자습서: NFS를 통해 Azure Data Box Heavy에 데이터 복사
이 자습서에서는 로컬 웹 UI를 사용하여 호스트 컴퓨터에서 Azure Data Box Heavy로 연결하고 데이터를 복사하는 방법을 설명합니다.
이 자습서에서는 다음을 하는 방법을 알아볼 수 있습니다.
- 필수 조건
- Data Box Heavy에 연결
- Data Box Heavy에 데이터 복사
필수 조건
시작하기 전에 다음 사항을 확인합니다.
- 자습서: Azure Data Box Heavy 설정을 완료했습니다.
- Data Box Heavy를 받았고 포털의 주문 상태가 배달됨입니다.
- Data Box Heavy에 복사할 데이터가 포함된 호스트 컴퓨터가 있습니다. 호스트 컴퓨터는 다음 사항이 필수입니다.
- 지원되는 운영 체제를 실행합니다.
- 고속 네트워크에 연결되어 있어야 합니다. 가장 빠른 복사 속도를 위해 40GbE 연결 2개(노드당 1개)를 병렬로 이용할 수 있습니다. 사용 가능한 40GbE 연결이 없는 경우 10GbE 연결이 2개(노드당 1개) 이상 있는 것이 좋습니다.
Data Box Heavy에 연결
선택한 스토리지 계정에 따라 Data Box Heavy에서 만드는 최대 항목 수는 다음과 같습니다.
- GPv1 및 GPv2에서 연결된 각 스토리지에 대한 공유 3개.
- Premium Storage에 대한 공유 1개
- Blob 스토리지 계정에 대한 공유 1개
해당 공유는 디바이스의 두 노드에 모두 생성됩니다.
블록 Blob 및 페이지 Blob 공유 아래:
- 첫 번째 수준 엔터티는 컨테이너입니다.
- 두 번째 수준 엔터티는 Blob입니다.
Azure Files에 대한 공유 아래:
- 첫 번째 수준 엔터티는 공유입니다.
- 두 번째 수준 엔터티는 파일입니다.
다음 표는 데이터가 업로드되는 Data Box Heavy 및 Azure Storage 경로 URL의 공유에 대한 UNC 경로를 보여줍니다. 최종 Azure Storage 경로 URL은 UNC 공유 경로에서 파생될 수 있습니다.
| 스토리지 | UNC 경로 |
|---|---|
| Azure 블록 Blob | //<DeviceIPAddress>/<StorageAccountName_BlockBlob>/<ContainerName>/files/a.txthttps://<StorageAccountName>.blob.core.windows.net/<ContainerName>/files/a.txt |
| Azure 페이지 Blob | //<DeviceIPAddress>/<StorageAccountName_PageBlob>/<ContainerName>/files/a.txthttps://<StorageAccountName>.blob.core.windows.net/<ContainerName>/files/a.txt |
| Azure 파일 | //<DeviceIPAddress>/<StorageAccountName_AzFile>/<ShareName>/files/a.txthttps://<StorageAccountName>.file.core.windows.net/<ShareName>/files/a.txt |
Linux 호스트 컴퓨터를 사용하는 경우 다음 단계에 따라 NFS 클라이언트에 대한 액세스를 허용하도록 디바이스를 구성합니다.
공유에 액세스할 수 있도록 허용된 클라이언트의 IP 주소를 입력합니다. 로컬 웹 UI에서 연결 및 복사 페이지로 이동합니다. NFS 설정 아래에서 NFS 클라이언트 액세스를 클릭합니다.
