HDInsight의 Apache Hadoop에서 Apache Hive 및 Apache Pig와 함께 C# 사용자 정의 함수 사용
HDInsight에서 Apache Hive 및 Apache Pig와 함께 C# UDF(사용자 정의 함수)를 사용하는 방법을 알아봅니다.
Important
이 문서의 단계는 Linux 기반 HDInsight 클러스터에 적용됩니다. Linux는 HDInsight 버전 3.4 이상에서 사용되는 유일한 운영 체제입니다. 자세한 내용은 HDInsight 구성 요소 버전 관리를 참조하세요.
Hive 및 Pig 모두 외부 애플리케이션으로 데이터를 전달해 처리할 수 있습니다. 이 프로세스를 스트리밍이라고 합니다. .NET 애플리케이션을 사용하는 경우 데이터는 STDIN의 애플리케이션에 전달되고 애플리케이션은 STDOUT에서 결과를 반환합니다. STDIN 및 STDOUT에서 읽거나 쓰려면 콘솔 애플리케이션에서 Console.ReadLine() 및 Console.WriteLine()을 사용할 수 있습니다.
필수 조건
.NET Framework 4.5를 대상으로 하는 C# 코드 작성 및 빌드에 대해 잘 알고 있어야 합니다.
원하는 IDE를 사용합니다. Visual Studio 또는 Visual Studio Code를 권장합니다. 이 문서의 단계는 Visual Studio 2019를 사용합니다.
.exe 파일을 클러스터로 업로드하고 Pig 및 Hive 작업을 실행하는 방법. Data Lake Tools for Visual Studio, Azure PowerShell 및 Azure CLI를 권장합니다. 이 문서의 단계는 Data Lake Tools for Visual Studio를 사용하여 파일을 업로드하고 예제 Hive 쿼리를 실행합니다.
Hive 쿼리를 실행하는 다른 방법에 대한 자세한 내용은 Azure HDInsight의 Apache Hive 및 HiveQL이란?을 참조하세요.
HDInsight 클러스터의 Hadoop. 클러스터를 만드는 방법에 대한 자세한 내용은 HDInsight 클러스터 만들기를 참조하세요.
HDInsight에서.NET
Linux 기반 HDInsight 클러스터는 Mono(https://mono-project.com)를 사용하여 .NET 애플리케이션을 실행합니다. Mono 버전 4.2.1은 HDInsight 버전 3.6에 포함되어 있습니다.
.NET 프레임워크 버전과 Mono의 호환성에 대한 자세한 내용은 Mono 호환성을 참조하세요.
.NET Framework 버전 및 HDInsight 버전과 함께 제공되는 Mono에 대한 자세한 내용은 HDInsight 구성 요소 버전을 참조하세요.
C# 프로젝트 만들기
다음 섹션에서는 Apache Hive UDF 및 Apache Pig UDF에 대해 Visual Studio에서 C# 프로젝트를 만드는 방법을 설명합니다.
Apache Hive UDF
Apache Hive UDF에 대한 C# 프로젝트를 만들려면 다음을 수행합니다.
Visual Studio를 시작합니다.
새 프로젝트 만들기를 선택합니다.
새 프로젝트 만들기 창에서 콘솔 앱(.NET Framework) 템플릿(C# 버전)을 선택합니다. 그런 후 다음을 선택합니다.
새 프로젝트 구성 창에서 HiveCSharp의 프로젝트 이름을 입력하고 새 프로젝트를 저장할 위치로 이동하거나 해당 위치를 만듭니다. 다음으로 만들기를 선택합니다.
Visual Studio IDE에서 Program.cs의 내용을 다음 코드로 바꿉니다.
using System; using System.Security.Cryptography; using System.Text; using System.Threading.Tasks; namespace HiveCSharp { class Program { static void Main(string[] args) { string line; // Read stdin in a loop while ((line = Console.ReadLine()) != null) { // Parse the string, trimming line feeds // and splitting fields at tabs line = line.TrimEnd('\n'); string[] field = line.Split('\t'); string phoneLabel = field[1] + ' ' + field[2]; // Emit new data to stdout, delimited by tabs Console.WriteLine("{0}\t{1}\t{2}", field[0], phoneLabel, GetMD5Hash(phoneLabel)); } } /// <summary> /// Returns an MD5 hash for the given string /// </summary> /// <param name="input">string value</param> /// <returns>an MD5 hash</returns> static string GetMD5Hash(string input) { // Step 1, calculate MD5 hash from input MD5 md5 = System.Security.Cryptography.MD5.Create(); byte[] inputBytes = System.Text.Encoding.ASCII.GetBytes(input); byte[] hash = md5.ComputeHash(inputBytes); // Step 2, convert byte array to hex string StringBuilder sb = new StringBuilder(); for (int i = 0; i < hash.Length; i++) { sb.Append(hash[i].ToString("x2")); } return sb.ToString(); } } }메뉴 모음에서 빌드>솔루션 빌드를 선택하여 프로젝트를 빌드합니다.
