Manager(DNS) 또는 타사 전역 부하 분산 장치를 통해 수행할 수 있습니다.
이 문서에서는 특히 Azure Traffic Manager 재해 복구 계획에 중점을 둡니다.
중단 검색, 알림 및 관리
재해가 발생하는 동안 기본 엔드포인트가 프로브되고 상태가 성능 저하로 변경되고 재해 복구 사이트는 온라인 상태로 유지됩니다. 기본적으로 Traffic Manager는 모든 트래픽을 기본(가장 높은 우선 순위) 엔드포인트로 전송합니다. 기본 엔드포인트의 성능이 저하된 것으로 보이면 Traffic Manager는 트래픽을 정상 상태인 두 번째 엔드포인트로 라우팅합니다. 추가 장애 조치(failover) 엔드포인트로 또는 엔드포인트 간에 부하를 공유하는 부하 분산 장치로 사용할 수 있는 Traffic Manager 내에서 더 많은 엔드포인트를 구성할 수 있습니다.
재해 복구 및 중단 검색 설정
동일한 기능을 수행할 수 있는 복잡한 아키텍처 및 여러 리소스 집합이 있는 경우 리소스의 상태를 확인하고 비정상 리소스에서 정상 리소스로 트래픽을 라우팅하도록 Azure Traffic Manager(DNS 기반)를 구성할 수 있습니다.
다음 예제에서 주 지역 및 보조 지역에는 각각 전체 배포가 있습니다. 이 배포에는 클라우드 서비스와 동기화된 데이터베이스가 포함됩니다.
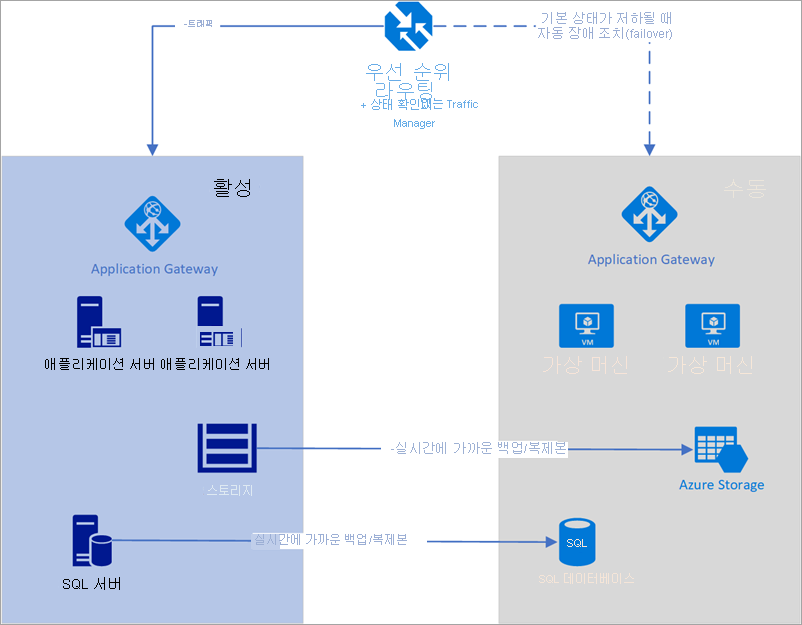
‘그림 - Azure Traffic Manager를 사용한 자동 장애 조치(failover)’
그러나 주 지역만이 사용자의 네트워크 요청을 활발히 처리합니다. 보조 지역은 주 지역에서 서비스 중단이 발생하는 경우에만 활성화됩니다. 이 경우에 모든 새로운 네트워크 요청은 보조 지역으로 라우팅됩니다. 데이터베이스 백업은 거의 즉각적으로 이루어지고, 부하 분산 장치에는 상태를 확인할 수 있는 IP가 포함되고, 인스턴스는 항상 실행 중이므로, 이 토폴로지는 수동 개입 없이 낮은 RTO 및 장애 조치(failover)를 적용하는 옵션을 제공합니다. 보조 장애 조치(failover) 지역은 주 지역에 장애가 발생한 후 즉시 활성화할 준비가 되어야 합니다.
