Azure HDInsight에서 Apache Hadoop이란?
Apache Hadoop은 클러스터에서 빅 데이터 집합을 분산 처리하고 분석하기 위한 원래의 오픈 소스 프레임워크였습니다. Hadoop 에코시스템에는 Apache Hive, Apache HBase, Spark, Kafka 등 관련 소프트웨어 및 유틸리티가 포함되어 있습니다.
Azure HDInsight는 엔터프라이즈용 클라우드의 완전 관리형 전체 스펙트럼 오픈 소스 분석 서비스입니다. Azure HDInsight의 Apache Hadoop 클러스터 유형을 사용하면 Apache HDFS(Hadoop Distributed File System), Apache Hadoop YARN 리소스 관리 및 간단한 MapReduce 프로그래밍 모델을 통해 일괄처리 데이터를 병렬로 처리하고 분석할 수 있습니다. HDInsight의 Hadoop 클러스터는 Azure Data Lake Storage Gen2와 호환됩니다.
HDInsight에서 사용할 수 있는 Hadoop 기술 스택 구성 요소를 보려면 HDInsight에서 사용할 수 있는 구성 요소 및 버전을 참조하세요. HDInsight의 Hadoop에 대한 자세한 내용은 HDInsight에 대한 Azure 기능 페이지를 참조하세요.
MapReduce란
Apache Hadoop MapReduce는 방대한 양의 데이터를 처리하는 작업을 작성하기 위한 소프트웨어 프레임워크입니다. 입력 데이터는 독립적인 청크로 분할됩니다. 각 청크는 클러스터의 노드에서 동시에 처리됩니다. MapReduce 작업은 두 함수로 구성됩니다.
매퍼: 입력된 데이터를 소비하고 분석하며(일반적으로 필터 및 정렬 작업) 튜플을 내보냅니다.(키-값 쌍)
리듀서: 매퍼에서 나온 튜플을 소배하고 매퍼 데이터에서 더 작고 결합된 결과를 생성하는 요약 작업을 수행합니다.
다음 다이어그램에서는 기본 단어 계산 MapReduce 작업 예제를 보여줍니다.
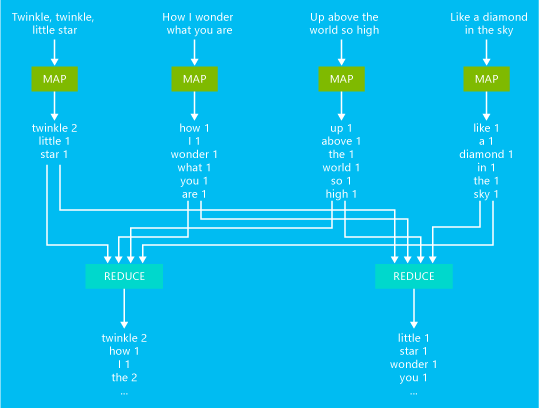
이 작업의 출력은 텍스트에서 각 단어가 발생한 횟수입니다.
- 매퍼는 입력 텍스트의 각 줄을 입력으로 가져오고 해당 줄을 단어로 구분합니다. 단어 뒤에 1이 표시되는 단어가 발생할 때마다 키/값 쌍을 내보냅니다. 리듀서로 보내기 전에 출력이 정렬됩니다.
- 리듀서가 각 단어의 개별 발생 수를 합산하고 단어 뒤에 발생 합계가 포함된 단일 키/값 쌍을 내보냅니다.
MapReduce는 다양한 언어로 구현할 수 있습니다. Java는 가장 일반적인 구현으로 해당 문서의 데모 용도로 사용됩니다.
개발 언어
Java 및 Java Virtual Machine을 기반으로 하는 언어 또는 프레임워크는 MapReduce 작업으로 직접 실행할 수 있습니다. 이 문서에서 사용된 예는 Java MapReduce 애플리케이션입니다. C#, Python, 독립 실행형 실행 파일 등의 비-Java 언어는 Hadoop 스트리밍을 사용해야 합니다.
Hadoop 스트리밍은 STDIN 및 STDOUT을 통해 매퍼 및 리듀서와 통신합니다. 매퍼와 리듀서는 STDIN에서 한 번에 한 줄씩 데이터를 읽고 STDOUT에 출력을 씁니다. 매퍼 및 리듀서가 읽거나 내보낸 각 줄은 탭 문자로 구분된 키/값 쌍의 형식이어야 합니다.
[key]\t[value]
자세한 내용은 Hadoop 스트리밍을 참조하세요.
HDInsight와 함께 Hadoop 스트리밍을 사용하는 예제는 다음 문서를 참조하세요.
어디에서 시작할 수 있나요?
- 빠른 시작: Azure Portal을 사용하여 Azure HDInsight에서 Apache Hadoop 클러스터 만들기
- 자습서: HDInsight에서 Apache Hadoop 작업 제출
- HDInsight에서 Apache Hadoop용 Java MapReduce 프로그램 개발
- Apache Hive를 ETL(추출, 변환 및 로드) 도구로 사용
- 규모에 맞게 ETL(추출, 변환 및 로드)
- 데이터 분석 파이프라인 운영