Azure HDInsight에서 Apache Hive 쿼리를 최적화
이 문서에서는 Apache Hive 쿼리의 성능을 개선하는 데 사용할 수 있는 가장 일반적인 성능 최적화 중 일부를 설명합니다.
클러스터 유형 선택
Azure HDInsight에서는 몇 가지 다른 클러스터 형식으로 Apache Hive 쿼리를 실행할 수 있습니다.
워크로드 요구 사항에 맞게 성능을 최적화할 수 있도록 적절한 클러스터 유형을 선택합니다.
ad hoc대화형 쿼리를 최적화하려면 클러스터 유형을 선택합니다.- 일괄 처리 프로세스로 사용되는 Hive 쿼리를 최적화하려면 Apache Hadoop 클러스터 유형을 선택합니다.
- 또한 Spark 및 HBase 클러스터 유형은 Hive 쿼리를 실행할 수 있으며 해당 워크로드를 실행하는 경우 적합할 수 있습니다.
다양한 HDInsight 클러스터 유형에서 Hive 쿼리를 실행하는 방법에 자세한 내용은 Azure HDInsight의 Apache Hive 및 HiveQL이란?을 참조하세요.
작업자 노드 확장
HDInsight 클러스터의 작업자 노드 수를 늘리면 작업에서 더 많은 매퍼 및 감속기를 병렬로 실행할 수 있습니다. 스케일 인 HDInsight의 크기를 확장할 수 있는 두 가지 방법이 있습니다.
클러스터를 만들 때 Azure Portal, Azure PowerShell 또는 명령줄 인터페이스를 사용하여 작업자 노드 수를 지정할 수 있습니다. 자세한 내용은 HDInsight 클러스터 만들기를 참조하세요. 다음 스크린샷에는 Azure Portal의 작업자 노드 구성이 나와 있습니다.
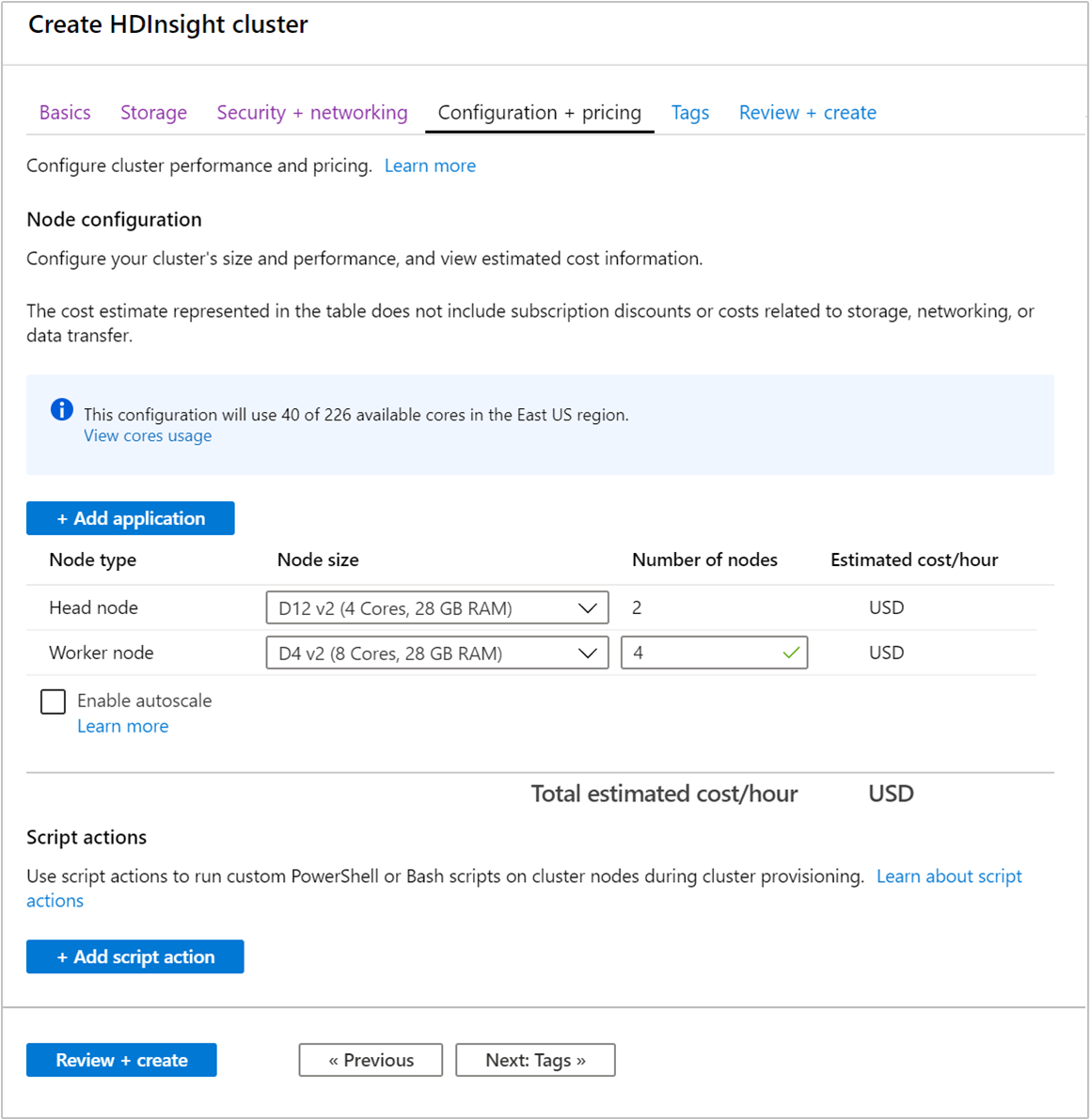
클러스터를 만든 후에는 작업자 노드 수를 편집하여 클러스터를 다시 만들지 않고도 클러스터 규모를 확장할 수도 있습니다.
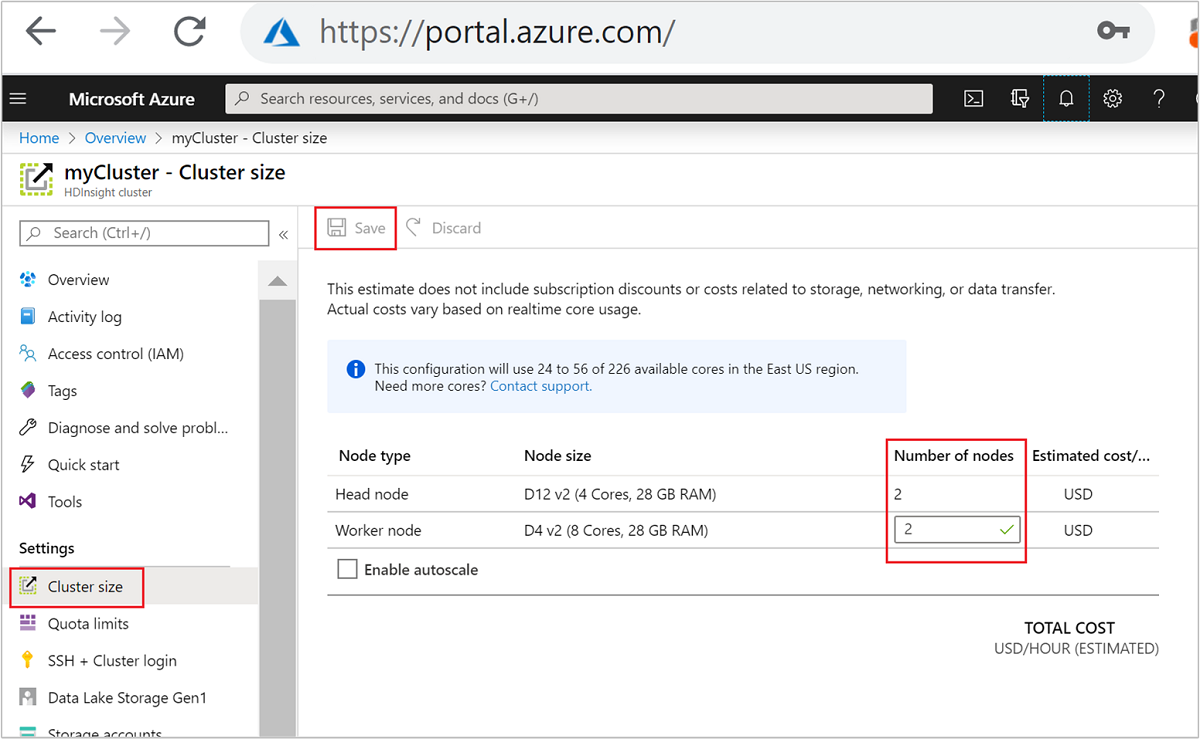
HDInsight 크기 조정에 대한 자세한 내용은 HDInsight 클러스터 크기 조정을 참조하세요.