http/https 및 TCP를 포함하여 다양한 유형의 상태 확인을 위한 내장 프로브가 있는 Azure Traffic Manager를 사용하는 경우, 이 시나리오가 가장 적합합니다. Azure Traffic Manager에는 아래 설명된 대로 장애가 발생할 경우 장애 조치(failover)를 수행하도록 구성할 수 있는 규칙 엔진도 있습니다. Traffic Manager를 사용하는 다음 솔루션을 살펴보겠습니다.
- 고객에게는 정적 IP가 100.168.124.44인 지역 #1 엔드포인트 prod.contoso.com 및 정적 IP가 100.168.124.43인 지역 #2 엔드포인트 dr.contoso.com이 있습니다.
- 이러한 각 환경은 부하 분산 장치 같은 공용 주소 속성을 통해 제어됩니다. 위에 표시된 대로 부하 분산 장치는 DNS 기반 엔드포인트 또는 FQDN(정규화된 도메인 이름)을 포함하도록 구성할 수 있습니다.
- 지역 2의 모든 인스턴스는 지역 1에서 실시간으로 복제됩니다. 또한 머신 이미지는 최신 상태이고 모든 소프트웨어/구성 데이터는 패치되고 지역 1과 일치합니다.
- 자동 크기 조정은 미리 구성되어 있습니다.
Azure Traffic Manager를 사용하여 장애 조치(failover)를 구성하려면:
새 Azure Traffic Manager 프로필 만들기 contoso123이라는 이름으로 새 Azure Traffic Manager 프로필을 만들고 라우팅 방법을 우선 순위로 선택합니다. 연결할 기존 리소스 그룹이 있는 경우 기존 리소스 그룹을 선택하고, 없는 경우에는 새 리소스 그룹을 만듭니다.
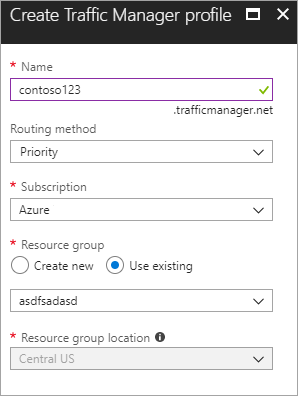
그림 - Traffic Manager 프로필 만들기
Traffic Manager 프로필 내에서 엔드포인트 만들기
이 단계에서는 프로덕션 및 재해 복구 사이트를 가리키는 엔드포인트를 만듭니다. 여기서 유형을 외부 엔드포인트로 선택하지만, 리소스가 Azure에서 호스트되는 경우 Azure 엔드포인트도 선택할 수 있습니다. Azure 엔드포인트를 선택한 경우, Azure에서 할당되는 App Service 또는 공용 IP 중에 대상 리소스를 선택합니다. 우선 순위는 지역 1의 주 서비스이므로 1로 설정됩니다. 마찬가지로 Traffic Manager 내에서도 재해 복구 엔드포인트를 만듭니다.
