자습서: Azure HDInsight에서 Apache Spark Machine Learning 애플리케이션 빌드
이 자습서에서는 Jupyter Notebook을 사용하여 Azure HDInsight에 대한 Apache Spark 기계 학습 애플리케이션을 빌드하는 방법을 알아봅니다.
MLlib는 일반적인 학습 알고리즘 및 유틸리티로 구성된 Spark의 적응형 기계 학습 라이브러리입니다. (분류, 회귀, 클러스터링, 협업 필터링 및 차원 축소. 또한 기본 최적화 기본 요소.)
이 자습서에서는 다음을 하는 방법을 알아볼 수 있습니다.
- Apache Spark 기계 학습 애플리케이션 개발
필수 조건
HDInsight의 Apache Spark. Apache Spark 클러스터 만들기를 참조하세요.
HDInsight의 Spark에서 Jupyter Notebook을 사용하는 방법 이해. 자세한 내용은 HDInsight의 Apache Spark로 데이터 로드 및 쿼리 실행을 참조하세요.
데이터 집합 이해
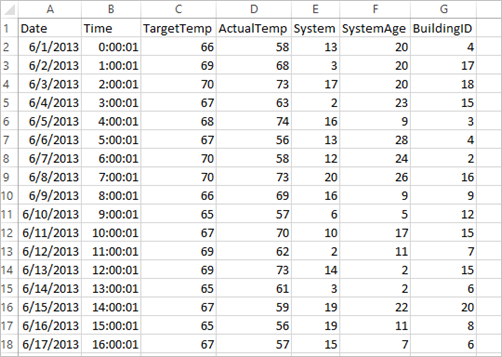
애플리케이션은 기본적으로 모든 클러스터에서 사용할 수 있는 샘플 HVAC.csv 데이터를 사용합니다. 파일은 \HdiSamples\HdiSamples\SensorSampleData\hvac에 있습니다. 이 데이터는 HVAC 시스템이 설치된 일부 건물의 목표 온도 및 실제 온도를 보여줍니다. System 열은 시스템 ID를 나타내고 SystemAge 열은 HVAC 시스템이 건물의 적절한 위치에 있었던 연수를 나타냅니다. 시스템 ID 및 시스템 연수가 지정된 상태에서 대상 온도를 기반으로 건물이 더 덥거나 추운지를 예측할 수 있습니다.
Spark MLlib를 사용하여 Spark Machine Learning 애플리케이션 개발
이 애플리케이션에는 문서 분류를 수행하는 데 ML 파이프라인을 사용합니다. ML Pipelines는 DataFrames를 기반으로 빌드된 균일한 고급 API 세트를 제공합니다. DataFrames를 통해 사용자는 실용적인 기계 학습 파이프라인을 만들고 튜닝할 수 있습니다. 파이프라인에서 기능 벡터 및 레이블을 사용하여 문서를 단어로 분할하고, 단어를 숫자 기능 벡터로 변환하며, 마지막으로 예측 모델을 빌드합니다. 다음 단계에 따라 애플리케이션을 만듭니다.
PySpark 커널을 사용하여 Jupyter Notebook을 만듭니다. 지침은 Jupyter Notebook 파일 만들기를 참조하세요.
이 시나리오에 필요한 형식을 가져옵니다. 빈 셀에 다음 코드 조각을 붙여넣은 다음 SHIFT + ENTER를 누릅니다.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row import os import sys from pyspark.sql.types import * from pyspark.mllib.classification import LogisticRegressionWithLBFGS from pyspark.mllib.regression import LabeledPoint from numpy import array데이터(hvac.csv)를 로드하고, 구문 분석하고, 모델 학습에 사용합니다.
# Define a type called LabelDocument LabeledDocument = Row("BuildingID", "SystemInfo", "label") # Define a function that parses the raw CSV file and returns an object of type LabeledDocument def parseDocument(line): values = [str(x) for x in line.split(',')] if (values[3] > values[2]): hot = 1.0 else: hot = 0.0 textValue = str(values[4]) + " " + str(values[5]) return LabeledDocument((values[6]), textValue, hot) # Load the raw HVAC.csv file, parse it using the function data = sc.textFile("/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") documents = data.filter(lambda s: "Date" not in s).map(parseDocument) training = documents.toDF()코드 조각에서 목표 온도와 실제 온도를 비교하는 함수를 정의합니다. 실제 온도가 큰 경우 건물이 더운 것이고 값이 1.0으로 표시됩니다. 그렇지 않으면 건물이 추운 것이고, 값이 0.0으로 표시됩니다.
tokenizer,hashingTF, andlr의 세 단계로 구성된 Spark 기계 학습 파이프라인을 구성합니다.tokenizer = Tokenizer(inputCol="SystemInfo", outputCol="words") hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features") lr = LogisticRegression(maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])파이프라인 및 작동 방법에 대한 자세한 내용은 Apache Spark Machine Learning 파이프라인을 참조하세요.
학습 문서에 파이프라인을 맞춥니다.
model = pipeline.fit(training)학습 문서를 확인하여 애플리케이션 진행 상태의 검사점을 설정합니다.
training.show()는 다음과 유사하게 출력됩니다.