Map Reduce 대신 Apache Tez 사용
Apache Tez는 MapReduce 엔진을 대신하는 실행 엔진입니다. Linux 기반 HDInsight 클러스터에는 Tez가 기본적으로 사용하도록 설정되어 있습니다.
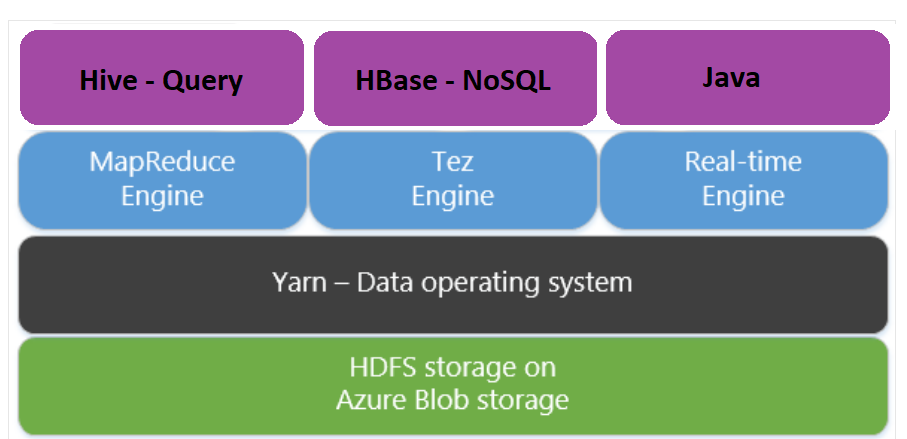
다음의 이유로 Tez가 훨씬 빠릅니다.
- MapReduce 엔진에서 DAG(Directed Acyclic Graph)를 단일 작업으로 실행합니다. DAG를 사용하려면 각 매퍼 세트 이후에 하나의 Reducer 세트가 뒤따라야 합니다. 이 요구 사항으로 인해 각 Hive 쿼리에 대해 여러 MapReduce 작업이 분리됩니다. Tez에는 이러한 제약 조건이 없으며 작업 시작 오버헤드를 최소화하는 하나의 작업으로 복잡한 DAG를 처리할 수 있습니다.
- 불필요한 쓰기를 방지합니다. MapReduce 엔진의 동일한 Hive 쿼리를 처리하기 위해 여러 작업이 사용됩니다. 각 MapReduce 작업의 출력은 중간 데이터를 위해 HDFS에 기록됩니다. Tez는 각 하이브 쿼리에 대한 작업 수를 최소화하므로 불필요한 쓰기를 피할 수 있습니다.
- 시작 지연을 최소화합니다. Tez는 시작하는 데 필요한 매퍼 수를 줄이고 전체 최적화를 개선하여 시작 지연을 최소화할 수 있습니다.
- 컨테이너를 다시 사용합니다. 가능하면 Tez는 컨테이너를 재사용하여 컨테이너 시작 대기 시간을 줄입니다.
- 연속 최적화 기술. 일반적으로 최적화는 컴파일 단계 중에 수행되었습니다. 런타임 중 더 나은 최적화를 허용하는 입력에 대한 자세한 정보를 제공합니다. Tez는 계획을 런타임 단계로 추가로 최적화할 수 있는 연속 최적화 기법을 사용합니다.
이러한 개념에 대한 자세한 내용은 Apache TEZ를 참조하세요.