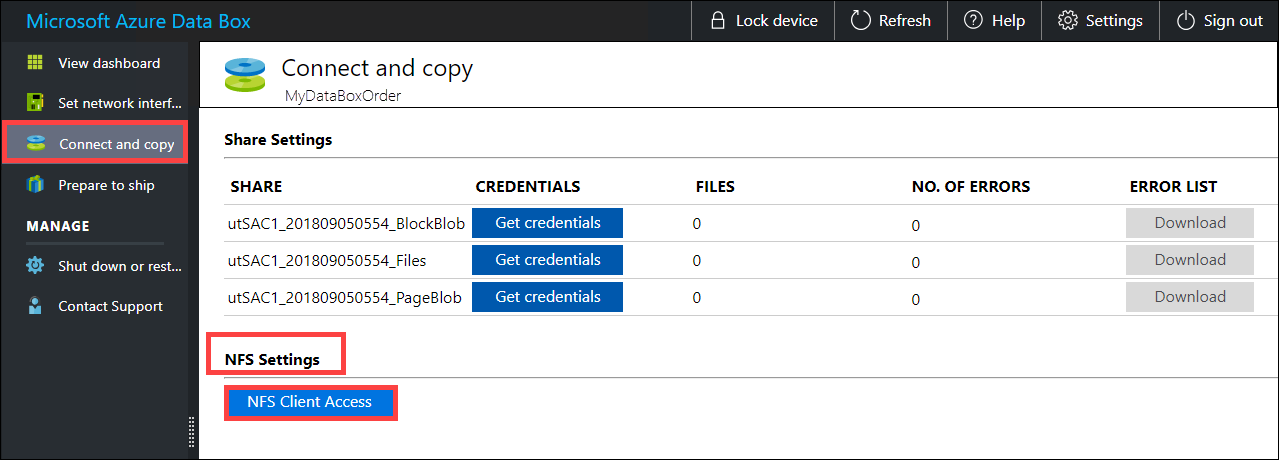
NFS 클라이언트의 IP 주소를 입력하고 추가를 클릭합니다. 이 단계를 반복하여 여러 NFS 클라이언트에 대한 액세스를 구성할 수 있습니다. 확인을 클릭합니다.
Linux 호스트 컴퓨터에 지원되는 버전의 NFS 클라이언트를 설치합니다. 해당 Linux 배포판에 맞는 버전을 사용하세요.
NFS 클라이언트가 설치되면 다음 명령을 사용하여 Data Box 디바이스에 NFS 공유를 탑재합니다.
sudo mount <Data Box Heavy device IP>:/<NFS share on Data Box Heavy device> <Path to the folder on local Linux computer>다음 예제에서는 NFS를 통해 Data Box Heavy 공유에 연결하는 방법을 보여줍니다. Data Box Heavy IP는
10.161.23.130이고,Mystoracct_Blob공유는 ubuntuVM에 탑재되며, 탑재 지점은/home/databoxheavyubuntuhost/databoxheavy입니다.sudo mount -t nfs 10.161.23.130:/Mystoracct_Blob /home/databoxheavyubuntuhost/databoxheavyMac 클라이언트에 대해 다음과 같은 추가 옵션을 추가해야 합니다.
sudo mount -t nfs -o sec=sys,resvport 10.161.23.130:/Mystoracct_Blob /home/databoxheavyubuntuhost/databoxheavy복사하려는 파일에 대한 폴더는 항상 공유 아래에 만든 다음 이 폴더에 파일을 복사합니다. 블록 Blob 및 페이지 Blob 공유 아래에 만들어진 폴더는 데이터가 Blob으로 업로드되는 컨테이너를 나타냅니다. 스토리지 계정의 root 폴더에 파일을 직접 복사할 수 없습니다.
Data Box Heavy에 데이터 복사
Data Box Heavy 공유에 연결하고 나면 다음 단계는 데이터를 복사하는 것입니다. 데이터 복사를 시작하기 전에 다음 고려 사항을 검토합니다.
적절한 데이터 형식에 해당하는 공유에 데이터를 복사해야 합니다. 예를 들어 블록 Blob에 대한 공유에 블록 Blob 데이터를 복사합니다. 페이지 Blob에 VHD를 복사합니다. 데이터 형식이 적절한 공유 형식과 일치하지 않는 경우 이후 단계에서 Azure에 데이터를 업로드하는 작업이 실패합니다.
데이터를 복사하는 동안 데이터 크기가 Azure 스토리지 및 Data Box Heavy 제한에 설명된 크기 제한을 준수해야 합니다.
