Apache Spark Streaming 개요
Apache Spark 스트리밍은 HDInsight Spark 클러스터에서 데이터 스트림 처리를 제공합니다. 노드 실패가 발생하는 경우에도 입력 이벤트가 정확히 한 번 처리되도록 보장합니다. Spark Stream은 Azure Event Hubs를 포함하여 다양한 범위의 소스에서 입력 데이터를 받는 장기적인 작업입니다. 또한: Azure IoT Hub, Apache Kafka, Apache Flume, X, ZeroMQ원시 TCP 소켓 또는 Apache Hadoop YARN 파일 시스템 모니터링 단독 이벤트 기반 프로세스와는 달리 Spark Stream은 2초 조각과 같은 시간 창으로 입력 데이터를 일괄 처리한 다음 맵을 사용하여 데이터의 각 일괄 처리를 변환하고, 작업을 줄이고 조인하고 추출합니다. 그런 다음 Spark Stream은 변환된 데이터를 파일 시스템, 데이터베이스, 대시보드 및 콘솔에 기록합니다.
Spark Streaming 애플리케이션은 처리를 위해 해당 일괄 처리를 보내기 전에 이벤트의 각 micro-batch를 수집하기 위해 잠시 기다려야 합니다. 반면, 이벤트 기반 애플리케이션은 각 이벤트를 즉시 처리합니다. Spark 스트리밍 대기 시간은 일반적으로 몇 초 이하입니다. 마이크로 일괄 처리 방법의 이점은 보다 효율적인 데이터 처리 및 간단한 집계 계산입니다.
DStream 소개
Spark 스트리밍은 DStream이라는 불연속화 스트림을 사용하여 들어오는 데이터의 연속 스트림을 나타냅니다. DStream은 Event Hubs나 Kafka와 같은 입력 원본으로부터 만들 수 있습니다. 또는 다른 DStream을 변환하여 만들 수도 있습니다.
DStream은 원시 이벤트 데이터를 기반으로 하는 추상화 계층을 제공합니다.
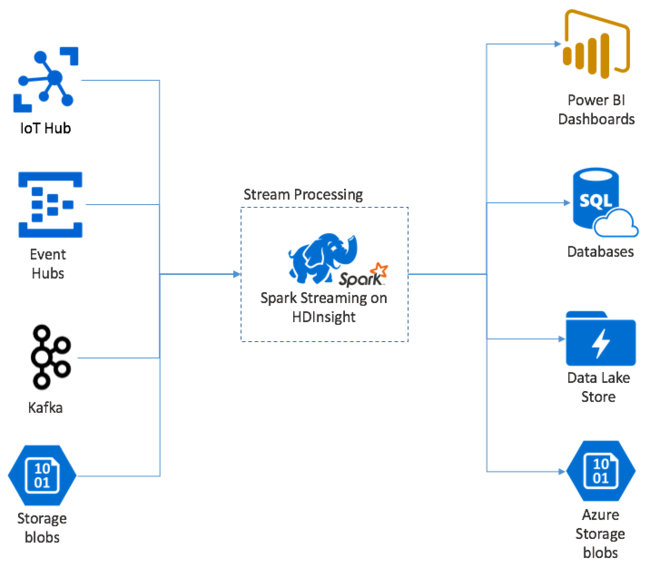
단일 이벤트로 시작하고, 연결된 자동 온도 조절기에서 읽는 온도를 말합니다. 이 이벤트가 Spark Streaming 애플리케이션에 도착하면 이벤트는 신뢰할 수 있는 방식으로, 즉 여러 노드에 복제되어 저장됩니다. 이 내결함성을 통해 단일 노드 실패로 인해 이벤트 손실이 발생되지 않도록 합니다. Spark 코어는 클러스터의 여러 노드에 걸쳐 데이터를 배포하는 데이터 구조를 사용합니다. 최상의 성능을 위해 각 노드는 일반적으로 자체 데이터를 메모리 내에 유지합니다. 이 데이터 구조는 RDD(복원력 있는 분산 데이터 세트)라고 합니다.