다음 설정 명령을 사용하여 쿼리를 접두사로 지정하면 Tez가 사용되는 Hive 쿼리를 원하는 대로 만들 수 있습니다.
set hive.execution.engine=tez;
Hive 분할
I/O 작업은 Hive 쿼리 실행의 주요 성능 병목 상태입니다. 읽어야 하는 데이터 양을 줄일 수 있는 경우 성능이 향상 될 수 있습니다. 기본적으로 Hive 쿼리는 전체 Hive 테이블을 검사합니다. 그렇지만 적은 양의 데이터(예: 필터링된 쿼리)를 검색해야 하는 쿼리의 경우 이 동작은 불필요한 오버 헤드가 발생합니다. Hive 분할을 사용하면 Hive 쿼리가 Hive 테이블의에서 데이터를 필요한 만큼만 액세스할 수 있습니다.
Hive 분할은 원시 데이터를 새 디렉터리로 재구성하여 구현됩니다. 각 파티션은 자체 파일 디렉터리를 갖습니다. 사용자가 분할을 정의합니다. 다음 다이어그램에서는 Hive 테이블을 년 열로 분할하는 것을 보여 줍니다. 각 연도로 새 디렉터리가 생성됩니다.
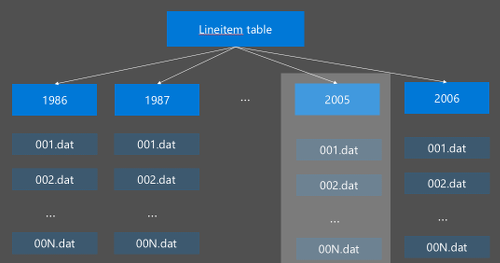
일부 분할 고려 사항:
- 언더 분할 안 함 - 몇 개의 값만 있는 열을 분할하면 파티션이 거의 생성되지 않을 수 있습니다. 예를 들어 성별을 분할하면 두 개의 파티션(남성과 여성)만 생성되므로 대기 시간이 최대 절반으로 줄어듭니다.
- 오버 분할 안 함 - 반대로 고유 값(예: userid)이 있는 열에서 분할을 만들면 여러 파티션이 생성됩니다. 오버 분할의 경우 많은 수의 디렉터리를 처리해야 하므로 클러스터 namenode에 과도한 스트레스가 발생합니다.
- 데이터 오차 방지 -모든 파티션의 크기가 고르도록 현명하게 분할 키를 선택합니다. 예를 들어 상태 열의 분할은 데이터 분포를 왜곡할 수 있습니다. 캘리포니아 주의 인구가 버몬트의 30배에 육박하므로 파티션 크기가 잠재적으로 왜곡되어 성능이 크게 달라질 수 있습니다.
파티션 테이블을 만들려면 Partitioned By 절을 사용합니다.
CREATE TABLE lineitem_part
(L_ORDERKEY INT, L_PARTKEY INT, L_SUPPKEY INT,L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
분할된 테이블을 만든 후 정적 분할 또는 동적 분할을 만들 수 있습니다.
정적 분할은 이미 적절한 디렉터리에 공유 데이터가 있다는 의미입니다. 정적 파티션을 사용하는 경우 디렉터리 위치에 따라 수동으로 Hive 파티션을 추가합니다. 다음 코드 조각은 예제로 제공됩니다.
INSERT OVERWRITE TABLE lineitem_part PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') SELECT * FROM lineitem WHERE lineitem.L_SHIPDATE = '5/23/1996 12:00:00 AM' ALTER TABLE lineitem_part ADD PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') LOCATION 'wasb://sampledata@ignitedemo.blob.core.windows.net/partitions/5_23_1996/'동적 분할 은 하이브가 파티션을 자동으로 만들수 있음을 의미합니다. 스테이징 테이블에서 분할 테이블을 이미 만들었으므로, 분할된 테이블에 데이터를 삽입하기만 하면 됩니다.