Data Box Heavy에 의해 업로드되는 데이터가 Data Box Heavy 외부의 다른 애플리케이션에 의해 동시에 업로드되는 경우 업로드 작업이 실패하고 데이터 손상이 발생할 수 있습니다.
SMB 및 NFS를 동시에 사용하거나 Azure의 동일한 최종 대상에 동일한 데이터를 복사하지 않는 것이 좋습니다. 이 경우 최종 결과를 확인할 수 없습니다.
복사하려는 파일에 대한 폴더는 항상 공유 아래에 만든 다음 이 폴더에 파일을 복사합니다. 블록 Blob 및 페이지 Blob 공유 아래에 만들어진 폴더는 데이터가 Blob으로 업로드되는 컨테이너를 나타냅니다. 스토리지 계정의 root 폴더에 파일을 직접 복사할 수 없습니다.
NFS 공유에서 Data Box Heavy의 NFS까지 대/소문자 구분 디렉터리 및 파일 이름을 수집하는 경우:
- 이름의 대/소문자가 유지됩니다.
- 파일은 대/소문자를 구분하지 않습니다.
예를 들어
SampleFile.txt및Samplefile.Txt를 복사할 경우 디바이스에 복사되는 이름의 대/소문자는 유지되지만 두 번째 파일은 동일한 파일로 인식되어 첫 번째 파일을 덮어씁니다.
Linux 호스트 컴퓨터를 사용하는 경우 Robocopy와 비슷한 복사 유틸리티를 사용합니다. Linux에서 사용할 수 있는 대안 중 일부는 rsync, FreeFileSync, Unison 또는 Ultracopier입니다.
cp 명령은 디렉터리를 복사하는 최고의 옵션 중 하나입니다. 사용 방법에 대한 자세한 내용은 cp 기본 페이지를 참조하세요.
다중 스레드 복사에 rsync 옵션을 사용하는 경우 다음 지침을 따르세요.
Linux 클라이언트에서 사용하는 파일 시스템에 따라 CIFS 유틸리티 또는 NFS 유틸리티 패키지를 설치합니다.
sudo apt-get install cifs-utilssudo apt-get install nfs-utilsRsync 및 Parallel을 설치합니다(Linux 배포판 버전에 따라 다름).
sudo apt-get install rsyncsudo apt-get install parallel탑재 지점을 만듭니다.
sudo mkdir /mnt/databoxheavy볼륨을 탑재합니다.
sudo mount -t NFS4 //Databox-heavy-IP-Address/share_name /mnt/databoxheavy폴더 디렉터리 구조를 미러링합니다.
rsync -za --include='*/' --exclude='*' /local_path/ /mnt/databoxheavy파일을 복사합니다.
cd /local_path/; find -L . -type f | parallel -j X rsync -za {} /mnt/databoxheavy/{}여기서 j는 병렬 처리의 수를 지정하고, X는 병렬 복사본의 수
병렬 복사본 16개로 시작하여 가용 리소스에 따라 스레드 수를 늘리는 것이 좋습니다.
Important
Linux 파일 형식인 기호 링크, 문자 파일, 블록 파일, 소켓 및 파이프는 지원되지 않습니다. 이러한 파일 형식을 사용하면 배송 준비 단계 동안 오류가 발생합니다.
대상 폴더를 열어 복사된 파일을 보고 확인합니다. 복사 프로세스 중 오류가 있는 경우 문제 해결을 위해 오류 파일을 다운로드하세요. 자세한 내용은 Data Box Heavy로 데이터를 복사하는 동안 오류 로그 보기를 참조하세요. 데이터를 복사하는 동안 발생하는 오류에 대한 자세한 목록을 보려면 Data Box Heavy 문제 해결을 참조하세요.