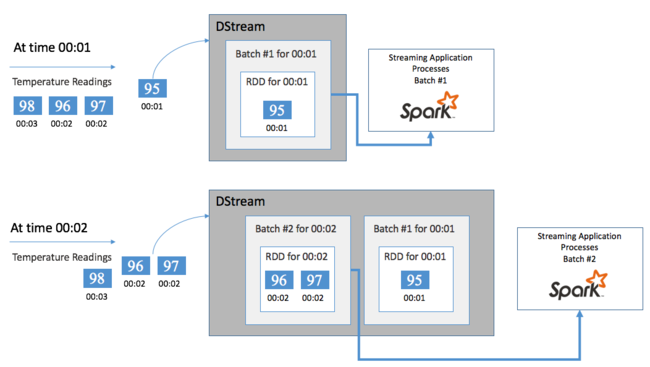
각 RDD는 일괄 처리 간격이라는 사용자 정의 시간 프레임을 통해 수집된 이벤트를 나타냅니다. 각 일괄 처리 간격이 지나면 해당 간격에서 모든 데이터를 포함하는 새 RDD가 생성됩니다. RDD의 연속 집합은 DStream으로 수집됩니다. 예를 들어 일괄 처리 간격이 1초 긴 경우 DStream에서 해당 초 동안 수집된 모든 데이터를 포함하는 하나의 RDD를 포함하는 일괄 처리를 매 초 내보냅니다. DStream을 처리할 때 이러한 일괄 처리 중 하나에 온도 이벤트가 나타납니다. Spark 스트리밍 애플리케이션은 이벤트를 포함하는 일괄 처리를 처리하고 각 RDD에 저장된 데이터에서 궁극적으로 작업을 수행합니다.
Spark 스트리밍 애플리케이션의 구조
Spark Streaming 애플리케이션은 장기 실행 애플리케이션으로 수집 원본으로부터 데이터를 받습니다. 데이터를 처리하기 위한 변환에 적용되며 그 후 데이터를 하나 이상의 대상으로 푸시합니다. Spark Streaming 애플리케이션의 구조에는 정적 부분과 동적 부분이 있습니다. 정적 부분은 데이터의 원본 위치와 데이터에서 수행할 처리를 정의합니다. 결과를 이동해야 할 위치를 지정합니다. 동적 부분은 정지 신호를 기다리며 애플리케이션을 무기한으로 실행합니다.
예를 들어, 다음과 같은 간단한 애플리케이션은 TCP 소켓을 통해 한 줄의 텍스트를 수신하고 각 단어가 나타나는 횟수를 계산합니다.
애플리케이션 정의
애플리케이션 논리 정의는 다음 4단계로 구성되어 있습니다.
- StreamingContext를 만듭니다.
- StreamingContext에서 DStream을 만듭니다.
- DStream에 변환을 적용합니다.
- 결과를 출력합니다.
이 정의는 정적이며 애플리케이션을 실행할 때까지 데이터가 처리되지 않습니다.
StreamingContext 만들기
클러스터를 가리키는 SparkContext에서 StreamingContext를 만듭니다. StreamingContext를 만들 때 초로 일괄 처리의 크기를 지정합니다. 예를 들어:
import org.apache.spark._
import org.apache.spark.streaming._
val ssc = new StreamingContext(sc, Seconds(1))
DStream 만들기
StreamingContext 인스턴스를 사용하여 입력 원본에 대한 입력 DStream을 만듭니다. 이 경우 애플리케이션은 연결된 기본 스토리지에서 새 파일의 출현을 확인합니다.
val lines = ssc.textFileStream("/uploads/Test/")
변환 적용
DStream에 변환을 적용하여 처리를 구현합니다. 이 애플리케이션은 파일에서 한번에 텍스트 한 줄을 받아 각 줄을 단어로 나눕니다. 그리고는 맵 감소 패턴을 사용하여 각 단어가 나타나는 횟수를 계산합니다.
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
출력 결과
출력 작업을 적용하여 대상 시스템에 변환 결과를 푸시합니다. 이 경우 계산을 통한 각 실행의 결과가 콘솔 출력에 출력 표시됩니다.
wordCounts.print()
애플리케이션 실행
스트리밍 애플리케이션을 시작하고 종료 신호를 받을 때까지 실행합니다.
ssc.start()
ssc.awaitTermination()
Spark Stream API에 대한 자세한 내용은 Apache Spark Streaming 프로그래밍 가이드를 참조하세요.