SET hive.exec.dynamic.partition = true; SET hive.exec.dynamic.partition.mode = nonstrict; INSERT INTO TABLE lineitem_part PARTITION (L_SHIPDATE) SELECT L_ORDERKEY as L_ORDERKEY, L_PARTKEY as L_PARTKEY, L_SUPPKEY as L_SUPPKEY, L_LINENUMBER as L_LINENUMBER, L_QUANTITY as L_QUANTITY, L_EXTENDEDPRICE as L_EXTENDEDPRICE, L_DISCOUNT as L_DISCOUNT, L_TAX as L_TAX, L_RETURNFLAG as L_RETURNFLAG, L_LINESTATUS as L_LINESTATUS, L_SHIPDATE as L_SHIPDATE_PS, L_COMMITDATE as L_COMMITDATE, L_RECEIPTDATE as L_RECEIPTDATE, L_SHIPINSTRUCT as L_SHIPINSTRUCT, L_SHIPMODE as L_SHIPMODE, L_COMMENT as L_COMMENT, L_SHIPDATE as L_SHIPDATE FROM lineitem;
자세한 내용은 분할된 테이블을 참조하세요.
ORCFile 형식 사용
Hive는 다양한 파일 형식을 지원합니다. 예시:
- 텍스트: 기본 파일 형식으로 대부분의 시나리오에서 작동합니다.
- Avro: 상호 운용성 시나리오에 대해 제대로 작동합니다.
- ORC/Parquet: 성능에 가장 적합합니다.
ORC(최적화된 행 칼럼 형식) 형식은 Hive 데이터를 저장하는 매우 효율적인 방법입니다. 다른 형식에 비해, ORC는 다음과 같은 이점이 있습니다.
- DateTime 및 복합 및 반정형 형식을 포함하는 복합 형식 지원
- 최대 70% 압축
- 행을 건너뛸 수 있는 10,000행마다 인덱스
- 런타임 실행 시 현저하게 감소
ORC 형식을 사용하려면 먼저 Stored as ORC절로 테이블을 만듭니다.
CREATE TABLE lineitem_orc_part
(L_ORDERKEY INT, L_PARTKEY INT,L_SUPPKEY INT, L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
STORED AS ORC;
다음으로 스테이징 테이블에서 ORC 테이블로 데이터를 삽입합니다. 예시:
INSERT INTO TABLE lineitem_orc
SELECT L_ORDERKEY as L_ORDERKEY,
L_PARTKEY as L_PARTKEY ,
L_SUPPKEY as L_SUPPKEY,
L_LINENUMBER as L_LINENUMBER,
L_QUANTITY as L_QUANTITY,
L_EXTENDEDPRICE as L_EXTENDEDPRICE,
L_DISCOUNT as L_DISCOUNT,
L_TAX as L_TAX,
L_RETURNFLAG as L_RETURNFLAG,
L_LINESTATUS as L_LINESTATUS,
L_SHIPDATE as L_SHIPDATE,
L_COMMITDATE as L_COMMITDATE,
L_RECEIPTDATE as L_RECEIPTDATE,
L_SHIPINSTRUCT as L_SHIPINSTRUCT,
L_SHIPMODE as L_SHIPMODE,
L_COMMENT as L_COMMENT
FROM lineitem;
Apache Hive 언어 설명서에서 ORC 형식에 대해 자세히 알아볼 수 있습니다.
벡터화
벡터화를 사용하면 Hive가 한번에 하나의 행을 처리하는 대신 함께 1024행을 일괄 처리할 수 있습니다. 즉, 실행할 내부 코드가 적기 때문에 간단한 작업은 더 빠르게 수행할 수 있습니다.
다음 설정을 사용하여 Hive 쿼리에 벡터화 접두사를 사용할 수 있도록 하려면:
set hive.vectorized.execution.enabled = true;
자세한 내용은 벡터화된 쿼리 실행을 참조하세요.
다른 최적화 방법
예를 들어 다음은 고려할 수 있는 추가 최적화 방법입니다.
- Hive 버킷팅: 대형 데이터 집합을 클러스터 또는 세그먼트하여 쿼리 성능을 최적화할 수 있는 기술입니다.
- 조인 최적화: 조인의 효율성을 높이고 사용자 힌트에 대한 필요성을 줄이는 Hive의 쿼리 실행 계획 최적화입니다. 자세한 내용은 조인 최적화를 참조하세요.
- 리듀서 증가
다음 단계
이 기사에서는 몇가지 일반적인 하이브 쿼리 최적화 방법을 배웠습니다. 자세한 내용은 다음 문서를 참조하세요.