+----------+----------+-----+ |BuildingID|SystemInfo|label| +----------+----------+-----+ | 4| 13 20| 0.0| | 17| 3 20| 0.0| | 18| 17 20| 1.0| | 15| 2 23| 0.0| | 3| 16 9| 1.0| | 4| 13 28| 0.0| | 2| 12 24| 0.0| | 16| 20 26| 1.0| | 9| 16 9| 1.0| | 12| 6 5| 0.0| | 15| 10 17| 1.0| | 7| 2 11| 0.0| | 15| 14 2| 1.0| | 6| 3 2| 0.0| | 20| 19 22| 0.0| | 8| 19 11| 0.0| | 6| 15 7| 0.0| | 13| 12 5| 0.0| | 4| 8 22| 0.0| | 7| 17 5| 0.0| +----------+----------+-----+원시 CSV 파일에 대한 출력을 비교합니다. 예를 들어 CSV 파일의 첫 번째 행에는 다음 데이터가 있습니다.

실제 온도가 건물이 춥다는 것을 의미하는 대상 온도보다 얼마나 작은지 확인합니다. 첫 번째 행의 label 값이 0.0이며, 이는 건물이 덥지 않다는 것을 의미합니다.
학습된 모델에 대해 실행할 데이터 집합을 준비합니다. 이렇게 하려면 시스템 ID 및 시스템 사용 기간(학습 출력에 SystemInfo로 표시됨)을 전달합니다. 모델은 해당 시스템 ID와 시스템 사용 기간이 있는 건물이 더 뜨거워질지(1.0으로 표시됨) 또는 더 차가워질지(0.0으로 표시됨) 여부를 예측합니다.
# SystemInfo here is a combination of system ID followed by system age Document = Row("id", "SystemInfo") test = sc.parallelize([("1L", "20 25"), ("2L", "4 15"), ("3L", "16 9"), ("4L", "9 22"), ("5L", "17 10"), ("6L", "7 22")]) \ .map(lambda x: Document(*x)).toDF()마지막으로 테스트 데이터에서 예측을 수행합니다.
# Make predictions on test documents and print columns of interest prediction = model.transform(test) selected = prediction.select("SystemInfo", "prediction", "probability") for row in selected.collect(): print (row)는 다음과 유사하게 출력됩니다.
Row(SystemInfo=u'20 25', prediction=1.0, probability=DenseVector([0.4999, 0.5001])) Row(SystemInfo=u'4 15', prediction=0.0, probability=DenseVector([0.5016, 0.4984])) Row(SystemInfo=u'16 9', prediction=1.0, probability=DenseVector([0.4785, 0.5215])) Row(SystemInfo=u'9 22', prediction=1.0, probability=DenseVector([0.4549, 0.5451])) Row(SystemInfo=u'17 10', prediction=1.0, probability=DenseVector([0.4925, 0.5075])) Row(SystemInfo=u'7 22', prediction=0.0, probability=DenseVector([0.5015, 0.4985]))예측의 첫 번째 행을 관찰합니다. ID가 20이고 시스템 사용 기간이 25년인 HVAC 시스템의 경우 건물이 덥습니다(prediction=1.0). DenseVector(0.49999)에 대한 첫 번째 값은 예측 0.0에 해당하고 두 번째 값(0.5001)은 예측 1.0에 해당합니다. 출력에서 두 번째 값이 약간만 높더라도 모델은 prediction=1.0을 보여 줍니다.
Notebook을 종료하여 리소스를 해제합니다. 이렇게 하기 위해 Notebook의 파일 메뉴에서 닫기 및 중지를 선택합니다. 그러면 Notebook이 종료된 후 닫힙니다.
Spark 기계 학습에 대한 Anaconda scikit-learn 라이브러리 사용
HDInsight에서 Apache Spark 클러스터에는 Anaconda 라이브러리가 포함되어 있습니다. Machine Learning에 대한 scikit-learn 라이브러리도 있습니다. 또한 라이브러리에는 Jupyter Notebook에서 직접 샘플 애플리케이션을 빌드하는 데 사용할 수 있는 다양한 데이터 세트가 포함되어 있습니다. scikit-learn 라이브러리 사용에 대한 예제는 https://scikit-learn.org/stable/auto_examples/index.html을 참조하세요.
리소스 정리
이 애플리케이션을 계속 사용할 계획이 없으면 다음 단계에 따라 생성된 클러스터를 삭제합니다.
Azure Portal에 로그인합니다.
맨 위에 있는 검색 상자에 HDInsight를 입력합니다.
서비스에서 HDInsight 클러스터를 선택합니다.
표시되는 HDInsight 클러스터 목록에서 이 자습서용으로 만든 클러스터 옆에 있는 ...를 선택합니다.
삭제를 선택합니다. 예를 선택합니다.
다음 단계
이 자습서에서는 Jupyter Notebook을 사용하여 Azure HDInsight에 대한 Apache Spark Machine Learning 애플리케이션을 빌드하는 방법을 알아보았습니다. 다음 자습서로 이동하여 Spark용 IntelliJ IDEA 작업을 사용하는 방법을 알아봅니다.