다음 샘플 애플리케이션은 자체 포함되어 있으므로 Jupyter Notebook 내에서 실행할 수 있습니다. 이 예제에서는 카운터의 값 및 5초마다 현재 시간(밀리초)을 출력하는 클래스 DummySource에서 모의 데이터 원본을 만듭니다. 새 StreamingContext 개체의 일괄 처리 간격은 30초입니다. 일괄 처리가 생성될 때마다 스트리밍 애플리케이션은 생산된 RDD를 검사합니다. 그 다음 RDD를 Spark DataFrame으로 변환하고 DataFrame에 대한 임시 테이블을 만듭니다.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process RDDs in the batch
stream.foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
위 애플리케이션을 시작한 후 30초 동안 기다립니다. 그런 다음, DataFrame을 정기적으로 쿼리하여 일괄 처리에 있는 값의 현재 집합을 확인할 수 있습니다. 예를 들어 다음 SQL 쿼리를 사용합니다.
%%sql
SELECT * FROM demo_numbers
결과 출력은 다음과 같이 표시됩니다.
| value | 시간 |
|---|---|
| 10 | 1497314465256 |
| 11 | 1497314470272 |
| 12 | 1497314475289 |
| 13 | 1497314480310 |
| 14 | 1497314485327 |
| 15 | 1497314490346 |
DummySource는 5초마다 하나의 값을 만들고 애플리케이션이 30초마다 하나의 일괄 처리를 내보내므로 6개의 값이 있습니다.
슬라이딩 창
특정 기간 동안 DStream에서 집계 계산을 수행하려는 경우(예: 지난 2초 동안 평균 온도를 얻기 위해) Spark Streaming에 포함된 sliding window 작업을 사용합니다. 슬라이딩 윈도우는 윈도우의 콘텐츠가 계산되는 기간(윈도우 길이) 및 간격(슬라이드 간격)이 있습니다.
이러한 슬라이딩 윈도우는 겹칠 수 있습니다. 예를 들어 1초마다 슬라이드하는 2초 길이로 윈도우를 정의할 수 있습니다. 즉 이 작업은 집계 계산을 수행할 때마다 윈도우는 이전 윈도우의 마지막 1초의 데이터를 포함합니다. 그리고 다음 1초의 모든 새 데이터도 포함합니다.
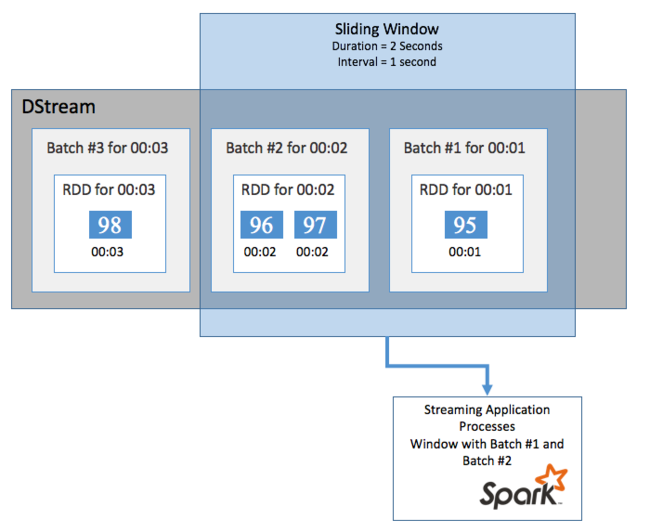
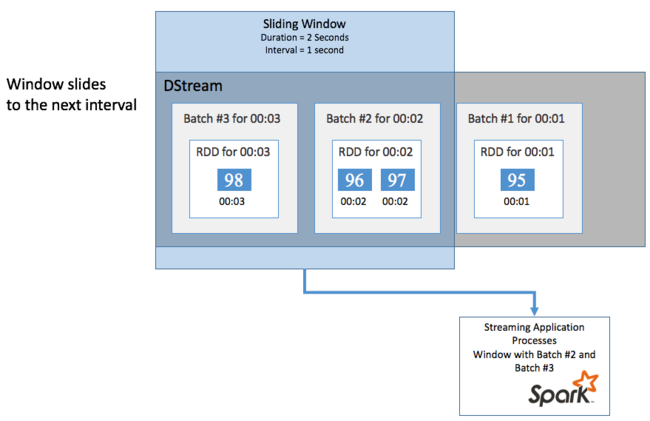
다음 예제에서는 1분의 기간, 1분의 슬라이드가 있는 창에 일괄 처리를 수집하도록 DummySource를 사용하는 코드를 업데이트합니다.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process batches in 1 minute windows
stream.window(org.apache.spark.streaming.Minutes(1)).foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
처음 1분 후 12개 항목(윈도우에서 수집한 두 개의 각 일괄 처리에서 6개 항목)이 생성됩니다.