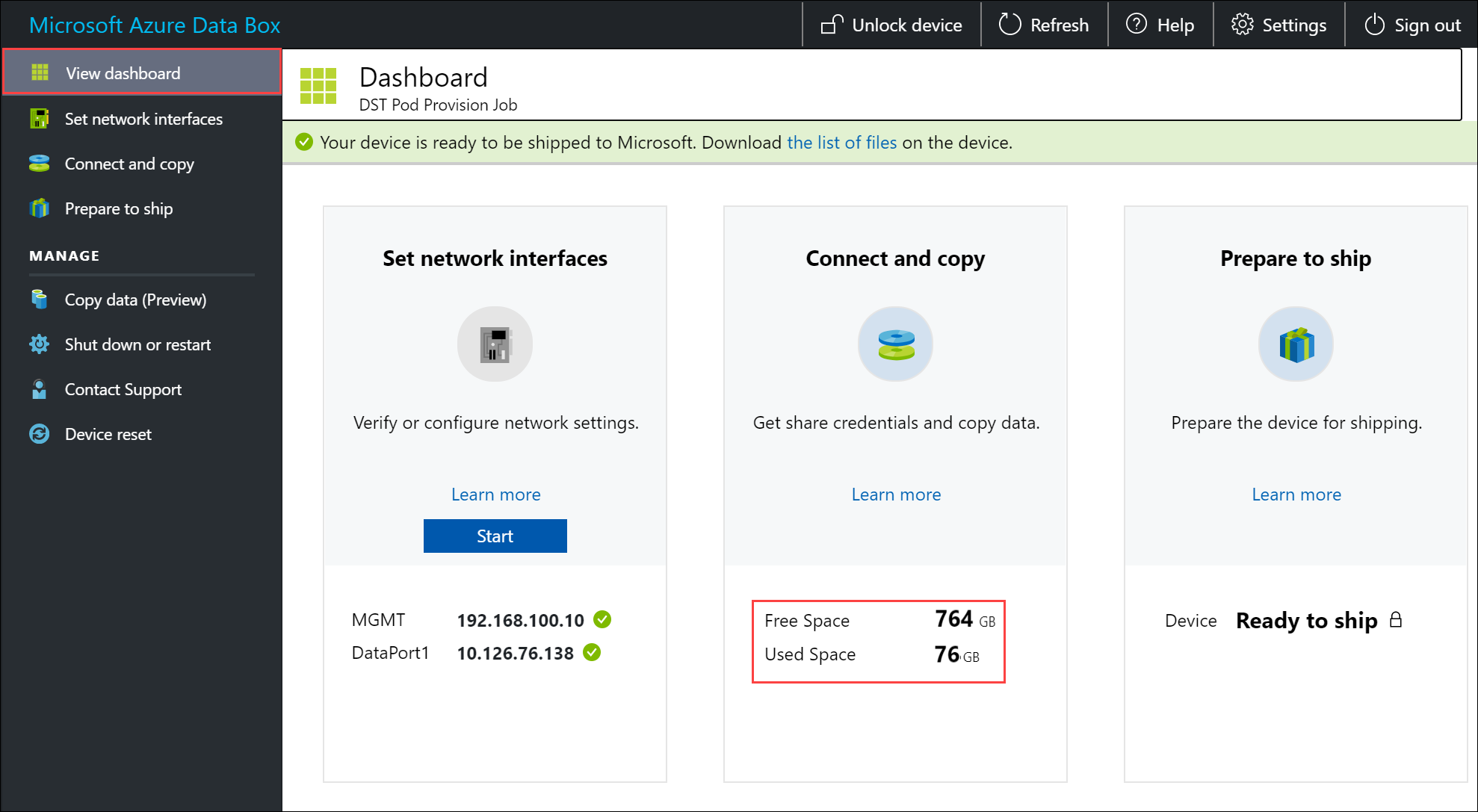
데이터 무결성을 보장하기 위해, 데이터가 복사될 때 체크섬이 인라인으로 계산됩니다. 복사가 완료되면 디바이스에서 사용 중인 공간과 여유 공간을 확인합니다.
다음 단계
이 자습서에서는 Azure Data Box Heavy 항목에 대해 다음과 같은 내용을 알아보았습니다.
- 필수 조건
- Data Box Heavy에 연결
- Data Box Heavy에 데이터 복사
Data Box를 Microsoft로 다시 배송하는 방법을 알아보려면 다음 자습서로 계속 진행하세요.