솔루션을 닫습니다.
Apache Pig UDF
Apache Hive UDF에 대한 C# 프로젝트를 만들려면 다음을 수행합니다.
Visual Studio를 엽니다.
시작 창에서 새 프로젝트 만들기를 선택합니다.
새 프로젝트 만들기 창에서 콘솔 앱(.NET Framework) 템플릿(C# 버전)을 선택합니다. 그런 후 다음을 선택합니다.
새 프로젝트 구성 창에서 PigUDF의 프로젝트 이름을 입력하고 새 프로젝트를 저장할 위치로 이동하거나 해당 위치를 만듭니다. 다음으로 만들기를 선택합니다.
Visual Studio IDE에서 Program.cs의 내용을 다음 코드로 바꿉니다.
using System; namespace PigUDF { class Program { static void Main(string[] args) { string line; // Read stdin in a loop while ((line = Console.ReadLine()) != null) { // Fix formatting on lines that begin with an exception if(line.StartsWith("java.lang.Exception")) { // Trim the error info off the beginning and add a note to the end of the line line = line.Remove(0, 21) + " - java.lang.Exception"; } // Split the fields apart at tab characters string[] field = line.Split('\t'); // Put fields back together for writing Console.WriteLine(String.Join("\t",field)); } } } }이 코드는 Pig에서 보낸 줄을 구문 분석하고
java.lang.Exception로 시작하는 줄의 형식을 변경합니다.메뉴 모음에서 빌드>솔루션 빌드를 선택하여 프로젝트를 빌드합니다.
솔루션을 열어 둡니다.
스토리지에 업로드
그런 다음, Hive 및 Pig UDF 애플리케이션을 HDInsight 클러스터의 스토리지에 업로드합니다.
Visual Studio에서 보기>서버 탐색기로 이동합니다.
서버 탐색기에서 Azure를 마우스 오른쪽 단추로 클릭하고 Microsoft Azure 구독에 연결을 선택하여 로그인 프로세스를 완료합니다.
이 애플리케이션을 배포하려는 HDInsight 클러스터를 확장합니다. 텍스트가 포함된 항목(기본 Storage 계정)이 목록에 표시됩니다.
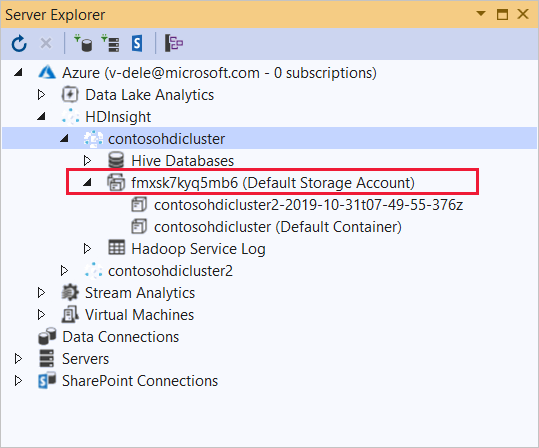
이 항목을 확장할 수 있는 경우 클러스터의 기본 스토리지로 Azure Storage 계정을 사용하고 있음을 의미합니다. 클러스터의 기본 스토리지에서 파일을 보려면 항목을 확장한 다음 (기본 컨테이너)를 두 번 클릭합니다.
이 항목을 확장할 수 없는 경우 클러스터의 기본 스토리지로 Azure Data Lake Storage를 사용하고 있음을 의미합니다. 클러스터의 기본 스토리지에 있는 파일을 보려면 항목을 확장한 다음 (기본 Storage 계정)을 두 번 클릭합니다.
.exe 파일을 업로드하려면 다음 방법 중 하나를 사용합니다.
Azure Storage 계정을 사용하는 경우 Blob 업로드 아이콘을 선택합니다.

새 파일 업로드 대화 상자에서 파일 이름 아래의 찾아보기를 선택합니다. Blob 업로드 대화 상자에서 HiveCSharp 프로젝트의 폴더로 이동
bin\debug한 다음 HiveCSharp.exe 파일을 선택합니다. 마지막으로 열기를 선택하고 확인을 선택하여 업로드를 완료합니다.Azure Data Lake Storage를 사용하는 경우 마우스 오른쪽 버튼으로 파일 목록의 빈 영역을 클릭한 다음, 업로드를 선택합니다. 마지막으로 HiveCSharp.exe 파일을 선택하고 열기를 선택합니다.
HiveCSharp.exe 업로드가 완료되면 PigUDF.exe 파일의 업로드 프로세스를 반복합니다.