| value | 시간 |
|---|---|
| 1 | 1497316294139 |
| 2 | 1497316299158 |
| 3 | 1497316304178 |
| 4 | 1497316309204 |
| 5 | 1497316314224 |
| 6 | 1497316319243 |
| 7 | 1497316324260 |
| 8 | 1497316329278 |
| 9 | 1497316334293 |
| 10 | 1497316339314 |
| 11 | 1497316344339 |
| 12 | 1497316349361 |
슬라이딩 윈도우 함수는 윈도우, countByWindow, reduceByWindow 및 countByValueAndWindow를 포함하여 Spark 스트리밍 API에서 사용할 수 있습니다. 이러한 함수에 대한 자세한 내용은 DStreams의 변환을 참조하세요.
검사점 설정
복원력 및 내결함성을 제공하기 위해 Spark Streaming은 노드 오류가 발생하는 경우에도 중단 없이 스트림 처리를 계속할 수 있도록 보장하는 검사점에 의존합니다. Spark는 영구 스토리지(Azure Storage 또는 Data Lake Storage)에 대한 검사점을 만듭니다. 이러한 검사점은 구성과 같은 스트리밍 애플리케이션 메타데이터와 애플리케이션에서 정의한 작업을 저장합니다. 또한 대기 중이었지만 아직 처리되지 않은 모든 일괄 처리도 저장합니다. 일부 경우에 검사점은 Spark에서 관리하는 RDD에 있는 것에서 데이터의 상태를 더 빠르게 다시 작성하도록 RDD에 데이터를 저장하는 것을 포함합니다.
Spark 스트리밍 애플리케이션 배포
일반적으로 Spark Streaming 애플리케이션은 JAR 파일에 로컬로 빌드합니다. 그런 다음 JAR 파일을 기본 연결된 스토리지로 복사하여 HDInsight의 Spark에 배포합니다. POST 작업을 사용하여 클러스터에서 사용할 수 있는 LIVY REST API를 통해 애플리케이션을 시작할 수 있습니다. POST의 본문에는 JAR에 대한 경로를 제공하는 JSON 문서가 포함되어 있습니다. main 메서드에서 스트리밍 애플리케이션을 정의하고 실행하는 클래스의 이름, 선택적으로 작업의 리소스 요구 사항(예: 실행기, 메모리 및 코어의 수)도 포함됩니다. 그 외에 애플리케이션 코드에 필요한 구성 설정도 있습니다.
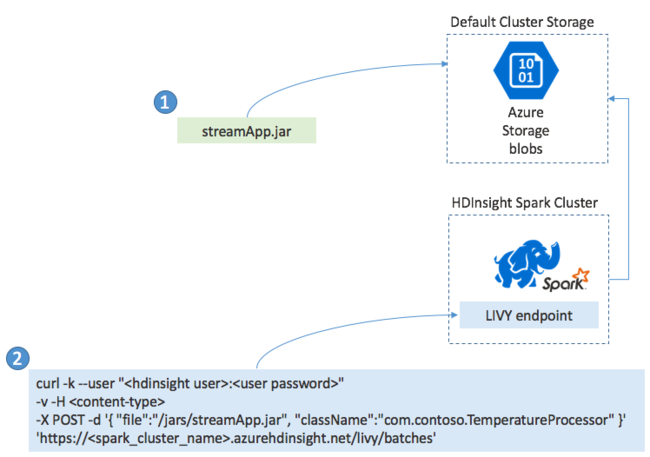
또한 LIVY 엔드포인트에 대한 GET 요청으로 모든 애플리케이션의 상태를 확인할 수 있습니다. 마지막으로 LIVY 엔드포인트에 대한 DELETE 요청을 실행하여 실행 중인 애플리케이션을 종료할 수 있습니다. LIVY API에 대한 자세한 내용은 Apache LIVY를 사용하는 원격 작업을 참조하세요.