Azure HDInsight를 사용하여 Apache Hadoop HDFS 문제 해결
HDFS(Hadoop 분산 파일 시스템)를 사용할 때의 주요 문제 및 해결 방법을 알아봅니다. 명령의 전체 목록은 HDFS 명령 가이드 및 파일 시스템 셸 가이드를 참조하세요.
클러스터 내부에서 로컬 HDFS에 액세스하는 방법
문제
HDInsight 클러스터 내에서 Azure Blob Storage 또는 Azure Data Lake Storage를 사용하는 대신, 명령줄 및 애플리케이션 코드에서 로컬 HDFS에 액세스합니다.
해결 단계
다음 명령과 같이 명령 프롬프트에서
hdfs dfs -D "fs.default.name=hdfs://mycluster/" ...를 그대로 사용합니다.hdfs dfs -D "fs.default.name=hdfs://mycluster/" -ls / Found 3 items drwxr-xr-x - hdiuser hdfs 0 2017-03-24 14:12 /EventCheckpoint-30-8-24-11102016-01 drwx-wx-wx - hive hdfs 0 2016-11-10 18:42 /tmp drwx------ - hdiuser hdfs 0 2016-11-10 22:22 /user다음 예제 애플리케이션과 같이 소스 코드에서 URI
hdfs://mycluster/를 그대로 사용합니다.import java.io.IOException; import java.net.URI; import org.apache.commons.io.IOUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; public class JavaUnitTests { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String hdfsUri = "hdfs://mycluster/"; conf.set("fs.defaultFS", hdfsUri); FileSystem fileSystem = FileSystem.get(URI.create(hdfsUri), conf); RemoteIterator<LocatedFileStatus> fileStatusIterator = fileSystem.listFiles(new Path("/tmp"), true); while(fileStatusIterator.hasNext()) { System.out.println(fileStatusIterator.next().getPath().toString()); } } }다음 명령을 사용하여 HDInsight 클러스터에서 컴파일된 .jar 파일(예:
java-unit-tests-1.0.jar)을 실행합니다.hadoop jar java-unit-tests-1.0.jar JavaUnitTests hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.info hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.lck hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.info hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.lck
Blob에서 쓰기를 위한 스토리지 예외
문제
hadoop 또는 hdfs dfs 명령을 사용하여 HBase 클러스터에 12GB를 초과하는 데이터를 기록하면 다음 오류가 발생할 수 있습니다.
ERROR azure.NativeAzureFileSystem: Encountered Storage Exception for write on Blob : example/test_large_file.bin._COPYING_ Exception details: null Error Code : RequestBodyTooLarge
copyFromLocal: java.io.IOException
at com.microsoft.azure.storage.core.Utility.initIOException(Utility.java:661)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:366)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:350)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: com.microsoft.azure.storage.StorageException: The request body is too large and exceeds the maximum permissible limit.
at com.microsoft.azure.storage.StorageException.translateException(StorageException.java:89)
at com.microsoft.azure.storage.core.StorageRequest.materializeException(StorageRequest.java:307)
at com.microsoft.azure.storage.core.ExecutionEngine.executeWithRetry(ExecutionEngine.java:182)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlockInternal(CloudBlockBlob.java:816)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlock(CloudBlockBlob.java:788)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:354)
... 7 more
원인
HDInsight의 HBase를 Azure Storage에 쓸 때 블록 크기는 기본적으로 256KB로 설정됩니다. HBase API 또는 REST API를 사용할 때는 잘 작동하는 반면 hadoop 또는 hdfs dfs 명령줄 유틸리티를 사용할 때 오류가 발생합니다.
해결
fs.azure.write.request.size를 사용하여 블록 크기를 더 크게 지정합니다. -D 매개 변수를 사용하여 사용량에 따라 이 수정 작업을 수행할 수 있습니다. hadoop 명령에서 이 매개 변수를 사용하는 예는 다음 명령과 같습니다.
hadoop -fs -D fs.azure.write.request.size=4194304 -copyFromLocal test_large_file.bin /example/data
Apache Ambari를 사용하여 fs.azure.write.request.size 값을 전역적으로 늘릴 수도 있습니다. 다음 단계에 따라 Ambari 웹 UI 값을 변경합니다.
브라우저에서 클러스터에 대한 Ambari 웹 UI로 이동합니다. URL은
https://CLUSTERNAME.azurehdinsight.net이며,CLUSTERNAME은 클러스터의 이름입니다. 메시지가 표시되면 클러스터의 관리자 이름 및 암호를 입력합니다.화면 왼쪽에서 HDFS를 선택한 다음 구성 탭을 선택합니다.
필터... 필드에
fs.azure.write.request.size를 입력합니다.값을 262144(256KB)에서 새 값으로 변경합니다. 예를 들어 4194304(4MB)로 변경합니다.
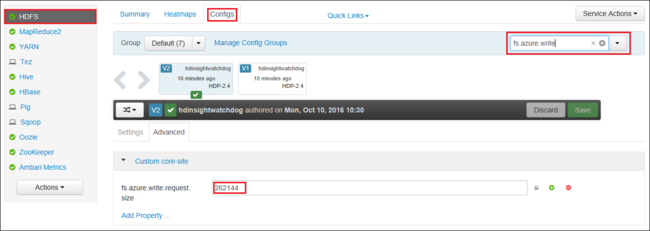
Ambari 사용에 대한 자세한 내용은 Apache Ambari 웹 UI를 사용하여 HDInsight 클러스터 관리를 참조하세요.
du
-du 명령은 지정된 디렉터리에 포함된 파일 및 디렉터리의 크기 또는 파일의 길이(파일일 경우)를 표시합니다.
-s 옵션은 표시되는 파일 길이에 대한 집계 요약을 생성합니다.
-h 옵션은 파일 크기의 형식을 지정합니다.
예시:
hdfs dfs -du -s -h hdfs://mycluster/
hdfs dfs -du -s -h hdfs://mycluster/tmp
rm
-rm 명령은 인수로 지정된 파일을 삭제합니다.
예시:
hdfs dfs -rm hdfs://mycluster/tmp/testfile
다음 단계
문제가 표시되지 않거나 문제를 해결할 수 없는 경우 다음 채널 중 하나를 방문하여 추가 지원을 받으세요.
Azure 커뮤니티 지원을 통해 Azure 전문가로부터 답변을 얻습니다.
사용자 환경을 개선하기 위한 공식 Microsoft Azure 계정인 @AzureSupport와 연결합니다. Azure 커뮤니티를 적절한 리소스(답변, 지원 및 전문가)에 연결합니다.
도움이 더 필요한 경우 Azure Portal에서 지원 요청을 제출할 수 있습니다. 메뉴 모음에서 지원을 선택하거나 도움말 + 지원 허브를 엽니다. 자세한 내용은 Azure 지원 요청을 만드는 방법을 참조하세요. 구독 관리 및 청구 지원에 대한 액세스 권한은 Microsoft Azure 구독에 포함되어 있으며, Azure 지원 플랜 중 하나를 통해 기술 지원이 제공됩니다.