Azure Databricks에서 Jar 활동을 실행하여 데이터 변환
적용 대상: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
파이프라인의 Azure Databricks Jar 작업은 Azure Databricks 클러스터에서 Spark Jar를 실행합니다. 이 문서는 데이터 변환 및 지원되는 변환 활동의 일반적인 개요를 표시하는 데이터 변환 활동 문서에서 작성합니다. Azure Databricks는 Apache Spark를 실행하기 위해 관리되는 플랫폼입니다.
11분 동안 이 기능의 소개 및 데모에 대한 다음 비디오를 시청하세요.
UI를 사용하여 파이프라인에 Azure Databricks에 대한 Jar 작업 추가
파이프라인에서 Azure Databricks에 대한 Jar 작업을 사용하려면 다음 단계를 완료합니다.
파이프라인 작업 창에서 Jar를 검색하고 Jar 작업을 파이프라인 캔버스로 끕니다.
아직 선택하지 않은 경우 캔버스에서 새 Jar 작업을 선택합니다.
Azure Databricks 탭을 선택하여 Jar 작업을 실행할 새 Azure Databricks 연결된 서비스를 선택하거나 만듭니다.
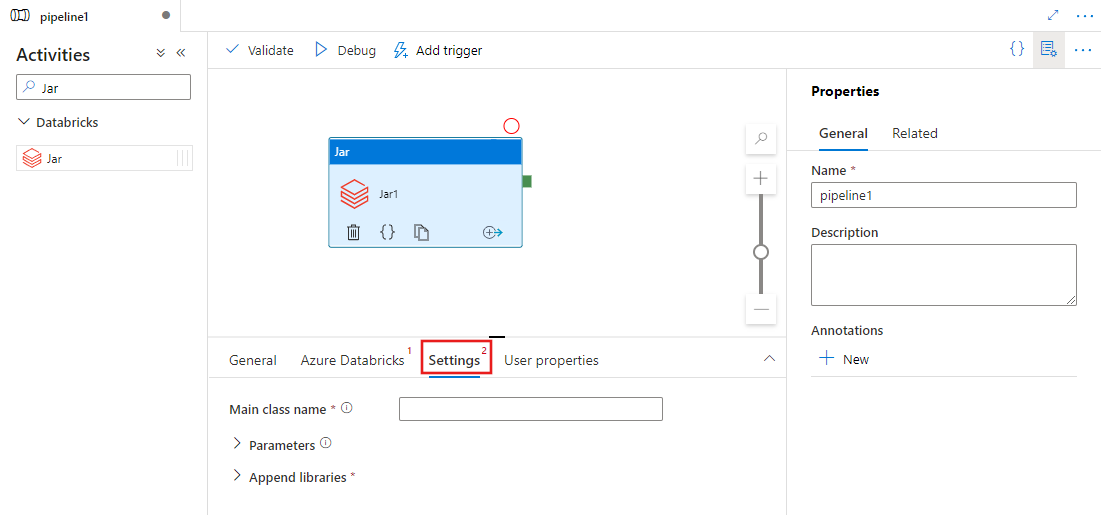
설정 탭을 선택하고 Azure Databricks에서 실행할 클래스 이름, Jar에 전달할 선택적 매개 변수 및 작업을 실행하기 위해 클러스터에 설치할 라이브러리를 지정합니다.
Databricks Jar 활동 정의
Databricks Jar 활동에 대한 샘플 JSON 정의는 다음과 같습니다.
{
"name": "SparkJarActivity",
"type": "DatabricksSparkJar",
"linkedServiceName": {
"referenceName": "AzureDatabricks",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mainClassName": "org.apache.spark.examples.SparkPi",
"parameters": [ "10" ],
"libraries": [
{
"jar": "dbfs:/docs/sparkpi.jar"
}
]
}
}
Databricks Jar 활동 속성
다음 표에서는 JSON 정의에 사용하는 JSON 속성을 설명합니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| name | 파이프라인의 작업 이름입니다. | 예 |
| description | 작업이 어떤 일을 수행하는지 설명하는 텍스트입니다. | 아니요 |
| type | Databricks Jar 활동의 경우 활동 유형은 DatabricksSparkJar입니다. | 예 |
| linkedServiceName | Jar 활동이 실행되는 Databricks 연결된 서비스의 이름입니다. 이 연결된 서비스에 대한 자세한 내용은 컴퓨팅 연결 서비스 문서를 참조하세요. | 예 |
| mainClassName | 실행될 main 메서드가 포함된 클래스의 전체 이름입니다. 이 클래스는 라이브러리로 제공된 JAR에 포함되어야 합니다. JAR 파일에는 여러 클래스가 포함될 수 있습니다. 각 클래스에는 main 메서드가 포함될 수 있습니다. | 예 |
| 매개 변수 | main 메서드에 전달할 매개 변수이며, 이 속성은 문자열의 배열입니다. | 아니요 |
| 라이브러리 | 작업을 실행할 클러스터에 설치할 라이브러리의 목록입니다. <문자열, 개체>의 배열일 수 있습니다. | 예(mainClassName 메서드가 하나 이상 포함되는 경우) |
참고 항목
알려진 문제 - 동시 Databricks Jar 활동을 실행하기 위해 동일한 대화형 클러스터를 사용하는 경우(클러스터 다시 시작 없이) Databricks에는 첫 번째 작업의 매개 변수가 다음 작업에서도 사용되는 것으로 알려진 문제가 있습니다. 따라서 후속 작업에 전달되는 잘못된 매개 변수가 생성됩니다. 이를 완화하려면 작업 클러스터를 대신 사용합니다.
Databricks 활동에 지원되는 라이브러리
이전 Databricks 활동 정의에서 jar,egg, maven, pypi, cran 라이브러리 유형을 지정했습니다.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
자세한 내용은 라이브러리 유형에 대한 Databricks 설명서를 참조하세요.
Databricks에서 라이브러리를 업로드하는 방법
작업 영역 UI를 사용할 수 있습니다.
UI를 사용하여 추가된 라이브러리의 dbfs 경로를 얻으려면 Databricks CLI를 사용하면 됩니다.
일반적으로 Jar 라이브러리는 UI를 사용하는 동안 dbfs:/FileStore/jars 아래에 저장됩니다. databricks fs ls dbfs:/FileStore/job-jars CLI를 통해 모두 나열할 수 있습니다.
또는 Databricks CLI를 사용할 수 있습니다.
Databricks CLI (설치 단계)를 사용합니다.
예를 들어, JAR를 DBFS에 복사하려면
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar을 수행합니다.
관련 콘텐츠
11분 동안 이 기능의 소개 및 데모에 대한 비디오를 시청하세요.