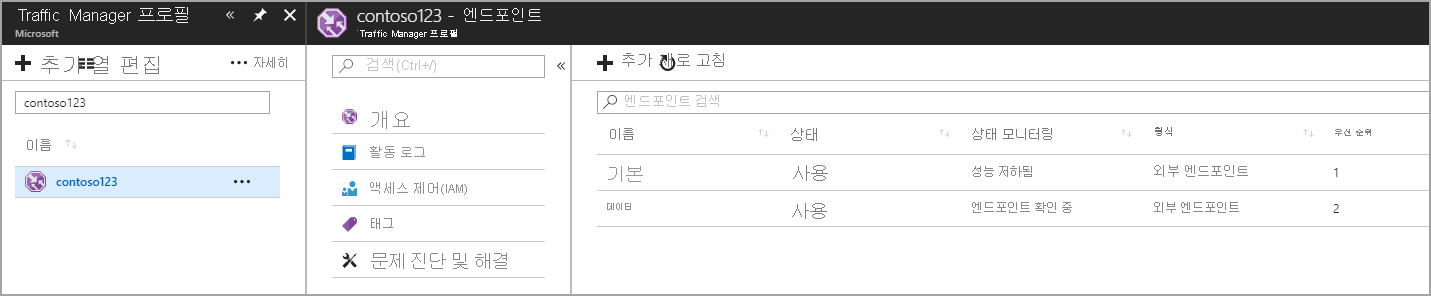
‘그림 - 재해 복구 엔드포인트 만들기’
상태 확인 및 장애 조치(failover) 구성 설정
이 단계에서는 대부분의 인터넷 연결 재귀 확인자가 적용하는 10초로 DNS TTL을 설정합니다. 이 구성은 DNS 확인자가 10초 이상 정보를 캐시하지 않음을 의미합니다.
엔드포인트 모니터 설정의 경우 경로는 / 또는 루트의 현재 설정이지만, 경로를 평가하기 위해 엔드포인트 설정을 사용자 지정할 수 있습니다(예: prod.contoso.com/index).
아래 예제에서는 프로빙 프로토콜로서 https를 보여 줍니다. 그러나 http 또는 tcp를 선택할 수도 있습니다. 프로토콜 선택은 엔드 애플리케이션에 따라 달라집니다. 프로빙 간격은 빠른 프로빙을 가능하게 하는 10초로 설정되고 재시도는 3으로 설정됩니다. 결과적으로 3회 연속 간격으로 장애가 등록되는 경우 Traffic Manager는 두 번째 엔드포인트로 장애 조치(failover)됩니다.
다음 수식은 자동화된 장애 조치(failover)의 총 시간을 정의합니다.
Time for failover = TTL + Retry * Probing interval이 경우 값은 10 + 3 * 10 = 40초(최대)입니다.
재시도가 1로 설정되고 TTL이 10초로 설정된 경우 장애 조치(failover) 시간은 10 + 1 * 10 = 20초입니다.
가양성 또는 사소하고 일시적인 네트워크 문제로 인한 장애 조치(failover)를 수행하지 않으려면 재시도를 1보다 큰 값으로 설정합니다.
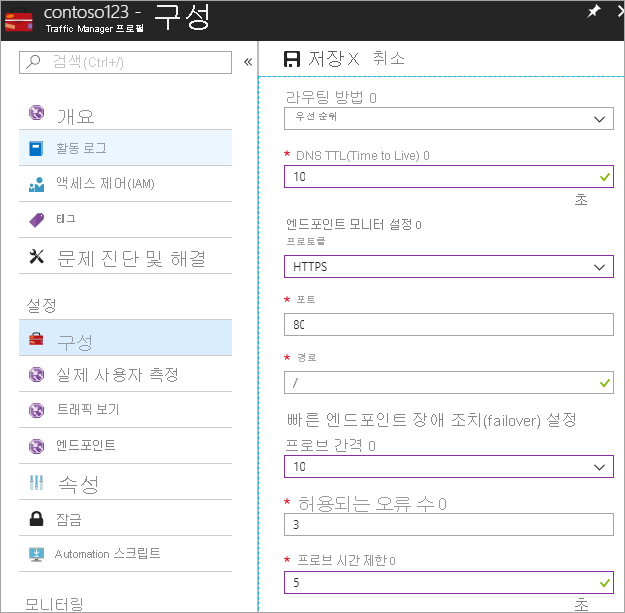
‘그림 - 상태 확인 및 장애 조치(failover) 구성 설정’
다음 단계
Azure Traffic Manager에 대해 자세히 알아보세요.
Azure DNS에 대해 자세히 알아봅니다.