Apache Hive 쿼리 실행
이제 Hive UDF 애플리케이션을 사용하는 Hive 쿼리를 실행할 수 있습니다.
Visual Studio에서 보기>서버 탐색기로 이동합니다.
Azure를 확장한 다음 HDInsight를 확장합니다.
HiveCSharp 애플리케이션을 배포한 클러스터를 마우스 오른쪽 단추로 클릭하고 Hive 쿼리 작성을 선택합니다.
Hive 쿼리로 다음 텍스트를 사용합니다.
-- Uncomment the following if you are using Azure Storage -- add file wasbs:///HiveCSharp.exe; -- Uncomment the following if you are using Azure Data Lake Storage Gen1 -- add file adl:///HiveCSharp.exe; -- Uncomment the following if you are using Azure Data Lake Storage Gen2 -- add file abfs:///HiveCSharp.exe; SELECT TRANSFORM (clientid, devicemake, devicemodel) USING 'HiveCSharp.exe' AS (clientid string, phoneLabel string, phoneHash string) FROM hivesampletable ORDER BY clientid LIMIT 50;Important
클러스터에 사용되는 기본 스토리지의 유형과 일치하는
add file문에서 주석 처리를 제거합니다.이 쿼리는
hivesampletable에서clientid,devicemake및devicemodel필드를 선택하고 해당 필드를 HiveCSharp.exe 애플리케이션으로 전달합니다. 쿼리는 애플리케이션이 3개의 필드를 반환할 것을 예상하며clientid,phoneLabel및phoneHash로 저장됩니다. 또한 쿼리는 기본 스토리지 컨테이너의 루트에서 HiveCSharp.exe를 찾는다고 예상합니다.기본 대화형을 배치로 전환하고 제출을 선택하여 HDInsight 클러스터에 작업을 제출합니다. Hive 작업 요약 창이 열립니다.
새로 고침을 선택하여 작업 상태가 완료로 변경될 때까지 요약을 새로 고칩니다. 작업 출력을 보려면 작업 출력을 선택합니다.
Apache Pig 작업 실행
Pig UDF 애플리케이션을 사용하는 Pig 작업을 실행할 수도 있습니다.
SSH를 사용하여 HDInsight 클러스터에 연결합니다. (예를 들어, 명령
ssh sshuser@<clustername>-ssh.azurehdinsight.net을 실행합니다.) 자세한 내용은 HDInsight에서 SSH 사용을 참조하세요.Pig 명령줄을 시작하려면 다음 명령을 사용합니다.
piggrunt>프롬프트가 표시됩니다..NET Framework 애플리케이션을 사용하는 Pig 작업을 실행하려면 다음을 입력합니다.
DEFINE streamer `PigUDF.exe` CACHE('/PigUDF.exe'); LOGS = LOAD '/example/data/sample.log' as (LINE:chararray); LOG = FILTER LOGS by LINE is not null; DETAILS = STREAM LOG through streamer as (col1, col2, col3, col4, col5); DUMP DETAILS;DEFINE문은 PigUDF.exe 애플리케이션에 대한streamer의 별칭을 만들고CACHE는 클러스터의 기본 스토리지에서 로드합니다. 나중에streamer는STREAM연산자와 함께 사용되어LOG에 포함된 단일 줄을 처리하고 일련의 열로 데이터를 반환합니다.참고 항목
스트리밍에 사용되는 애플리케이션 이름은 별칭이 지정된 경우
`(기호) 문자로 묶어야 하며SHIP와 함께 사용된 경우'(작은따옴표) 문자로 묶어야 합니다.마지막 줄을 입력하면 작업이 시작되어야 합니다. 다음 텍스트와 비슷한 출력이 반환됩니다.
(2019-07-15 16:43:25 SampleClass5 [WARN] problem finding id 1358451042 - java.lang.Exception) (2019-07-15 16:43:25 SampleClass5 [DEBUG] detail for id 1976092771) (2019-07-15 16:43:25 SampleClass5 [TRACE] verbose detail for id 1317358561) (2019-07-15 16:43:25 SampleClass5 [TRACE] verbose detail for id 1737534798) (2019-07-15 16:43:25 SampleClass7 [DEBUG] detail for id 1475865947)Pig를 종료하는 데
exit를 사용합니다.
다음 단계
이 문서에서는 HDInsight의 Hive 및 Pig에서 .NET Framework 애플리케이션을 사용하는 방법에 대해 배웠습니다. Python을 Hive 및 Pig와 함께 사용하는 방법에 대해 알고 싶으면 HDInsight에서 Apache Hive 및 Apache Pig와 함께 Python 사용을 참조하세요.
Hive를 사용하고 MapReduce 사용에 대해 배우는 다른 방법은 다음 문서를 참조하세요.